基于fastGpt + m3e模型打造企业/个人私有化知识库(本地部署教程)
基于fastGpt + m3e模型打造企业/个人私有化知识库(本地部署教程)
引言
在数字化时代,构建个人知识库已成为技术爱好者的新趋势。为此,我专门编写了一篇简单易懂的教程,旨在帮助您使用FastGPT和Docker Compose搭建自己的本地知识库。这篇“保姆级”教程将引导您轻松完成这一任务。
关于FastGpt
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!本文就以FastGpt来搭建一个属于自己的ai助理
核心流程图
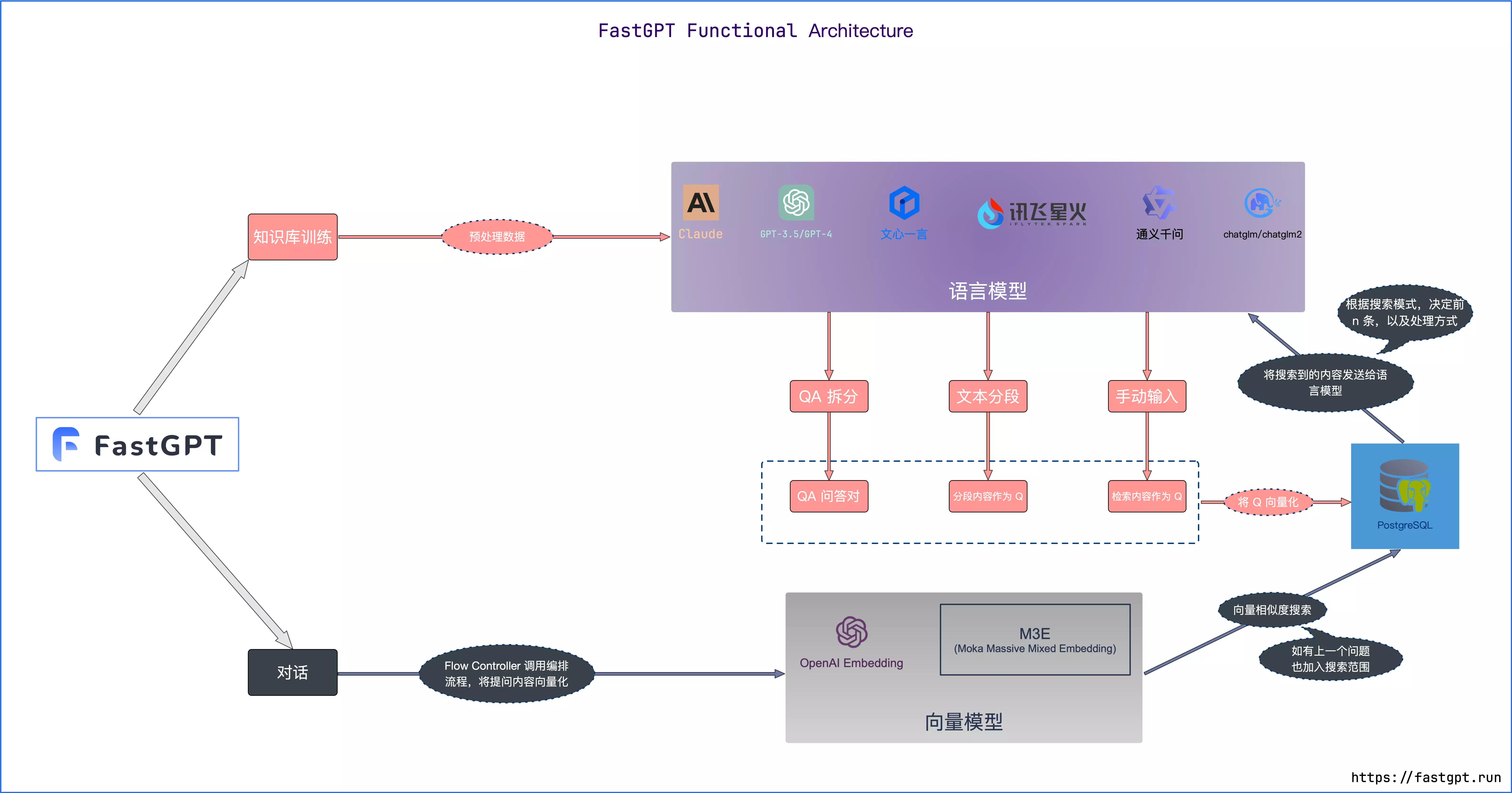
FastGpt前置基础知识
5大模型类别
-
LLMModule(大型语言模型)
: 大型语言模型(LLM)是设计用来处理和理解人类语言的AI模型。它们通常在大量的文本数据上进行训练,能够执行语言翻译、文本摘要、问答以及文本生成等任务。
- qwen-tubo(初代的通义千问文本模型,我们日常聊天的文本模型), chat-3.5-turbo(ChatGPT3.5)
-
vectorModels(向量模型) :向量模型用于将数据(通常是文本或图像)表示为高维空间中的向量。这些模型在机器学习和AI中是基础性的,用于执行相似性搜索、聚类和分类等任务LLM的模型训练就是基于向量模型.
-
reRankModels(重排模型): 重排模型通常用于在初步排序或筛选后,对结果进行进一步的精细排序,这类模型的作用的是对于结果进行重新排列,提高回答的准确率.
