
elasticsearch 学习笔记之一 elasticdump
一、背景
对于数据量较小的数据进行备份还原,可以使用elasticdump工具。
- 数据量较小的情况:由于Elasticdump的工作方式是每次导入导出100条数据,因此它更适合数据量不是特别大的情况。对于大批量数据迁移,可能需要考虑其他的工具或方法。
- 迁移索引个数不多的情况:Elasticdump适合迁移索引个数不多的场景。每个索引的分片数量和副本数量需要单独进行迁移,或者在目标集群中提前创建好索引,然后再进行数据迁移。
- 无需跨集群配置的情况:相比于reindex跨集群操作,Elasticdump无需在ES集群的配置文件elasticsearch.yml中设置授权迁移访问地址(白名单)。
- 使用第三方开源的elasticdump工具,该工具不区分elasticsearch是单节点部署还是集群部署。
二、基本用法
1、支持的使用功能
- 可以一次性备份所有索引下的所有文档数据(--type=data) 且可以还原所有文档数据且支持重复还原,备份数据的时候会碰到:scroll context达到最大值500导致备份失败。 因此大数据量的备份不建议用该工具; 还原的时候耗时也比较久。
- 可以一次性备份所有索引(--type=index),但不支持通过一个命令还原所有索引
- 可以通过通配符备份所有索引下的所有文档数据(--type=data),并一次性还原
- 可以通过通配符备份符合要求的索引(--type=index),但不支持通过通配符命令还原备份下的所有索引
- 可以备份单个索引下的所有文档数据(--type=data)并进行还原 且支持重复还原
- 可以备份单个索引(--type=index),但是还原的时候必须将该索引删除才能还原
2、弊端
- 不支持一次性备份索引的所有数据,包括 index、data。 对于一个索引只能分开备份 index 和 data;
- 索引index的数据(settting\mapping)要想还原,则必须先删除已经存在的索引,否则还原失败。目前单个mapping类型的数据还原也存在问题;
- 通过通配符备份下来的索引数据index,必须要一个一个指定索引进行还原,无法再次通过通配符的形式进行还原;
- 通配符和全量备份下来的index 或 data,只能放在一个文件中,不能按照索引单个文件存储;
- 全量文档数据备份的时候,会碰到scroll context达到最大值500导致备份失败的问题;碰到该问题之后,备份失败重试也会失败。必须将es段的search.max_open_scroll_context 值设置大些;
- 如果想同时备份索引A和索引B的index或者data,目前通过一个命令无法同时备份A和B;
3、语法
elasticdump --input SOURCE --output DESTINATION [OPTIONS]
| 核心选项 | ||||
| 选项名 | 是否必配置 | 用法 | 说明 | 示例 |
| --input | 必配 |
--input=http://es用户名:es密码@ip:port 或 --input=http://es用户名:es密码@ip:port/索引 或 --input=/opt/xxx.json |
源地址 没有配置索引的情况下表示将所有索引导出 配置索引的情况下表示将指定索引指定数据导出 |
elasticdump --input=http://elastic:elasticsearch_422@10.19.223.119:9200 elasticdump --input=http://elastic:elasticsearch_422@10.19.223.119:9200/iotrm_event_event_acs\$0x00030403_2024-10-29 |
| --input-index | 选配 |
--input-index=all --input-index=index/type |
未配置的情况下默认为all | |
| --output | 必配 |
--output=http://es用户名:es密码@ip:port 或 --output=http://es用户名:es密码@ip:port/索引 或 --output=/opt/xxx.json |
目标地址 输入源是包含多个索引(type=index)的文件或地址时,output无法通过 http://es用户名:es密码@ip:port 这个形式还原或者通过通配符的形式还原 type=index数据,只能通过http://es用户名:es密码@ip:port/索引 指定索引的方式一个一个索引数据还原
|
elasticdump --output=http://elastic:elasticsearch_422@10.19.223.119:9200 elasticdump --output=http://elastic:elasticsearch_422@10.19.223.119:9200/iotrm_event_event_acs\$0x00030403_2024-10-29 |
| --output-index | 选配 |
--output-index=all --output-index=index/type |
未配置的情况下默认为all | |
| 可选选项 | ||||
| 选项名 | 是否必配置 | 用法 | 说明 | 示例 |
| --type | 否 |
--type=data type 可选值为:index, settings, analyzer, data, mapping, policy, alias, template, component_template, index_template |
--type 未配置的情况下,默认是data type值只能指定一个,因此不能通过一个命令导出多个数据,比如同时导出数据和索引定义 index的时候会把settings、mapping、alias的数据导出
What are we exporting? |
|
| --big-int-fields | 否 |
Specifies a comma-seperated list of fields that should be checked for big-int support |
||
| --bulkAction | 否 |
Sets the operation type to be used when preparing the request body to be sent to elastic search. |
||
| --ca, --input-ca, --output-ca |
CA certificate. Use --ca if source and destination are identical. |
|||
| --cert, --input-cert, --output-cert |
Client certificate file. Use --cert if source and destination are identical. |
|||
| --csvConfigs |
Set all fast-csv configurations |
|||
| --csvCustomHeaders |
A comma-seperated listed of values that will be used as headers for your data. This param must |
|||
| --csvDelimiter |
The delimiter that will separate columns. |
|||
| --csvFirstRowAsHeaders |
If set to true the first row will be treated as the headers. |
|||
| --csvHandleNestedData |
Set to true to handle nested JSON/CSV data. |
|||
| --csvIdColumn |
Name of the column to extract the record identifier (id) from |
|||
| --csvIgnoreAutoColumns |
Set to true to prevent the following columns @id, @index, @type from being written to the output file |
|||
| --csvIgnoreEmpty |
Set to true to ignore empty rows. |
|||
| --csvIncludeEndRowDelimiter |
Set to true to include a row delimiter at the end of the csv |
|||
| --csvIndexColumn |
Name of the column to extract the record index from |
|||
| --csvLTrim |
Set to true to left trim all columns. |
|||
| --csvMaxRows |
If number is > 0 then only the specified number of rows will be parsed.(e.g. 100 would return th e first 100 rows of data) |
|||
| --csvRTrim |
Set to true to right trim all columns. |
|||
| --csvRenameHeaders |
If you want the first line of the file to be removed and replaced by the one provided in the `cs vCustomHeaders` option |
|||
| --csvSkipLines |
If number is > 0 the specified number of lines will be skipped. |
|||
| --csvSkipRows |
If number is > 0 then the specified number of parsed rows will be skipped |
|||
| --csvTrim |
Set to true to trim all white space from columns. |
|||
| --csvTypeColumn |
Name of the column to extract the record type from |
|||
| --csvWriteHeaders |
Determines if headers should be written to the csv file. |
|||
| --customBackoff | Activate custom customBackoff function. (s3) | |||
| --debug |
Display the elasticsearch commands being used |
|||
| --delete |
Delete documents one-by-one from the input as they are |
|||
| --delete-with-routing |
Passes the routing query-param to the delete function |
|||
| --esCompress |
if true, add an Accept-Encoding header to request compressed content encodings from the server ( if not already present) |
|||
| --fileSize |
supports file splitting. This value must be a string supported by the **bytes** module. |
|||
| --filterSystemTemplates |
Whether to remove metrics-*-* and logs-*-* system templates |
|||
| --force-os-version |
Forces the OpenSearch version used by elasticsearch-dump. |
|||
| --fsCompress |
gzip data before sending output to file. |
|||
| --compressionLevel |
The level of zlib compression to apply to responses. |
|||
| --handleVersion |
Tells elastisearch transport to handle the `_version` field if present in the dataset |
|||
| --headers |
Add custom headers to Elastisearch requests (helpful when |
|||
| --help | This page | |||
| --ignore-errors |
Will continue the read/write loop on write error |
|||
| --ignore-es-write-errors |
Will continue the read/write loop on a write error from elasticsearch |
|||
| --inputSocksPort, --outputSocksPort | Socks5 host port | |||
| --inputSocksProxy, --outputSocksProxy | Socks5 host address | |||
| --inputTransport | Provide a custom js file to use as the input transport | |||
| --key, --input-key, --output-key |
Private key file. Use --key if source and destination are identical. |
|||
| --limit |
How many objects to move in batch per operation |
|||
| --maxRows | supports file splitting. Files are split by the number of rows specified | |||
| --maxSockets |
How many simultaneous HTTP requests can the process make? |
|||
| --noRefresh |
Disable input index refresh. |
|||
| --offset |
