


MySQL学习基础篇
本文目录
1 数据库相关概念
2 认识MySQL
3 数据库的安装
4 数据库操作
6 数据表操作
7 表的增删改查
8 子查询
9 存储引擎和字符集
数据库相关概念
1、啥是数据库
- 简单理解
所谓的数据库,其实就是有点类似于excel表格,主要就是用来管理数据,对数据进行增删改查的。所以某种程度上来说,excel也可以看成一个简单的数库,只不过是在文件中对数据的读写速度相对较慢,所以现在我们使用数据库管理系统来管理和存储大量的数据
- 官方定义
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库
2、数据库的分类
- 关系型数据库,如 MySQL,Oracle,SqlServer等
- 非关系型数据库,如 Redis,Mongodb,Memcache等
3、关系型数据库的特点
- 数据以表格的形式出现
- 每行为各种记录的数据
- 每列为记录名称所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成database
4、关系型数据库的常用术语
- 数据库: 数据库是一些关联表的集合。
- 数据表: 在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余可以使系统速度更快。(在查询时可能经常需要在多个表之间进行连接查询;而进行连接操作会降低查询速度。例如,学生的信息存储在student表中,院系信息存储在department表中。通过student表中的dept_id字段与department表建立关联关系。如果要查询一个学生所在系的名称,必须从student表中查找学生所在院系的编号(dept_id),然后根据这个编号去department查找系的名称。如果经常需要进行这个操作时,连接查询会浪费很多的时间。因此可以在student表中增加一个冗余字段dept_name,该字段用来存储学生所在院系的名称。这样就不用每次都进行连接操作了。)
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
认识数据库
Mysql是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。由瑞典MySQL AB公司开发,目前属于Oracle公司
MySQL的特点:
- MySQL是开源的,所以你不需要支付额外的费用。
- MySQL使用标准的SQL数据语言形式。
- MySQL可以允许于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等。
- MySQL对PHP有很好的支持,PHP是目前最流行的Web开发语言。
- MySQL支持大型数据库,支持5000万条记录的数据,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB。
- MySQL是可以定制的,采用了GPL协议,你可以修改源码来开发自己的Mysql系统
数据库的安装
- windows版本
1)下载
http://dev.mysql.com/downloads/mysql/
2)解压
如果想要让MySQL安装在指定目录,那么就将解压后的文件夹移动到指定目录,如:C:\mysql-5.7.16-winx64
3)服务端初始化
MySQL解压后的 bin 目录下有一大堆的可执行文件,执行如下命令初始化数据
cd c:\mysql-5.7.16-winx64\bin mysqld --initialize-insecure
4)启动MySQL服务器
由于初始化时使用的【mysqld –initialize-insecure】命令,其默认未给root账户设置密码
# 进入可执行文件目录 cd c:\mysql-5.7.16-winx64\bin # 连接MySQL服务器 mysql -u root -p # 提示请输入密码,直接回车
登录成功后,会出现以下的显示
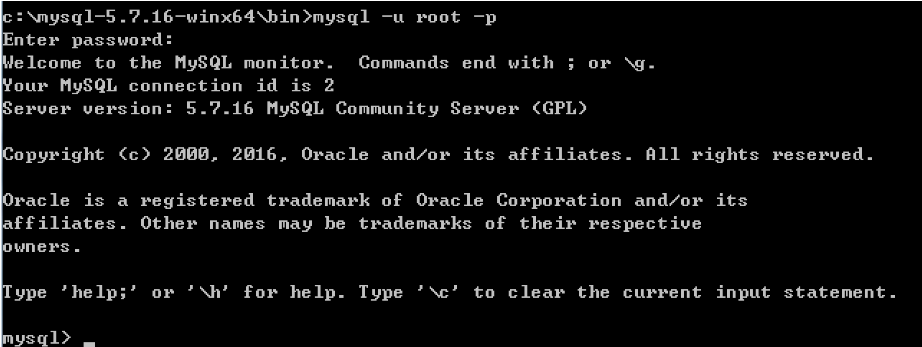
到此为止,MySQL服务端已经安装成功并且客户端已经可以连接上,以后再操作MySQL时,只需要重复上述4、5步骤即可。但是,在4、5步骤中重复的进入可执行文件目录比较繁琐,如想日后操作简便,可以做如下操作:
添加环境变量
将MySQL可执行文件添加到环境变量中,从而执行执行命令即可
