第4章 锁的优化及注意事项(二)
4.2 Java虚拟机对锁优化所做的努力
- 介绍几种JDK内部的“锁”优化策略。
4.2.1 锁偏向
- 锁偏向是一种针对加锁操作的优化手段。它的核心思想是:如果一个线程获得了锁,那么锁就进入偏向模式。当这个线程再次请求锁时,无须再做任何同步操作。这样就节省了大量有关锁申请的操作,从而 提高了程序性能。因此,对于几乎没有锁竞争的场合,偏向锁有比较好的优化效果,因为连续多次极有可能是同一个线程请求相同的锁。而对于锁竞争比较激烈的场合,其效果不佳。因为在竞争激烈的场合,最有可能的情况是每次都是不同的线程来请求相同的锁。这样偏向模式会失效,因此还不如不启用偏向锁。使用Java虚拟机参数-XX:+UseBiasedLocking可以开启偏向锁。
4.2.2 轻量级锁
- 如果偏向锁失败,虚拟机并不会立即挂起线程。它还会使用一种称为轻量级锁的优化手段。轻量级锁的操作也很轻便,它只是简单地将对象头部作为指针,指向持有锁的线程堆栈的内部,来判断一个线程是 否持有对象锁。如果线程获得轻量级锁成功,则可以顺利进入临界区。如果轻量级加锁失败,则表示其他线程抢先争夺到了锁,那么当前线程的锁请求就会膨胀为重量级锁。
4.2.3 自旋锁
- 锁膨胀后,虚拟机为了避免线程真实地在操作系统层面挂起,虚拟机还会在做最后的努力————自旋锁。由于当前线程暂时无法获得锁,但是什么时候可以获得锁是一个未知数。也许在几个CPU时钟周期后,就可以得到锁。如果这样,简单粗暴地挂起线程可能是一种得不偿失的操作。因此,系统会进行一次赌注:它会假设在不久的将来,线程可以得到这把锁。因此,虚拟机会让当前线程做几个空循环,在经过若干次循环后,如果可以得到锁,那么就顺利进入临界区。如果还不能获得锁,才会真实地将线程在操作系统层面挂起。
4.2.4 锁消除
- 锁消除是一种更彻底的锁优化。Java虚拟机在JIT编译时,通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁。通过锁消除,可以节省毫无意义的请求锁时间。
- 如果不可能存在竞争,为什么程序员还要加上锁呢?这是因为在Java软件开发过程中,我们必然会使用一些JDK的内置API,比如StringBuffer、Vector等。你在使用这些类的时候,也许根本不会考虑这些对 象到底内部是如何实现的。比如,你很有可能在一个不可能存在并发竞争的场合使用Vector。而众所周知,Vector内部使用了synchronized请求锁。比如下面的代码:
public String[] createStrings() {
Vector<String> v = new Vector<String>();
for (int i = 0; i < 100; i++) {
v.add(Integer.toString(i));
}
return v.toArray(new String[]{});
}
- 注意上述代码中的Vector,由于变量v只在createStrings()函数中使用,因此,它只是一个单纯的局部变量。局部变量是在线程栈上分配的,属于线程私有的数据,因此不可能被其他线程访问。所以,在这 种情况下,Vector内部所有加锁同步都是没有必要的。如果虚拟机检测到这种情况,就会将这些无用的锁操作去除。
- 锁消除涉及的一项关键技术为逃逸分析。所谓逃逸分析就是观察其一个变量是否会逃出某一个作用域。在本例中,变量v显然没有逃出createString()函数之外。以此为基础,虚拟机才可以大胆地将v内部的 加锁操作去除。如果createStrings()放回的不是String数组,而是v本身,那么就认为变量v逃逸出了当前函数,也就是说v有可能被其他线程访问。如果是这样,虚拟机就不能消除v中的锁操作。
- 逃逸分析必须在-server模式下进行,可以使用-XX:+DoEscapeAnalysis参数打开逃逸分析。
- 使用-XX:+EliminateLocks参数可以打开锁消除。
4.3 人手一支笔:ThreadLocal
- 除了控制资源的访问外,我们还可以通过增加资源来保证所有对象的线程安全。
- 如果说锁是使用第一种思路,那么ThreadLocal就是使用第二种思路了。
4.3.1 ThreadLocal的简单使用
- 从ThreadLocal的名字上可以看到,这是一个线程的局部变量。也就是说,只有当前线程可以访问。既然是只有当前线程可以访问的数据,自然是线程安全的。
- 下面来看一个简单的实例:
private static final SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static class ParseDate implements Runnable {
int i = 0;
public ParseDate(int i) {this.i = i;}
public void run() {
try {
Date t = sdf.parse("2015-03-29 19:29:" + i % 60);
System.out.println(i + ":" + t);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(10);
for (int i = 0; i < 1000; i++) {
es.execute(new ParseDate(i));
}
}
-
上述代码在多线程中使用SimpleDateFormat来解析字符串类型的日期。如果你执行上述的代码,一般来说,你很可能得到一些异常:

-
出现这些问题的原因,是SimpleDateFormat.parse()方法并不是线程安全的。因此,在线程池中共享这个对象必然导致错误。
-
一种可行的方案是在sdf.parse()前后加锁,这也是我们一般的处理思路。这里我们不这么做,我们使用ThreadLocal为每一个线程都产生一个SimpleDateFormat对象案例:
static ThreadLocal<SimpleDateFormat> tl = new ThreadLocal<SimpleDateFormat>();
public static class ParseDate implements Runnable {
int i = 0;
public ParseDate(int i) {this.i = i;}
public vid run() {
try {
if (tl.get() == null) {
tl.set(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
}
Date t = tl.get().parse("2015-03-29 19:29:" + i % 60);
System.out.println(i + ":" + t);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
- 上述代码第7~9行,如果当前线程不持有SimpleDateformat对象实例。那么就新建一个并把它设置到当前线程中,如果已经持有,则直接使用。
- 从这里也可以看到,为每一个线程人手分配一个对象的工作并不是由ThreadLocal来完成的,而是需要在应用层面保证的。如果在应用上为每一个线程分配了相同的对象实例,那么ThreadLocal也不能保证线程安全。这点也需要大家注意。
- 注意:为每一个线程分配不同的对象,需要在应用层面保证。ThreadLocal只是起到了简单的容器作用。
4.3.2 ThreadLocal的实现原理
- 那ThreadLocal又是如何保证这些对象只被当前线程所访问呢?下面让我们一起深入ThreadLocal的内部实现。
- 我们需要关注的,自然是ThreadLocal的set()方法和get()方法。从set()方法先说起:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
map.set(this, value);
} else {
createMap(t, value);
}
}
- 在set时,首先获得当前线程对象,然后通过getMap()拿到线程的ThreadLocalMap,并将值设入ThreadLocalMap中。而ThreadLocalMap可以理解为一个Map(虽然不是,但是你可以把它简单地理解成HashMap),但是它是定义在Thread内部的成员。注意下面的定义是从Thread类中摘出来的:
ThreadLocal.ThreadLocalMap threadLocals = null;
- 而设置到ThreadLocal中的数据,也正是写入了threadLocals这个Map。其中,key为ThreadLocal当前对象,value就是我们需要的值。而threadLocals本身就保存了当前自己所在线程的所有“局部变量”,也就是一个ThreadLocal变量的集合。
- 在进行get()操作时,自然就是将这个Map中的数据拿出来:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
return (T)e.value;
}
}
return setInitialValue();
}
- 首先,get()方法也是先取得当前线程的ThreadLocalMap对象。然后,通过将自己作为key取得内部的实际数据。
- 在了解了ThreadLocal的内部实现后,我们自然会引出一个问题。那就是这些变量是维护在Thread内部的(ThreadLocalMap定义所在类),这也意味着只要线程不退出,对象的引用将一直存在。
- 当线程退出时,Thread类会进行一些清理工作,其中就包括清理ThreadLocalMap,注意下述代码的加粗部分:
//在线程退出前,由系统回调,进行资源清理
private void exit() {
if (group != null) {
group.threadTerminated(this);
group = null;
}
target = null;
//加速资源清理
threadLocals = null;
inheritableThreadLocals = null;
inheritedAccessControlContext = null;
blocker = null;
uncaughtExceptionHandler = null;
}
- 因此,如果我们使用线程池,那就意味着当前线程未必会退出(比如固定大小的线程池,线程总是存在)。如果这样,将一些大大的对象设置到ThreadLocal中(它实际保存在线程持有的threadLocals Map内),可能会使系统出现内存泄露的可能(你设置了对象到ThreadLocal中,但是不清理它,在使用几次后,这个对象不再有用了,但是它却无法被回收)。
- 此时,如果你希望及时回收对象,最好使用ThreadLocal.remove()方法将这个变量移除。就像我们习惯性地关闭数据库连接一样。如果你确定不需要这个对象了,那么就应该告诉虚拟机,请把它回收掉,防止内存泄露。