Integer containing the number of rows you wish to skip |
|||
| --outputTransport | Provide a custom js file to use as the output transport | |||
| --overwrite |
Overwrite output file if it exists |
|||
| --params |
Add custom parameters to Elastisearch requests uri. Helpful when you for example |
|||
| --parseExtraFields | Comma-separated list of meta-fields to be parsed | |||
| --pass, --input-pass, --output-pass |
Pass phrase for the private key. Use --pass if source and destination are identical. |
|||
| --quiet |
Suppress all messages except for errors |
|||
| --retryAttempts |
Integer indicating the number of times a request should be automatically re-attempted before fai ling |
|||
| --retryDelay |
Integer indicating the back-off/break period between retry attempts (milliseconds) |
|||
| --retryDelayBase | The base number of milliseconds to use in the exponential backoff for operation retries. | |||
| --scroll-with-post |
Use a HTTP POST method to perform scrolling instead of the default GET |
|||
| --scrollId |
The last scroll Id returned from elasticsearch. |
|||
| --scrollTime |
Time the nodes will hold the requested search in order. |
|||
| --searchBody |
Preform a partial extract based on search results |
|||
| --searchBodyTemplate |
A method/function which can be called to the searchBody |
|||
| --searchWithTemplate |
Enable to use Search Template when using --searchBody |
|||
| --size |
How many objects to retrieve |
|||
| --skip-existing |
Skips resource_already_exists_exception when enabled and exit with success |
|||
| --sourceOnly |
Output only the json contained within the document _source |
|||
| --support-big-int | Support big integer numbers | |||
| --templateRegex |
Regex used to filter templates before passing to the output transport |
|||
| --timeout |
Integer containing the number of milliseconds to wait for |
|||
| --tlsAuth | Enable TLS X509 client authentication | |||
| --toLog |
When using a custom outputTransport, should log lines |
|||
| --transform |
A method/function which can be called to modify documents |
|||
| --versionType |
Elasticsearch versioning types. Should be `internal`, `external`, `external_gte`, `force`. |
|||
| AWS独有配置项 | ||||
| --awsAccessKeyId and --awsSecretAccessKey |
When using Amazon Elasticsearch Service protected by |
|||
| --awsChain |
Use [standard](https://aws.amazon.com/blogs/security/a-new-and-standardized-way-to-manage-creden tials-in-the-aws-sdks/) |
|||
| --awsIniFileName |
Override the default aws ini file name when using --awsIniFileProfile |
|||
| --awsIniFileProfile |
Alternative to --awsAccessKeyId and --awsSecretAccessKey, |
|||
| --awsRegion |
Sets the AWS region that the signature will be generated for |
|||
| --awsService |
Sets the AWS service that the signature will be generated for |
|||
| --awsUrlRegex |
Overrides the default regular expression that is used to validate AWS urls that should be signed |
|||
| --s3ACL |
S3 ACL: private | public-read | public-read-write | authenticated-read | aws-exec-read | |
|||
| --s3AccessKeyId |
AWS access key ID |
|||
| --s3Compress |
gzip data before sending to s3 |
|||
| --s3Configs |
Set all s3 constructor configurations |
|||
| --s3Endpoint |
AWS endpoint that can be used for AWS compatible backends such as |
|||
| --s3ForcePathStyle | Force path style URLs for S3 objects [default false] | |||
| --s3Options |
Set all s3 parameters shown here https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/S3.html #createMultipartUpload-property |
|||
| --s3Region | AWS region | |||
| --s3SSEKMSKeyId | KMS Id to be used with aws:kms uploads | |||
| --s3SSLEnabled | Use SSL to connect to AWS [default true] | |||
| --s3SecretAccessKey | AWS secret access key | |||
| --s3ServerSideEncryption | Enables encrypted uploads | |||
| --s3StorageClass |
Set the Storage Class used for s3 |
|||
4、简单示例
4.1 Backup and index to a gzip using stdout
elasticdump \ --input=http://production.es.com:9200/my_index \ --output=$ \ | gzip > /data/my_index.json.gz
4.2 Backup the results of a query to a file
elasticdump \ --input=http://production.es.com:9200/my_index \ --output=query.json \ --searchBody "{\"query\":{\"term\":{\"username\": \"admin\"}}}"
4.3 Import data from S3 into ES (using s3urls)
elasticdump \ --s3AccessKeyId "${access_key_id}" \ --s3SecretAccessKey "${access_key_secret}" \ --input "s3://${bucket_name}/${file_name}.json" \ --output=http://production.es.com:9200/my_index
4.4 Export ES data to S3 (using s3urls)
elasticdump \ --s3AccessKeyId "${access_key_id}" \ --s3SecretAccessKey "${access_key_secret}" \ --input=http://production.es.com:9200/my_index \ --output "s3://${bucket_name}/${file_name}.json"
4.5 Import data from MINIO (s3 compatible) into ES (using s3urls)
elasticdump \ --s3AccessKeyId "${access_key_id}" \ --s3SecretAccessKey "${access_key_secret}" \ --input "s3://${bucket_name}/${file_name}.json" \ --output=http://production.es.com:9200/my_index --s3ForcePathStyle true --s3Endpoint https://production.minio.co
4.6 Export ES data to MINIO (s3 compatible) (using s3urls)
elasticdump \ --s3AccessKeyId "${access_key_id}" \ --s3SecretAccessKey "${access_key_secret}" \ --input=http://production.es.com:9200/my_index \ --output "s3://${bucket_name}/${file_name}.json" --s3ForcePathStyle true --s3Endpoint https://production.minio.co
4.7 Import data from CSV file into ES (using csvurls)
elasticdump \ # csv:// prefix must be included to allow parsing of csv files # --input "csv://${file_path}.csv" \ --input "csv:///data/cars.csv" --output=http://production.es.com:9200/my_index \ --csvSkipRows 1 # used to skip parsed rows (this does not include the headers row) --csvDelimiter ";" # default csvDelimiter is ','
4.8 Backup the results of a query to a file
elasticdump \ --input=http://production.es.com:9200/my_index \ --output=query.json \ --searchBody="{\"query\":{\"term\":{\"username\": \"admin\"}}}"
4.9 Specify searchBody from a file
elasticdump \ --input=http://production.es.com:9200/my_index \ --output=query.json \ --searchBody=@/data/searchbody.json
4.10 Copy a single shard data
elasticdump \ --input=http://es.com:9200/api \ --output=http://es.com:9200/api2 \ --input-params="{\"preference\":\"_shards:0\"}"
Learn more @ https://github.com/taskrabbit/elasticsearch-dump
三、安装
elasticdump 源码地址:https://github.com/elasticsearch-dump/elasticsearch-dump
1、安装 Nodejs
- 进入网站 https://nodejs.org/zh-cn/download/prebuilt-binaries 下载
- 选择linux x86 下载二进制成果物包(这个根据实际情况自行选择)
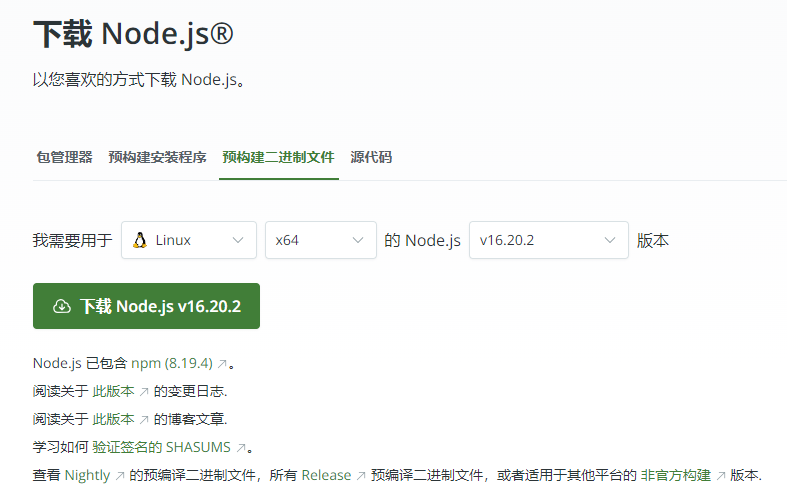
- 远程到 linux 服务器上,将下载的 node-v16.20.2-linux-x64.tar.xz node压缩包 上传到 /opt/tmp上
- cd /opt/tmp
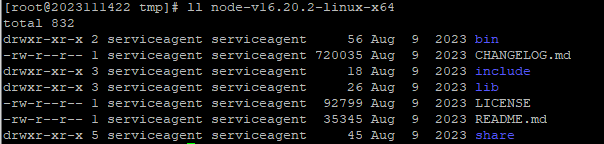
- tar -xf node-v16.20.2-linux-x64.tar.xz

