

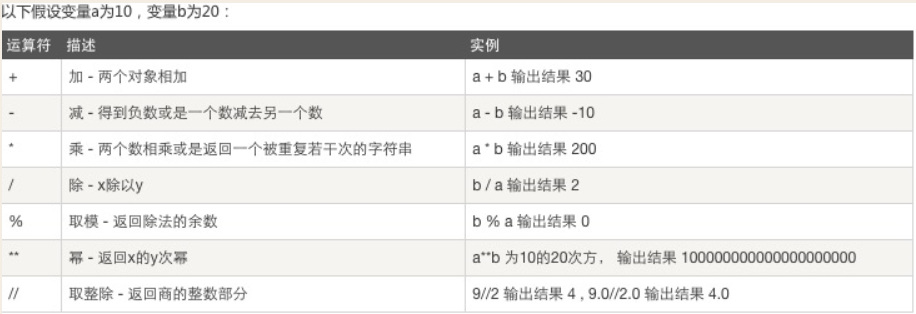
python数据类型
本文目录
整型:int
用途:记录年龄、等级、号码
# int('abadf') #报错 # int('10.1') #报错 # int('101') #int只能将字符串中包含纯数字转成整型


# 其他进制转成十进制 # 二进制:0,1 # 10 #1*(2**1) + 0*(2**0) # # 十进制:0-9 # 371 #3*(10**2) + 7*(10**1) + 1*(10**0) # # 八进制:0-7 # 371 #3*(8**2) + 7*(8**1) + 1*(8**0) # # 十六进制:0-9 A-F # 371 #3*(16**2) + 7*(16**1) + 1*(8**0) # 十进制转成其他进制 # print(bin(12)) # print(oct(12)) #14 =>1*(8**1) + 4*(8**0) # print(hex(16))
浮点型:float
用途:记录身高、体重、薪资
x=10.3 print(id(x)) x=10.4 print(id(x)) """ 2228681159088 2228681158848 """
整型类型:存一个值,不可变
字符类型:str
作用:记录描述性质的数据,比如人的名字、性别、家庭地址、公司简介
定义:在引号内按照从左到右的顺序依次包含一个个字符,引号可以是单引号、双引号、三引号(可以存多行)
注意引号的配对
print("my name is 'sanqiansi'") print('my name is "sanqiansi"')
强调:
1、字符串之间可以相加:
'1111'+2222
2、字符串相加是新申请内存空间然后拷贝相加的字符串到新的空间中,效率不高
print('my name is '+'sanqiansi'+' my age is '+'18')
3、字符串还可以做乘法运算
print('hello'*10) print('='*100)
常用操作+内置方法
#1、按索引取值(正向取+反向取) :只能取 msg='hello world' print(msg[4]) print(msg[-1]) msg[3]='A' 不支持,报错 #2、切片(顾头不顾尾,步长) msg='hello world' # 就是从一个大的字符串中切分出一个全新的子字符串 print(msg[0:5]) print(msg) # 没有改变原值 print(msg[0:5:1]) #步长为1 print(msg[0:5]) #hello print(msg[0:5:2]) #hlo # 了解: print(msg[0:5:1]) msg='hello world' print(msg[5:0:-1]) print(msg[5::-1]) print(msg[-1::-1]) print(msg[::-1]) """ hello olle olleh dlrow olleh dlrow olleh """ #3、长度len msg='hello world' print(len(msg)) #4、成员运算in和not in: 判断一个子字符串是否存在于一个大的字符串中 print('xxx' not in 'yb is shuaige') # 推荐 #5、去掉字符串左右两边的字符strip,不管中间的 user=' yb ' user=' x yb ' user="*******yb********" user=" **+* */***yb* **-*****" print(user.strip("* +/-")) #6、切分split:针对按照某种分隔符组织的字符串,可以用split将其切分成列表,进而进行取值 msg="root:123456:0:0::/root:/bin/bash" res=msg.split(':') print(res) print(res[1]) """ ['root', '123456', '0', '0', '', '/root', '/bin/bash'] 123456 """ #根据需要取某个特定的字段 cmd='dowload|a.txt|3333333' cmd_name,filename,filesize=cmd.split('|') #7、循环 msg='hello' for item in msg: print(item) """ h e l l o """
#1、strip,lstrip,rstrip print('*****yb*****'.lstrip('*')) print('*****yb*****'.rstrip('*')) print('*****yb*****'.strip('*')) #2、lower,upper msg='aABBBBb' res=msg.lower() print(res) print(msg) #3、startswith,endswith msg='yb is shuaige' print(msg.startswith('yb')) print(msg.endswith('ge')) print(msg.endswith('e')) #4、format的三种玩法 print('my name is %s my age is %s' %('yb',18)) print('my name is {name} my