右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【将MySQL的bin目录路径追加到变值值中,用 ; 分割】
如:
C:\Program Files (x86)\Parallels\Parallels Tools\Applications;%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem;%SYSTEMROOT%\System32\WindowsPowerShell\v1.0\;C:\Python27;C:\Python35;C:\mysql-5.7.16-winx64\bin
如此一来,以后再启动服务并连接时,仅需:
# 启动MySQL服务,在终端输入 mysqld # 连接MySQL服务,在终端输入: mysql -u root -p
将MySQL服务制作成windows服务
上一步解决了一些问题,但不够彻底,因为在执行【mysqd】启动MySQL服务器时,当前终端会被hang住,那么做一下设置即可解决此问题:
# 制作MySQL的Windows服务,在终端执行此命令: "c:\mysql-5.7.16-winx64\bin\mysqld" --install # 移除MySQL的Windows服务,在终端执行此命令: "c:\mysql-5.7.16-winx64\bin\mysqld" --remove
注册成服务之后,以后再启动和关闭MySQL服务时,仅需执行如下命令:
# 启动MySQL服务 net start mysql # 关闭MySQL服务 net stop mysql
- Linux版本
yum包安装和源码安装两种方式,推荐使用yum包的方式进行安装
源码安装:http://www.cnblogs.com/shangzekai/p/4374489.html
yum安装:
yum install mysql-server service mysqld start mysql -h host -u user -p
数据库操作
1、显示数据库
SHOW DATABASES;
2、创建数据库
# utf-8 CREATE DATABASE 数据库名称 DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
3、使用数据库
USE db_name;
显示当前使用的数据库中所有表:SHOW TABLES;
4、用户管理
创建用户
create user '用户名'@'IP地址' identified by '密码';
删除用户
drop user '用户名'@'IP地址';
修改用户
rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';;
修改密码
set password for '用户名'@'IP地址' = Password('新密码')
PS:用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作(不建议)
5、授权管理
show grants for '用户'@'IP地址' -- 查看权限 grant 权限 on 数据库.表 to '用户'@'IP地址' -- 授权 revoke 权限 on 数据库.表 from '用户'@'IP地址' -- 取消权限
- 授权目标数据库的各类方式
数据库名.* 数据库中的所有 数据库名.表 指定数据库中的某张表 数据库名.存储过程 指定数据库中的存储过程 *.* 所有数据库
- 授权用户的各类方式
用户名@IP地址 用户只能在改IP下才能访问 用户名@192.168.1.% 用户只能在改IP段下才能访问(通配符%表示任意) 用户名@% 用户可以再任意IP下访问(默认IP地址为%)
常见的例子:
grant all privileges on db1.tb1 TO '用户名'@'IP' grant select on db1.* TO '用户名'@'IP' grant select,insert on *.* TO '用户名'@'IP' revoke select on db1.tb1 from '用户名'@'IP'
操作完成之后,不会立即生效,要想立即生效,可以如下操作
flush privileges,将数据读取到内存中,从而立即生效
MySQL数据类型
先学习一个简单的建表语句
create table 表名 (
列1 [列属性 是否为null 默认值],
列2 [列属性 是否为null 默认值],
.....