- 解压之后的目录结构为

- 将环境变量设置到当前的远程 shell 上,如果要永久生效,可以直接更改环境变量文件(在 /etc/profile 文件中添加环境变量,再使用 source /etc/profile 进行生效)
- export NODE_HOME=export NODE_HOME=/opt/tmp/node-v16.20.2-linux-x64
- export PATH=export PATH=$PATH:$NODE_HOME/bin
- 检查是否生效
- node --version

-
-
- npm --version
-

2、安装 npm
- npm 已经集成在了nodejs 二进制成果物里面了,按照 第1 章节去安装nodejs 的过程中,实际上已经将npm 安装好了,通过执行命令 npm --version 就可以看到安装的npm 版本号
- npm github 地址为:https://github.com/npm/cli/releases/tag/v10.9.0
参考文章:
https://blog.csdn.net/qq_32894641/article/details/136388906
3、离线安装 elasticdump
如果 elasticdump 运行的服务器是无法连接网络的,此时需要先找一台可以连接上网络的服务器先在线安装 elasticdump ,然后通过 npm-pack-all 对其进行打包,再将打包后的 elasticdump 放置到 目标服务器上,再通过 npm 安装。
在线安装 elasticdump 所在服务器 也必须先按照 1、2 章节内容 安装 nodejs 以及 npm.
3.1、安装 npm-pack-all(要求linux服务器能够连接上网络)
npm-pack-all是一个Node.js的工具,用于将项目中的依赖项打包成tgz(tarball)文件。这些tgz文件是npm包的分发格式,可以被其他开发者下载并安装到他们的项目中。
- 打包项目依赖:npm-pack-all可以遍历项目的node_modules目录,将其中的每个依赖项单独打包成一个tgz文件。这样,你就可以将这些文件分享给其他开发者,或者将它们上传到npm仓库中供其他人使用。
- 忽略指定依赖:npm-pack-all允许你指定要忽略的依赖项。这对于那些你不想分享或上传的依赖项非常有用。
- 自定义输出目录:你可以使用npm-pack-all将打包后的tgz文件输出到指定的目录,方便你进行管理和分发。
安装(前提条件 npm 已经安装)
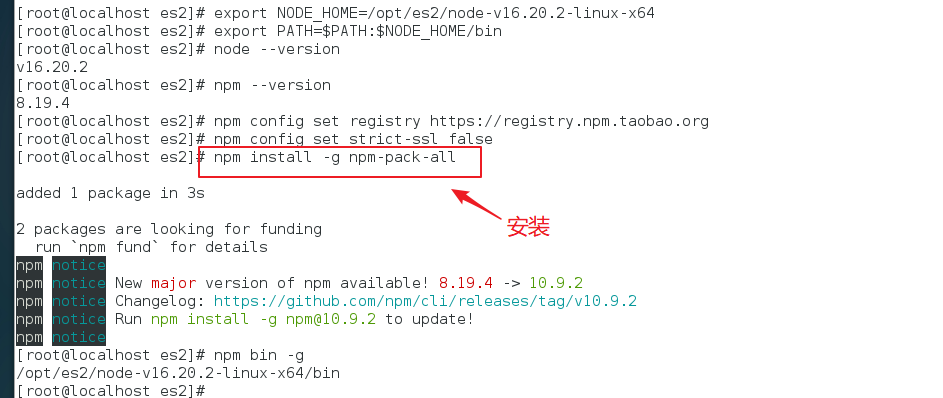
- 设置镜像仓库
npm config set registry https://registry.npm.taobao.org
- 下载依赖有报错的话执行下这个
npm config set strict-ssl false
- npm install -g npm-pack-all #全局安装 npm-pack-all
- npm bin -g # 查看npm/node安装位置

3.2、通过 npm 在线安装 elasticdump
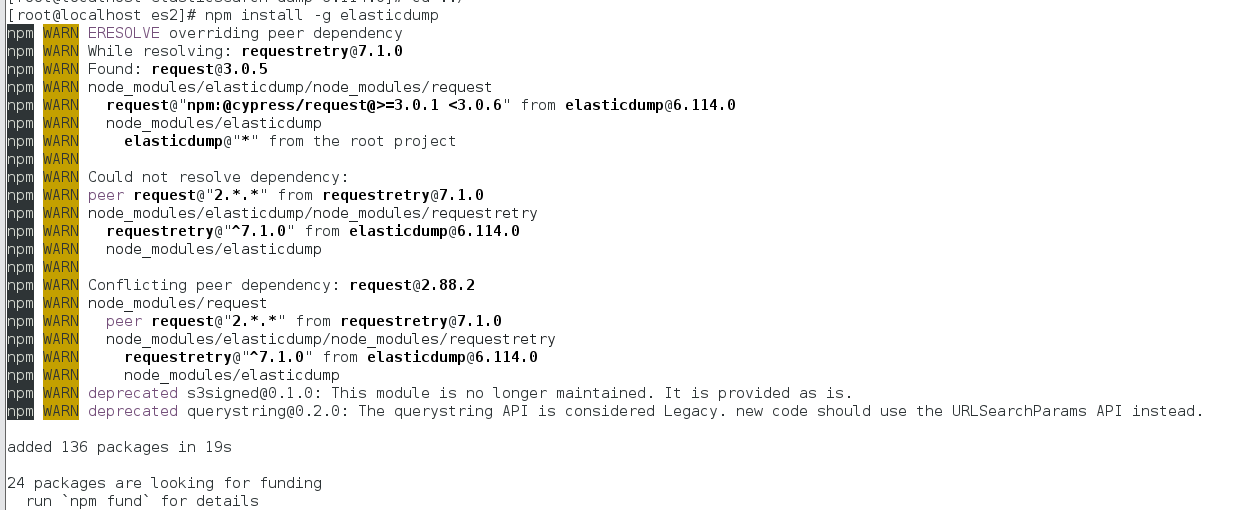
- npm install -g elasticdump
该命令会安装最新的elasticdump版本
- 查看安装位置
- npm bin -g (默认是安装在 nodejs 的 bin 目录下)
- ll nodejs安装目录/bin,可以看到安装好的 elasticdump 工具,对应的实际路径在 nodejs目录/lib/node_modules/elasticdump 目录下

