基于三台云服务器搭建Hadoop3.3的分布式集群
基于三台云服务器搭建Hadoop3.3的分布式集群
之前写过基于三台云服务器搭建Redis,但是时过境迁那篇文章已经脱离时代了(主要是作者很菜)那时候我连Docker都没玩过更别说大数据了,现在需求推动人进步,这次我又来记录我搭建Hadoop的集群的过程。
确认服务器信息和其他
本人使用的是云服务器相关配置如下:
| 服务器信息 | 时间 | 配置 | 带宽 | 硬盘 | 价格 |
|---|---|---|---|---|---|
| 天翼云主机 | 一年 | 4核8G | 5M | 40G | 366 |
| 腾讯云主机 | 一年 | 2核4G | 3M | 50G | 468 |
| 亿速云主机 | 一月 | 2核2G | 3M | 20G | 39 |
| 阿里云主机(备用) | 一年 | 1核2G | 1M | 40G | 117(学生优惠续费) |
如果有上云需求的小伙伴建议还是买天翼云,真的很便宜(但是界面友好度还是不够,很多时候功能需要自己去找,其次我还是推荐腾讯云和阿里云毕竟做的久沉淀的东西越多,而且腾讯元的售后服务非常不错这个我很想点个赞,我遇到的问题很快能帮我解决而且提供技术参考!)白飘党还是看预算的,当然也又亚马逊云,不过得需要VISA信用卡,看你选择喽!此处不放连接了,有需要的自己去看。
PS:我还用过华为云和百度云,总结下来华为云是最让我。。。。的,无脑👎(个人见解!)
SSH工具:FinalShell(真的良心的国产SSH软件,从我从业以来一直在用!个人感觉非常好!)
IP地址(为了安全脱敏了):
master:182...0
cluster1:1...90
cluster2:42...25
配置服务器相关设置
2.1、所有服务器设置hostname和host
首先的设置hostname,如果你拿到新主机一定要设置hostname和hosts文件
vim /etc/hostname
然后设置成你想要的名称
vim /etc/hosts
之后可以将如下文件粘贴过去
你本机的ip(内网) localhost
::1 你的hostname 你的hostname
::1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
你本机的ip(内网) 你的hostname
cluster1的外网ip) cluster1的hostname
cluster2的外网ip) cluster2的hostname
这个host文件是以master为例,如果是在cluster机器上只需要把各自的机器换成master的外网ip和master的hostname
如果你使用的是finalshell的话,可以直接使用它内部的文件系统去寻找和打开,它会自动保存你修改的文件,之后重启机器
reboot
2.2、所有服务器设置ssh免登录本地连接
ssh-keygen -t rsa -P ''
将生成的秘钥添加到本地验证key中
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
之后
ssh localhost
输入yes和你的密码后即可看到你的控制台清空了,代表你已经重新连接这台服务器了了
切换到master主机连接cluster1和cluster2服务
ssh cluster1
ssh cluster2
输入密码后即可连接,如果连接失败,请检查各自的服务器是否开放端口和ssh服务启动以及ssh localhost可以成功。