age is {age}'.format(age=18,name='yb')) # 了解 print('my name is {} my age is {}'.format(18,'yb')) print('my name is {0} my age is {1}{1}'.format(18,'yb')) #5、split,rsplit msg='get|a.txt|333331231' print(msg.split('|',1)) print(msg.rsplit('|',1)) """ ['get', 'a.txt|333331231'] ['get|a.txt', '333331231'] """ #6、join msg='get|a.txt|333331231' l=msg.split('|') print(l) #['get', 'a.txt', '333331231'] src_msg='|'.join(l) print(src_msg) #get|a.txt|333331231 #7、replace msg='zs say i have one dog,zs is zs hahaha' print(msg.replace('zs','dog',1)) #数字为替换的个数 print(msg) #8、isdigit # 判断字符串中包含的是否为纯数字 print('10.1'.isdigit()) #False age=input('>>: ').strip() if age.isdigit(): age=int(age) #int('asfdsadfsd') if age > 30: print('too big') elif age < 30: print('too small') else: print('you got it') else: print('必须输入数字')
#1、find,rfind,index,rindex,count msg='hello yb is shuaige' print(msg.find('yb')) #找到返回第一个字母的索引位置 print(msg.find('yb',0,3)) #找不到返回-1 print(msg.index('yb')) #6 找到返回索引位置 print(msg.index('yb',0,3)) #找不到直接报错 msg='yb aaa yb' print(msg.find('yb')) #0 print(msg.rfind('yb')) #7 msg='yb aaa yb' print(msg.count('yb')) # 统计一个子字符串在大字符串中出现的次数,返回2 #2、center,ljust,rjust,zfill print('yb'.center(20,'*')) #*********yb********* print('yb'.ljust(20,'*')) #yb****************** print('yb'.rjust(20,'*')) #******************yb print('yb'.zfill(20)) #000000000000000000yb #3、expandtabs:把字符串中的 tab 符号('\t')转为空格,tab 符号('\t')默认的空格数是 8 print('a\tb'.expandtabs(1)) #数字代表是几个空格,不写默认空8个 #4、captalize,swapcase,title print('hello'.capitalize()) #Hello print('hElLo'.swapcase()) #HeLlO print('yb is nb'.title()) #Yb Is Nb #5、is数字系列 #在python3中 num1=b'4' #bytes num2=u'4' #unicode,python3中无需加u就是unicode num3='壹' #中文数字 num4='Ⅳ' #罗马数字 # ''.isnumeric(): unicode,中文数字,罗马数字 print(num2.isnumeric()) #True print(num3.isnumeric()) #True print(num4.isnumeric()) #True # ''.isdigit() :bytes,unicode print(num1.isdigit()) #True print(num2.isdigit()) #True print(num3.isdigit()) #False print(num4.isdigit()) #False #6、is其他 print('abc你'.isalpha()) # 字符串中包含的是字母或者中文字符 #True # 字符串中包含的是字母(中文字符)或数字 print('ab'.isalnum()) #True print('123123'.isalnum()) #True print('ab123'.isalnum()) #True print('ab123啊'.isalnum()) #True
列表类型:list
作用:记录/存多个值,可以方便地取出来指定位置的值,比如人的多个爱好,一堆学生姓名
定义:在[]内用逗号分隔开多个任意类型的值