列n [列属性 是否为null 默认值]
)engine = 存储引擎 charset = 字符集
1、数值型
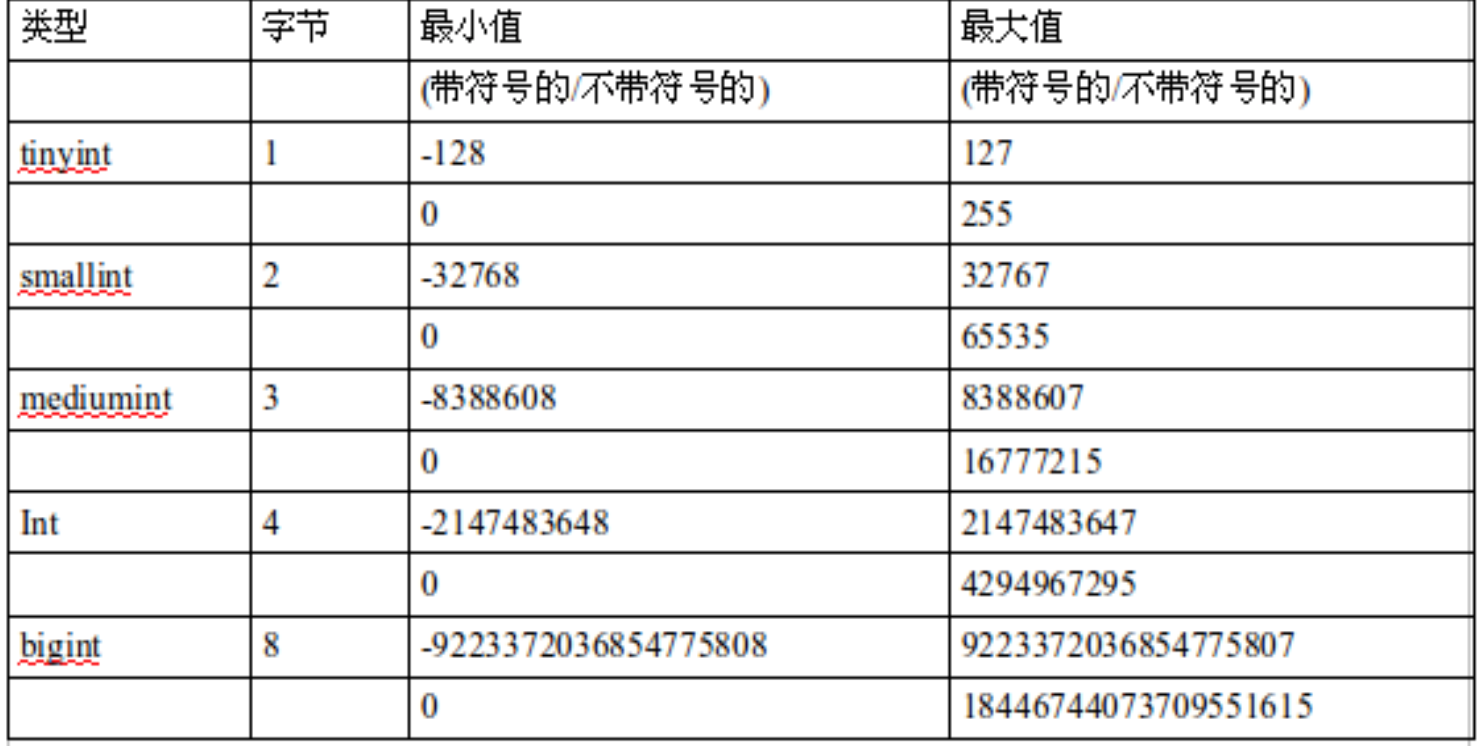
补充:
- unsigned表示为无符号
- float(M,D) 浮点型
- decimal(M,D) 定点型 比float更加的精准
- M: 精度(总位数)D: 标度(小数位)
2、字符串类型
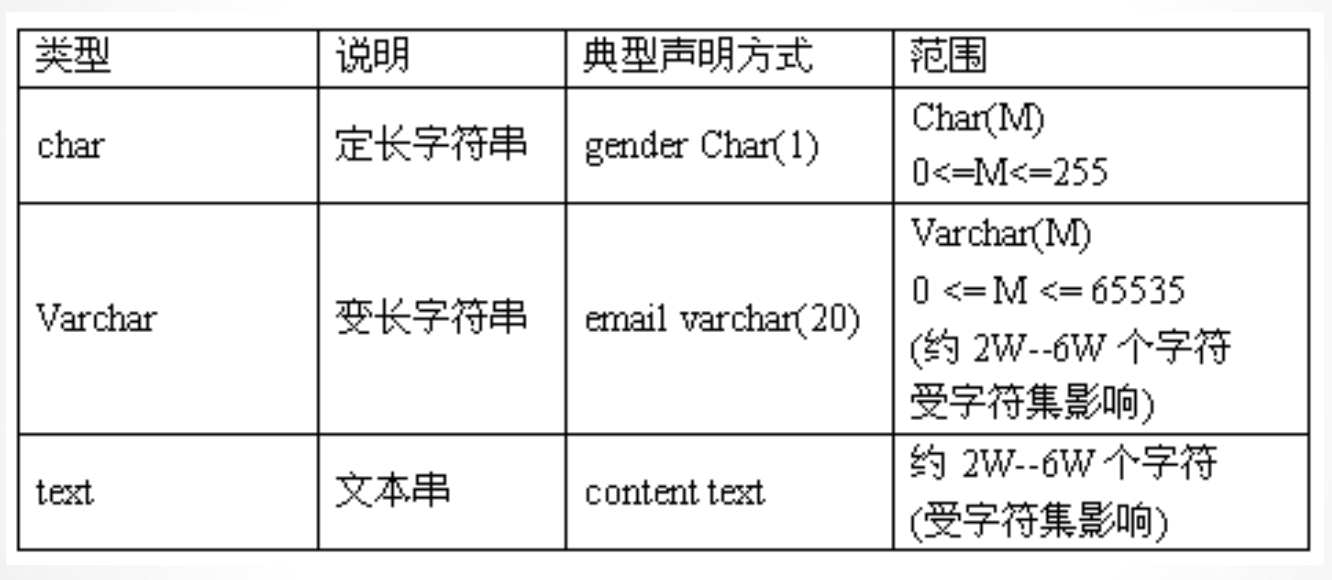
3、时间日期类型

4、特殊的NULL类型
- NULL 不是假,也不是真,而是”空”
- NULL 的判断只能用is null,is not null
- NULL 影响查询速度,一般避免使值为NULL
数据表操作
1、创建表
create table 表名 (
列1 [列属性 是否为null 默认值],
列2 [列属性 是否为null 默认值],
.....
列n [列属性 是否为null 默认值]
)engine = 存储引擎 charset = 字符集
对上述建表语句的解释
- 是否为null
not null - 不可空 null - 可空
- 默认值
创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table tb1(
id int not null defalut 2,
num int not null
)
- 自增
如果为某列设置自增列,插入数据时无需设置此列,默认将自增(表中只能有一个自增列)
create table tb1(
nid int not null auto_increment primary key,
num int null
)
或
create table tb1(
nid int not null auto_increment,
num int null,
index(nid)
)
注意:
对于自增列,必须是索引(含主键)
对于自增可以设置步长和起始值
show session variables like 'auto_inc%'; set session auto_increment_increment = 2; set session auto_increment_offset = 10; shwo global variables like 'auto_inc%'; set global auto_increment_increment = 2; set global auto_increment_offset = 10;
