机器阅读理解(看经典MRC模型与花式Attention)
简介
机器阅读理解(Machine Reading Comprehension)为自然语言处理的核心任务之一,也是评价模型理解文本能力的一项重要任务,其本质可以看作是一种句子关系匹配任务,其具体的预测结果与具体任务有关。
记录一下之后用来实践的数据集:
阅读理解任务具有多种类别:单项/多项选择、完形填空以及抽取式问答。百度发布的DuReader机器阅读理解数据集涵盖了以上三种任务类型,因此选择用来实践也是非常合适的。
DuReader数据集的样本可用一个四维数组表示:\(\{q, t, D, A\}\),其中\(q\)表示问题,\(t\)表示问题类型,\(D\)表示文档集合,\(A\)表示答案集合。一半的样本来源于百度搜索引擎,一半来源于百度知道。下图展示了DuReader数据集的不同类型样本。(这里记录一下数据集,之后要是出了实践代码这里再补上)

经典模型概述
这里记录一下比较经典的机器阅读理解模型,或者说记录一下各种花式 Attention,想要了解细节的小伙伴也可以去看看原文,这里也都附上了链接。
Model 1: Attentive Reader and Impatient Reader
原文链接:Teaching Machines to Read and Comprehend
这篇文章提出的模型有三个:The Deep LSTM Reader、The Attentive Reader 和 The Impatient Reader。最主要的贡献还是 Attentive Reader 和 Impatient Reader 这两个模型,这两个模型也是机器阅读理解一维匹配模型和二维匹配模型的开山鼻祖。
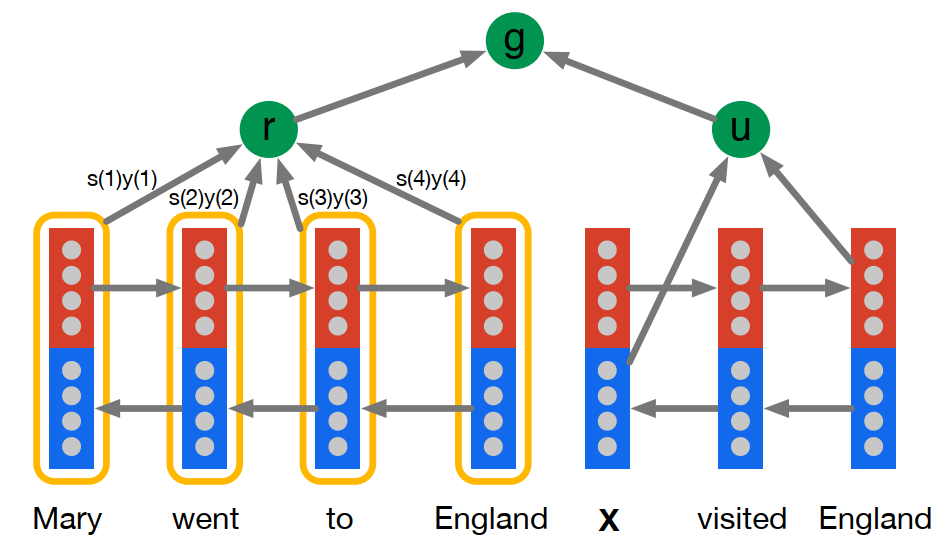
Attentive Reader
Attentive Reader 的基本结构如上图所示,实际上也比较简单,就是一个简单的细粒度注意力机制在机器阅读理解任务中的经典应用。
- \(u\) 是问题 \(Q\) 在经过双向 LSTMs 编码后的最后一个前向输出状态和最后一个后向输出状态的拼接。
- \(y_d(t)\) 是文档 \(D\) 中 第 \(t\) 个词经过双向 LSTMs 编码后的前向输出状态和后向输出状态的拼接。
- 将文档 \(D\) 的单词表示\(y_d(t)\)作为Key,将问题表示 \(u\) 作为 Query,输入一个注意力层,得到问题对文档的注意力加权表征 \(r\)。
- 模型最后将文档表示 \(r\) 和问题表示 \(u\) 通过一个非线性函数进行结合进行判断。
Impatient Reader
Impatient Reader 模型结构如下图所示:
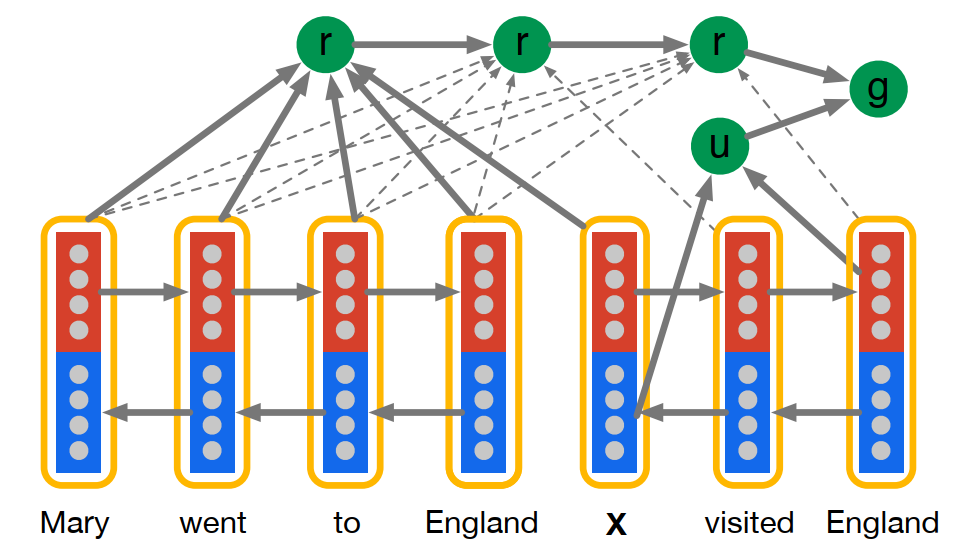
由上图可知,我们可以总结出以下几点区别:
- Impatient Reader 在计算注意力的时候,将每个单词当作一个单独的 Query 从而计算该单词对于 Doc 中每个词的注意力加权表征,并用非线性变换将所有的 r 进行反复累积(单词的重阅读能力),即:
- 最后将最后一个文档表示 \(r(|q|)\) 和问题表示 \(u\) 进行非线性组合用于答案预测。
介绍了模型结构之后,我们就可以从两个模型的区别来总结一下一维匹配模型与二维匹配模型的区别:
- 所谓的一维匹配模型,即将问题直接编码为一个固定长度的向量,在计算注意力分数的时候,等效于直接计算文档 \(D\) 每个词在特定问题上下文向量中作为答案的概率,也正是在计算问题向量 \(Q\) 与文档各个词的匹配关系中形成的一维线性结构,我们可以将其称为一维匹配模型;
- 二维匹配模型,直接输出问题 \(Q\) 每一个词的编码,计算注意力的时候,计算文档 \(Q\) 中每一个词对 \(D\) 中每一个词的注意力,即形成了一个词 - 词的二维匹配结构。由于二维匹配模型将问题由整体表达语义的一维结构转换成为按照问题中每个单词及其上下文的语义的二维结构,明确引入了更多细节信息,所以整体而言模型效果要稍优于一维匹配模型。
Model 2: Attentive Sum Reader
原文链接:Text Understanding with the Attention Sum Reader Network