l1=list('hello') #list就相当于调用了一个for循环依次取出'hello'的值放入列表 print(l1) #['h', 'e', 'l', 'l', 'o'] l2=list({'x':1,'y':2,'z':3}) print(l2) #['x', 'y', 'z'] 只打印出key # list(10000) # 报错
l=[10,3.1,'sanqiansi',['a','b']] # l=list([10,3.1,'sanqiansi',['a','b']]) print(l) print(l[0]) print(l[2]) print(l[3]) print(l[3][1]) l1=['a','b',['c',['d',]]] print(l1[2][1][0]) print(type(l))
使用:
hobbies="read music sleep eat play" hobbies=["read","music","sleep","eat","play"] print(hobbies[2]) students_info=[ ['yb',18,['play',]], ['zs',18,['play','sleep']] ] print(students_info[1][2][0])hobbies="read music sleep eat play" hobbies=["read","music","sleep","eat","play"] print(hobbies[2]) students_info=[ ['yb',18,['play',]], ['zs',18,['play','sleep']] ] print(students_info[1][2][0])
常用操作+内置方法
#1、按索引存取值(正向存取+反向存取):即可存也可以取 l=['yb','zs','yxd'] print(l[0]) l[0]='YB' print(l) print(l[-1]) print(l[3]) #报错 # l[0]='YB' # 只能根据已经存在的索引去改值 # l[3]='xxxxxxxx' #如果索引不存在直接报错 #2、切片(顾头不顾尾,步长) l=['yb','zs','yxd',444,555,66666] print(l[0:5]) #['yb', 'zs', 'yxd', 444, 555] print(l[0:5:2]) #['yb', 'yxd', 555] print(l[::-1]) #[66666, 555, 444, 'yxd', 'zs', 'yb'] #3、长度 l=['yb','zs','yxd',444,555,66666,[1,2,3]] print(len(l)) #7 #4、成员运算in和not in l=['yb','zs','yxd',444,555,66666,[1,2,3]] print('zs' in l) print(444 in l) #5、追加 l=['yb','zs','yxd'] l.append(44444) l.append(55555) print(l) #['yb', 'zs', 'yxd', 44444, 55555] #6、往指定索引前插入值 l=['yb','zs','yxd'] l.insert(0,11111) print(l) #[11111, 'yb', 'zs', 'yxd'] l.insert(2,2222222) print(l) #[11111, 'yb', 2222222, 'zs', 'yxd'] #7、删除 l=['yb','zs','yxd'] # 单纯的删除值: # 方式1: del l[1] # 通用的 print(l) #['yb', 'yxd'] # 方式2: res=l.remove('zs') # 指定要删除的值,返回是None print(l,res) #['yb', 'yxd'] None # 从列表中拿走一个值 res=l.pop(-1) # 按照索引删除值(默认是从末尾删除),返回删除的那个值 print(l,res) #['yb', 'zs'] yxd #8、循环 l=['yb','zs','yxd'] for item in l: print(item) """ yb zs yxd """
l=['yb','yb','zs','yxd',444,555,66666] print(l.count('yb')) #2 print(l.index('yb')) #0 # print(l.index('yxd',0,1))#报错 l.clear() #清空列表 #extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) l=['yb','yb','zs','yxd',444,555,66666] items=['a','b','c'] # items='hello' for item in items: l.append(item) l.extend(items) print(l) #['yb', 'yb', 'zs', 'yxd', 444, 555, 66666, 'a', 'b', 'c', 'a', 'b', 'c'] l=['yb','yb','zs','yxd',444,555,66666] l.reverse() print(l) #[66666, 555, 444, 'yxd', 'zs', 'yb', 'yb'] nums=[3,-1,9,8,11] nums.sort(reverse=True) print(nums) #[11, 9, 8, 3, -1] items=[1,'a','b',2] items.sort()# 报错,整型和字符串不支持一起排序
