Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的原因是什么?
Spark SQL刚开始也是使用了hive里面一些东西的,但是Spark SQL里面的hive版本肯定要比hive社区理的版本要低一些的,那么hive里面有的东西,比如说原来跑在mapreduce之上已有的一些功能,如果你使用hive on spark的话他是能支持的,但是有一些功能想要直接在Spark SQL上直接用,很可能是没有办法支持,因为Spark SQL里面的一些功能并没有hive完善,毕竟hive已经这么多年,而Spark只是发展了这两三年而已。那么shark终止以后,在Spark界重心就已经在Spark SQL上了,Spark SQl干的事情和原来的shark是有很大的差别的,因为原来的shark依赖了很多hive的东西,那么在sparksql里面就必须要把这个依赖更好的减轻。
2.用spark.read 创建DataFrame
有以下这几种通过spark.read 创建DataFrame: spark.read.text('people.txt')、spark.read.json('people.json')、spark.read.parquet('people.parquet')、spark.read.format('text).load('people.txt')、spark.read.format('json).load('people.json')、spark.read.format('parquet).load('people.parquet')
3.观察从不同类型文件创建DataFrame有什么异同?
通过spark.read.text('people.txt')这种方式创建DataFrame是以值的形式存储的,通过spark.read.json('people.json')这种方式创建DataFrame是以键值对的形式存储的,通过spark.read.parquet('people.parquet')这种方式创建DataFrame是以列族的形式存储的。
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
pandas的DataFrame 是一种表格型数据结构,按照列结构存储,它含有一组有序的列,每列可以是不同的值,但每一列只能有一种数据类型。拥有丰富、灵活、操作简单的 api,在数据量不大的情况下有较好的效果。Spark的DataFrame 是基于 RDD 的一种数据类型,具有比 RDD 节省空间和更高运算效率的优点,对于大数据量的运算,分布式计算能突破 pandas 的瓶颈,而 Spark 则是分布式计算的典型代表。
Spark SQL DataFrame的基本操作
创建:
spark.read.text()
file='file:///usr/local/spark/examples/src/main/resources/people.txt'
df=spark.read.text(file)

spark.read.json()
file='file:///usr/local/spark/examples/src/main/resources/people.json'
df1=spark.read.json(file)

打印数据
df.show()默认打印前20条数据,df.show(n)
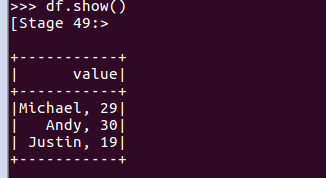

打印概要
df.printSchema()
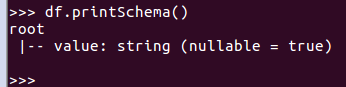
df1.printSchema()
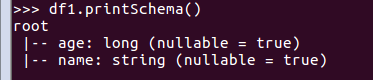
查询总行数
df.count()
df1.count()

df.head(3) #list类型,list中每个元素是Row类
df.head(3)
df1.head(3)

输出全部行
df.collect() #list类型,list中每个元素是Row类
df.collect()
df1.collect()

查询概况
df.describe().show()

df1.describe().show()

取列
df[‘name’]
df1['name']
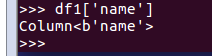
df.name
df1.name

df.select()
df1.select(df1.name).show()

df.filter()
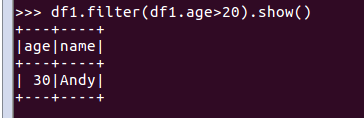
df1.filter(df1.age>20).show()
df.groupBy()
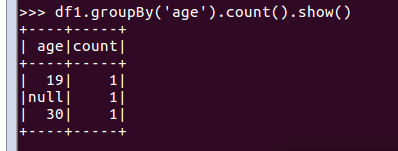
df1.groupBy('age').count().show()
df.sort()
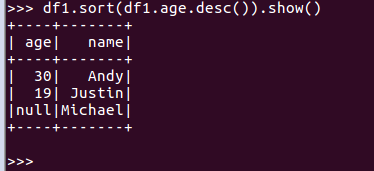
df1.sort(df1.age.desc()).show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号