- 另外一种有趣的情况是JDK也可能允许你像释放普通变量一样释放ThreadLocal。比如,我们有时候为了加速垃圾回收,会特意写出类似obj=null之类的代码。如果这么做,obj所指向的对象就会更容易地被垃圾回收器发现,从而加速回收。
- 同理,如果对于ThreadLocal的变量,我们也手动将其设置为null,比如tl=null。那么这个ThreadLocal对应的所有线程的局部变量都有可能被回收。先来看一个简单的例子:
public class ThreadLocalDemo_Gc {
static volatile ThreadLocla<SimpleDateFormat> tl = new ThreadLocal<SimpleDateFormat>() {
protected void finalize() throws Throwable {
System.out.println(this.toString() + " is gc");
}
};
static volatile CountDownLatch cd = new CountDownLatch(1000);
public static class ParseDate implements Runnable {
int i = 0;
public ParseDate(int i) {
this.i = i;
}
public void run() {
try {
if (tl.get() == null) {
tl.set(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") {
protected void finalize() throws Throwable {
System.out.println(this.toString() +" is gc");
}
});
System.out.println(Thread.currentThread().getId() + ": create SimpleDateFormat");
}
Date t = tl.get().parse("2015-03-29 19:29:" + i % 60);
} catch (ParseException e) {
e.printStackTrace();
} finally {
cd.countDown();
}
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10000; i++) {
es.execute(new ParseDate(i));
}
cd.await();
System.out.println("mission complete!!");
tl = null;
System.gc();
System.out.println("first GC complete!!");
//在设置ThreadLocal的时候,会清除ThreadLocalMap中的无效对象
tl = new ThreadLocal<SimpleDateFormat>();
cd = new CountDownLatch(10000);
for (int i = 0; i < 10000; i++) {
es.execute(new ParseDate(i));
}
cd.await();
Thread.sleep(1000);
System.gc();
System.out.println("second GC complete!!");
}
}
-
上述案例是为了跟踪ThreadLocal对象以及内部SimpleDateFormat对象的垃圾回收。为此,我们在第3行和第17行,重载了finalize()方法。这样,我们在对象被回收时,就可以看到它们的踪迹。
-
在主函数main中,先后进行了两次任务提交,每次10000个任务。在第一次任务提交后,代码第39行,我们将tl设置为null,接着进行一次GC。接着,我们进行第2次任务提交,完成后,在第50行再进 行一次GC。
-
如果执行上述代码,则最有可能的一种输出如下:


-
注意这些输出的所代表的含义。首先,线程池10个线程都各自创建了一个SimpleDateFormat对象实例。接着进行第一次GC,可以看到ThreadLocal对象被回收了(这里使用了匿名类,所以类名看起来有 点怪,这个类就是第2行创建的tl对象)。接着提交了第2次任务,这次一样也创建10个SimpleDateFormat对象。然后,进行第2次GC。可以看到,在第2次GC后,第一次创建的10个SimpleDateFormat子类实例全部被回收。可以看到,虽然我们没有手工remove()这些对象,但是系统依然有可能回收它们。
-
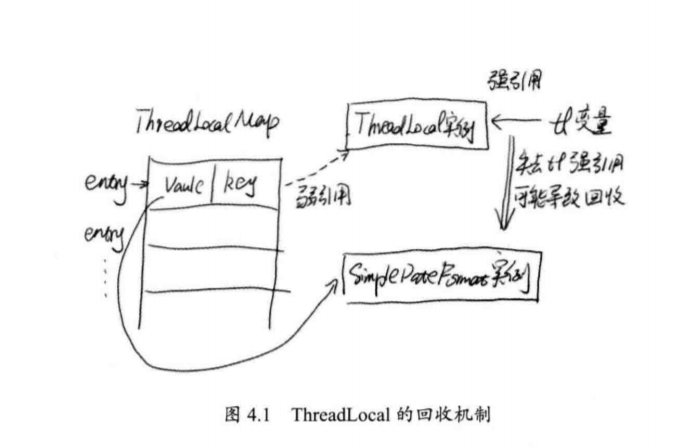
要了解这里的回收机制,我们需要更进一步了解Thread.ThreadLocalMap的实现。之前我们说过,ThreadLocalMap是一个类似HashMap的东西。更精确地说,它更加类似WeakHashMap。
-
ThreadLocalMap的实现使用了弱引用。弱引用是比强引用弱得多的引用。Java虚拟机在垃圾回收时,如果发现弱引用,就会立即回收。ThreadLocalMap内部由一系列Entry构成,每一个Entry都是WeakReference
:
static class Entry extends WeakReference<ThreadLocal> {