- 主键
一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一
create table tb1(
nid int not null auto_increment primary key,
num int null
)
或
create table tb1(
nid int not null,
num int not null,
primary key(nid,num)
)
- 外键
creat table color(
nid int not null primary key,
name char(16) not null
)
create table fruit(
nid int not null primary key,
smt char(32) null ,
color_id int not null,
constraint fk_cc foreign key (color_id) references color(nid)
)
2、删除表
drop table 表名
3、清空表
delete from 表名 truncate table 表名
4、修改表
添加列:alter table 表名 add 列名 类型
删除列:alter table 表名 drop column 列名
修改列:
alter table 表名 modify column 列名 类型; -- 类型
alter table 表名 change 原列名 新列名 类型; -- 列名,类型
添加主键:
alter table 表名 add primary key(列名);
删除主键:
alter table 表名 drop primary key;
alter table 表名 modify 列名 int, drop primary key;
添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段);
删除外键:alter table 表名 drop foreign key 外键名称
表的增删改查
1、增加
insert into 表 (列名,列名...) values (值,值,值...) insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...) insert into 表 (列名,列名...) select (列名,列名...) from 表
注释:列名可以不写,如果不写,则默认插入所有列的数据
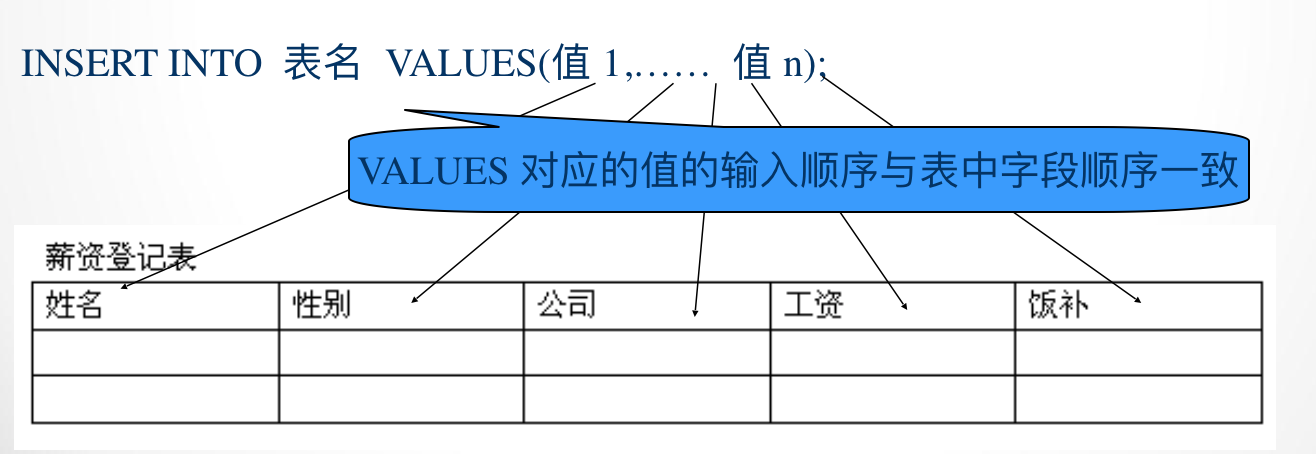
2、删除
delete from 表 delete from 表 where id=1 and name='yb'
3、修改
update 表 set name = 'yb' update 表 set name = 'yb' where id>1
4、基本查询
select * from 表
5、高级查询
- where条件查询
条件为真,则该行取出
select * from 表 where id > 1 select nid,name,gender from 表 where id > 1
注意:where之后可以跟的运算符类型如下

常见的例子
select * from 表 where id > 1 and name != 'yb' and num = 12; select * from 表 where id between 5 and 16; select * from 表 where id in (11,22,33) select * from 表 where id not in (11,22,33) select * from 表 where id in (select nid from 表)
- 通配符匹配
select * from 表 where name like 'y%' - y开头的所有(多个字符串) select * from 表 where name like 'y_' - y开头的所有(一个字符)
- 限制取几条
limit [偏移量], 取出条目 分页应用中最为典型,如第1页取1-20条,第2页取21-40条
select * from 表 limit 5; - 前5行 select * from 表 limit 4,5; - 从第4行开始的5行 select * from 表 limit 5 offset 4 - 从第4行开始的5行(不推荐)
- 排序
对栏目的商品按价格由高到低或由低到高排序
各种排序场合,如取热点新闻,发帖状元等
默认是升序排列
select * from 表 order by 列 asc - 根据 “列” 从小到大排列 select * from 表 order by 列 desc - 根据 “列” 从大到小排列