# 队列:先进先出 l=[] # 入队 l.append('first') l.append('second') l.append('third') print(l) # 出队 print(l.pop(0)) print(l.pop(0)) print(l.pop(0)) """ ['first', 'second', 'third'] first second third """ # 堆栈:先进后出 l=[] # 入栈 l.append('first') l.append('second') l.append('third') print(l) # 出栈 print(l.pop()) print(l.pop()) print(l.pop()) """ ['first', 'second', 'third'] third second first """
用途:记录多个值,当多个值没有改的需求,此时用元组更合适
定义方式:在()内用逗号分隔开多个任意类型的值
常用操作+内置方法
#1、按索引取值(正向取+反向取):只能取 t=('yb',123,['a','b']) print(id(t[0])) print(id(t[1])) print(id(t[2])) t[2][0]='A' print(t) #可以改元组内列表的值 ('yb', 123, ['A', 'b']) # t[0]='YB' 报错,元组不可变 #2、切片(顾头不顾尾,步长) t=(1,2,3,4,5) print(t[0:3]) #(1, 2, 3) print(t) #(1, 2, 3, 4, 5) #4、成员运算in和not in #5、循环 for item in ('a','b','c'): print(item) # 需要掌握的操作 t=('a','b','c','a') print(t.count('a')) print(t.index('a',1,10)) # print(t.index('xxx',1,10)) 报错 #index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。如果包含子字符串返回开始的索引值,否则抛出异常。
字典类型:dict
作用:记录多个key:value值,优势是每一个值value都有其对应关系/映射关系key,而key对value有描述性的功能
定义: 在{}内用逗号分隔开多个key:value元素,其中value可以是任意的数据类型,而key必须是不可变的类型,通常应该是字符串类型
info={'name':'yb','sex':'male','age':18} #info=dict({'name':'yb','sex':'male','age':18})
print(type(info))
print(info['name'])
emp_info=['yb',18,'male',['oldboy',200,'SH']] print(emp_info[2]) print(emp_info[3][0]) emp_info={ 'name':'yb', 'age':18, 'sex':'male', 'comapy_info':{ 'cname':'oldboy', 'emp_count':200, 'addr':'SH' } } print(emp_info['comapy_info']['cname'])
# 用法一: dic=dict(x=1,y=2,z=3) print(dic) #{'x': 1, 'y': 2, 'z': 3} # 用法二: userinfo=[ ['name','yb'], ['age',18], ['sex','male'] ] d={} for k,v in userinfo: #k,v=['name', 'egon'] print(k,v) """ name yb age 18 sex male """ d[k]=v print(d) #{'name': 'yb', 'age': 18, 'sex': 'male'} d=dict(userinfo) print(d) #{'name': 'yb', 'age': 18, 'sex': 'male'}
常用操作+内置方法
#1、按key存取值:可存可取 dic={'name':'yb'} print(dic['name']) #yb dic['name']='YB' print(dic) #{'name': 'YB'} dic['age']=18 print(dic) #{'name': 'YB', 'age': 18} l=['a','b'] l[0]='A' # l[2]='c' 报错,最大索引为1 #2、长度len dic={'name':'yb','age':18,'name':'YB','name':'XXXX'} print(dic) #{'name': 'XXXX', 'age': 18} key一样会覆盖 print(len(dic)) #2 #3、成员运算in和not in:字典的成员运算判断的是key dic={'name':'yb','age':18,} print(18 in dic) #Flase print('age' in dic) #True #4、删除 