这篇文章的模型主题基本与 Attentive Reader 十分类似,是一种一维匹配模型,主要是在最后的 Answer 判断应用了一种 Pointer Sum Attention 机制,模型结构如下图所示:
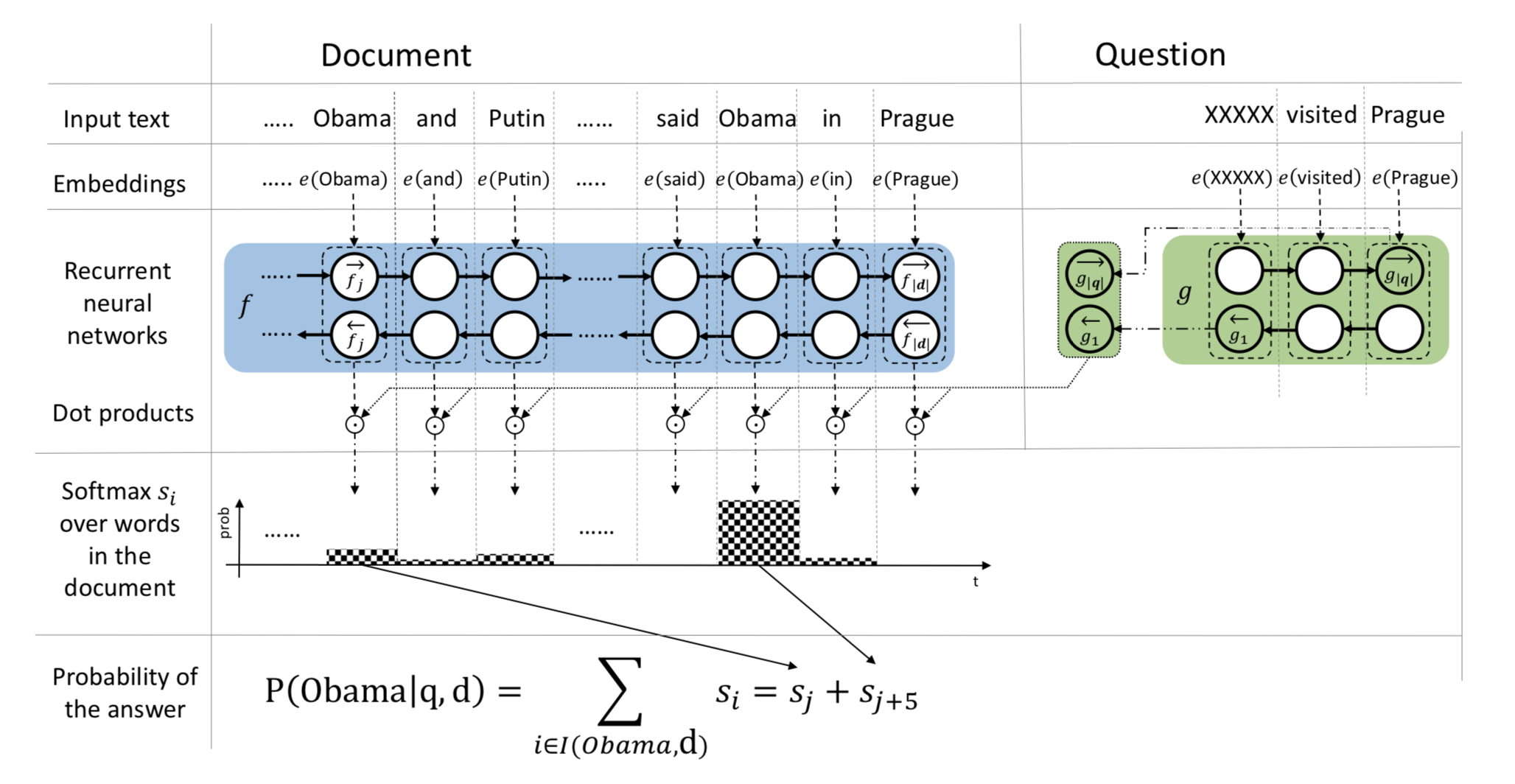
对该模型做一个简单的解释:
- 与 Attentive Reader 一样,应用两个RNN(该文中为GRU)对 Document 和 Question 分别进行编码
- Attention层应用的是 Dot Attention,相对于 Attentive Reader 参数更少,即注意力权重
- 我们之前提到过,一维匹配模型的注意力分数等效于直接文档 d 中每个词在特定问题上下文向量中作为答案的概率,该模型的做法就是,在得到每个词Softmax归一化之后的分数后,将同类型的词的分数累加,得分最高的词即为答案(即作者提到的Pointer Sum Attention)
这样一个将注意力分数累加的操作将受到一个词出现次数的影响,通常,出现次数越多的词越可能成为问题的答案,这样是否是合理的呢?实验数据表明这样的假设确实是合理的。该模型的结构以及Attention的求解过程明显比 Attentive Reader 更简单,却取得了更好的效果,这也意味着并不是越复杂的模型效果会更好,简单的结构在合适的场景下能取得非常好的结果。
Model 3: Stanford Attentive Reader
该模型同样是对 Attentive Reader 的改进,属于一种一维匹配模型,我们先来看看熟悉的模型结构:

模型主体这里就不讲了,主要记录一下其与 Attentive Reader 不一样的部分:
- 注意力计算方式为bilinear(较点积的方式更灵活):
-
得到注意力加权输出\(o\)之后,然后直接用\(o\)进行分类预测,而 Attentive Reader 是用输出与 query 又做了一次非线性处理之后才预测的,实验证明移除非线性层不会伤害模型性能。
-
原来的模型考虑所有出现在词汇表V中的词来做预测。而该模型只考虑出现在文本中的实体(进一步减少参数)
上述三点中,第一点是比较重要的,而后面两点都是对模型的一个简化处理。
Model 4: AOA Reader
原文链接:Attention-over-Attention Neural Networks for Reading Comprehension
AOA Reader 属于是一种二维匹配模型,该论文的亮点是将另一种注意力嵌套在现有注意力之上的机制,即注意力过度集中机制,其主要模型结构如下图所示:
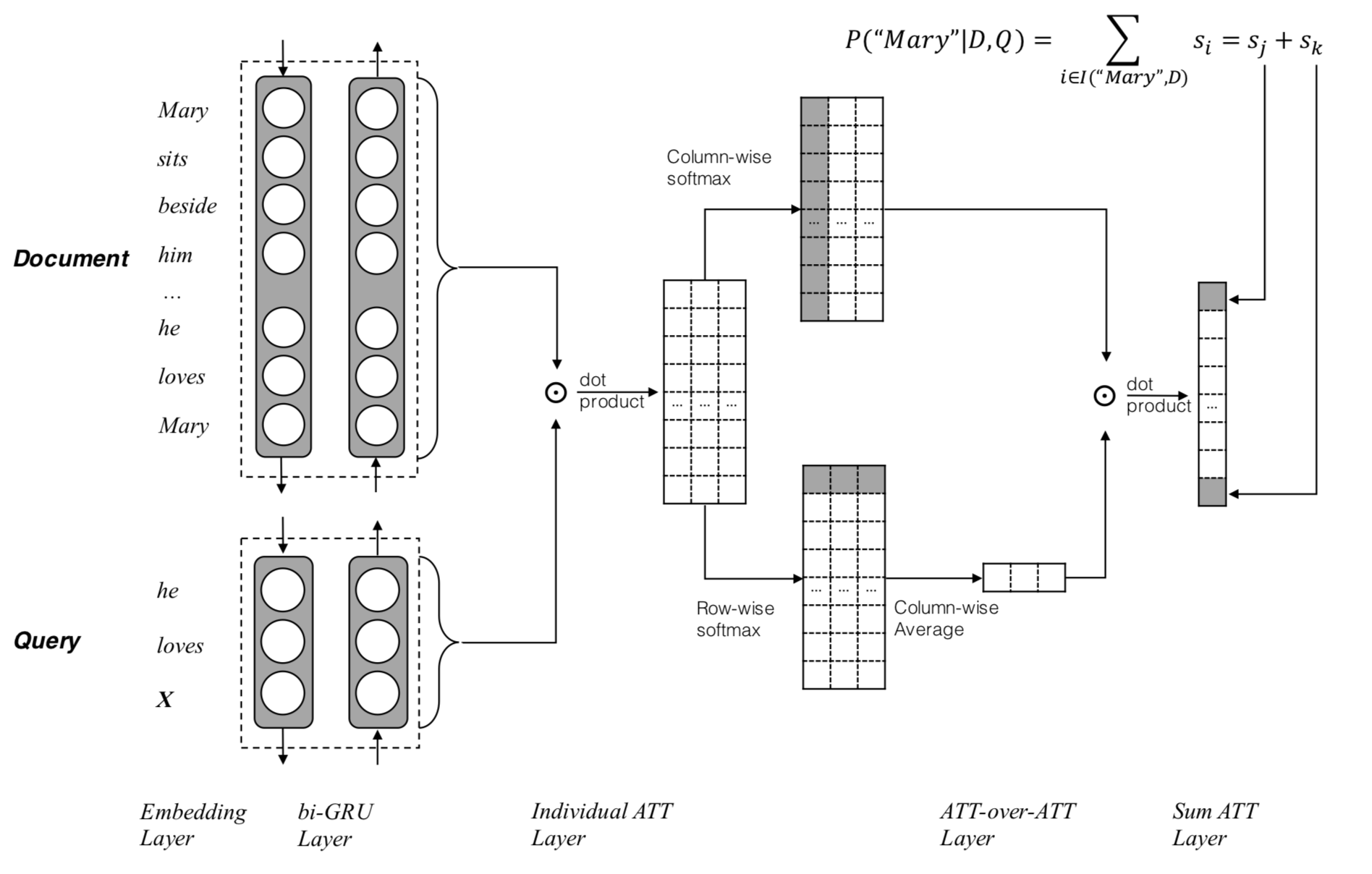
- 利用双向GRU对 Document 和 Query分别编码,得到编码后的隐藏层表征,即
- 利用pair-wise matching matrix来计算得到注意力匹配分数:
- 在列方向上进行 Softmax 归一化,注意上一个公式,每一列表示 query 一个词对 doc 所有词的注意力分数大小,得到所谓的 query-to-document attention
- 在行的方向进行 Softmax 归一化,得到 document-to-query attention
- 将 document-to-query attention 作平均得到最终的 query-level attention:
- 最后,用每个query-to-document attention和刚刚得到的query-level attention做点乘,得到document中每个词的score。
- 与Attentive Sum Reader类似,最后预测答案词的方式是将同类型的词的分数累加,得分最高的词即为答案,下式中,V为词表:
- 对于损失函数,我们可以直接最大化正确词的概率分数即可,下式中,A为标注答案词:
Model 5: Match-LSTM and Answering Point
Match-LSTM:Learning Natural Language Inference with LSTM
Pointer Networks:Pointer Networks
