
文本分类二之文本预处理
一. 文本预处理
文本处理的核心任务是要把非结构化和半结构化的文本转换成结构化的形式,即向量空间模型,在这之前,必须要对不同类型的文本进行预处理,在大多数文本挖掘任务中,文本预处理的步骤都是相似的,基本步骤如下:
1.选择处理的文本范围
2.建立分类文本语料库
2.1训练集语料(已经分好类的文本资源)
目前较好的中文分词语料库有复旦大学谭松波中文分词语料库和搜狗新闻分类语料库。复旦大学的语料库小一些,但是质量很高。
下文中采用的中文语料库。
未分词训练语料库的路径G:\workspace\TextClassification\train_corpus_small
语料目录结构如图:
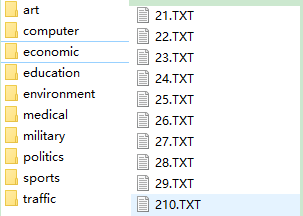
未分词训练语料一共包含10个子目录,目录名称为已预料类别。该类所属的训练文本就位于子目录中,以连续的自然数编号。
2.2测试集语料
待分类的文本语料,可以是训练集的一部分,也可以是外部来源的文本语料。
本文选用的测试集下载
未分词测试语料库的路径G:\workspace\TextClassification\test_corpus
3.文本格式转换
不同格式的文本不论采取何种处理方式,都要统一转换为纯文本文件。
4.检测句子边界
标记句子的结束
二. 分词介绍
将一个汉字序列(句子)切分成一个个单独的词。分词就是将连续的字序列按照一定的规范重新组合成次序列的过程。解决中文分词的算法是基于概率图模型的条件随机场(CRF)。文本结构化表示简单分为四大类:词向量空间模型、主题模型、依存句法的树表示、RDF的图表示。
1.下载安装jieba
2.创建分词,语料库路径\train_corpus_seg
2.1设置字符集,并导入jieba分词包
import sys
import os
import jieba
#配置utf-8输出环境
reload(sys)
sys.setdefaultencoding('utf-8')
#定义两个函数,用于读取和保存文件
def savefile(savepath,content): #保存至文件
fp=open(savepath,"wb")
fp.write(content)
fp.close()
def readfile(path): #读取文件
fp=open(path,"rb")
content=fp.read()
fp.close()
return content
def corpus_segment(corpus_path, seg_path):
catelist=os.listdir(corpus_path)#获取corpus_path下的所有子目录
for mydir in catelist:
class_path=corpus_path+mydir+"/" #拼出子目录的路径
seg_dir=seg_path+mydir+"/" #拼出分词后语料分类目录
if not os.path.exists(seg_dir): #是否存在目录
os.makedirs(seg_dir) #没有,则创建
file_list=os.listdir(class_path) #获取目录下的所有文件
for file_path in file_list: #遍历目录下的文件
fullname=class_path+file_path #拼出文件名全路径
content=readfile(fullname).strip() #读取文件的内容
#删除换行和多余的空格
content=content.replace("\r\n","").strip()
content_seg=jieba.cut(content)#为文件内容分词
#将处理好的文件保存到分词后语料目录
savefile(seg_dir+file_path," ".join(content_seg))
#整个语料库的分词主程序
corpus_path="train_corpus_small/"#未分次训练语料库路径
seg_path="train_corpus_seg/" #分词后训练语料库的路径
corpus_segment(corpus_path,seg_path)
corpus_path="test_corpus/"#未分次测试语料库路径
seg_path="test_corpus_seg/" #分词后测试语料库的路径
corpus_segment(corpus_path,seg_path)
2.2分词的结果

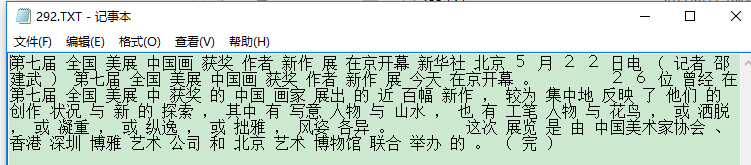
截止目前,我们已经得到了分词后的训练集语料库和测试集语料库,下面我们要把这两个数据集表示为变量,从而为下面程序调用提供服务。在实际应用中,为了后续生成向量空间模型的方便,这些分词后的文本信息还要转换成文本向量信息,并对象化。需要引入Scikit-Learn库的Bunch数据结构。(分类集名称列表、分类标签列表、文件路径、文件词的向量形式)。Bunch就相当于python中的字典。你往里面传什么,它就存什么。
用Bunch表示,就是:
from sklearn.datasets.base import Bunch
bunch = Bunch(target_name=[],label=[],filenames=[],contents=[])
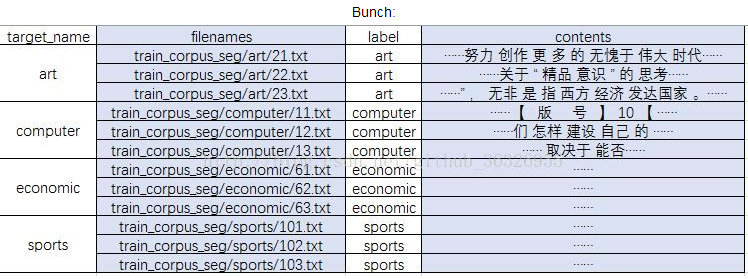
在Bunch对象里面创建了有4个成员:
target_name:是一个list,存放的是整个数据集的类别集合。
label:是一个list,存放的是所有文本的标签。
filenames:是一个list,存放的是所有文本文件的名字。
contents:是一个list,分词后文本文件词向量形式。
如图:
将分好词的文本文件转换并持久化为Bunch类的代码如下:
# -*- coding: utf-8 -*-
import os #python内置的包,用于进行文件目录操作,我们将会用到os.listdir函数
import pickle #导入cPickle包并且取一个别名pickle
from sklearn.datasets.base import Bunch
bunch=Bunch(target_name=[],label=[],filenames=[],contents=[])
def corpus2Bunch(wordbag_path,seg_path):
catelist=os.listdir(seg_path)
bunch.target_name.extend(catelist)
for mydir in catelist:
class_path=seg_path+mydir+"/"
file_list=os.listdir(class_path)
for file_path in file_list:
fullname=class_path+file_path
bunch.label.append(mydir)
bunch.filenames.append(fullname)
bunch.contents.append(readfile(fullname).strip())
file_obj=open(wordbag_path,"wb")
pickle.dump(bunch,file_obj) #将文件bunch保存到file_obj中
file_obj.close()
#对训练集进行Bunch化操作
wordbag_path="train_word_bag/train_set.dat"
seg_path="train_corpus_seg/"
corpus2Bunch(wordbag_path,seg_path)
# 对测试集进行Bunch化操作:
wordbag_path = "test_word_bag/test_set.dat" # Bunch存储路径
seg_path = "test_corpus_seg/" # 分词后分类语料库路径
corpus2Bunch(wordbag_path,seg_path)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号