- 通过 npm-pack-all 打包 elasticdump 安装后的成果物
- cd nodejs安装目录/lib/node_modules/elasticdump
- npm-pack-all
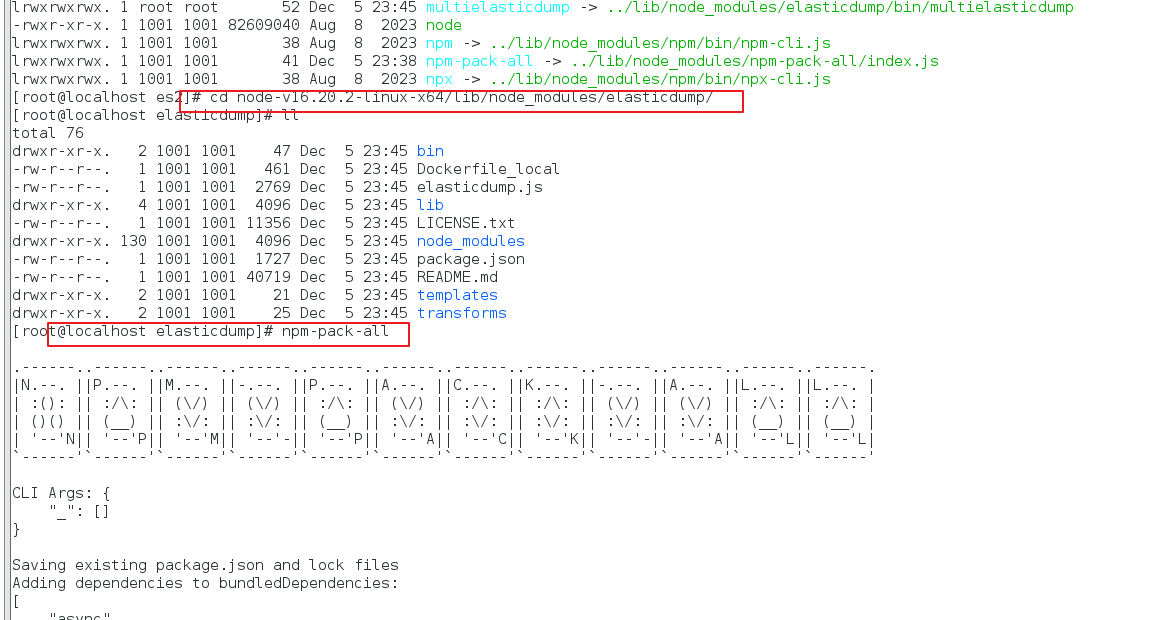
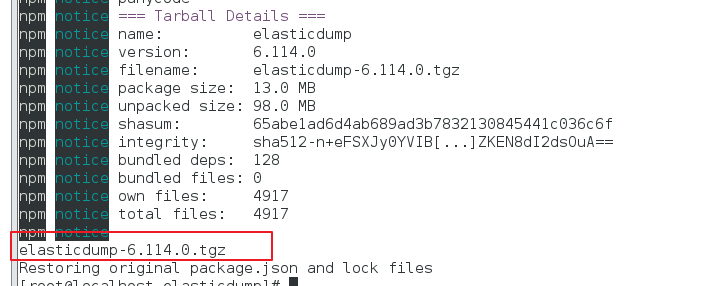
- 可以看到打包后的 压缩名为:elasticdump-6.114.0.tgz。 在 nodejs安装目录/lib/node_modules/elasticdump 目录下

3.3 将elasticdump 安装到离线服务器上
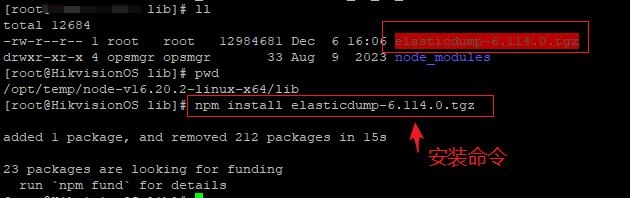
- 将 elasticdump-6.114.0.tgz 上传到 离线服务器上 /opt/tmp/node-v16.20.2-linux-x64/lib/ 下,lib 下存在目录 node_modules
- cd /opt/tmp/node-v16.20.2-linux-x64/lib/
- npm install /opt/tmp/elasticdump-6.114.0.tgz
- npm root #查找 node_modules 所在位置。 显然本次操作,node_moudles 就是在 /opt/tmp/node-v16.20.2-linux-x64/lib 下面
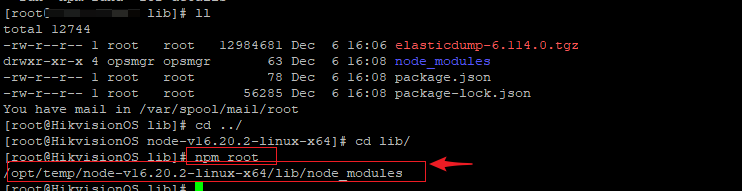
- elasticdump 在 node_modules/elasticdump 下
- 设置环境变量
- export ELASTIC_DUMP_HOME=/opt/tmp/node-v16.20.2-linux-x64/lib/node_modules/elasticdump
- export PATH=$PATH:$ELASTIC_DUMP_HOME/bin
- elasticdump --help #检查是否安装好可使用
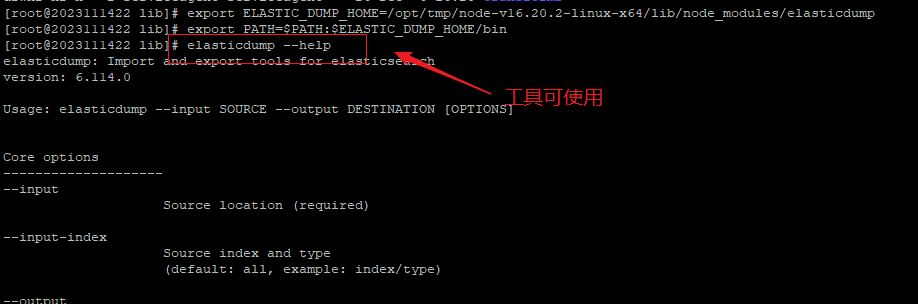
四、实战
1、对所有索引下的数据进行备份
elasticdump --overwrite --input=http://elastic:elasticsearch_422@10.19.223.119:9200/ --output=/opt/tmp/wf/data/es_dump_all/data_all.json --limit=10000 --- --type参数未指定的时候,默认是data


示例显示导出了 2685006条数据
注意:使用该命令导出所有数据会遇到该问题 ---- 创建太多的 scroll contexts ,默认为500

虽然使用了scroll 分页方式进行了查询,但是分页查询太多,导致超过上限。。 需要更改 search.max_open_scroll_context 配置值,默认是500
因此不建议 使用该工具查询大数据量的数据。
2、对所有索引下的数据进行还原
elasticdump --overwrite --output=http://elastic:TZQSHMX8zPOaezaT@10.19.214.13:9200/ --input=/opt/tmp/wf/data/es_dump_all/data_all.json --limit=10000 --- --type参数未指定的时候,默认是data

