
ElasticSearch 数据增删改实现
前言
本文介绍 ElasticSearch 增加、删除、修改数据的使用示例。通过Restful 接口和 Python 实现。ES最新版本中有Delete By Query 和 Update By Query等功能,但是老版本是没有相关功能的,这里需要特别注意下。详细可参考官网资料:
5.4版本:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html
2.4版本:https://www.elastic.co/guide/en/elasticsearch/reference/2.4/docs.html
事先需要安装好ElasticSearch和head插件。可参考:http://blog.csdn.net/xsdxs/article/details/52815270
Restful API 实现
创建索引
创建索引
curl -XPOST 'localhost:9200/customer?pretty'

插入数据
单条插入-指定id
curl -XPOST 'localhost:9200/customer/external/1?pretty' -d' {"name": "John Doe" }'
单条插入-不指定id
curl -XPOST 'localhost:9200/customer/external?pretty' -d' {"name": "Jane Doe" }'
批量插入:
curl -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary “@accounts.json"
参考资料:http://blog.csdn.net/pilihaotian/article/details/52452014
数据下载:https://raw.githubusercontent.com/bly2k/files/master/accounts.zip
删除数据
删除数据:下面的语句将执行删除Customer中ID为2的数据
curl -XDELETE 'localhost:9200/customer/external/2?pretty'
根据查询条件删除(PS:这条本人没试过,我用的还是2.4版本,这是参照官网资料的5.4版本写的)
curl -XPOST 'localhost:9200/customer/external/_delete_by_query?pretty' -d '{ "query": { "match": { "name": "John" } } }'
删除全部
{ "query": { "match_all": {} } }
更新数据
更新文档: 修改id=1的name属性,并直接增加属性和属性值
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d ' { "doc": { "name": "xyd", "age": 20 } }'
更新索引–脚本方式
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d' { "script": "ctx._source.age += 5" }'
Python API 实现
说明
以下代码实现是:单条增加、根据_id删除、根据_id更新、批量增加等接口。调试的时候建议一个一个功能运行。
代码
# -*- coding: utf-8 -*- from elasticsearch.helpers import bulk import elasticsearch class ElasticSearchClient(object): @staticmethod def get_es_servers(): es_servers = [{ "host": "localhost", "port": "9200" }] es_client = elasticsearch.Elasticsearch(hosts=es_servers) return es_client class LoadElasticSearch(object): def __init__(self): self.index = "hz" self.doc_type = "xyd" self.es_client = ElasticSearchClient.get_es_servers() self.set_mapping() def set_mapping(self): """ 设置mapping """ mapping = { self.doc_type: { "properties": { "document_id": { "type": "integer" }, "title": { "type": "string" }, "content": { "type": "string" } } } } if not self.es_client.indices.exists(index=self.index): # 创建Index和mapping self.es_client.indices.create(index=self.index, body=mapping, ignore=400) self.es_client.indices.put_mapping(index=self.index, doc_type=self.doc_type, body=mapping) def add_date(self, row_obj): """ 单条插入ES """ _id = row_obj.get("_id", 1) row_obj.pop("_id") self.es_client.index(index=self.index, doc_type=self.doc_type, body=row_obj, id=_id) def add_date_bulk(self, row_obj_list): """ 批量插入ES """ load_data = [] i = 1 bulk_num = 2000 # 2000条为一批 for row_obj in row_obj_list: action = { "_index": self.index, "_type": self.doc_type, "_id": row_obj.get('_id', 'None'), "_source": { 'document_id': row_obj.get('document_id', None), 'title': row_obj.get('title', None), 'content': row_obj.get('content', None), } } load_data.append(action) i += 1 # 批量处理 if len(load_data) == bulk_num: print '插入', i / bulk_num, '批数据' print len(load_data) success, failed = bulk(self.es_client, load_data, index=self.index, raise_on_error=True) del load_data[0:len(load_data)] print success, failed if len(load_data) > 0: success, failed = bulk(self.es_client, load_data, index=self.index, raise_on_error=True) del load_data[0:len(load_data)] print success, failed def update_by_id(self, row_obj): """ 根据给定的_id,更新ES文档 :return: """ _id = row_obj.get("_id", 1) row_obj.pop("_id") self.es_client.update(index=self.index, doc_type=self.doc_type, body={"doc": row_obj}, id=_id) def delete_by_id(self, _id): """ 根据给定的id,删除文档 :return: """ self.es_client.delete(index=self.index, doc_type=self.doc_type, id=_id) if __name__ == '__main__': write_obj = { "_id": 1, "document_id": 1, "title": u"Hbase 测试数据", "content": u"Hbase 日常运维,这是个假数据监控Hbase运行状况。通常IO增加时io wait也会增加,现在FMS的机器正常情况......", } load_es = LoadElasticSearch() # 插入单条数据测试 load_es.add_date(write_obj) # 根据id更新测试 # write_obj["title"] = u"更新标题" # load_es.update_by_id(write_obj) # 根据id删除测试 # load_es.delete_by_id(1) # 批量插入数据测试 # row_obj_list = [] # for i in range(2, 2200): # temp_obj = write_obj.copy() # temp_obj["_id"] = i # temp_obj["document_id"] = i # row_obj_list.append(temp_obj) # load_es.add_date_bulk(row_obj_list)
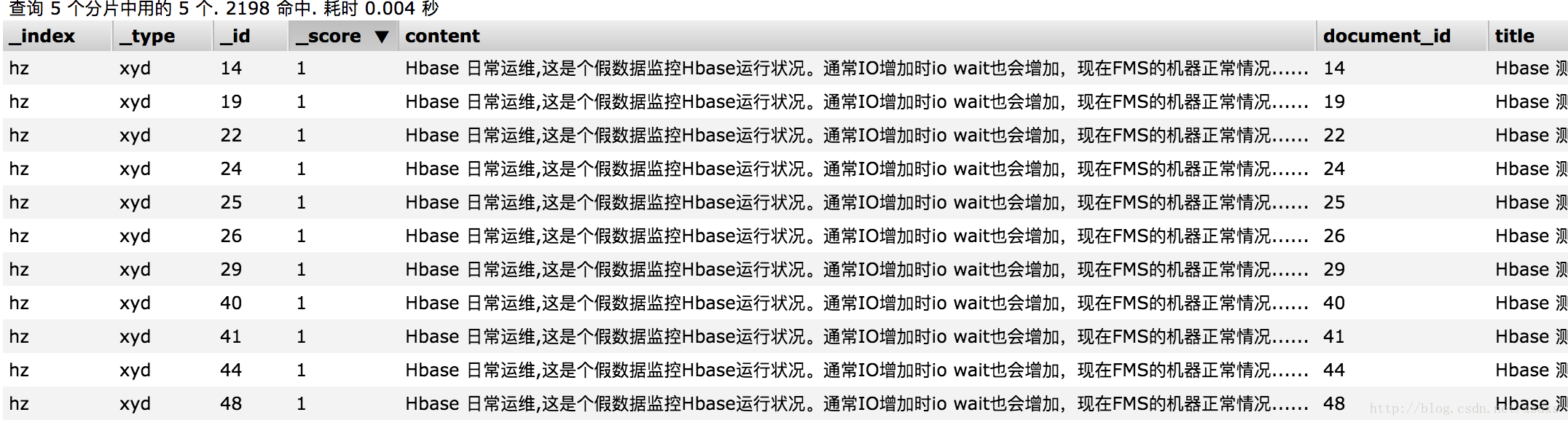
结果显示
单条增加:

单条修改:

单条删除:

批量增加:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号