- 例如,在搜索引擎中,重排模型可能会根据用户的点击行为或反馈来调整搜索结果的顺序。
-
audioSpeechModels(音频语音模型): 音频语音模型专注于处理和分析音频数据,尤其是语音。这些模型可以用于语音识别、语音合成、情感分析等任务。
-
**whisperModel(音频处理模型) **: 用于执行如语音识别、音频分类或语音到文本的转换等任务。
M3E
Moka Massive Mixed Embedding 的缩写
Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 **uniem** ,评测 BenchMark 使用 **MTEB-zh**Massive,此模型通过**千万级** (2200w+) 的中文句对数据集进行训练Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索Embedding,此模型是文本嵌入模型,可以将自然语言转换成稠密的向量+
环境准备
Docker部署
FastGpt的部署,极大的进行依赖Docker环境,所以需要在你的本地或者需要部署的服务器进行安装Docker环境
Linux系统
教程取自【Linux安装最新版Docker完整教程】
安装依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
设置阿里云docker-ce镜像源
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装Docker
yum install -y docker-ce
启动docker并设置开机自启
#启动docker命令
systemctl start docker
#设置开机自启命令
systemctl enable docker
#查看docker版本命令
docker version
配置国内镜像源
因为docker服务在国外,会导致下载慢或者无法下载。需要配置国内镜像,以阿里云为例:
您可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
#创建文件
sudo mkdir -p /etc/docker
#修改配置文件
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://**(替换为自己的地址).mirror.aliyuncs.com"]
