Kubernetes Pod生命周期
一、Kubernetes Pod 生命周期
-
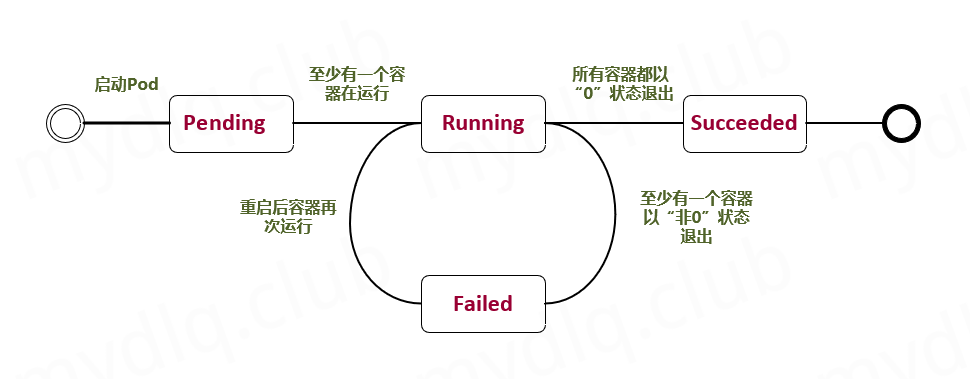
Pending(挂起):Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间。
-
Running(运行中):Pod内所有的容器都已经被创建,且至少一个容器正在处于运行状态、正在启动状态或者重启状态
-
Successed(成功):Pod中所有容器都执行成功后退出,并且没有处于重启的容器
-
Faild(失败):Pod中所有容器都已退出,但是至少还有一个容器退出时为失败状态
-
Unknow(未知):由于一些原因,Pod的状态无法获取,通常是与Pod通信时错误导致的.
二、Pod重启策略
-
Always:只要容器失效退出就重启容器
-
onFailure:当容器以非正常退出后重新启动容器
-
Never:无论容器状态如何,都不重新启动容器
三、Pod的存活与就绪探针
在Kubernetes中Pod是最小的计算单元,而一个Pod又由多个容器组成,相当于每个容器就是一个应用,应用在运行期间,可能因为某也意外情况致使程序挂掉。那么如何监控这些容器状态稳定性,保证服务在运行期间不会发生问题,发生问题后进行重启等机制,就成为了重中之重的事情,考虑到这点 kubernetes 推出了存活探针机制。
有了存活探针后能保证程序在运行中如果挂掉能够自动重启,但是还有个经常遇到的问题,比如说,在 Kubernetes 中启动 Pod,显示明明 Pod 已经启动成功,且能访问里面的端口,但是却返回错误信息。还有就是在执行滚动更新时候,总会出现一段时间,Pod 对外提供网络访问,但是访问却发生 404,这两个原因,都是因为 Pod 已经成功启动,但是 Pod 的的容器中应用程序还在启动中导致,考虑到这点 Kubernetes 推出了就绪探针机制。
Pod两种探针
livenessProbe (存活探测):
指容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为 Success。
readinessProbe (就绪探测):
指容器是否准备好服务请求。当探测成功后才使Pod对外提供网络访问,设置容器 Ready 状态为 true ,如果探测失败,则设置容器的 Ready 状态为 false 。对于被Service管理的Pod,Service 与 Pod 、EndPoind 的关联关系也将基于Pod是否为 Ready 状态进行设置,如果Pod运行过程中 Ready 状态变为 false,则系统自动从 Service 关联的 EndPoint 列表中移除,如果Pod恢复为 Ready 状态,将再被加回 EndPoint 列表,通过这种机制就能防止将流量转发到不可用的Pod上。
该什么时候使用存活(liveness)和就绪(readiness)探针?