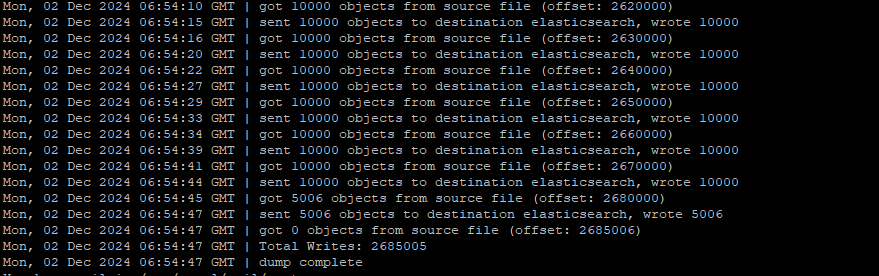
示例显示还原了 2685005 数据耗费了37分钟左右
3、指定索引下的数据进行备份
导出备份 iotrm_event_event_acs$0x00030403_2024-10-29 索引下的所有数据,注意:这里$,在命令行上转为\$
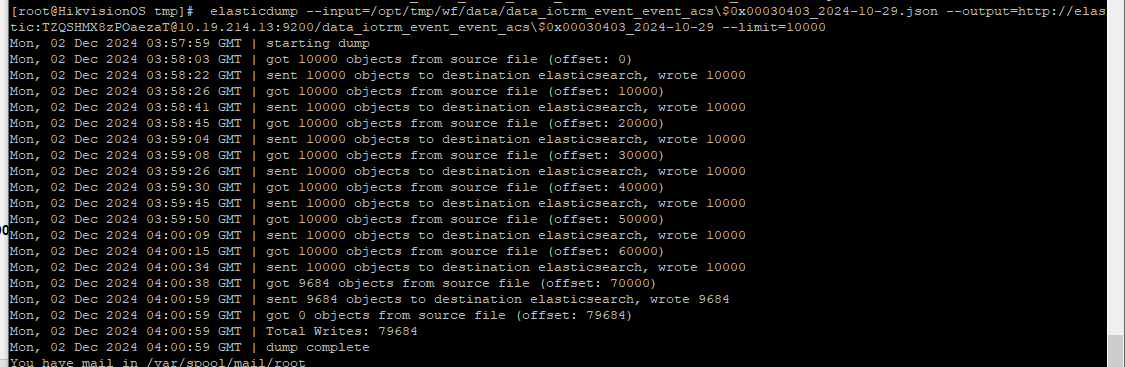
elasticdump --overwrite --input=http://elastic:elasticsearch_422@10.19.223.119:9200/iotrm_event_event_acs\$0x00030403_2024-10-29 --output=/opt/tmp/wf/data/data_iotrm_event_event_acs\$0x00030403_2024-10-29.json --limit=10000 (--type不指定的情况下,默认导出data数据)
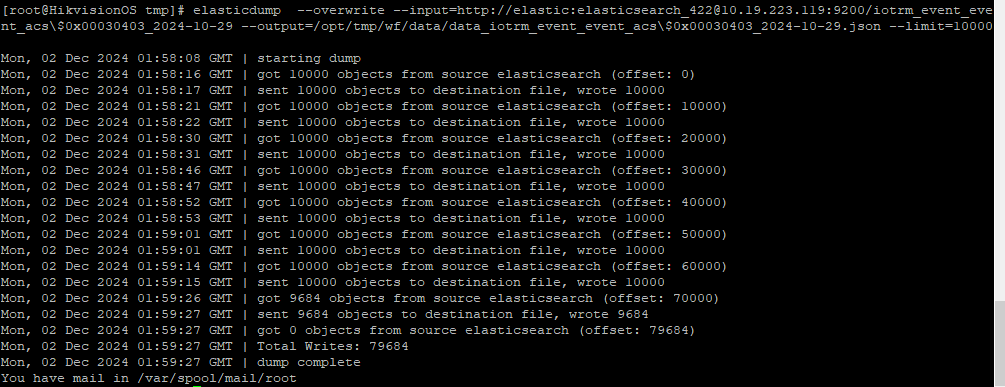
这里导出了 79684条数据
4、指定索引下的数据进行还原
将备份文件中对应的 iotrm_event_event_acs$0x00030403_2024-10-29 索引数据导入到elasticsearch软件中
elasticdump --input=/opt/tmp/wf/data/data_iotrm_event_event_acs\$0x00030403_2024-10-29.json --output=http://elastic:TZQSHMX8zPOaezaT@10.19.214.13:9200/data_iotrm_event_event_acs\$0x00030403_2024-10-29 --limit=10000 ---- 