- 分组
把行按某个字段进行分组
见于统计场合,如按栏目计算帖子数,统计每个人的平均成绩等
select num from 表 group by num select num,nid from 表 group by num,nid select num,nid from 表 where nid > 10 group by num,nid order by nid desc select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid select num from 表 group by num having max(id) > 10 特别的:group by 必须在where之后,order by之前
having和where的异同点:
1). having与where类似,可筛选数据
2). where针对表中的列发挥作用,查询数据
3). having针对查询结果中的列发挥作用,筛选数据
注意:上述查询条件写的时候的顺序
group by > order by > limit
select name,sum(score) from 表 where id > 10 group by score order by age desc limit 2, 10
6、连接查询
- 作用
从2张或多张表中,取出有关联的数据
- 场景
取文章及所在栏目名称,取个人信息及所发布的文章等
- 种类
左连接
右连接
内连接
- 左连接语法
A表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name from A left join B on A.nid = B.nid

- 右连接语法
B表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name from A right join B on A.nid = B.nid
- 内连接语法
内连接是左右连接的交集
select A.num, A.name, B.name from A inner join B on A.nid = B.nid
子查询
子查询就是在原有的查询语句中,嵌入新的查询,来得到我们想要的结果集。
where型子查询
把内层sql语句查询的结果作为外层sql查询的条件