}
EOF
##重启docker
sudo systemctl daemon-reload
sudo systemctl restart docker
Windows系统
我们建议将源代码和其他数据绑定到 Linux 容器中时,将其存储在 Linux 文件系统中,而不是 Windows 文件系统中。
可以选择直接使用 WSL 2 后端在 Windows 中安装 Docker Desktop。
也可以直接在 WSL 2 中安装命令行版本的 Docker。
MacOs系统
推荐直接使用 Orbstack。可直接通过 Homebrew 来安装:
brew install orbstack
开始部署
架构图
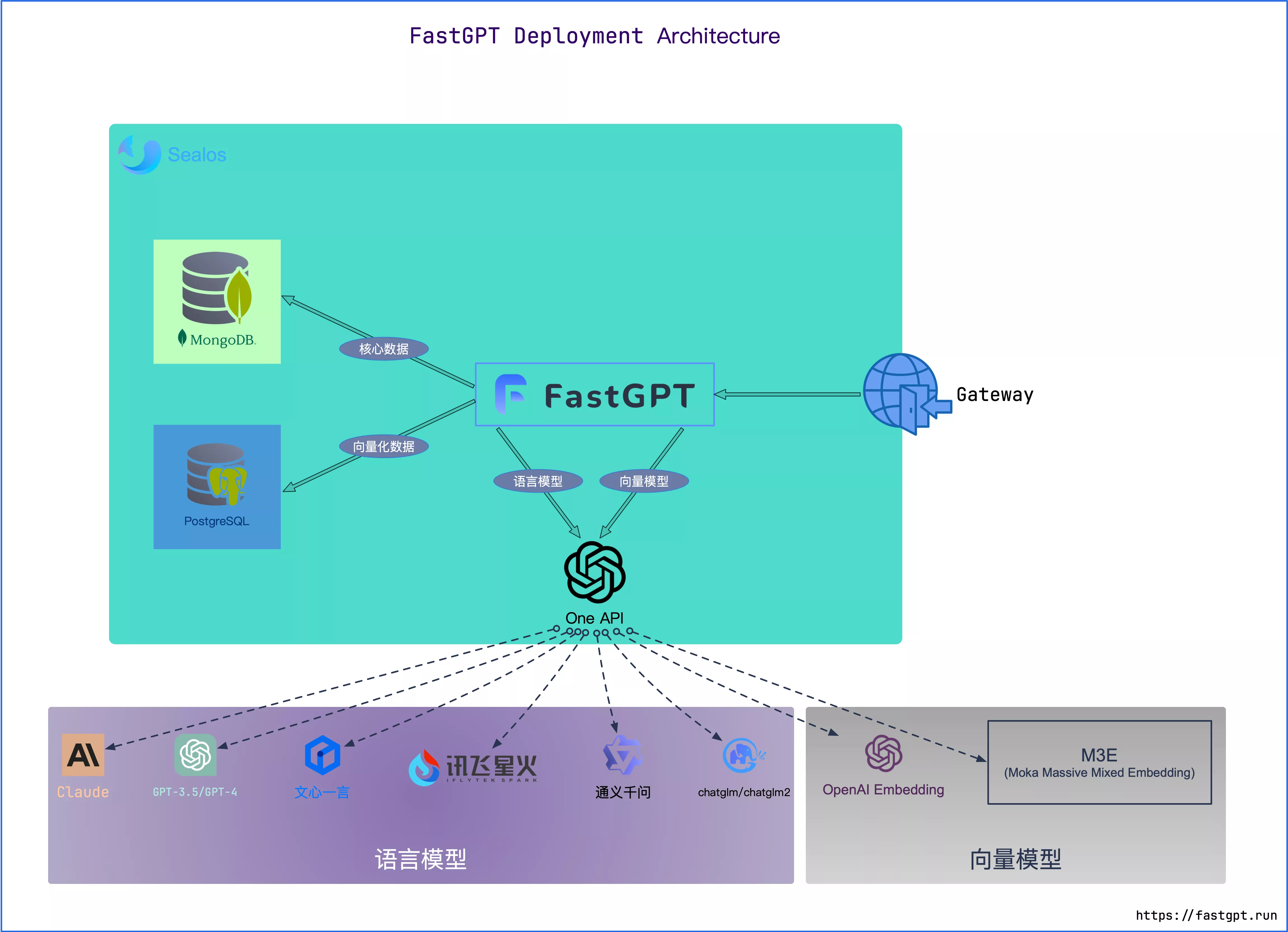
FastGpt部署
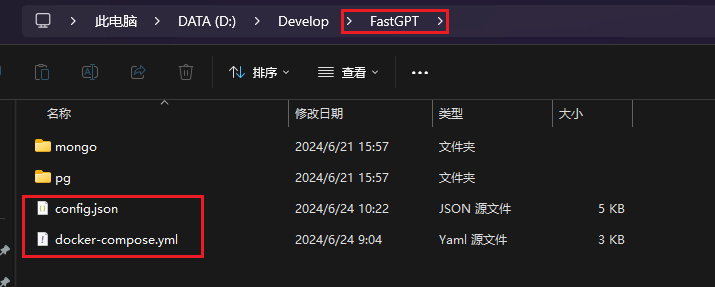
新建文件夹
本地创建一个名为【fastgpt】的文件夹并进去
windows:右键-》新建
linux:
新建文件夹
mkdir fastgpt
进入
cd fastgpt
下载配置文件
下载不下来可以直接本地新建相应文件,然后将文件中的内容放进去
# 下载config.json文件
wget https://gitee.com/sigmend/FastGPT/raw/main/projects/app/data/config.json -o config.json
# 下载docker-compose.yml
wget https://gitee.com/sigmend/FastGPT/raw/main/files/deploy/fastgpt/docker-compose.yml -o docker-compose.yml
启动容器
以管理员身份运行cmd,并进入FastGPT目录
# 在 docker-compose.yml 同级目录下执行
docker-compose pull
docker-compose up -d
Mongo数据库初始化
首次使用时,需要连接数据库,已经默认配置了数据库信息,但是第一次连接需要进行初始化,不然无法登陆。
1、终端中执行下面命令,创建mongo密钥:
openssl rand -base64 756 > ./mongodb.key chmod 600 ./mongodb.key # 修改密钥权限,部分系统是admin,部分是root chown 999:root ./mongodb.key2、修改 docker-compose.yml,挂载密钥
这一步检查即可,一般都是默认
mongo: # image: mongo:5.0.18 # image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云 container_name: mongo ports: - 27017:27017 networks: - fastgpt command: mongod --keyFile /data/mongodb.key --replSet rs0 environment: # 默认的用户名和密码,只有首次允许有效 - MONGO_INITDB_ROOT_USERNAME=myusername - MONGO_INITDB_ROOT_PASSWORD=mypassword volumes: - ./mongo/data:/data/db - ./mongodb.key:/data/mongodb.key3、重启服务
docker-compose down docker-compose up -d4、进入容器执行副本集合初始化
# 查看 mongo 容器是否正常运行 docker ps # 进入容器 docker exec -it mongo bash # 连接数据库(这里要填Mongo的用户名和密码) mongo -u myusername -p mypassword --authenticationDatabase admin # 初始化副本集。如果需要外网访问,mongo:27017 。如果需要外网访问,需要增加Mongo连接参数:directConnection=true rs.initiate({ _id: "rs0", members: [ { _id: 0, host: "mongo:27017" } ] }) # 检查状态。如果提示 rs0 状态,则代表运行成功 rs.status()
访问FastGPT
目前可以通过
ip:3000直接访问(注意防火墙)。登录用户名为root,密码为docker-compose.yml环境变量里设置的DEFAULT_ROOT_PSW。如果需要域名访问,请自行安装并配置 Nginx。