Match-LSTM and Answering Point:Machine Comprehension Using Match-LSTM and Answer Pointer
由论文标题可知,该论文利用 Match-LSTM 以及 Answer Pointer 模型来解决机器阅读理解问题,Match-LSTM也属于二维匹配模型的一种,注意力求解方法我们下面再详细介绍,该论文的主要贡献在于将Pointer Net中指针的思想首次应用于阅读理解任务中。首先,我们分别看看两个模型的结构:
Match-LSTM
Match-LSTM最初提出是用于解决文本蕴含任务的。文本蕴含任务的目标是,给定一个 premise(前提),根据此 premise 判断相应的 hypothesis(假说)正确与否,如果从此 premise 能够推断出这个 hypothesis,则判断为 entailment(蕴含),否则为 contradiction(矛盾)。文本蕴含任务也可以看作是句子关系判断任务的一种。
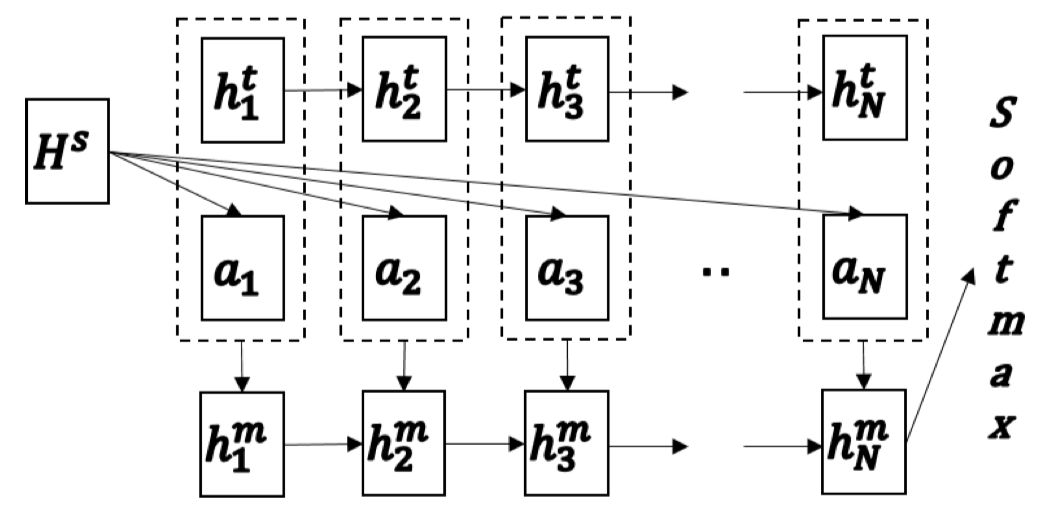
模型的主要结构如上图所示,图中,\(H^S\)为 premise 经过LSTM编码后的隐藏层表征,同理,\(h_k^t\)为 hypothesis 中第 \(k\) 个词的隐藏层表征。整个模型的计算如下:
- 得到两个表征之后,同样是 Attention 操作(详细的Attention计算方法参考原文)得到 hypothesis 对于 premise 每个词注意力加权输出\(a_k\)
- 将注意力加权输出与 hypothesis 对应位置词的隐藏层拼接\(m_k=[a_k;h_k^t]\),再将其通过一个长度为\(N\)的LSTM,得到一个 hypothesis 整合注意力向量的隐藏表征,用最后一个时刻的隐藏层向量\(h_N^m\)预测最后结果。
Pointer Net
Pointer Net的提出解决了一类特殊问题:如果生成的输出序列中的字符必然出现于输入序列,则我们可以采用Pointer Net的结构来得到输出,而不需要事先规定固定词表。这类模型在文本摘要任务中得到了广泛的应用,主要思路如下图所示:

对于左边的传统模型,如果给定的词汇表已经限定,则模型无法预测大于4的数字,而对于右边的Ptr-Net,我们不需要给定词汇表,只需要在预测的时候每一步都指向输入序列中权重最大的那个元素,由于输出序列完全来自于输入序列,则解空间完全可以随着输入序列变化。而我们在求 Attention 过程中的 Softmax 分数,正是每一个输出位置对输入序列的注意力大小,直接将最大分数的位置作为该输出位置的指针即可。
Match-LSTM and Answering Point
将两者结合起来,在机器阅读理解任务中,可以将 question 当作 premise,将 passage 当作 hypothesis,整个模型的思路如下:
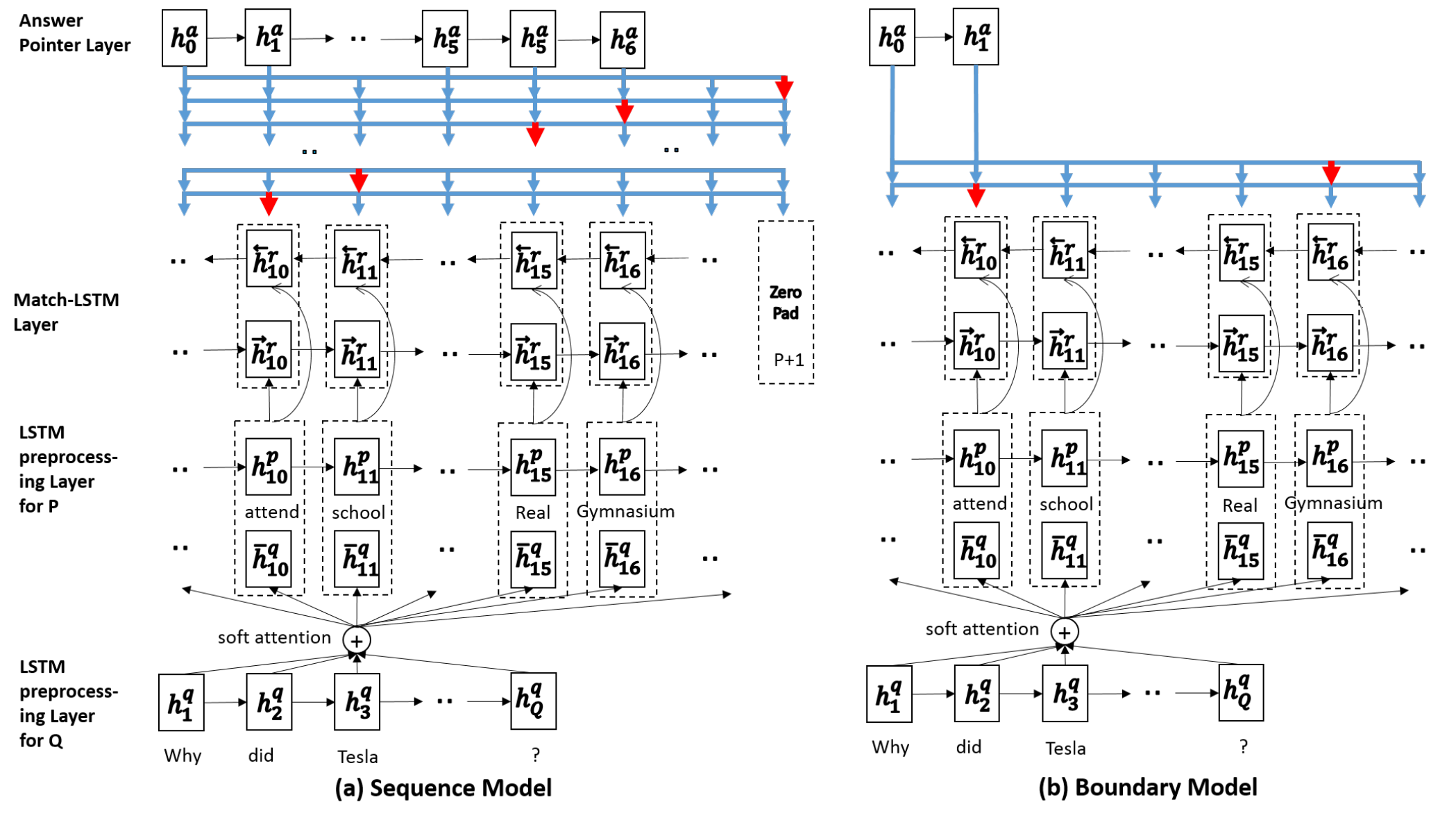
- 首先针对 question 以及 passage 用 LSTM 进行预编码
- 对编码过后的向量输入到之前提到的Match-LSTM中,只是最后一层长度为 \(N\) 的 LSTM 改为了双向LSTM,得到双向LSTM的隐藏输出\(H^r\),可以将其看作 passage 对 question 的初步 Attention 编码结果
- 作者采用了两种 Answer Point Layer 模型输出预测结果
-
Sequence Model:考虑到生成的答案在 passage 中不是连续存在的,因此预测的是一个答案标记序列
- 首先,使用注意机制再次获得一个注意力权重向量,其中\(\beta_{k, j}\)是从段落中选择第 j 个字符作为第 k 个答案字符的概率,\(\beta_{k,P+1}\)表示答案在段落第 k 个字符结束的概率,\(\beta_{k}\)将其按行 Softmax 得到第 k 个答案字符对段落中所有字符的注意力分数:
\[F_k=tanh(V\widetilde{H}^r+(W^ah^a_{k-1} + b^a)\otimes e_{P+1}) \]\[\beta_{k}=softmax(v^TF_k+c\otimes e_{P+1}) \]- 上式中\(\widetilde{H}^r \in \mathbb{R}^{2l \times (P +1)}\)为\(H^r\)与零向量的结合,\((\cdot \otimes e_Q)\)表示将左边的向量复制\(Q\)次(相当于广播),\(h_{k-1}^a \in \mathbb{R}^l\)是LSTM的第k-1位置的隐藏向量,LSTM如下定义:
\[h_k^a=\overrightarrow{LSTM}(\widetilde{H}^r\beta^T_k, h_{k-1}^a) \]- 针对我们得到的\(\beta _{k,j}\),我们可以将其表征为 passage 中选择第 j 个字符作为第 k 个答案字符的概率,即\(p(a_k=j|a_1,a_2,...,a_{k-1},H^r)=\beta _{k,j}\),因此生成答案序列的概率为:
\[p(a|H^r)=\prod _kp(a_k|a_1,a_2,..a_{k-1},H^r) \]- 损失函数可以直接定义为最小化答案字符位置概率的负数,即
\[-\sum _{n=1}^Nlogp(a_n|P_n,Q_n) \] -
Boundary Model:其与 Sequence Model 非常类似,只是默认生成的答案在 passage 中是连续存在的,因此只需要预测开始位置,且在已知开始位置的基础上预测一个结束位置即可,即:
\[p(a|H^r)=p(a_s|H^r)p(a_e|a_s,H^r) \] -
Model 5: BiDAF
原文链接:Bidirectional Attention Flow for Machine Comprehension
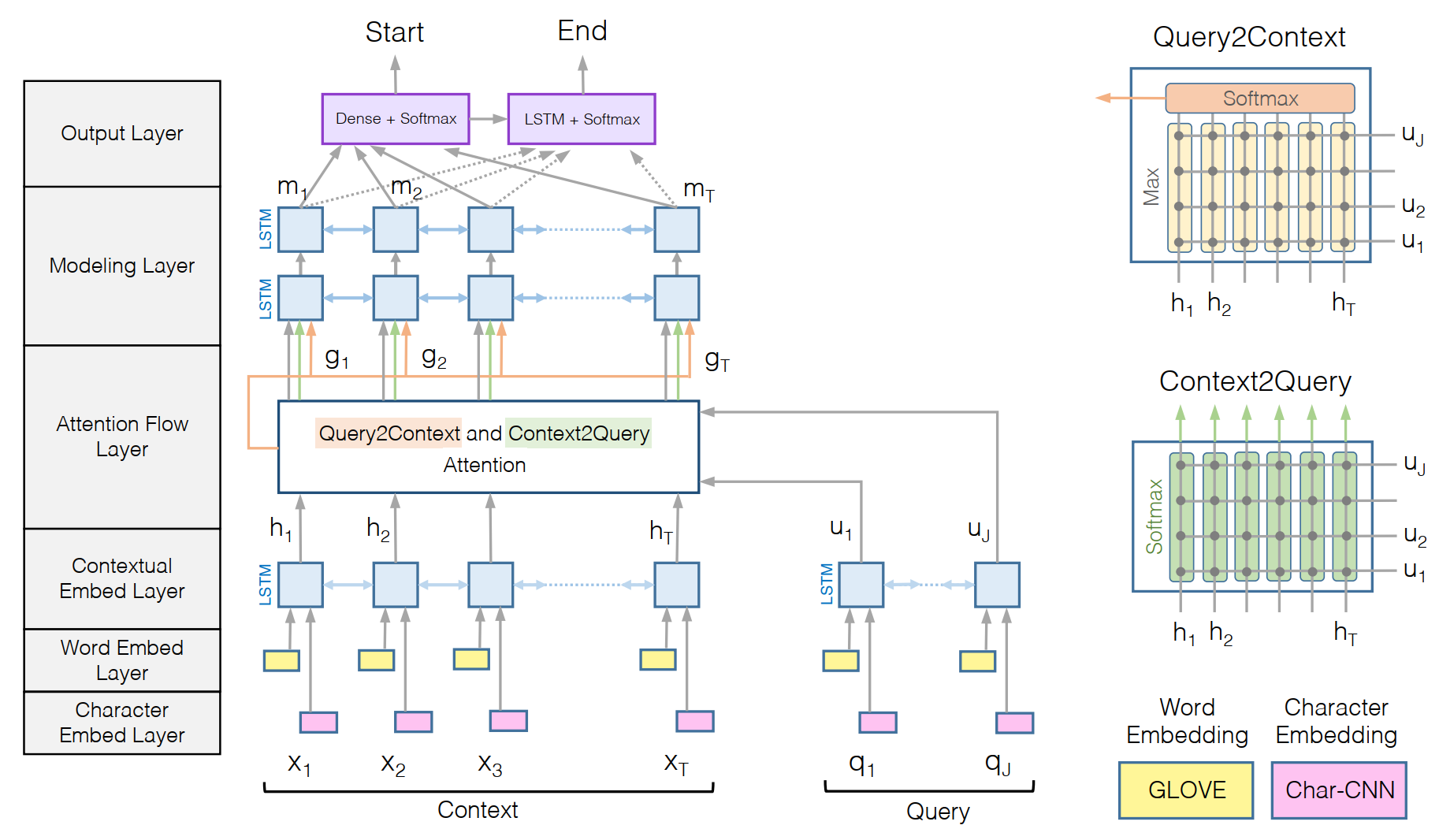
在 Match-LSTM 提出之后,question-aware 表征的构造方式开始出现在各个论文之中。该论文中的 Attention 计算主要有以下三个特征;
- 为典型的二维匹配模型,在词-词的层面上求 Attention 矩阵,计算了 query-to-context(Q2C) 和 context-to-query(C2Q)两个方向的 attention 信息,最后构造出 qurry-aware 的 Context 表示
- 在每一个时刻,仅仅对 query 和当前时刻的 context paragraph 进行计算,并不直接依赖上一时刻的 attention,使得每次的attention计算更关注当前时刻的文本,不受过去信息的影响
模型结构如上图所示,由图可知,模型主要有以下几个部分:
-
字符嵌入层:字符嵌入层负责将每个单词映射到高维向量空间。使用卷积神经网络(CNN)在字符级别上对每个单词进行编码,该卷积网络的应用原理参考Kim在2014年发表的TextCNN。CNN的输出在整个宽度上被max-pooled,以获得每个单词的固定大小向量。
-
词嵌入层:使用预训练的 Glove 词向量。并将字符嵌入层得到的词向量与预训练词向量拼接之后,输入一个2层的Highway层,得到整合之后的词表征。
-
上下文嵌入层:使用BiLSTM对 Context 和 Query 分别进行编码。值得注意的是,上述这三层提取了三个不同粒度的特征对 Context 以及 Query 进行编码,得到矩阵 \(H \in R^{2d\times T}\) 和 \(U \in R^{2d \times J}\)。
-
注意力流层:该层是该模型最重要的部分。注意力流层负责链接与融合query和context的信息。和以前流行的attention机制不一样,我们的模型不会把query和context变成一个单一的特征向量,而是将每个时间步的attention向量都与之前层的嵌入向量,一起输入modeling层。这可以减少因为early summarization引起的信息损失。其具体操作如下:
- 该层的输入是 Context 的表征 \(H\) 和 Query 的表征 \(U\),输出为 query-aware 的 Context 表征,以及之前的上下文嵌入。
- 在该层中,计算了两个方向上的 Attention,context-to-query 和 query-to-context
- 首先,构造一个共享相似度矩阵:
\[S_{tj} = \alpha (H_{:t}, U_{:j}) \ \in R^{T*J} \]\[\alpha(h, u) = w^T_{(S)}(h;u;h \cdot u) \]-
接下来,使用得到的共享相似度矩阵 \(S\) 来计算两个方向上的注意力大小
- context-to-query attention:计算 query 上的一个词对 context 上的每个词的注意力大小(相关性),与 AOA 模型中的做法有点类似,对行方向进行归一化,再对 query 进行注意力加权,包含所有query信息:
\[a_t = softmax(S_{t:}) \ \in R^J \]\[\hat{U}_{:t} = \sum _{j} a _{tj}U _{:j} \in R^{2d \times T} \]- query-to-context attention(Q2C): 计算 context 上的一个词对 query 上的每个词的注意力(相关性),这些 context words 对回答问题很重要。直接取相关性矩阵每一列的最大值,再将其进行softmax归一化,对 context 加权,并在列方向上迭代T次,最后得到的矩阵维度为\(\hat{H}\in R^{2d*T}\),包含所有的context信息,即:
\[b = softmax(max_{col}(S)) \ \in R^T \]\[\hat{h} = \sum_tb_tH_{:t} \ \in R^{2d} \] -
将 Context 表征 \(H\) 与 Attention 表征进行整合为\(G\),整合方式如下,得到的矩阵中每一列可视为 Context 中每一个词的 query-aware 表示:
\[G_{:t} = \beta (H_{:t}, \hat{U}_{:t}, \hat{H}_{:t}) \in R^{d_G} \]上式中,\(d_G\)为\(\beta\)的输出维度,论文中对\(\beta\)取如下定义:
\[\beta(h, \hat{u}, \hat{h}) = [h;\hat{u};h \cdot \hat{u};h\cdot\hat{h}]\in R^{8d \times T} \] -
建模层:这一层的输入为之前得到的\(G\),Context 的 query-aware 表示。这一层可以看作利用 Bi-LSTM 对含 Context 及 Query 信息的矩阵G进行进一步的信息提取,得到输出矩阵大小为\(M \in R^{2d\times T}\),将其用于预测答案。
-
输出层:对于问答任务,该层采用指针的方式来预测输出,即仅预测答案在 Context 中的开始位置以及结束位置。
- Start:直接将 \(G\) 与 \(M\) 拼接之后,输入一个全联接层进行预测,即
\[p^1 = softmax(w^T_{(p^1)}[G;M]) \]- Stop:将 \(M\) 通过另一个 BiLSTM 得到 \(M^2\) 然后与 \(G\) 拼接,通过全联接层预测,即
\[p^2 = softmax(w^T_{(p^2)}[G;M^2]) \] -
损失函数为开始和结束位置的交叉熵之和,与 Match-LSTM 中的 Boundary Model 类似。
Model 6: R-NET
原文链接:R-NET: MACHINE READING COMPREHENSION WITH SELF-MATCHING NETWORKS

R-Net主要是在 Match-LSTM 的基础上进行的,的主要结构如上图所示,结构已经非常清楚了,主要包括Encoding Layer,Gated Matching Layer,Self-Matching Layer,Boundary Prediction Layer四个部分,我们先把结构展开讲一下,再对该论文的贡献进行总结。
- Question and Passage Encoder:该层将Word Embedding 以及 Character Embedding 拼接,在输入一个双向GRU对 Question 以及 Passage 进行编码,即
-