- 典型语法
select * from tableName
where colName = (select colName from tbName where ....)
或
{where colName in (select colName from tbName where ..)}
- 应用场景
查询出某大栏目下的所有商品
存储引擎和字符集
1、存储引擎
设有张马虎,李小心两人,都是地铁口的自行车管理员.每天都有很多人来存取自行车
张马虎的管理方式是:来存自己存,不记录存的是什么车,取时交5毛,也不检查取的是否是自己的车.
李小心呢,则在存取自己车时,记录存车人的特征与自行车的特征,当人来取车,还要小心核一下,人与车的特征是否对应
其实存储引擎和上述的情况都是一样的
数据库对同样的数据,有着不同的存储方式和管理方式
在mysql中,称为存储引擎
- 存储引擎的特点和分类

-
存储引擎的选择
1). 文章,新闻等安全性要求不高的,选myisam
2). 订单,资金,账单,火车票等对安全性要求高的,选用innodb
3). 对于临时中转表,可以用memory型 ,速度最快
MySQL在5.6版本以上,默认的存储引擎就是innodb
2、字符集
字符集是一套符号和编码的规则,不论是在 oracle 数据库还是在 mysql 数据库,都存在字符集的选择问题,而且如果在数据库创建阶段没有正确选择字符集,那么可能在后期需要更换字符集,而字符集的更换是代价比较高的操作,也存在一定的风险,所以,我们推荐在应用开始阶段,就按照需求正确的选择合适的字符集,避免后期不必要的调整
- 查看所有字符集
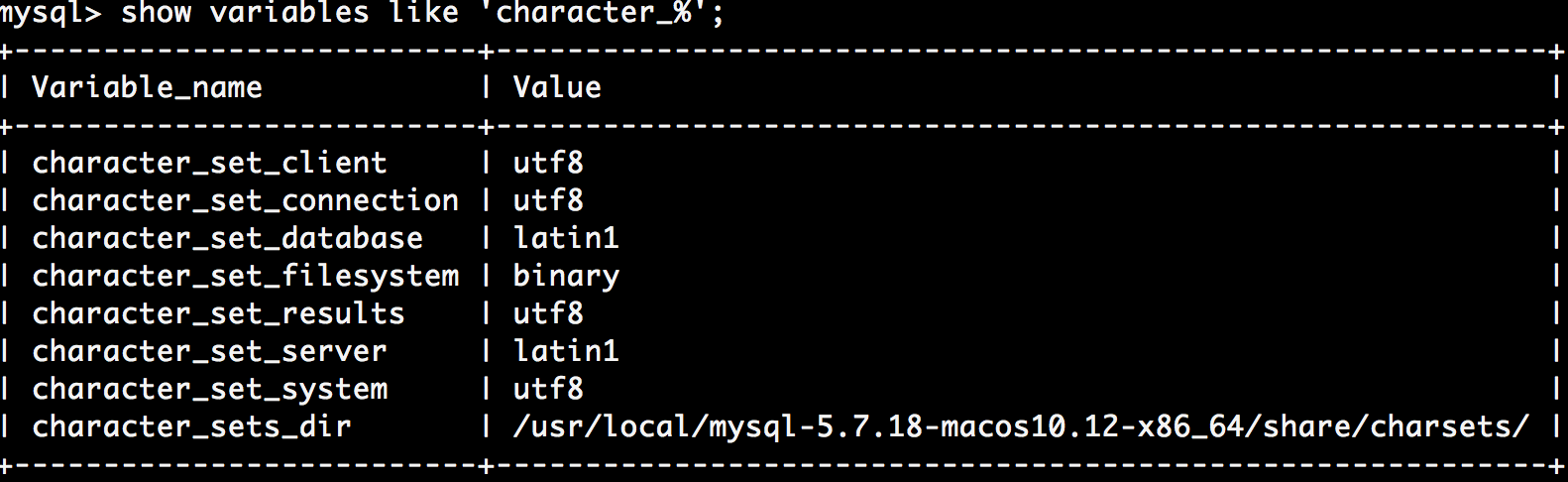
在mysql客户端与mysql服务端之间,存在着一个字符集转换器,来看一下mysql字符集间的转换
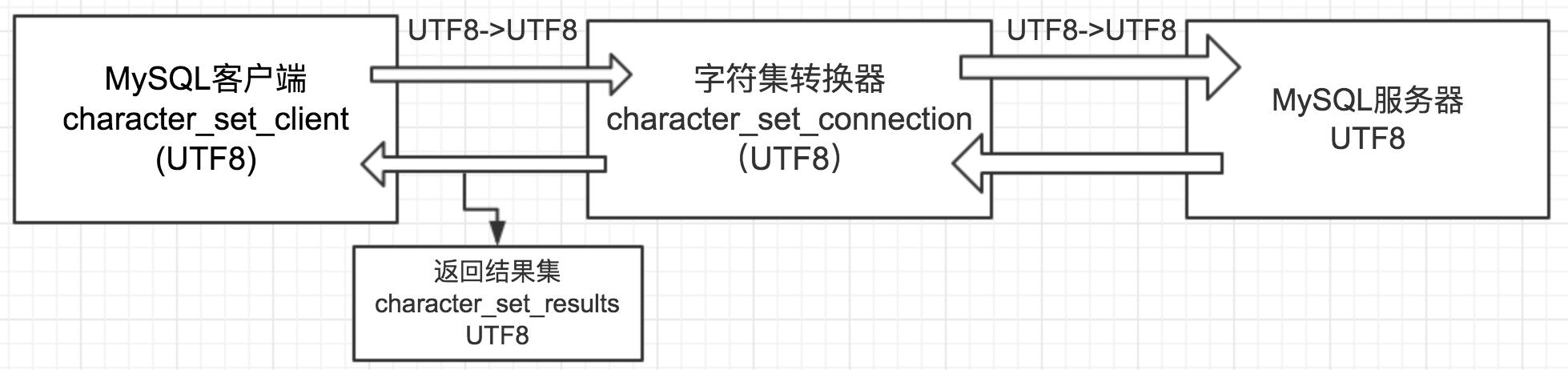
- character_set_client => utf8 (客户端告诉转换器发送过来的是utf8格式的编码)
- character_set_connection => utf8(将客户端传送过来的数据转换成utf8格式)
- character_set_results => utf8 (告诉客户端结果数据的编码是utf8)
注:以上三个字符集可以使用set names utf8来统一进行设置
那为什么会出现乱码?