首次运行,会自动初始化 root 用户,密码为
1234(与环境变量中的DEFAULT_ROOT_PSW一致),日志里会提示一次MongoServerError: Unable to read from a snapshot due to pending collection catalog changes;可忽略。
OneApi部署
关于OneApi
OneApi的作用就是把这些API的调用进行了整合到了一起,使我们进行使用的时候完全的按照OneAPI的一套规范就能够进行调用和使用其他的大模型,无疑OneApi极大的进行提高了我们进行学习AI的效率,不用在不同的模型接口之间进行切换,也使得FastApi可以直接的通过这套规范进行训练
部署OneApi
在终端中输入相关命令
项目中的3000端口被占用,需要重新设定一个端口映射
# 使用 SQLite 的部署命令(不用安装mysql):
docker run --name one-api -d --restart always -p 13000:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api
# 使用 MySQL 的部署命令,在上面的基础上添加 `-e SQL_DSN="root:123456@tcp(localhost:3306)/oneapi"`,请自行修改数据库连接参数,不清楚如何修改请参见下面环境变量一节。
# 例如:
docker run --name one-api -d --restart always -p 13000:3000 -e SQL_DSN="root:123456@tcp(127.0.0.1:3306)/oneapi" -e TZ=Asia/Shanghai -v /home--network host/ubu:ntu/data/one-api:/data justsong/one-api
命令详解
docker run: 这是 Docker 的主要命令之一,用于创建并启动一个新的容器。
–name one-api: 这个选项为即将运行的容器设置一个名字,这里名字被设为 one-api。这样做可以更容易地识别和引用容器。
-d: 这个选项表示容器将在“分离模式”下运行,意味着它会在后台运行。
–restart always: 这指定了容器的重启策略。在这里,always 意味着如果容器停止(无论是由于错误还是由于任何其他原因),它将自动重启。