连接之后会切换到对应的服务器,这个时候再新建一个master节点的session terminal,然后输入如下命令:
scp ~/.ssh/id_rsa.pub 连接的用户(我使用的是root)@你的cluster1 hostname:~/
scp ~/.ssh/id_rsa.pub 连接的用户(我使用的是root)@你的cluster2 hostname:~/
出现进度条则表示已经将服务器的验证公钥传输到两个从节点服务器了,可以切换到服务器去查看$home下,确认存在后在两个从节点服务器中输入如下命令:
```shell
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
```
接着为了安全起见删除从master传递过来的公钥文件
rm ~/id_rsa.pub
2.3、三个服务器安装Java和Hadoop
JDK8下载连接:https://www.oracle.com/java/technologies/downloads/#java8
Hadoop3.3下载连接:https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
JDK8不多说了,官网下载Linux版本后上传到三个服务器
在/home下创建java文件夹和Hadoop
cd /home
mkdir java
mkdir hadoop
将上传的文件包解压到/home/java下
tar -zxvf jdk1.8.tar.gz -C /home/java
接着将Hadoop包下载,目前最新的版本我用的是3.3
tar -zxvf hadoop3.3.tar.gz -C /home/hadoop
解压后建议将jdk和Hadoop解压后的文件夹重命名,我的是jdk1.8和hadoop-3.3.1
解压后需要设置环境变量:
vim /etc/profile
将下面的代码追加到后面
export PATH=/bin:/usr/bin:$PATH
#Java Configuration
export JAVA_HOME=/home/java/jdk1.8
export JRE_HOME=/home/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
#Hadoop Configuration
export HADOOP_HOME=/home/hadoop/hadoop-3.3.1
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
Esc回车后按:wq保存,接着使我们的配置生效的话使用如下命令
source ~/.bashrc
测试一下环境变量:
java -version
如果出现了Java的环境变量则代表生效了
三台机器只需要做一次,其他的复制过去就可以了
到这我们的第一步就算完成了,接着就是Hadoop的集群设置了
Hadoop搭建
3.1、创建Hadoop文件夹
mkdir ~/hadoop
mkdir ~/hadoop/tmp
mkdir ~/hadoop/var
mkdir ~/hadoop/dfs
mkdir ~/hadoop/dfs/name
mkdir ~/hadoop/dfs/data
3.2、修改core-site.xml文件
cd /home/hadoop/hadoop-3.3.1/etc/hadoop
vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<!-- 由于我的是root用户所以写成root,如果你创建的文件夹不在root下记得换掉 -->
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://你的hostname:9000</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<!-- 指定静态角色,HDFS上传文件的时候需要 -->
<value>root</value>
</property>
</configuration>
Esc按:wq保存
3.3、修改Hadoop-env.sh和yarn-env.sh文件
因为相对路径不能识别所以使用绝对路径
vim hadoop-env.sh
将注释的 export JAVA_HOME =
改为 export JAVA_HOME=/home/java/jdk1.8
Esc按:wq保存
同理修改
vim yarn-env.sh
3.4、修改hdfs-site.xml
下面的HDFS的存放路径,可以根据自己机器更改。
<configuration>
<property>
<name>dfs.name.dir</name>
<!-- 由于我的是root用户所以写成root,如果你创建的文件夹不在root下记得换掉 -->
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!-- 如果不设置的话,则需要在host文件中配置好映射你的hostnamme -->
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
3.5、修改mapred-site.xml
他是确定执行mapreduce的运行框架配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Esc按:wq保存
3.6、修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>你的hostname</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8182</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
Esc按:wq保存
3.7、修改集群配置
vim workers
将三台机器的hostname写入进去,一行一个
所有的操作只需要在master进行一次即可,其他节点的配置只需要将/etc/hadoop的文件直接拷贝即可
scp -r //home/hadoop/hadoop-3.3.1/etc/hadoop 用户(我是用的是root)@cluster1:/home/hadoop/hadoop-3.3.1/etc/hadoop
或者FinalShell直接将文件夹下载后再上传拿过去
3.8、格式化NameNode和DataNode
cd /home/hadoop/hadoop-3.3.1/bin
./hdfs namenode -format
./hdfs datanode -format
格式化成功后会生成version文件在~/hadoop/dfs/data/current中看到他基本上就成功了,但是他只会出现在master服务器中,并不会在两个从节点出现,因为从节点不会启动ResourceManager和SecondaryNameNode的服务。