将iotrm_event_event_acs\$0x00030403_2024-10-29索引下的数据还原到另外一个不存在的索引data_iotrm_event_event_acs\$0x00030403_2024-10-29,此时会自动创建这个不存在的索引;但是该索引对应的settting、mapping 均使用默认的。
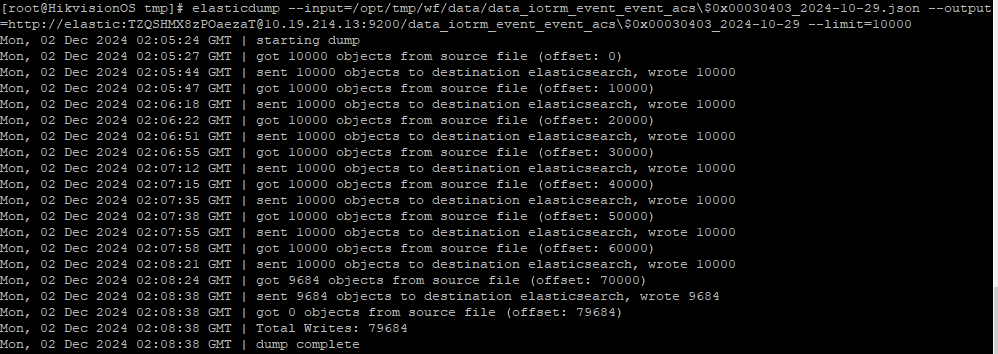
使用elastichead可以看到导入的数据 79684 条
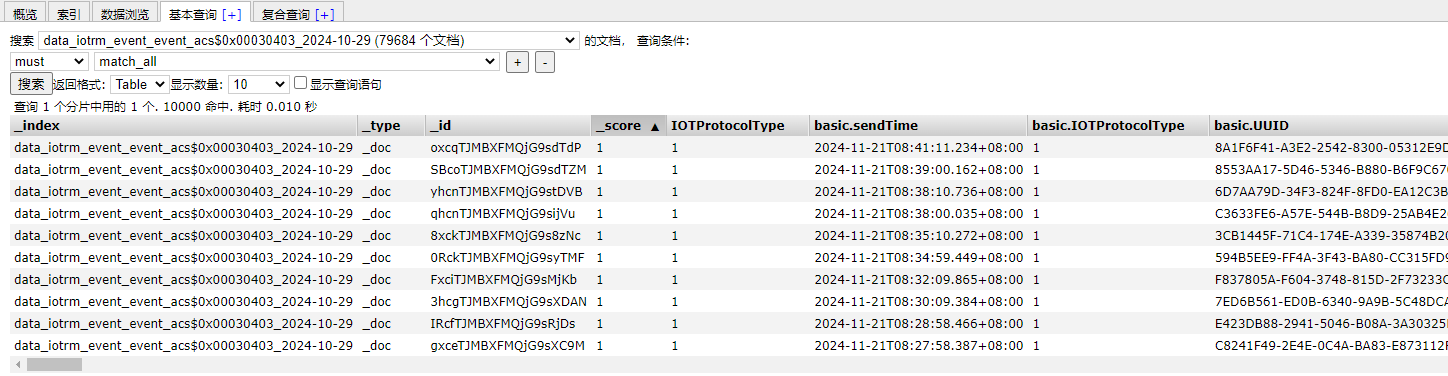
对该索引下的数据 增删改数据之后(修改了oxcqTJMBXFMQjG9sdTdP 数据, 删除了ID为SBcoTJMBXFMQjG9sdTZM/的数据,新增 docId 为1的数据),然后再导入,看下效果
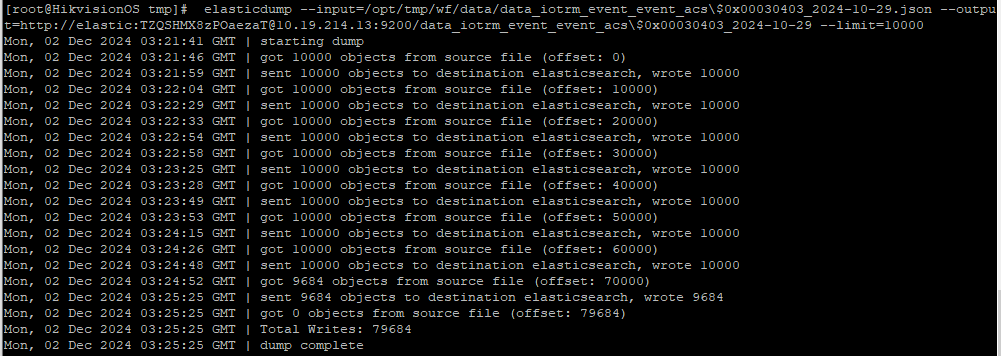
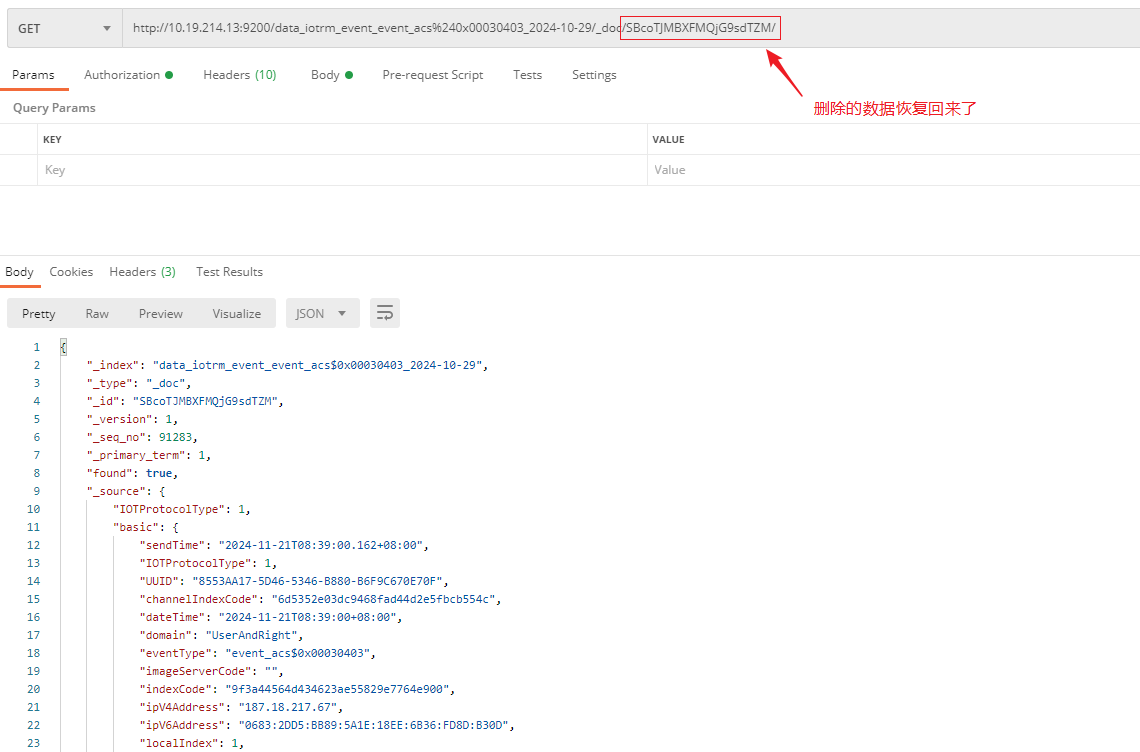
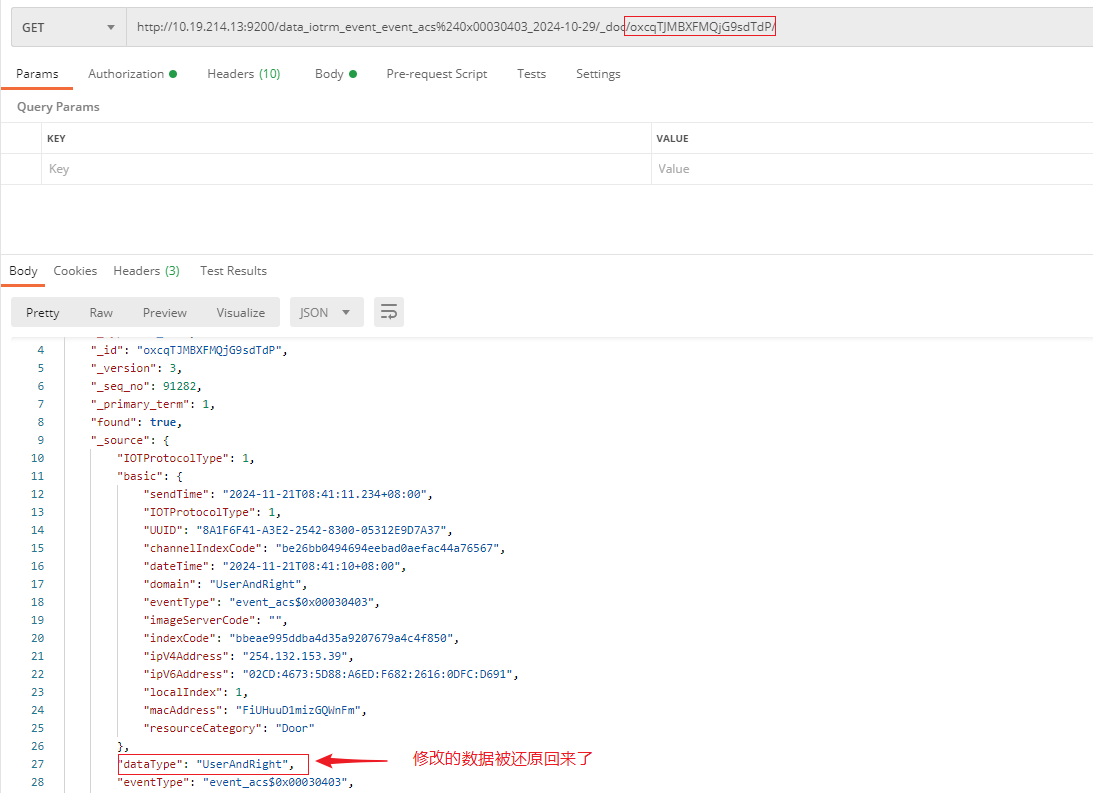
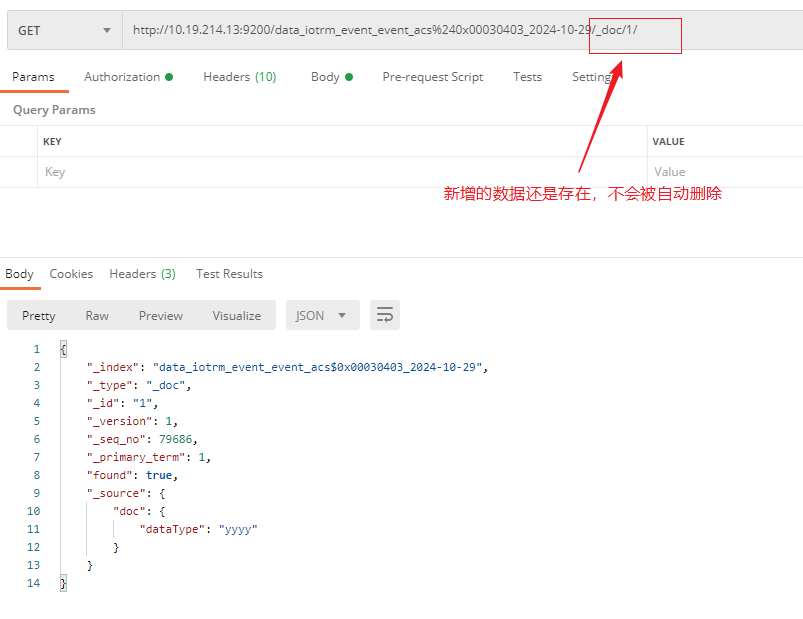
由此可以得出结论一:如果只是数据的导出导入,那么在导出-导入期间变更的数据只有删改的数据会被还原掉,新增的数据仍然是在的,不会自动删除。
5、备份指定索引(不包含数据)
elasticdump --overwrite --input=http://elastic:elasticsearch_422@10.19.223.119:9200/iotrm_event_event_acs\$0x00030403_2024-10-29 --output=/opt/tmp/wf/data/data_iotrm_event_event_acs\$0x00030403_2024-10-29_index.json --limit=10000 --type=index