-p 13000:3000: 这是端口映射。此设置将容器内的 3000 端口映射到宿主机的 13000 端口。这意味着宿主机的 13000 端口上的流量将被转发到容器的 3000 端口。
-e TZ=Asia/Shanghai: 这个选项设置了一个环境变量。在这里,它设置了容器的时区为 Asia/Shanghai。
-v /home/ubuntu/data/one-api:/data: 这是一个卷挂载。它将宿主机的 /home/ubuntu/data/one-api 目录挂载到容器内的 /data 目录。这允许在容器和宿主机之间共享数据。
justsong/one-api: 这是要运行的 Docker 镜像的名称。在这个例子中,它将从 Docker Hub(或者其他配置的注册中心)拉取名为 justsong/one-api 的镜像。
访问OneApi
可以通过
ip:13000访问OneAPI,默认账号为root密码为123456。本地访问: http://localhost:13000
请注意:到了这一步后暂时还不能训练模型,还需要结合m3e,本教程先部署所有需要的环境后,再教学配置以及使用,请继续往后看。
M3E嵌入模型部署
关于m3e嵌入模型
M3E是Moka Massive Mixed Embedding的缩写,是一个由MokaAI训练并开源的文本嵌入模型。适合使用场景主要是中文,少量英文的情况,其在文本分类和文本检索任务上表现出色,据称在某些任务上超越了ChatGPT。此工具是我们实现本地化个人模型的必备,当然,也不是非m3e不可,但是本文以m3e为教程演示,其他工具自行寻找教程。
拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
启动镜像
# 使用CPU运行
docker run -d --name m3e -p 6100:6008 registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
# nvida-docker 使用GPU
docker run -d --name m3e -p 6100:6008 --gpus all registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