Gated Attention-based Recurrent Networks:论文提出了一种门限注意力循环网络来将 Question 的信息整合到 Passage 的表征中,它是基于注意力的循环网络的一种变体,具有一个附加的门来确定段落中有关问题的信息的重要性。由 Question 与 Passage 的表征 \(u^Q_t, u^P_t\) 得到 Sentence-Pair 表征 \(v^P_t\):
\[v^P_t = RNN(v^P_{t-1}, c_t) \]其中,\(c_t = att(u^Q, [u^P, v^P_{t-1}])\),可以将其看作一个注意力池化向量,具体计算如下:
\[s_t^j = v^T tanh(W_u^Qu^Q_j + W_u^P u^P_t + W_v^P v_{t−1}^P) \]\[a^t_i = exp(s^t_i)/sum^m_{j=1}exp(s^t_j) \]\[c_t = \sum^m_{i=1}a^t_iu^Q_i \]则得到的每一个 Sentence-Pair 向量都动态整合了整个问题的匹配信息,借鉴 Match-LSTM 的思想,将 Passage 的表征输入到最后的RNN中,得到 Question-aware Passage 表征 :
\[v^P_t = RNN(v^P_{t-1}, [u^P_t, c_t]) \]为了动态判断输入向量与 Question 的相关性,还额外加入一个门机制,对RNN的输入进行控制,因此将其称为 Gated Attention-based Recurrent Networks:
\[[u_t^P, c_t]^* = g_t \cdot [u_t^P, c_t] \]\[g_t = sigmoid(W_g[u_t^P, c_t]) \] -
Self-Matching Attention:上一层输出的 Question-aware 表征确定了段落中与问题相关的重要部分,但这种表征的一个重要问题是其很难包含上下文信息,然而一个答案的确定很多时候都是很依赖于上下文的。为了解决这个问题,论文提出了 Self-Matching Attention,其动态地收集整个段落的信息给段落当前的词语,把与当前段落词语相关的信息和其匹配的问题信息编码成段落表示:
这里的$c_t = att(v^P ; v_t^P )$为对整个 Passage 的自注意力池化:
$$s^t_j = v^Ttanh(W_v^P v_j^P + W_v^{\tilde{P}}v_t^P )$$
$$a^t_i = exp(s^t_i)/\sum^n_{j=1}exp(s^t_j)$$
$$c_t = \sum^n_{i=1}a^t_iv_i^P$$
同样,对$[v_t^P, c_t]$增加与上一层输入同样的门控机制,来自适应控制 RNN 的输入。
-
Output Layer:该模型同样利用 Point Network 的结构来直接预测答案的起始位置和输出位置。
- 根据给定段落表示,把 Attention 权重分数作为一个 Pointer 来选取答案在段落中的起始位置,也就是基于初始语境信息,计算段落中每个词语的 Attention 权重,权重最高的作为起始位置:
\[s^t_j = v^Ttanh(W_h^P h_j^P + W_h^{a}h_{t-1}^a) \]\[a^t_i = exp(s^t_i)/\sum^n_{j=1}exp(s^t_j) \]\[p^t = argmax(a_1^t, ..., a_n^t) \]上式中,\(h^a_{t-1}\) 为 Point Network 最后的隐藏状态
- 在得到起始位置之后,用注意力分数对 Self-Matching 的 Passage 表征进行加权,然后利用之前的Question Attention-Pooling表征,作为RNN的初识状态,对加权后的Passage 表征进行再处理,得到新的语境,新的语境信息计算方式如下:
\[c_t = \sum^n_{i=1}a^t_ih^P_i \]\[h^a_t = RNN(h^a_{t-1}; c_t) \]- 当预测开始位置的时候,将对 Question 的表征使用 Attention-Pooling的向量作为 Pointer Network 的初始语境。