测试搭建
cd /home/hadoop/hadoop-3.3.1/sbin
start-dfs.sh
start-yarn.sh
第一次登录会问你是否连接,输入yes后再输入密码就ok了
由于ssh已经测试过了,所以不会出现询问。
当主节点启动完成后在主节点和两个从节点输入jps查看
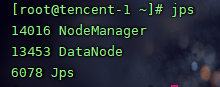
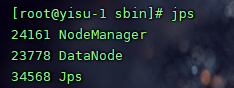
接着访问master节点的页面
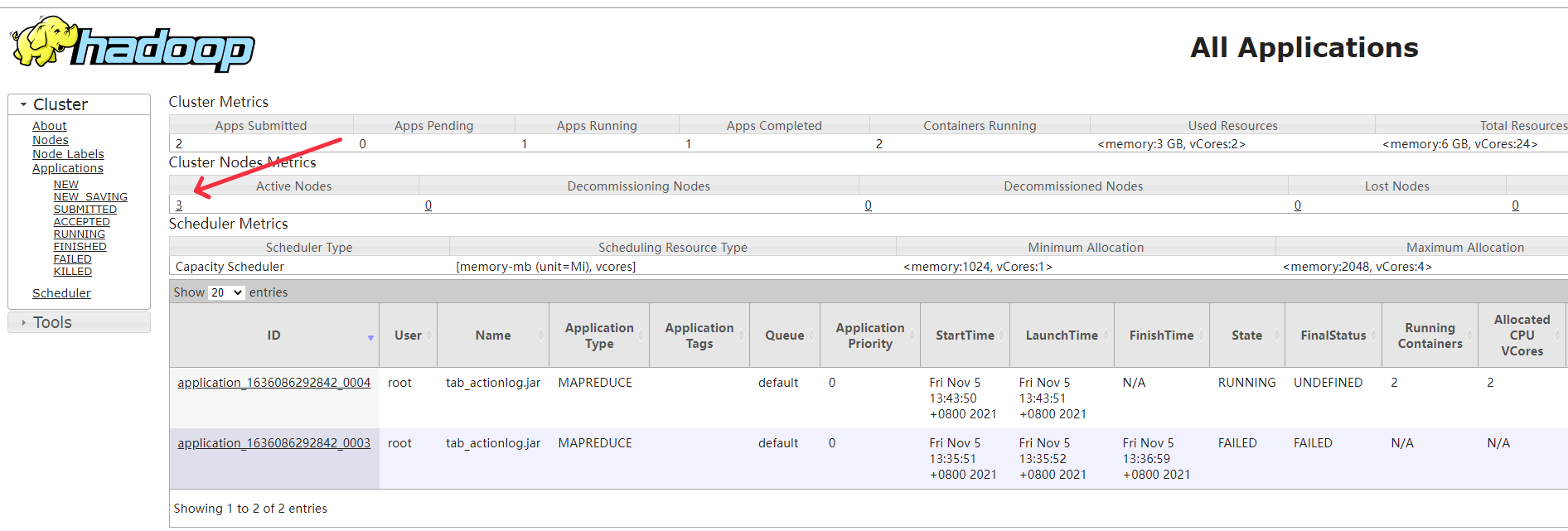
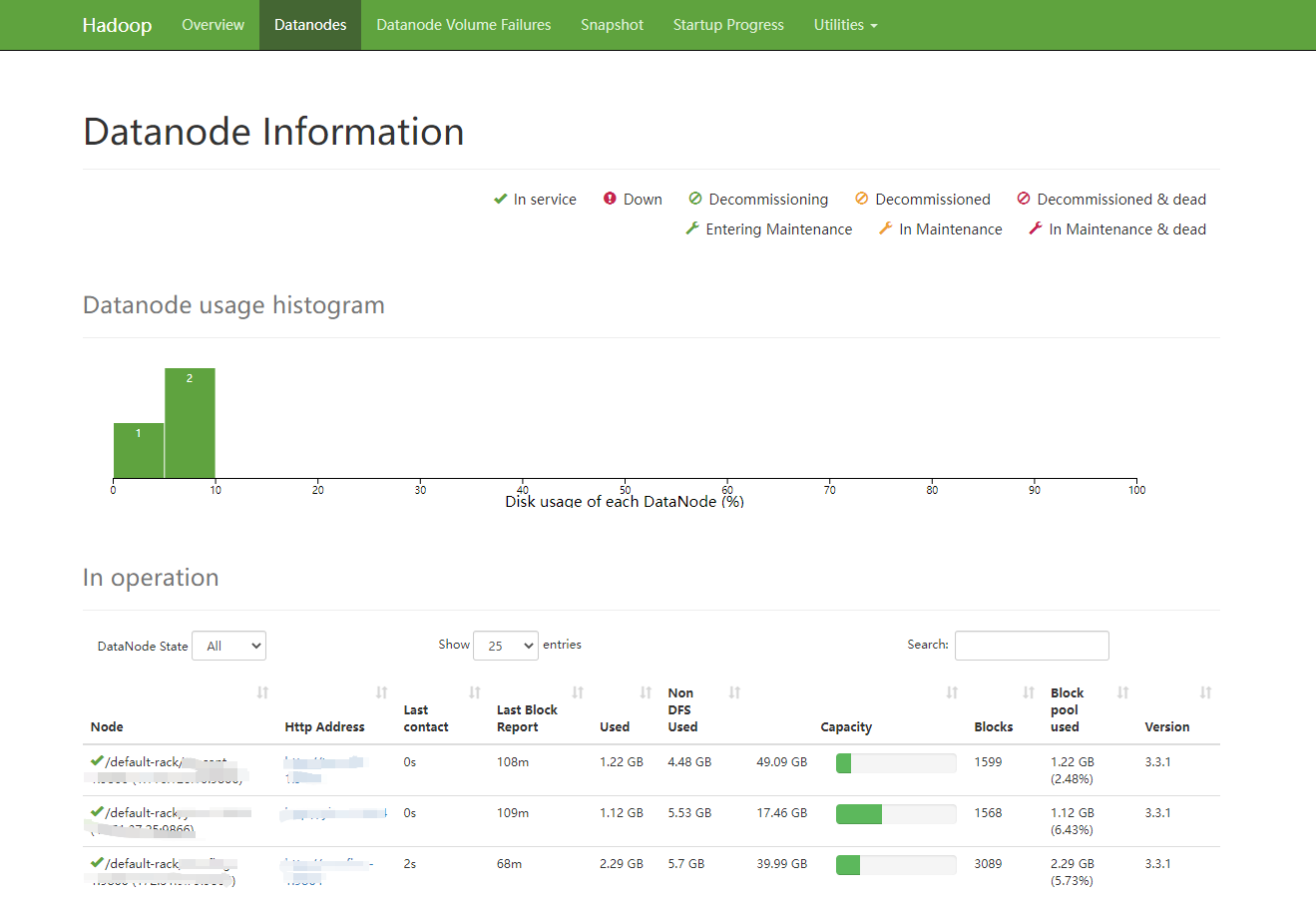
上述分别为8088端口和50070端口的访问页面,出现三个节点则代表你的分布式hadoop集群已经搭建成功了
Hadoop知识回顾
Hadoop是一个开源的大数据框架,是一个分布式计算的解决方案。
Hadoop包含三个核心:
一、HDFS
HDFS是分布式文件系统,有高容错性的特点,可以部署在价格低廉的服务器上,主要包含namenode和datanode。
Namenode是hdfs中文件目录和文件分配管理者,它保存着文件名和数据块的映射管理,数据块和datanode列表的映射关系。
其中文件名和数据块的关系保存在磁盘上,但是namenode上不保存数据块和datanode列表的关系,该列表是通过datanode上报建立起来的。
二、YARN
主要由:ResourceManager,nodeManager,ApplicationMaster,Container组成

ResourceManager(RM)
主要接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM),一个集群只有一个。
NodeManager(NM)
主要是节点上的资源管理,启动Container运行task计算,上报资源、container情况给RM和任务处理情况给AM,整个集群有多个。
ApplicationMaster(AM)
主要是单个Application(Job)的task管理和调度,向RM进行资源的申请,向NM发出launch Container指令,接收NM的task处理状态信息。每个应用有一个。
Container:
是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。当AM向RM申请资源时,RM为AM返回的资源便是Container表示的。
YARN会为每个任务分配一个Container,且该任务只能使用Container中描述的资源。
三、MapReduce
Hadoop的两个核心解决了数据存储问题(HDFS分布式文件系统)和分布式计算问题(MapRe-duce)。
MapReduce是hadoop的一种离线计算框架,适合离线批处理,具有很好的容错性和扩展性,适合简单的批处理任务。
Hadoop的特点:
一、扩容能力:能可靠地存储和处理千兆字节的数据。
二、成本低:可以通过普通机器组成的服务器群来分发以及处理数据,这些服务器群总计可达数千个。
三、高效率:通过分发数据,HADOOP可以在数据所在的节点上并行地处理他们,这使得处理的非常迅速。
四、可靠性:hadoop能自动地维护数据的多份副本,并且在任务失败后能自动的重新部署计算任务。