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
- 这里的参数k就是Map的key,v就是Map的value。其中k也就是ThreadLocal实例,作为弱引用使用(super(k)就是调用了WeakReference的构造函数)。因此,虽然这里使用ThreadLocal作为Map的key,但是实际上,它并不真的持有TheadLocal的引用。而当ThreadLocal的外部强引用被回收时,ThreadLocalMap中的key就会变成null。当系统进行ThreadLocalMap清理时(比如将新的变量加入表中,就会自 动进行一次清理),就会自然将这些垃圾数据回收。这个结构如图4.1所示。
4.3.3 对性能有何帮助
- 为每一个线程分配一个独立的对象对系统性能也许是有帮助的。这也不一定,这完全取决于共享对象的内部逻辑。如果共享对象对于竞争的处理容易引起性能损失,我们还是应该考虑ThreadLocal为每 个线程分配单独的对象。一个典型的案例就是在多线程下产生随机数。
- 这里,让我们简单测试一下在多线程下产生随机数的性能问题。首先,我们定义一些全局变量:
public static final int GEN_COUNT = 10000000;
public static final int THREAD_COUNT = 4;
static ExecutorService exe = Executors.newFixedThreadPool(THREAD_COUNT);
public static Random rnd = new Random(123);
public static ThreadLocal<Random> tRnd = new ThreadLocal<Random>() {
@Override
protected Random initialValue() {
return new Random(123);
}
};
- 代码第1行定义了每个线程要产生的随机数数量,第2行定了参与工作的线程数量,第3行定义了线程池,第4行定义了被多线程共享的Random实例用于产生随机数,第6~11行定义了由ThreadLocal封装的Random。
- 接着,定义一个工作线程的内部逻辑。它可以工作在两种模式下:
- 第一是多线程共享一个Random(mode = 0),
- 第二是多个线程各分配一个Random(mode = 1)。
public static class RndTask implements Callable<Long> {
private int mode = 0;
public RndTask(int mode) {
this.mode = mode;
}
public Random getRandom() {
if (mode == 0) {
return rnd
} else if (mode == 1) {
return tRnd.get();
} else {
return null;
}
}
@Override
public Long call() {
long b = System.currentTimeMillis();
for (long i = 0; i < GEN_COUNT; i++) {
getRandom().nextInt();
}
long e = System.currentTimeMillis();
System.out.println(Thread.currentThread().getName() +"spend " + (e - b) + "ms");
return e - b;
}
}
- 上述代码第19-27行定义了线程的工作内容。每个线程会产生若干个随机数,完成工作后,记录并返回所消耗的世界。
- 最后是我们的main()函数,它分别对上述两种情况进行测试,并打印了测试的耗时:
public static void main(String[] args) throws InterruptedException, ExecutionException {
Future<long>[] futs = new Future[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
futs[i] = exe.submit(new RndTask(0));
}
long totaltime = 0;
for (int i = 0; i < THREAD_COUNT; i++) {
totaltime += futs[i].get();
}
System.out.println("多线程访问同一个Random实例:" + totaltime + "ms");
//ThreadLocal的情况
for (int i = 0; i < THREAD_COUNT; i++) {
futs[i] = exe.submit(new RndTaks(1));
}
totaltime = 0;
for (int i = 0; i < THREAD_COUNT; i++) {
totaltime += futs[i].get()''
}
System.out.println("使用ThreadLocal包装Random实例:" + totaltime + "ms");
exe.shutdown();
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号