\[s_j = v^Ttanh(W_u^Q u_j^Q + W_V^{Q}V_r^Q ) \]\[a_i = exp(s_i)/\sum^m_{j=1}exp(s_j) \]\[r_Q = \sum^m_{i=1}a_iu_i^Q \]上式中\(V_r^Q\)为参数向量
-
同样选择交叉熵作为模型的损失函数
了解了模型的主要结构,我们来看看该模型的创新点在什么地方:
- 首先,提出了一种gated attention-based recurrent network,也就是在经典的attention-based recurrent networks上额外增加了门机制,这样做的主要原因是针对阅读理解的问题,段落中的每个单词的重要性是不同的。通过门机制,模型根据段落与问题的相关程度,赋予了段落中不同词的重要程度,掩盖了段落中不相关的部分。
- 由于RNN本身只能存储有限段落信息,一个候选答案通常不知道段落的其余部分的信息,提出了 Self-Matching 机制这种机制,用整个段落的信息动态完善段落表示,使后续网络能够更好地预测答案。
Model 7: QANet
原文链接:QANET
深度可分离卷积:Xception: Deep Learning with Depthwise Separable Convolutions
DCN:Dynamic Connection Network for Question Answering
最后一个模型QANet,是预训练模型发布之前排名最优的一个阅读理解模型了,其与之前模型明显的不同就是,抛弃了RNN,只使用 CNN 和 Self-Attention 完成编码工作,使得速度与准确率大大赠强。模型的主要结构如下图(左)所示

该模型与大多与之模型的结构都是相同的,,由五个部分组成:Embedding layer, Embedding encoder layer, Context-query attention layer, Model encoder layer 和 Output layer。其中,整个模型中使用相同的编码器块(图右),仅改变每个块的卷积层数,该编码器块主要由如下几个特点:
- 编码器块中的每一层都使用了 Layernorm 和残差链接
- 每个编码器块的输入位置都加入了 Transformer 中定义的 Position Embedding
- Self-Attention 采用了 Transformer 中的多头注意力机制
- 编码器块中的卷积网络并不是简单的卷积网络,而是深度可分离卷积层((depthwise separable convolutions),该结构由更好的泛化能力,且有更少的参数和更低的计算量
- 对于普通的卷积核卷积,输入矩阵维度为 \(N_{in} \times N_{in} \times C_{in}\),假设卷积核大小为\(N_{k}\times N_{k} \times C_{in}\),输出通道数为 \(C_{out}\) ,则需要的参数为 \(N_k \times N_k \times C_{in} \times C_{out}\)
- 对于深度可分离卷积,则使用 \(C_{in}\) 个 \(N_k \times N_k \times 1\) 的卷积核分别卷积每个通道,然后使用\(C_{out}\) 个 \(1 \times 1 \times C_{in}\) 的一维卷积整合多通道信息,整体参数只有 \(C_{in} \times (N_k \times N_k + C_{out})\)个参数
下面来看看整体结构:
-
Input Embedding Layer:与之前的模型处理类似,也是整合词向量以及字符向量的方式来得到词表征。
- 对于词嵌入,利用预训练的GloVe词向量来初始化,并在训练的过程中固定,而对于OOV词,将其初随机初始化之后加入训练。
- 对于字符向量,将每个字符都初始化为200维的可训练向量,每个词都固定到16的长度,则每个词的字符向量表示为字符向量矩阵的最大池化表示,从而将其映射到 200 的固定长度。最后的词表征为词向量与字符向量表征拼接\([x_w;x_c]\) 通过一个 Highway 的输出向量。
-
Embedding Encoder Layer:编码层就是编码器块堆叠形成的,此处的编码器块层数为1,将 Input Embedding Layer 输出的长度为 500 的向量 映射为一个长度为 128 的向量。