one-api部署国内大模型
登入one api
根据设定的端口,在浏览器内输入localhost:13000,默认账号为
root密码为123456
创建渠道
登录进去后,点击上方的【渠道】->【添加新的渠道】
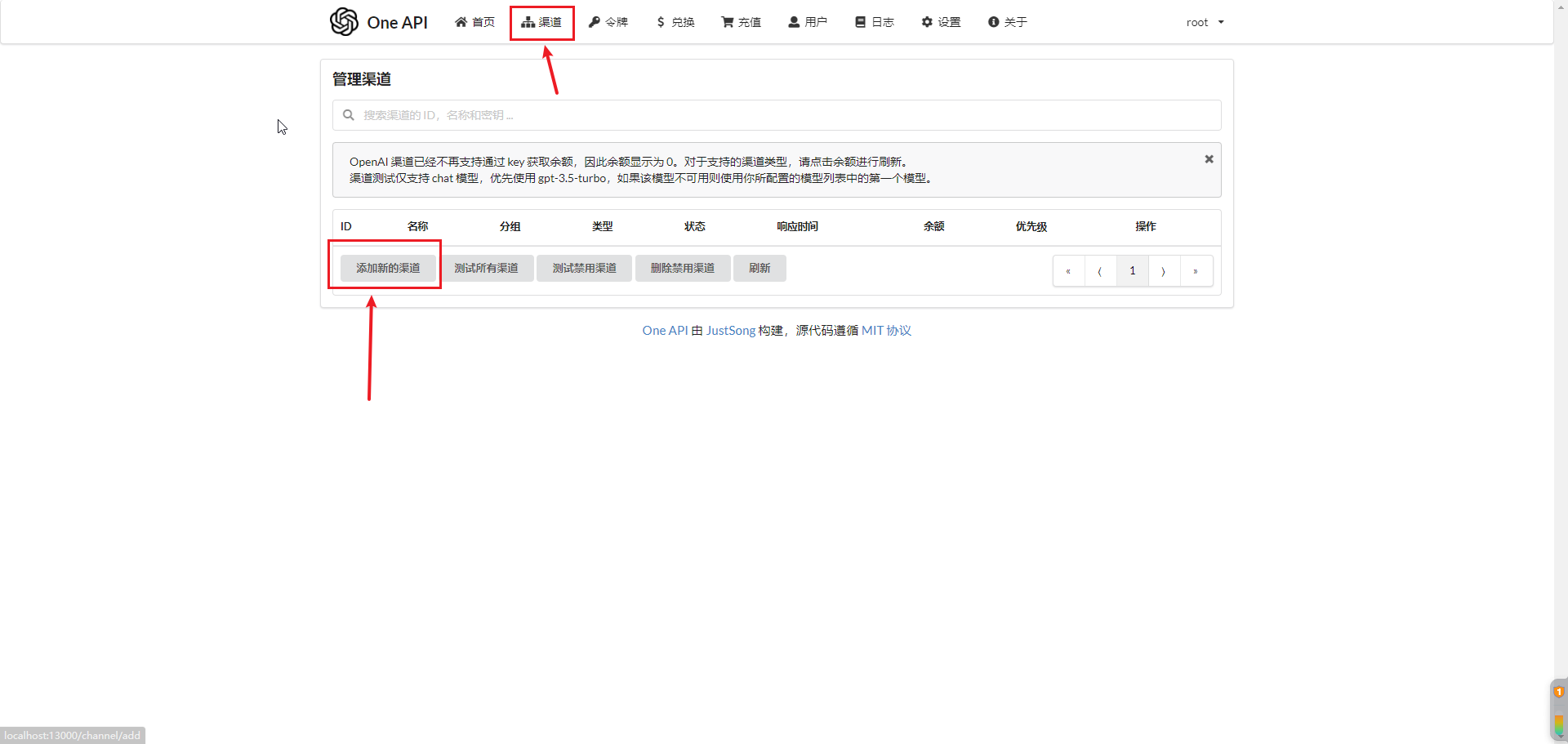
渠道有很多,比如:文心一言、openAI、讯飞星火、通义千问等。
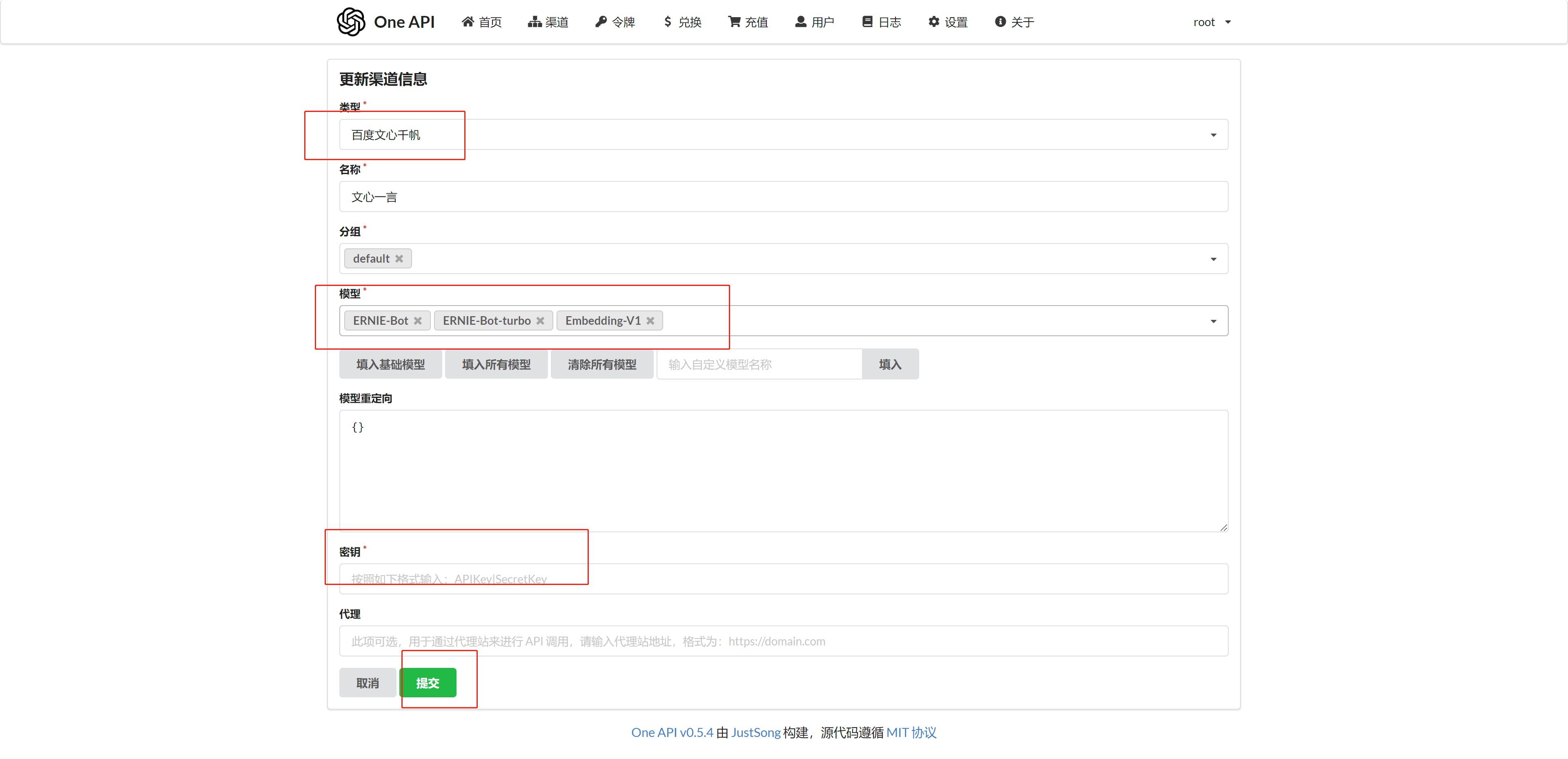
以添加文心一言为例
添加对话模型渠道
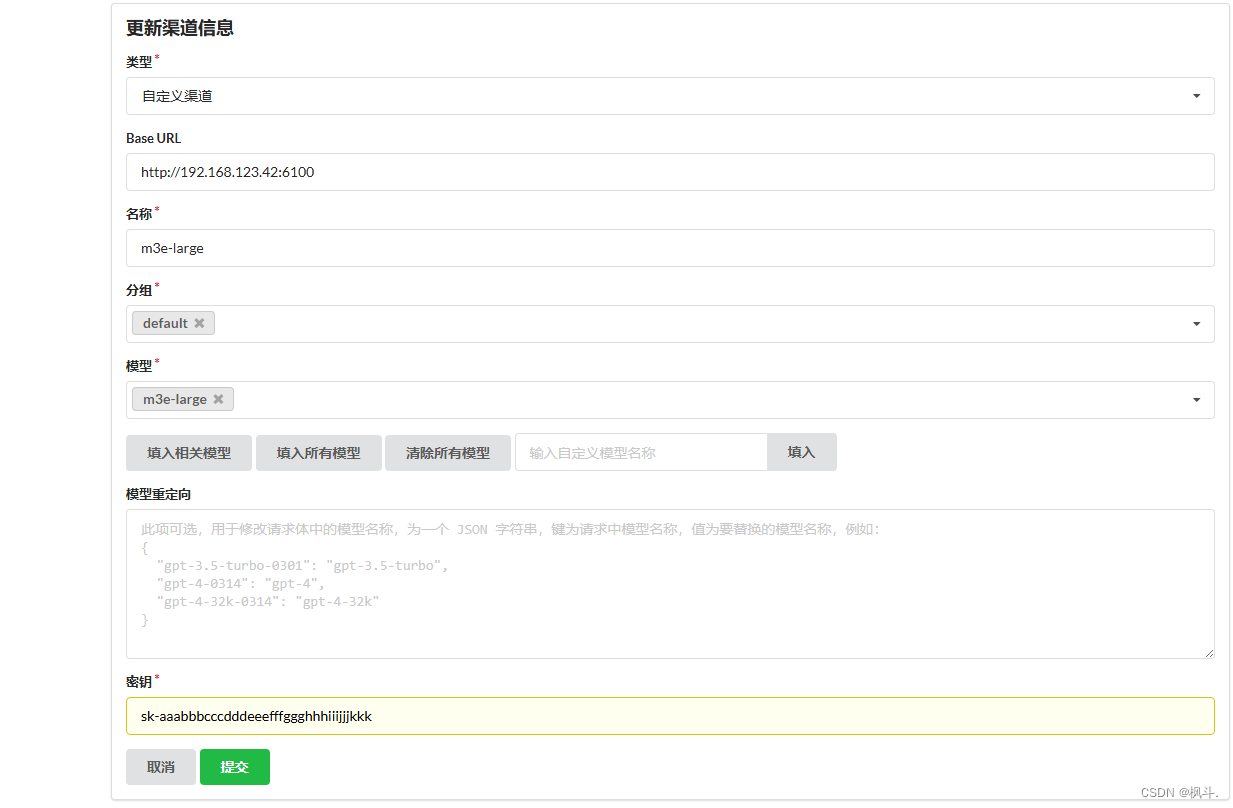
添加m3e嵌入模型渠道
密钥默认设置为: sk-aaabbbcccdddeeefffggghhhiiijjjkkk
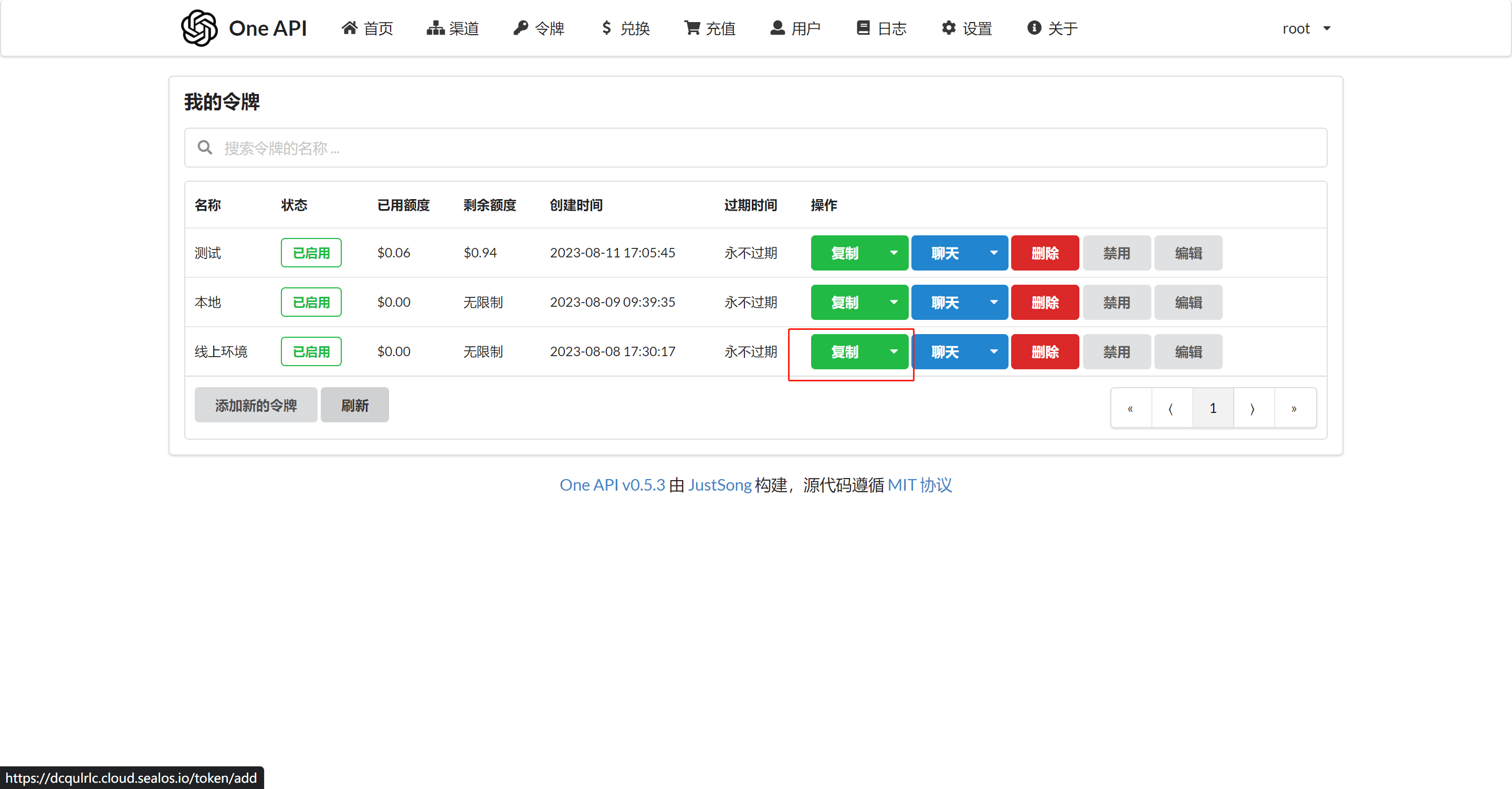
创建令牌
修改 FastGPT 配置文件
config.json
"chatModels": [
...
#新增一个模型配置
{
"model": "qwen-turbo",#要和oneApi中定义的模型名称一致
"name": "通义千问", #要和oneApi中定义的渠道名称一致
"maxContext": 8000,
"maxResponse": 4000,
"quoteMaxToken": 2000,
"maxTemperature": 1,
"vision": false,
"defaultSystemChatPrompt": ""
}
...
]
docker-compose.yml
# oneApi的服务地址
# base_url为ip地址:13000 注意:这个地方的ip不能是localhost或者127.0.0.1,需要外网ip或者局域网ip
- OPENAI_BASE_URL=http://*******:13000/v1
# api-key点击令牌复制的key
- CHAT_API_KEY=sk-**************
添加m3e向量模型:
"vectorModels": [
......
{
"model": "m3e",
"name": "m3e",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 700,
"maxToken": 3000,
"weight": 100
},
......