6、还原指定索引(不包含数据)
elasticdump --input=/opt/tmp/wf/data/data_iotrm_event_event_acs\$0x00030403_2024-10-29_index.json --output=http://elastic:TZQSHMX8zPOaezaT@10.19.214.13:9200/data_iotrm_event_event_acs\$0x00030403_2024-10-29 --limit=10000 --type=index (包含?)

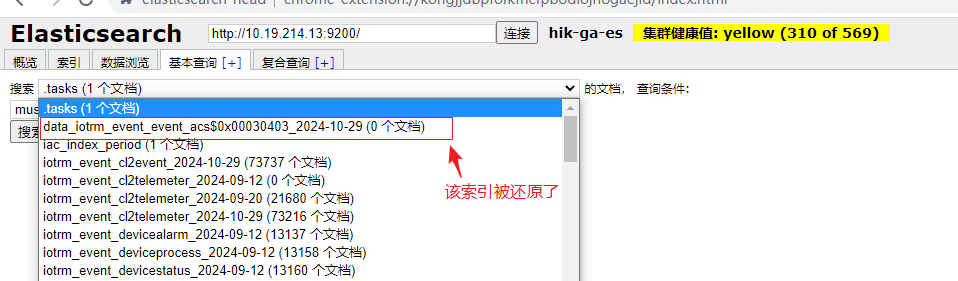
还原从 索引 iotrm_event_event_acs\$0x00030403_2024-10-29 导出的数据文件 data_iotrm_event_event_acs\$0x00030403_2024-10-29.json,在不指定 索引名称的情况下,会发现被还原到了原始索引上(iotrm_event_event_acs\$0x00030403_2024-10-29),上述还原的新索引data_iotrm_event_event_acs\$0x00030403_2024-10-29无数据
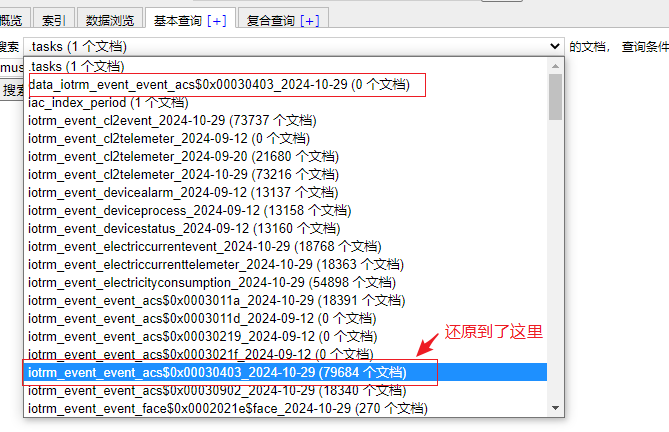
还原从 索引 iotrm_event_event_acs$0x00030403_2024-10-29 导出的数据文件 data_iotrm_event_event_acs$0x00030403_2024-10-29.json,将数据导入到索引 data_iotrm_event_event_acs$0x00030403_2024-10-29 中
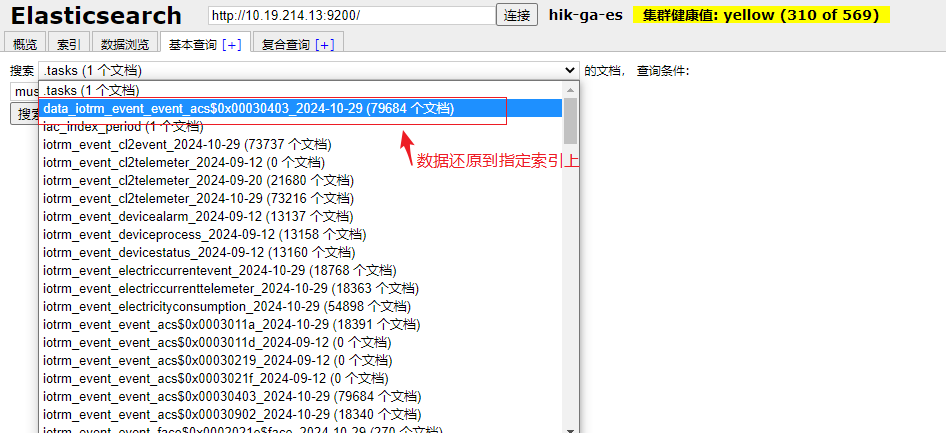
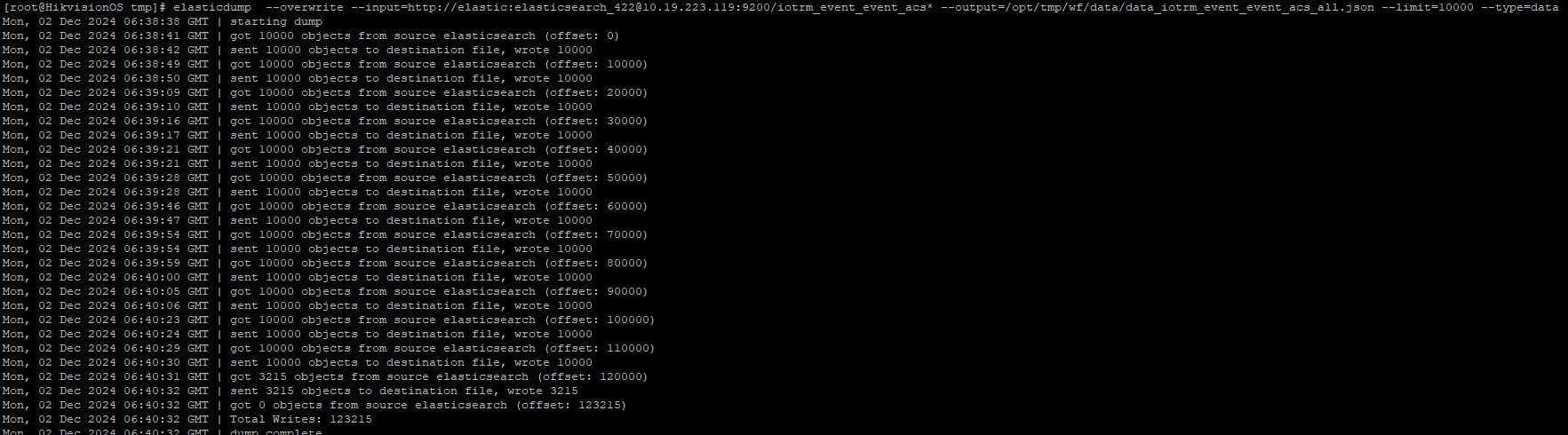
7、指定多个索引数据以及索引进行备份
1) 导出多个索引数据
elasticdump --overwrite --input=http://elastic:elasticsearch_422@10.19.223.119:9200/iotrm_event_event_acs* --output=/opt/tmp/wf/data/data_iotrm_event_event_acs_all.json --limit=10000 --type=data
- 这里将 input 中的指定索引部分使用了通配符的形式,表示导出iotrm_event_event_acs开头的所有索引;
- 导出的数据类型通过type指定了为data;
2)导出多个索引定义
elasticdump --overwrite --input=http://elastic:elasticsearch_422@10.19.223.119:9200/iotrm_event_event_acs* --output=/opt/tmp/wf/data/data_iotrm_event_event_acs_all.json --limit=10000 --type=index

