
爬虫综合大作业
本次作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:newsdf = pd.read_csv(r'F:\duym\gzccnews.csv')
一、把爬取的内容保存到数据库
- 保存到sqlite3数据库
import sqlite3 with sqlite3.connect('newsdb.sqlite') as db: newsdf.to_sql('gzccnewsdb',con=db, if_exists='replace') with sqlite3.connect('newsdb.sqlite') as db: df = pandas.read_sql_query('SELECT * FROM gzccnewsdb',con=db)#查询
截图:

- 保存到MySQL数据库
import pymysql from sqlalchemy import create_engine conn = create_engine('mysql+pymysql://root:@localhost:3306/gzccnews?charset=utf8',encoding='utf-8') newsdf.to_sql(name ='gzccnews', con = conn, if_exists = 'append', index = False)
截图:
-
- 在MySQL中新建数据库

-
- 导入数据库成功
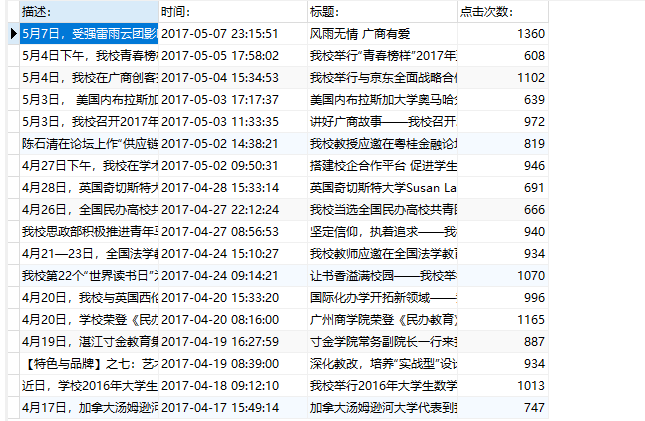
二、爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
- 爬虫主题:分析电影《何以为家》好不好看
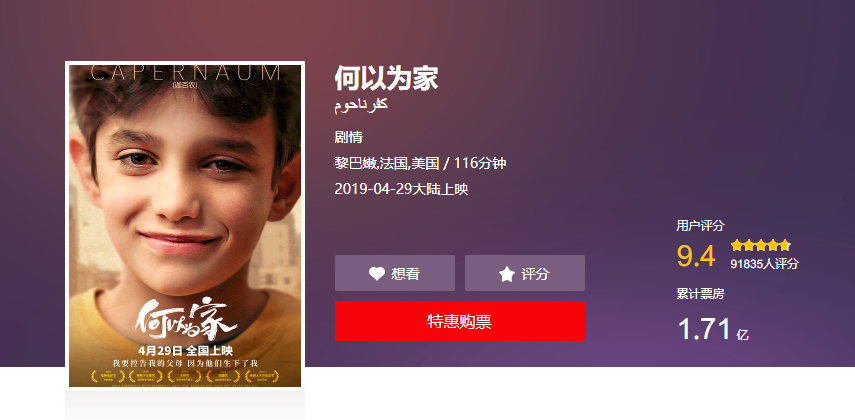
主要内容:法庭上,十二岁的男孩赞恩向法官状告他的亲生父母,原因是,他们给了他生命。故事中,赞恩的父母在无力抚养和教育的状况下依然不停生育,作为家中的长子赞恩,弱小的肩膀承担了无数生活的重压。当妹妹被强行卖给商贩为妻时,赞恩愤怒离家,之后遇到一对没有合法身份的母子,相互扶持勉强生活。然而生活并没有眷顾赞恩,重重磨难迫使他做出了令人震惊的举动……
- 爬取对象:猫眼电影(https://maoyan.com/)
- 爬取对象的限制与约束:猫眼电影的web版关于电影的评论是有限的,不允许获取所有用户的评论,最终发现要在手机终端的页面才可以获得
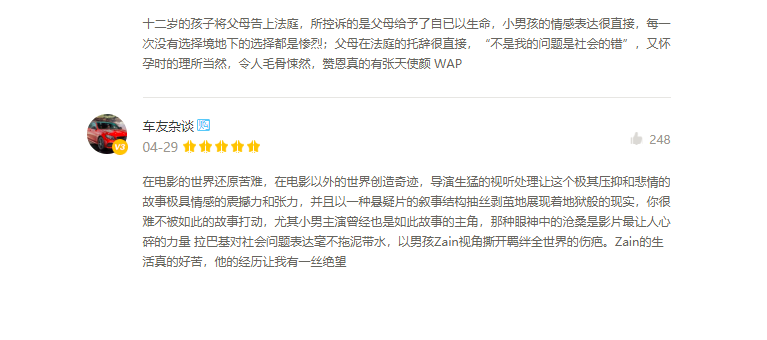
图1 web版不能获得所有评论
图2 手机版可以获得所有评论
- 爬取内容:
本次爬取了评论部分的用户ID、所在城市、用户名、评论、评分、时间六项,共爬取了13778条评论。
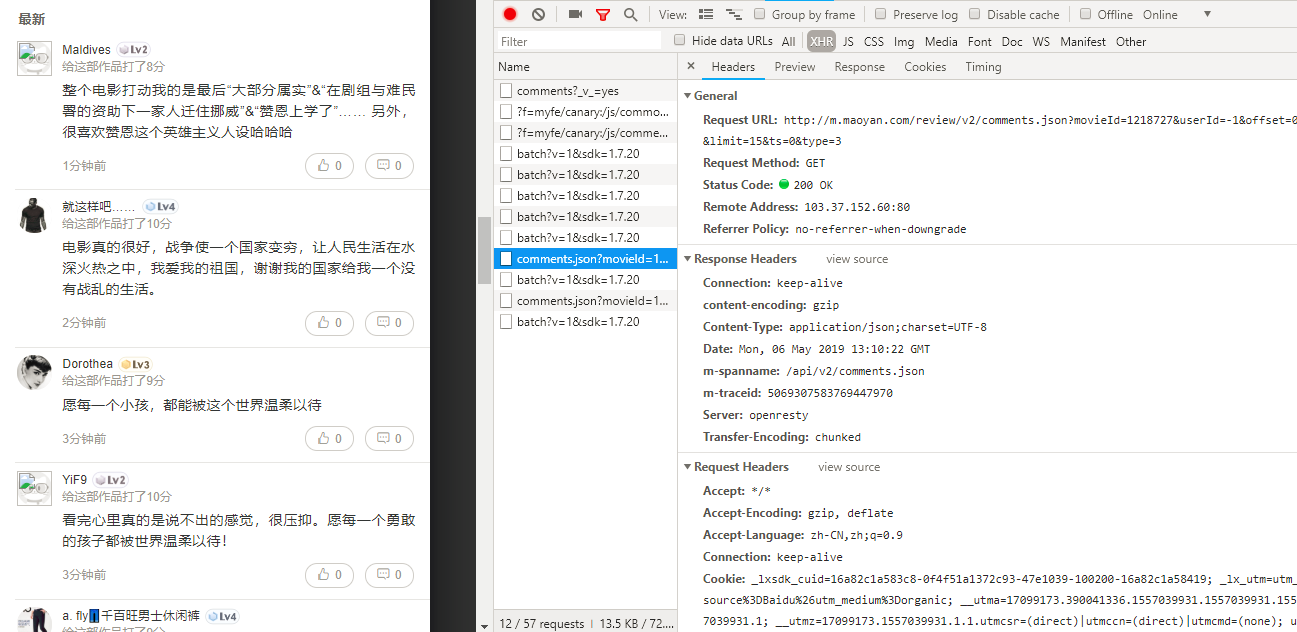
找到爬取的json数据切入口:http://m.maoyan.com/mmdb/comments/movie/1218727.json?_v_=yes&offset=0&startTime=2019-05-03%2022%3A25%3A03
爬取代码如下:
from urllib import request import json # 获取数据,根据url获取 def get_data(url): headers = { '1': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Mobile Safari/537.36', '2': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1', '3': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' } req = request.Request(url, headers=headers) response = request.urlopen(req) if response.getcode() == 200: return response.read() return None def parse_data(html): data = json.loads(html)['cmts'] # 将str转换为json for item in data: comment = { 'id': item['id'], 'nickName': item['nickName'] if 'nickName' in item else '', 'cityName': item['cityName'] if 'cityName' in item else '', # 处理cityName不存在的情况 'content': item['content'].replace('\n', ' ', 10), # 处理评论内容换行的情况 'score': item['score'], 'startTime': item['startTime']if 'startTime' in item else '' } comments.append(comment) return comments if __name__ == '__main__': for d in range(14): for i in range(30): comments = [] html = get_data('http://m.maoyan.com/mmdb/comments/movie/1218727.json?_v_=yes&offset={}&startTime=2019-06-{}%2022%3A25%3A03'.format(i*15,d)) comments = parse_data(html) # df = pd.DataFrame(comments) for item in comments: with open('pinglun.csv', 'a', encoding='utf-8') as f: f.write(str(item['id']) + ';' + item['cityName'] + ';' + item['nickName'] + ';' + item['content'] + ';' + str(item['score']) + ';' + item['startTime'] + '\n') print('爬取中。。。') print(comments)
爬取结果:

- 进行数据分析如下:
1、获取用户评论中热词Top20,并且制作词云
代码如下:
import jieba import pandas as pd comments = [] with open('p.txt', mode='r', encoding='utf-8') as f: rows = f.readlines() for row in rows: comment = row.split(';')[3] if comment != '': comments.append(comment) pl=' '.join(comments) print(' '.join(comments)) ci=['。',' ','我们','知道','看到','自己','起来','什么','他们','一个','看着','没有','看看','就是','怎么','还是','这么','觉得','电影'] for c in ci: mytext = pl.replace(c, "") '''分割出词汇''' words = list(jieba.cut(mytext)) wordDict={} '''统计频率次数''' wordSet=set(words) for w in wordSet: if len(w)>1: wordDict[w] = words.count(w) '''排序''' wordList = list(wordDict.items()) wordList.sort(key=lambda x:x[1],reverse=True) '''输出top20''' for i in range(20): print(wordList[i]) '''保存为csv文件''' pd.DataFrame(data=wordList).to_csv('ciyun.csv',encoding='utf-8')
运行截图如下:

词云显示如下:

2、分析电影评分情况
代码如下:
pf = [] with open('p.txt', mode='r', encoding='utf-8') as f: rows = f.readlines() for row in rows: fenCol = row.split(';')[4] if fenCol != '': pf.append(fenCol) pfDict={} '''统计频率次数''' Set=set(pf) for w in Set: pfDict[w] = pf.count(w) '''排序''' List = list(pfDict.items()) List.sort(key=lambda x:x[1],reverse=True) '''输出''' for key in List: print(key) from pyecharts import Pie pie=Pie("《何以为家》评分占比",width=1000) pie.add('评分情况',['0分','0.5分','1分','1.5分','2分','2.5分','3分','3.5分','4分','4.5分','5分'], [1,12,3,4,4,7,6,18,57,153,629], center=[75, 50], is_random=True,is_legend_show=False, is_label_show=True) pie.render('.\粉丝评分图.html')
运行截图如下:

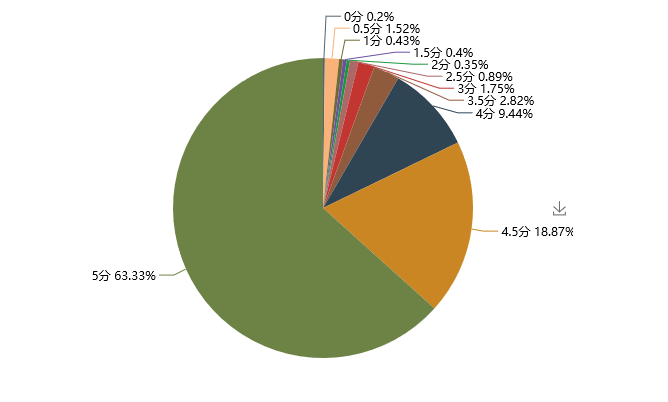
评分情况可视化如下:
- 总结
经过对猫眼电影上《何以为家》这部电影的部分评论的爬取、分析、数据可视化之后,从中我们可以知晓:
1、电影的主题是围绕家庭中父母和孩子的关系展开的;
2、通过对观众评论的分析得知,电影主要给人以生活化、真实的感觉;
3、通过对评分的分析,可以看出总体评分还是非常非常高的,给5分的观众占了大多数,对得起猫眼9.4的评分(2019.5.6);
4、值得一看。