dic={'name':'yb','age':18,} # 通用 del dic['name'] print(dic) #{'age': 18} # del dic['xxx'] #key不存在则报错 res=dic.pop('age') #删除key对应的value,并返回value print(dic) #{'name': 'yb'} print(res) #18 # dic.pop('xxx') #key不存在则报错 res=dic.popitem() #popitem() 方法随机返回并删除字典中的一对键和值(一般删除末尾对) print(dic) #{'name': 'yb'} print(res) #('age', 18) #5、键keys(),值values(),键值对items() dic={'name':'yb','age':18,} print(dic.keys()) #dict_keys(['name', 'age']) l=[] for k in dic.keys(): l.append(k) print(l) #['name', 'age'] print(list(dic.keys())) #['name', 'age'] print(dic.values()) #dict_values(['yb', 18]) print(list(dic.values())) #['yb', 18] print(dic.items()) #dict_items([('name', 'yb'), ('age', 18)]) print(list(dic.items())) #[('name', 'yb'), ('age', 18)] #6、循环 dic={'name':'yb','age':18,'sex':'male'} for k in dic.keys(): print(k,dic[k]) for k in dic: print(k,dic[k]) for v in dic.values(): print(v) # for k,v in dic.items(): print(k,v) """ name yb age 18 sex male """ """ name yb age 18 sex male """ """ yb 18 male """ """ name yb age 18 sex male """ # 8 dic.get() dic={'name':'yb','age':18,'sex':'male'} # dic=['xxx'] 只有key没有value的字典没有get方法 v=dic.get('name') print(v) #yb v=dic.get('xxx') print(v) #None
# dic.fromkeys()的用法: l=['name','age','sex'] # dic={'name':None,'age':None,'sex':None} dic={} # for k in l: # dic[k]=None # print(dic) dic=dic.fromkeys(l,None) print(dic) """ fromkeys() 函数用于创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值 dict.fromkeys(seq[, value]) """ old_dic={'name':'yb','age':18,'sex':'male'} new_dic={'name':'YB','x':1,'y':2} old_dic.update(new_dic) print(old_dic) #{'name': 'YB', 'age': 18, 'sex': 'male', 'x': 1, 'y': 2} # setdefault:有则不动/返回原值,无则添加/返回新值 dic={'name':'yb','age':18} res=dic.setdefault('name','YB') # 字典中已经存在key则不修改,返回已经存在的key对应的value print(dic) #{'name': 'yb', 'age': 18} print(res) #yb res=dic.setdefault('sex','male') # 字典不存在key则添加"sex":"male",返回新的value print(dic) #{'name': 'yb', 'age': 18, 'sex': 'male'} print(res) #male
#将小于66大于66分开 nums=[11,22,33,44,55,66,77,88,99,90] dic={ 'k1':[], 'k2':[] } for num in nums: if num > 66: dic['k1'].append(num) else: dic['k2'].append(num) print(dic) #{'k1': [77, 88, 99, 90], 'k2': [11, 22, 33, 44, 55, 66]} #统计重复字符串个数 s='hello yb yb say hello zs zs' words=s.split() dic={} print(words) #['hello', 'yb', 'yb', 'say', 'hello', 'zs', 'zs'] for word in words: if word in dic: dic[word]+=1 else: dic[word]=1 print(dic) #{'hello': 2, 'yb': 2, 'say': 1, 'zs': 2}