8、还原多个索引数据以及索引
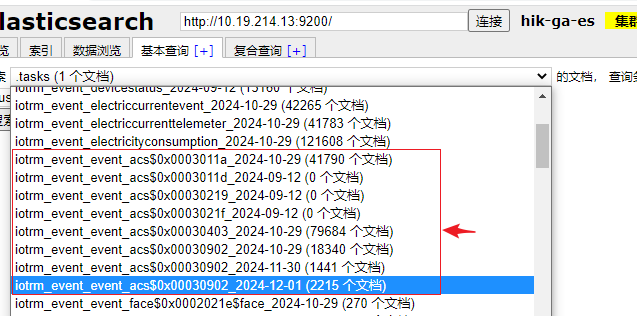
1)删除 iotrm_event_event_acs 开头的部分索引
http://10.19.214.13:9200/data_iotrm_event_event_acsxxx?pretty
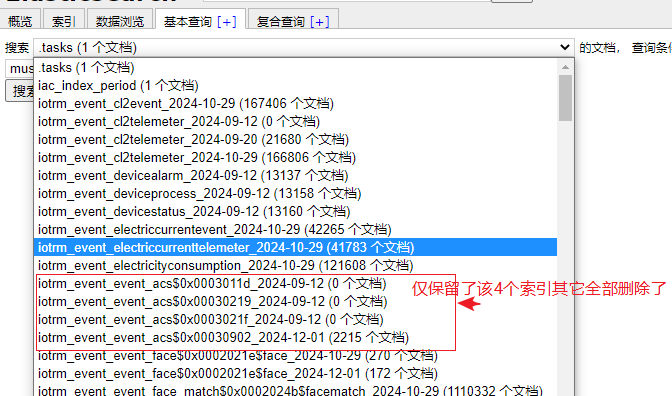
2)还原索引
不指定索引的情况下进行索引还原似乎不可行

3)还原数据
elasticdump --output=http://elastic:TZQSHMX8zPOaezaT@10.19.214.13:9200 --input=/opt/tmp/wf/data/data_iotrm_event_event_acs_all_data.json --limit=10000 --type=data
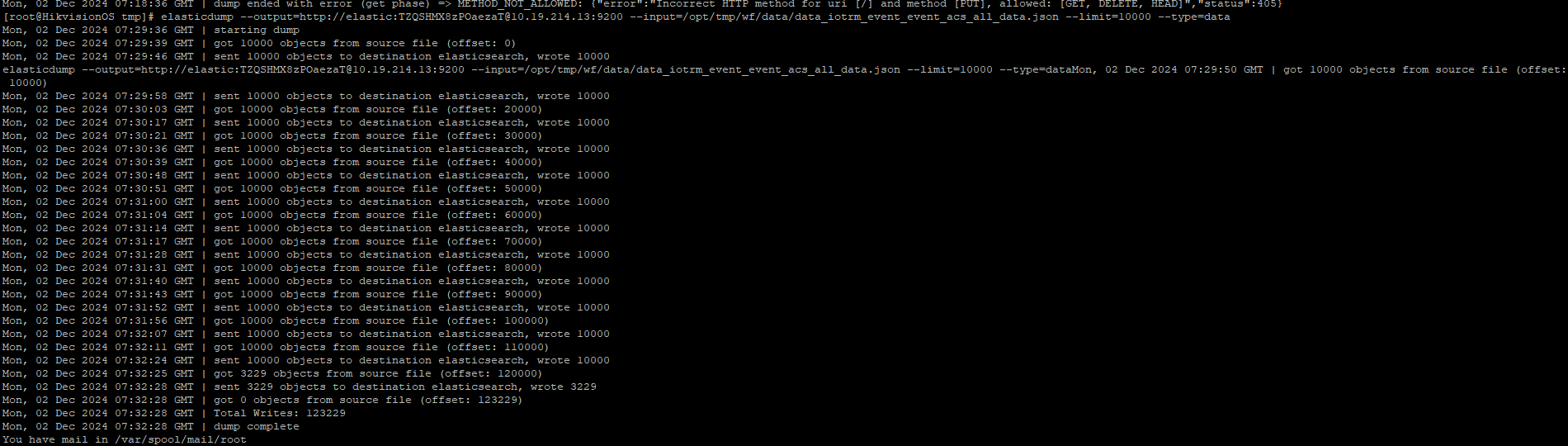
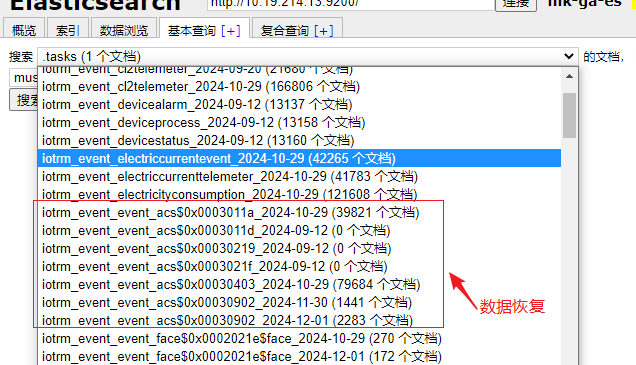
9、备份所有索引
elasticdump --overwrite --input=http://elastic:elasticsearch_422@10.19.223.119:9200 --output=/opt/tmp/wf/data/all_index.json --limit=10000 --type=index

10、还原所有索引
elasticdump --output=http://elastic:TZQSHMX8zPOaezaT@10.19.214.13:9200 --input=/opt/tmp/wf/data/all_index.json --limit=10000 --type=index (不支持通过一个命令批量还原索引)

目前只能单个索引备份,然后从单个索引备份文件中还原索引,且要求该索引已经被删除

图上显示:索引存在的情况下,是还原索引失败的。
第二次操作成功是因为 通过postman 将索引删除了。
五、参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号