]
重启FastGpt
docker-compose down
docker-compose up -d
Fast创建个人知识库
创建知识库
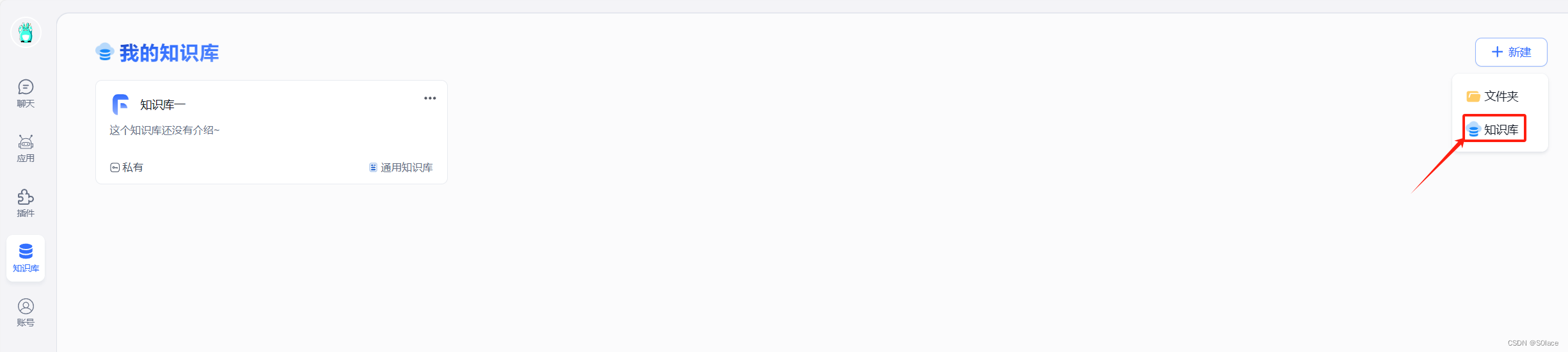
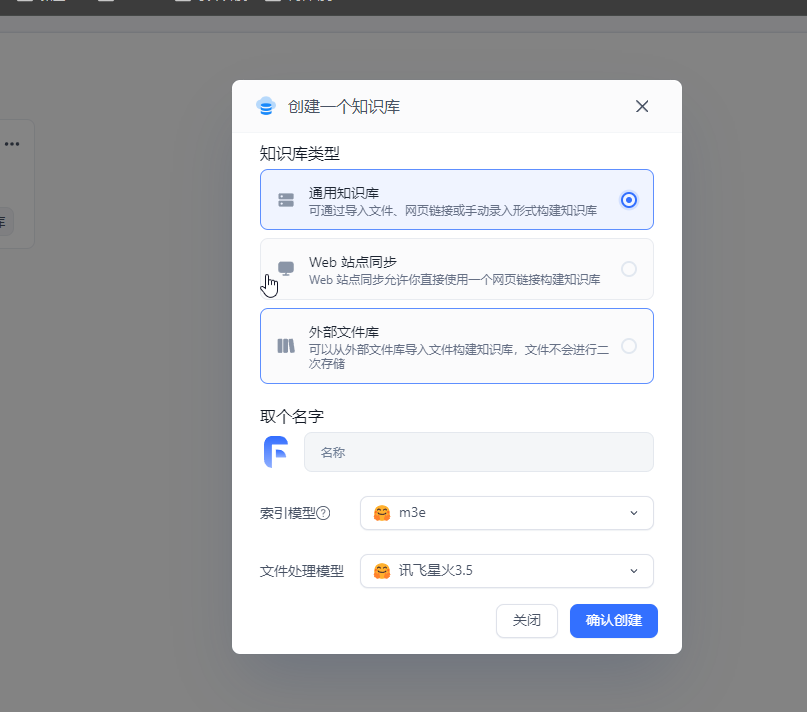
索引模型选择配置好的m3e
文件处理模型选择配置好的语言对话模型
导入文本,文档数据等
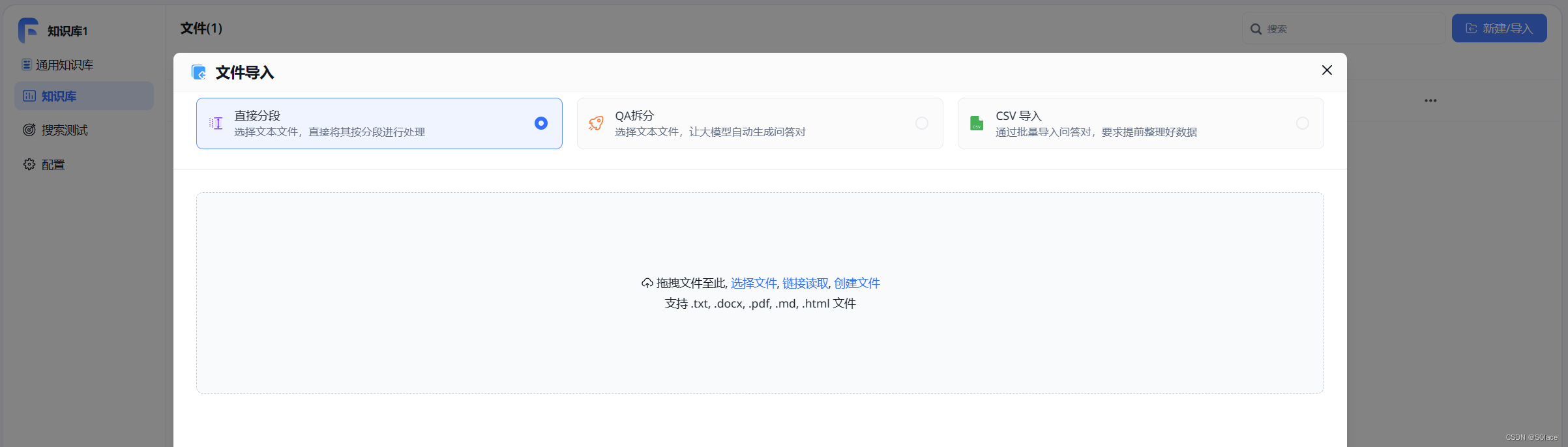
添加成功后,等待索引成功即可。
创建知识库应用
新增一个应用
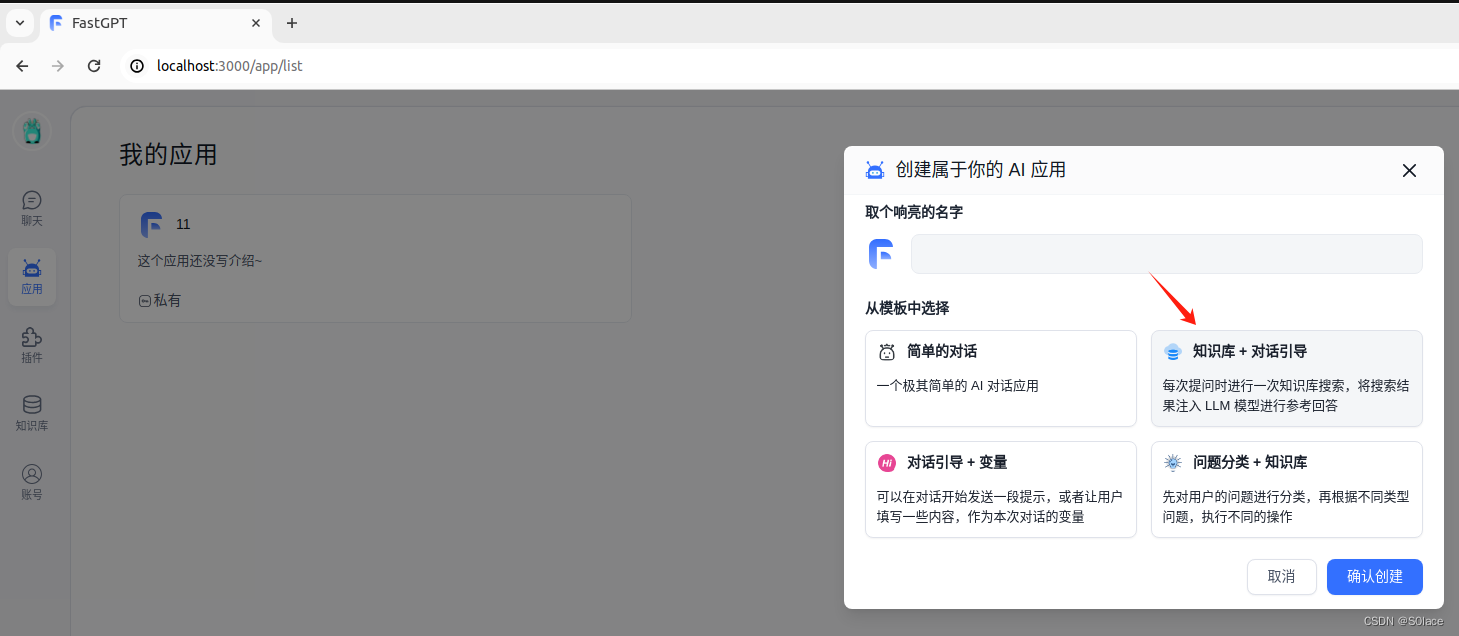
选择需要关联的知识库
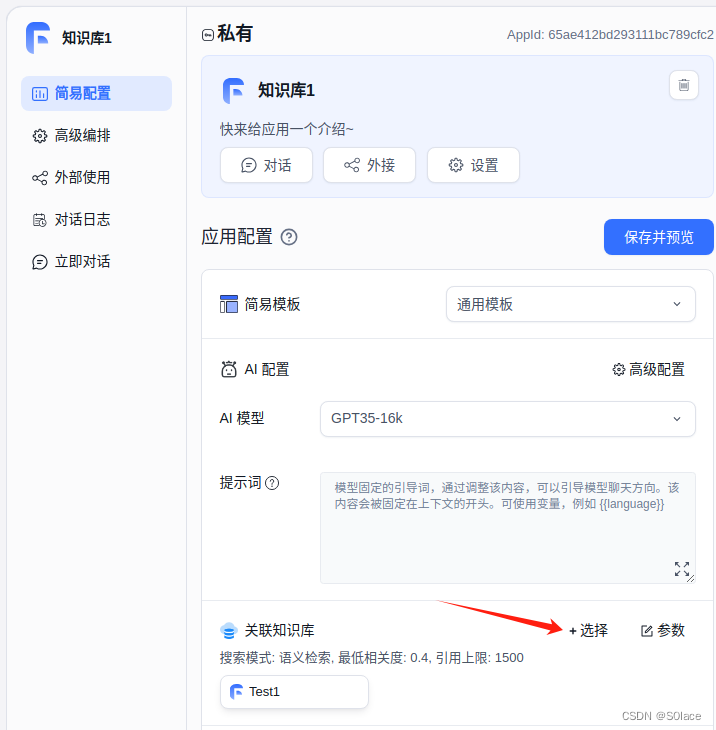
自定义对话测试
此时语言模型对话内容中,就可以穿插自己定义的知识库内容了,还可以发布、预览
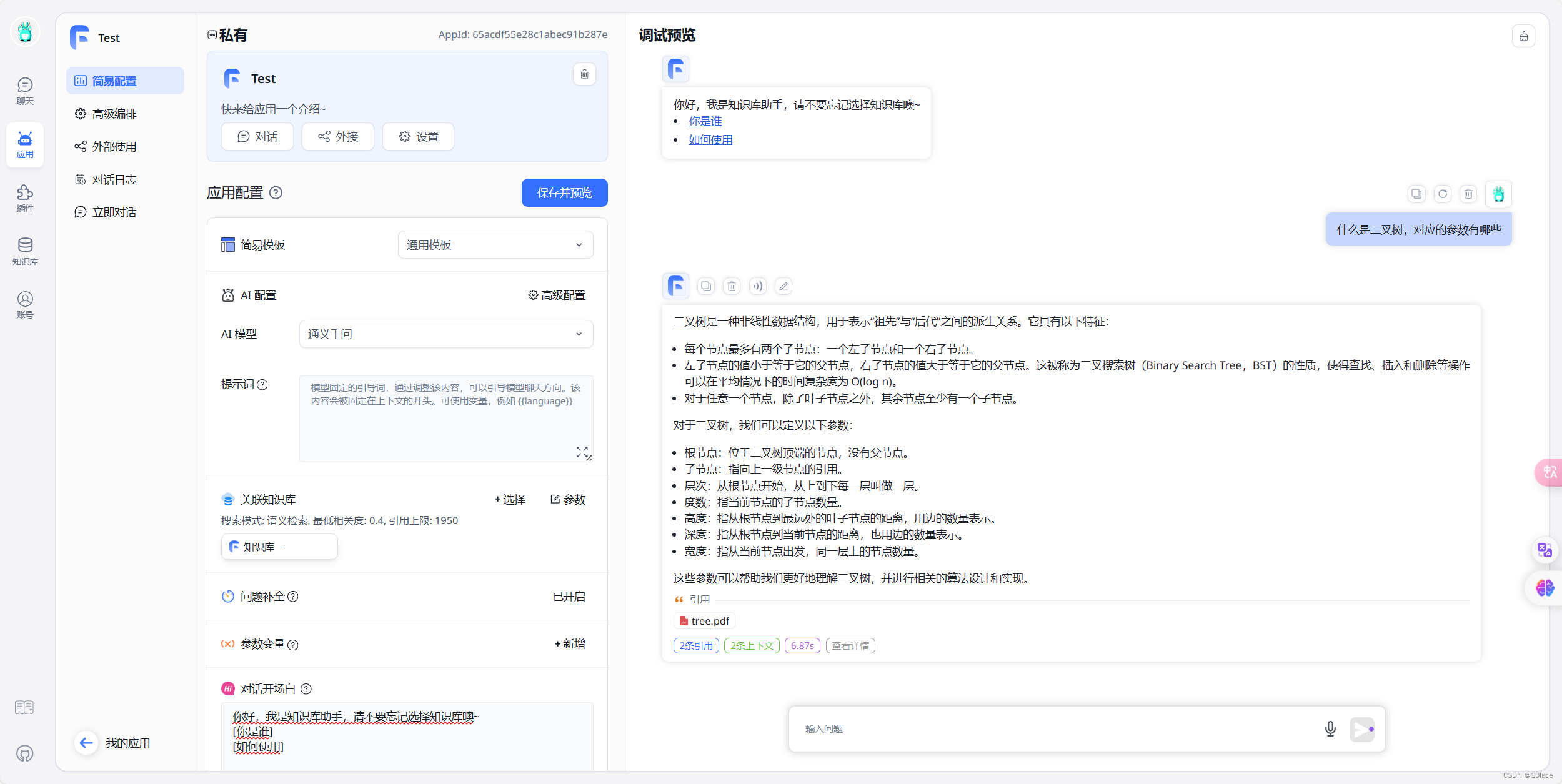
到此,就完成了基础的部署。
遇到问题
在部署过程中如果遇到问题,请善用搜索引擎
官方文档地址:
FastGpt官方文档地址: https://doc.fastgpt.in/docs/development/docker/
常见问题处理: https://doc.fastai.site/docs/development/faq/#connection-error
相关文档
-
FastGpt开源: https://github.com/labring/FastGPT
-
私有化知识库本地部署打造专属ai助理(FastGpt本地部署全过程及相关模型部署训练): https://blog.csdn.net/m0_74205854/article/details/139376489
-
【向量模型M3E,打造功能完备的本地AI知识库】Docker一键部署,oneapi快速嵌入AI应用: https://zhuanlan.zhihu.com/p/675271031
-
保姆级教程:FastGPT构建个人本地知识库(Docker compose快速部署): https://blog.csdn.net/m0_62536353/article/details/135733446

 浙公网安备 33010602011771号
浙公网安备 33010602011771号