-
Context-Query Attention Layer:我们用 C 和 Q 分别表示编码后的 Context 和 Question,根据二维匹配模型,首先计算出 C 和 Q 的相似矩阵 \(S \in R^{n \times m}\),然后对其进行 Softmax 归一化,得到 Context 中每个词对 Question 所有词的注意力分数,再将归一化后的矩阵 \(\bar{S}\) 对问题表征 Q 进行加权,从而得到问题的context-to-query attention表征:
\[A=S \cdot Q^T \ \in R^{n\times d} \]相似度矩阵的计算方法也是比较传统的方法:
\[f(q, c) = W_0[q; c; q \cdot c] \]另外,作者还借鉴了当时高性能的模型中求解双向注意力的方法(如BiDAF),计算了上下文的 query-to-context attention 表征,计算方式借鉴的是 DCN 中的计算方法,首先对相似度矩阵 \(S\) 进行列归一化,得到 Question 的每个词对 Context 所有词的注意力分数 \(\bar{\bar{S}}\) ,则 query-to-context attention 表征为
\[B=\bar{S} \cdot \bar{\bar{S}}^T \cdot C^T \ \in R^{n\times d} \] -
Model Encoder Layer:这部分继续沿用了与 BiADF 中类似的结构,输入为 Contest 的 query-aware 表征 \([c, a, c \cdot a, c \cdot b]\) ,其中 \(a, b\) 为矩阵 \(A, B\) 中的一行。而编码器块处了卷积层数为2,总的块数是7以外,其余与 Embedding Encoder Layer 中的结构相同,总共堆叠3组编码器块(共有 3*7 个Encoder Block)。
-
Output layer:这一层同样沿用与 BiADF 类似的结构,仅仅答案开始以及结束的位置进行预测。
其中,$W_1, W_2$ 均为可训练矩阵,而$M_0, M_1, M_2$ 分别为3组编码器块的输出
- 损失函数同样为交叉熵。当然,通过改变输出层的网络结构,该模型能够适应其他类型的阅读理解任务,如单项多项选择等。
总结
如果你看到了这里,就会发现 QANet 基本融合之前所有模型的优点,从而得到了当时的最优效果(即使模型性能之后还是被预训练模型吊打),在这篇文章的基础上,最后我们总结一下机器阅读理解模型的一些已被证实的十分有效的技巧:
- 利用 Highway 结构对词向量以及字符向量的整合
- 编码器 CNN 以及 Transformer 的并行能力以及信息提取能力已经可以完全代替LSTM,且CNN可用深度可分离卷积网络,大大较少参数
- 既然使用了 CNN 和 Transformer,位置编码则是必不可少的
- 通过对相关矩阵进行 Softmax 归一化的方法得到双向注意力,再整合为包含问题信息的上下文表征,是一个十分高效的模型编码方式
- 对于答案为上下文中某一个文段的问题,目前最优的方法是 Pointer Network 中指针位置预测的方法
参考链接
https://zhuanlan.zhihu.com/p/22671467
https://zhuanlan.zhihu.com/p/52977813
https://zhuanlan.zhihu.com/p/53132772
https://zhuanlan.zhihu.com/p/53324276
https://zhuanlan.zhihu.com/p/21349199
https://zhuanlan.zhihu.com/p/48959800
https://blog.csdn.net/zhang2010hao/article/details/88387493
https://zhuanlan.zhihu.com/p/53626872
https://zhuanlan.zhihu.com/p/35229701
https://zhuanlan.zhihu.com/p/61502862
https://zhuanlan.zhihu.com/p/58961139