结束记录
在部署云服务器的时候会遇到很多问题,比如主机通信,安全组端口未开放,服务器无法登录之类的问题,下面我做个我目前遇到的问题以及解决方案
1、主机通信,确保主机可以ping通,如果ping不通则代表你的服务器是有问题的,但是这种情况很少。
2、安全组端口未开放导致端口50070或8848的页面无法访问,找你的安全组添加各自的IP访问即可。
3、服务器无法访问:这个情况我是重点要说的,便宜的云服务器由于没有任何安全措施设置的话会收到一个名叫kdevtempfsi的挖矿病毒攻击,而且我的每一台云服务器都遭受了该攻击,这个病毒导致我ssh目录和cron目录被删除,导致我无法连接服务器,而且攻击十分频繁!基本上每天白天我清理掉后晚上又会被继续攻击(主要是我的安全意识低下)
解决方案:
使用VNC登录服务器(在SSH不可用的前提下)
systemctl status sshd
查看ssh服务状态后如果是dead的话则需要检查内部情况
sshd -t
查看是否缺少了文件目录/var/empty/sshd
如果缺少则创建该目录
mkdir /var/empty
mkdir /var/empty/sshd
如果不缺少的话则直接启动ssh服务
service sshd start
此时应该可以连接SSH,
登录SSH后找到病毒文件地址
find / -name kdevtmpfsi
find / -name kinsing
rm -f 病毒的地址
找到进程并干掉它
ps -ef|grep kinsing
ps -ef|grep kdevtmpfsi
kill -9 pid
接着需要找到定时任务去kill
crontab -l
如果出现一条记录绑定IP且是国外的,那么就是这个挖矿病毒的,接着删除它
crontab -r
如果病毒反复攻击你的服务器,你要检查你的安全组放行,只针对固定IP固定端口开放,同时搭建Hadoop时没有启用kerberos认证,所以在服务安全上hadoop是不可靠的!
4、伴随着第三种情况,还会出现hadoop子节点异常造成僵尸进程占满CPU和内存资源,这时候需要kill -9 命令并重启机器可以解决。
本文引用以及推荐阅读:
https://blog.csdn.net/lz_1992/article/details/50166101 Hadoop的特点
https://blog.csdn.net/weixin_44161678/article/details/86019336 Hadoop的三大核心
https://segmentfault.com/a/1190000038390745 挖矿病毒解决
http://dblab.xmu.edu.cn/blog/1177-2/ 大数据分布式Hadoop集群部署方案
https://www.zhihu.com/question/333417513 Hadoop到底是干什么的
https://xuwujing.blog.csdn.net/article/details/78637874 大数据Hadoop单机搭建
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html Hadoop官方文档
推荐视频:
https://edu.fanruan.com/video/play/2095 数据仓库搭建实战以及Hadoop后续学习路线

 浙公网安备 33010602011771号
浙公网安备 33010602011771号