#上面第二题的解法二 words=s.split() dic={} for word in words: dic.setdefault(word,words.count(word)) print(dic)
用途: 关系运算,去重
定义方式: 在{}内用逗号分开个的多个值
集合的三大特性:
每一个值都必须是不可变类型
元素不能重复
集合内元素无序
s={1,1,1,1,1,1,1,1,1,2,3}
print(s)
#{1, 2, 3}
s={'a','b','c'}
print(s[0])#报错,无序,不支持索引
s=set('hello')
print(s) #{'e', 'h', 'o', 'l'}
print(set(['a','b','c',[1,2]])) #unhashable type: 'list'
# 取及报名python课程又报名linux课程的学员:交集 # print(pythons & linuxs) # print(pythons.intersection(linuxs)) # 取所有报名老男孩课程的学员:并集 # print(pythons | linuxs) # print(pythons.union(linuxs)) # 取只报名python课程的学员: 差集 # print(pythons - linuxs) # print(pythons.difference(linuxs)) # 取只报名linux课程的学员: 差集 # print(linuxs - pythons) # print(linuxs.difference(pythons)) # 取没有同时报名两门课程的学员:对称差集 # print(pythons ^ linuxs) # print(pythons.symmetric_difference(linuxs)) # 是否相等 s1={1,2,3} s2={3,1,2} print(s1 == s2) #True # 父集:一个集合是包含另外一个集合 #issuperset() 方法用于判断指定集合的所有元素是否都包含在原始的集合中,如果是则返回 True,否则返回 False。 s1={1,2,3} s2={1,2} print(s1 >= s2) #True print(s1.issuperset(s2)) #True s1={1,2,3} s2={1,2,4} print(s1 >= s2)#False # 子集 s1={1,2,3} s2={1,2} print(s2 <= s1)#True print(s2.issubset(s1))#True
# 需要掌握操作 s1={1,2,3} s1.update({3,4,5}) print(s1) #{1, 2, 3, 4, 5} s1={1,2,3} res=s1.pop() print(res) #1 s1={1,2,3} res=s1.remove(3) #单纯的删除,返回值为None print(s1)#{1, 2} s1={1,2,3} s1.add(4) print(s1)#{1, 2, 3, 4} s1={1,2,3} s2={1,2} s1.difference_update(s2) #s1=s1.difference(s2) print(s1) #{3} """ difference_update() 方法用于移除两个集合中都存在的元素。 difference_update() 方法与 difference() 方法的区别在于 difference() 方法返回一个移除相同元素的新集合,而 difference_update() 方法是直接在原来的集合中移除元素,没有返回值。 """ s1={1,2,3} res=s1.discard(3) ##单纯的删除,返回值为None print(s1) #{1, 2} print(res) #None # s1.remove(444444) #删除的元素不存在则报错 # s1.discard(444444) #删除的元素不存在不会报错 s1={1,2,3} s2={1,2,4} print(s1.isdisjoint(s2)) #如果两个集合有交集则返回False s1={1,2,3} s2={4,5,6} print(s1.isdisjoint(s2)) #如果两个集合没有交集则返回True
# 集合去重 # 局限性 #1、无法保证原数据类型的顺序 #2、当某一个数据中包含的多个值全部为不可变的类型时才能用集合去重 names=['yb','zs','yb','yb','zs','yxd'] s=set(names) print(s) #{'yxd', 'yb', 'zs'} l=list(s) print(l) #['yxd', 'yb', 'zs'] # 集合去重 # 局限性 #1、无法保证原数据类型的顺序 #2、当某一个数据中包含的多个值全部为不可变的类型时才能用集合去重 stus_info=[ {'name':'yb','age':18}, {'name':'zs','age':73}, {'name':'yxd','age':84}, {'name': 'lb', 'age': 18}, {'name': 'yl', 'age': 