如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活探针; kubelet 将根据 Pod 的restartPolicy 自动执行正确的操作。
如果您希望容器在探测失败时被杀死并重新启动,那么请指定一个存活探针,并指定restartPolicy 为 Always 或 OnFailure。
如果要仅在探测成功时才开始向 Pod 发送流量,请指定就绪探针。在这种情况下,就绪探针可能与存活探针相同,但是 spec 中的就绪探针的存在意味着 Pod 将在没有接收到任何流量的情况下启动,并且只有在探针探测成功后才开始接收流量。
如果您希望容器能够自行维护,您可以指定一个就绪探针,该探针检查与存活探针不同的端点。
请注意,如果您只想在 Pod 被删除时能够排除请求,则不一定需要使用就绪探针;在删除 Pod 时,Pod 会自动将自身置于未完成状态,无论就绪探针是否存在。当等待 Pod 中的容器停止时,Pod 仍处于未完成状态。
Pod探针的探测方式与结果
目前 LivenessProbe 和 ReadinessProbe 两种探针都支持下面三种探测方法:
-
ExecAction:在容器中执行指定的命令,如果能成功执行,则探测成功
-
HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP Get方法,如果响应的状态码200-400,则认为容器探测成功
-
TCPSocketAction:通过容器IP地址和端口号执行TCP检查,如果能建立TCP连接,则探测成功
探针探测结果有以下值:
-
Success:表示通过检测
-
Failure:表示未通过检测
-
Unknow:表示检测没有正常进行
Pod探针的相关属性
两种探针有许多字段可选,可以用来更加精确的控制LivenessProbe和ReadinessProbe两种探针的探测:
-
initialDelaySeconds:Pod启动后首次进行检查的等待时间,单位“秒”
-
periodSeconds:检查的间隔时间,默认为10s,单位“秒”
-
timeoutSeconds:探针执行检测请求后,等待响应的超时时间,默认为1s,单位“秒”
-
successThreshold:探针检测失败后认为成功的最小连接成功次数,默认为1s,在liveness探针中必须为1s,最小为1s
-
failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,在readiness探针中,Pod会被标记为未就绪,默认3s,最小值1s
两种探针的区别
总的来说 ReadinessProbe 和 LivenessProbe 是使用相同的探测方式,只是探测后对 Pod 的处置方式不同:
-
ReadinessProbe:当容器检测失败后,将Pod的IP:Port从对应Service关联的EndPoint地址列表中删除
-
LivenessProbe:当检测失败后将容器杀死,并根据Pod的重启策略来决定对应措施
四、探针使用示例
1、LivenessProbe探针使用示例
2、ReadinessProbe探针使用示例
3、ReadinessProbe+LivenessProbe结合使用示例
Pod 配置内存申请和限制
给容器配置内存申请,只要在容器的配置文件里添加resources:requests就可以了。配置限制的话, 则是添加resources:limits.
apiVersion: v1 kind: Pod metadata: name: memory-demo spec: containers: - name: memory-demo-ctr image: vish/stress resources: limits: memory: "200Mi" requests: memory: "100Mi" args: - -mem-total - 150Mi - -mem-alloc-size - 10Mi - -mem-alloc-sleep - 1s
如果不配置内存限制
如果不给容器配置内存限制,那下面的任意一种情况可能会出现:
容器使用内存资源没有上限,容器可以使用当前节点上所有可用的内存资源。
容器所运行的命名空间有默认内存限制,容器会自动继承默认的限制。集群管理员可以使用这个文档 LimitRange来配置默认的内存限制。
五、Pod 声明内存申请和限制
给容器声明一个CPU请求,只要在容器的配置文件里包含这么一句resources:requests就可以, 声明一个CPU限制,则是这么一句resources:limits.
六、Kubernetes 给 Pod 配置服务质量(QoS)等级
QoS 等级
当 Kubernetes 创建一个 Pod 时,它就会给这个 Pod 分配一个 QoS 等级:
- Guaranteed
- Burstable
- BestEffort
1.> 想要给 Pod 分配 QoS 等级为 Guaranteed:
Pod 里的每个容器都必须有内存限制和请求,而且必须是一样的。
Pod 里的每个容器都必须有 CPU 限制和请求,而且必须是一样的
当出现下面的情况时,则是一个 Pod 被分配了 QoS 等级为 Burstable :
2.> 该 Pod 不满足 QoS 等级 Guaranteed 的要求。
Pod 里至少有一个容器有内存或者 CPU 请求。
3.> 要给一个 Pod 配置 BestEffort 的 QoS 等级, Pod 里的容器必须没有任何内存或者 CPU 的限制或请求。
参考文档: http://docs.kubernetes.org.cn/719.html
https://www.cnblogs.com/bigberg/p/13559308.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号