我们首先来看一下经常用的字符集的详细信息
- latin字符集

- gbk字符集

- utf8字符集
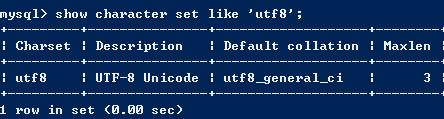
对比以上三幅图可以知道,每种字符集中,用于存储一个字符的最大的字节数目都不同,utf8最大,latin最
小。所以在经过字符集转换器的时候,如果处理不当,会造成数据丢失
比如:我们将character_set_connection的值改为lantin的时候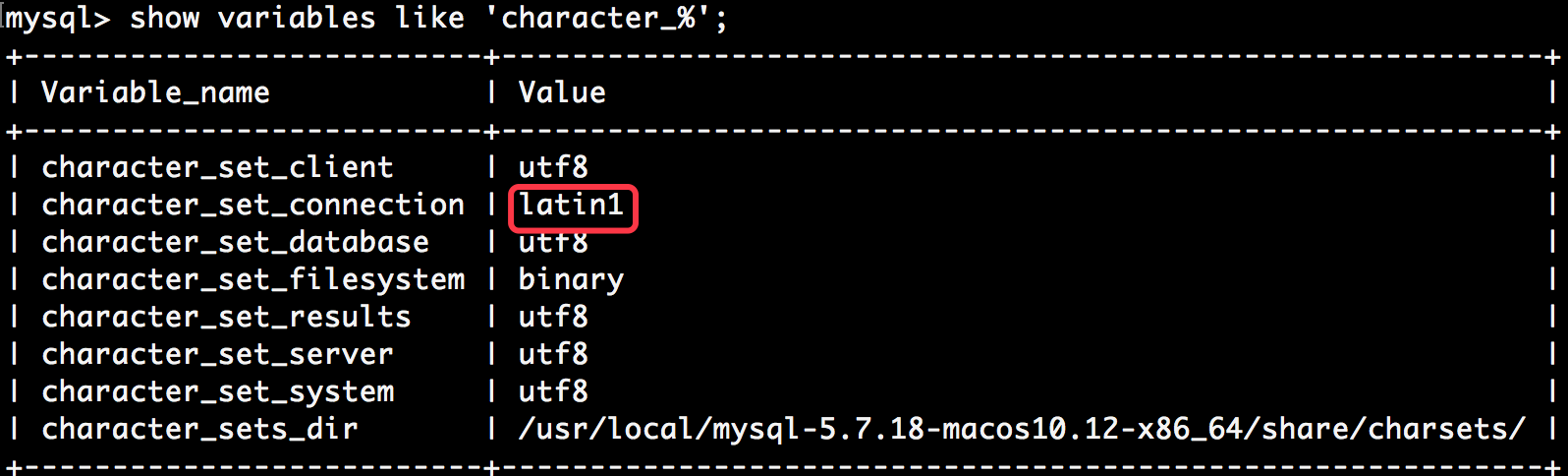
从客户端发送过来的utf8数据,会被转成lantin1格式,因为utf8格式的数据占用的字符数较多,从而会造成数据丢失
- 如何避免以上的情况?
其实非常的简单,就是数据在经过上面三层转换的时候,只要有一个数据的格式和它两个不一样的话,都会出现乱码,因此我们需要确保三者的字符集是一致的
- 设置字符集的两种方法
*使用set names utf8来统一设置,上文已说过 *这种形式的设置只会在当前窗口有效,当窗口关闭后重新打开 CMD 客户端的时候又会出现乱码问题;那么,如何进行一个一劳永逸的设置呢?在 MySQL 的安装目录下有一个 my.ini 配置文件,通过修改这个配置文件可以一劳永逸的解决乱码问题。在这个配置文件中 [mysql] 与客户端配置相关,[mysqld] 与服务器配置相关。默认配置如下:
[mysql] default-character-set=utf8 [mysqld] character-set-server=utf8
修改完成后,service mysql restart重启mysql服务就生效