18}, {'name': 'yb', 'age': 18}, {'name': 'zs', 'age': 84}, ] # # set(stus_info) # 报错 l=[] for info in stus_info: if info not in l: l.append(info) print(l) stus_info=l print(stus_info) """ [{'name': 'yb', 'age': 18}, {'name': 'zs', 'age': 73}, {'name': 'yxd', 'age': 84}, {'name': 'lb', 'age': 18}, {'name': 'yl', 'age': 18}, {'name': 'zs', 'age': 84}] [{'name': 'yb', 'age': 18}, {'name': 'zs', 'age': 73}, {'name': 'yxd', 'age': 84}, {'name': 'lb', 'age': 18}, {'name': 'yl', 'age': 18}, {'name': 'zs', 'age': 84}] """
tag=True # tag=bool(True) tag=False print(type(tag)) #<class 'bool'>
==比较的是值
age=18
print(age == 18)
is:比较的是id是否相等
x=1 y=x print(x is y)
强调:id相等值一定相等,id不等但是值仍然可以相等
tag=True print(id(tag)) #140711128709456 res=3 > 1 print(id(res)) #140711128709456 res2=1 < 10 print(id(res)) #140711128709456

# 数字之间可以互相比较大小 # print(10 > 3) # print(10 > 3.1) # 而字符串只能与字符串比较大小(按照对应位置的字符参考ASCII表去比较的) # msg1='hello' # msg2='z' # print(msg1 > msg2) # A-Za-z # print('a' > 'Z') # print('Z' > 'Y')= # print(len('hello') > 3) # print('a' > 3) #列表只能与列表比较大小(按照对应位置的值依次比较,对应位置的值必须是相同的类型) # l1=[1,2,3] # l2=[10,] # print(l2 > l1) # l3=[10,2,'b',3] # l4=[10,2,'b','c'] # print(l3 > l4)
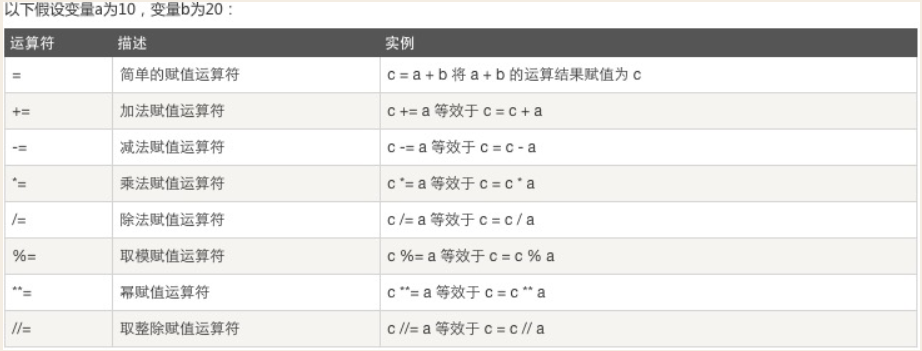
# 赋值运算 # age=18 # 增量赋值 # age+=1 #age=age+1 # print(age) # 链式赋值 # x=100 # y=x # z=x # x=z=y=100 # print(id(x),id(y),id(z)) # 交叉赋值 # m=1000 # n=2000 # # # temp=m # # m=n # # n=temp # n,m=m,n # print(m,n) # 解压赋值 # salaries=[11,22,33,44,55,] # mon1=salaries[0] # mon2=salaries[1] # mon3=salaries[2] # mon4=salaries[3] # mon5=salaries[4] # mon1,mon2,mon3,mon4,mon5=salaries # print(mon1,mon2,mon3,mon4,mon5) # 等号右面包含的值的个数必须与等号左边变量名的个数一致 # mon1,mon2,mon3,mon4,mon5,mon6=salaries # mon1,mon2,mon3,mon4,=salaries # _=3333 # print(_) # mon1,mon2,_,_,_=salaries # mon1,mon2,*_=salaries # print(mon1) # print(mon2) # salaries=[11,22,33,44,55,] # first=salaries[0] # last=salaries[4] # first,_,_,_,last=salaries # first,*_,last=salaries # print(first) # print(last)
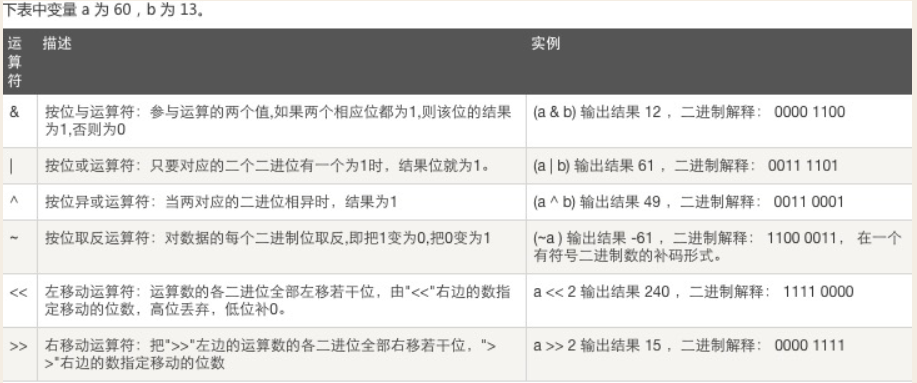
位运算就是直接对整数在内存中的二进制位进行操作。比如,and运算本来是一个逻辑运算符,但整数与整数之间也可以进行and运算。举个例子,6的二进制是110,11的二进制是1011,那么6 and 11的结果就是2,它是二进制对应位进行逻辑运算的结果(0表示False,1表示True,空位都当0处理)。



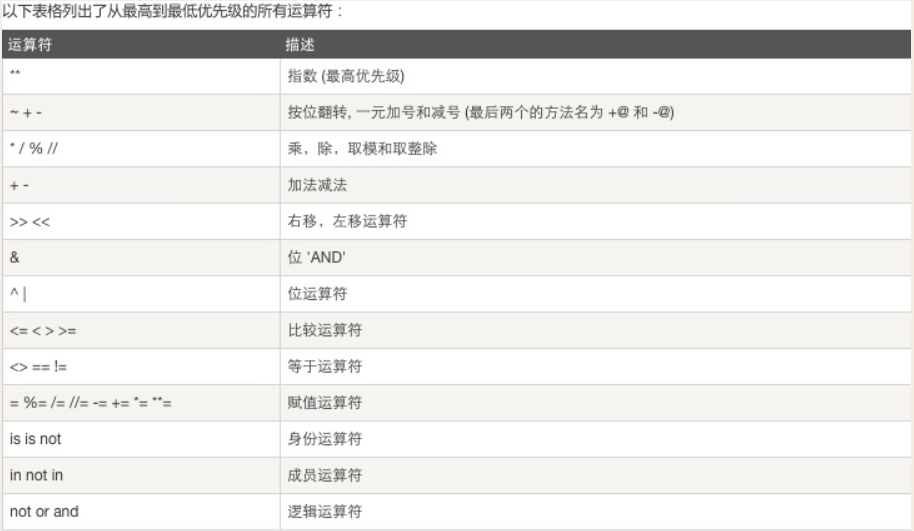
数据类型特性总结
按存值个数分类
原子类型/标量 数字,字符串
容器类型 列表,元组,字典
按可变不可变分类
可变 列表,字典
不可变 数字,字符串,元组,
按访问顺序分类
直接访问 数字
顺序访问(序列类型) 字符串,列表,元组
key值访问 字典
