

Nova 操作汇总(限 libvirt 虚机) [Nova Operations Summary]
本文梳理一下 Nova 主要操作的流程。
0. Nova REST-CLI-Horizon 操作对照表
Nova 基本的 CRUD 操作和 extensions:
| # | 类别 | Nova V2 REST API Action | Nova CLI | Horizon | 解释 |
| 虚机操作 | POST | boot | Launch Instance |
启动一个新的虚机 |
|
| DELETE | delete | Terminate Instance |
关闭和删除一个虚机
|
||
| confirmResize | resize-confirm | N/A |
确认 resize 操作 |
||
| revertResize | resize-revert | N/A |
取消 resize 操作 |
||
| reboot | reboot [--hard] |
Soft Reboot Instance Hard Reboot Instance |
重启虚机,具体分析见本文 1. 章节 |
||
| changePassword | root-password | libvirt driver 没有实现 | |||
| resize | resize | Resize Instance | 迁移虚机或者改变虚机的flavor: http://www.cnblogs.com/sammyliu/p/4572287.html | ||
| rebuild | rebuild | Rebuild Instance | 先调用 driver.destroy (destroy domain,detach volume connections,plug VIF), 然后再调用 driver.spawn | ||
| createImage | image-create | N/A | 快照。http://www.cnblogs.com/sammyliu/p/4468757.html | ||
| os-start | start | Launch Instance | = hard reboot,见下面 1. 章节 | ||
| os-stop | stop | Shut Off Instance | call dom.destroy | ||
| admin action | pause | pause | Pause Instance | call dom.suspend | |
| unpause | unpause | Resume Instance | call dom.resume | ||
| suspend | suspend | N/A |
|
||
| resume | resume | N/A |
|
||
| migrate | migrate | N/A | http://www.cnblogs.com/sammyliu/p/4572287.html | ||
| resetNetwork | N/A | libvirt 没有实现 | |||
| injectNetworkInfo | N/A | Set up basic filtering (MAC, IP, and ARP spoofing protection),调用 _conn.nwfilterDefineXML(xml) | |||
| lock | lock | N/A | 直接在数据库中 instance 上面设置 lock = true | ||
| unlock | unlock | N/A | 直接在数据库中 instance 上面设置 lock = false | ||
| createBackup | backup | N/A |
同 createImage,可以指定类型(daily 或者 weekly),和保存的 image 的最大数目,老的 image 会被删除 {"backup_type": "daily", "rotation": "2", "name": "bk"} |
||
| os-migrateLive | live-migration | N/A | http://www.cnblogs.com/sammyliu/p/4572287.html | ||
| os-resetState | reset-state | N/A | 传入 state 参数,直接修改数据库中 instance 的状态 | ||
| bare metal | add_interface | baremetal-interface-add | TBD | ||
| remove_interface | baremetal-interface-remove | TBD | |||
| cloudpipe | update | cloudpipe-configure | TBD | ||
| console | os-getVNCConsole | get-vnc-console | Console |
见本文第四章节 |
|
| os-getSPICEConsole | get-spice-console | TBD | |||
| os-getRDPConsole | get-rdp-console | TBD | |||
| os-getSerialConsole | TBD | ||||
| os-getConsoleOutput | console-log | View Log | 读取 虚机的 console.log 文件并返回其内容;如果没有这文件的话,则使用 “pty”,将其内容写入到 consolue文件并返回其内容。 | ||
| delete | restore | restore | Terminate Instance | Restore a previously deleted (but not reclaimed) instance。直接修改数据库。 | |
| forceDelete | force-delete | N/A |
有 snapshot,则全部删除;然后从 DB 中删除 instance. |
||
| evacuate | evacuate | evacuate | 从 DB 中读取 instance 数据,在一个新的主机上 rebuild。 | ||
| flavor access | addTenantAccess | flavor-access-add | Flavor - Modify Access | 修改 DB 中 flavor 表 | |
| removeTenantAccess | flavor-access-remove | Flavor - Modify Access | 修改 DB 中 flavor 表 | ||
| flavor manage | delete | flavor-delete | Flavor - Delete Flavor | 直接 DB 操作 | |
| create | flavor-create | Flavor - Create Flavor | 直接 DB 操作 | ||
| floating ip | addFloatingIp | floating-ip-create | Associate Floating IP | 调用 network_api.associate_floating_ip | |
| removeFloatingIp | floating-ip-delete | Disassociate Floating IP | 调用 network_api.disassociate_floating_ip | ||
| NIC | addFixedIp | fixed-ip-reserve |
参数 "networkId"。
|
||
| removeFixedIp | fixed-ip-unreserve |
参数 "address"。
|
|||
| network associate | disassociate_host | Associate or disassociate host or project to network。 call network_api.associate | |||
| disassociate_project | network-disassociate | call network_api.associate | |||
| associate_host | network-associate-host | call network_api.associate | |||
| os network | disassociate | call network_api.associate | |||
| rescue | rescue | rescue | 见本文第二章节 | ||
| unrescue | unrescue | 见本文第二章节 | |||
| security group | addSecurityGroup | add-secgroup | call security_group_rpcapi.refresh_security_group_rules | ||
| removeSecurityGroup | secgroup-delete | call security_group_rpcapi.refresh_security_group_rules | |||
| shelve | shelve | shelve | 见本文第三章节 | ||
| shelveOffload | shelve-offload | 见本文第三章节 | |||
| unshelve | unshelve | 见本文第三章节 |
1. Reboot (重启)
物理机有两种重启方式:一种从操作系统中重启,一种直接先断电然后再接通电源。虚机的重启也有类似的两种方式:Soft Reboot 和 Hard Reboot。nova reboot 命令在不使用 “-hard” 情况下,默认会 Soft Reboot,如果失败则会 Hard reboot;如果使用了 “-hard”,则直接 Hard reboot。
1.1 Soft reboot
Soft reboot 完全依赖于虚机的操作系统和 ACPI。其过程为:
- Shutdown domain (domain.shutdown)
- Launch domain (domain.createWithFlags)
关于 shutdown API ,它会shutdown一个虚机,但是虚机的各种附件(object)依然可以使用,只是虚机的操作系统被停止了。注意,虚机的操作系统可能会忽略该请求。这时候,shutdown 不会成功(在 CONF.libvirt.wait_soft_reboot_seconds 指定的时间内,nova发现虚机没有被 shutdown),得转到 hard reboot 了。(Shutdown a domain, the domain object is still usable thereafter, but the domain OS is being stopped. Note that the guest OS may ignore the request.)
1.2 Hard reboot
Hard reboot 比 Soft reboot 复杂、耗时长。其主要过程为:
- Destroy domain (virt_dom.destroy())。Destroy 和 Shutdown 两个 API 的区别是:shutdown domain 以后,客户机的磁盘存储处于可用状态,而且该 API 在命令发给 Guest OS 后立即返回,客户程序需要不断检查其状态来判断是否shutdown 成功;而 destroy API 执行后,客户机的所有资源都会被归还给 Hypervisor (all resources used by it are given back to the hypervisor),它的过程是首先给客户机发送一个terminate 指令比如SIGTERM,如果在一定的时间内未成功则直接发送 SIGKILL 指令将虚机杀掉。
- 根据 domain 的信息(instance, network_info, disk_info,image_meta, block_device_info)重新生成 domain 的配置 xml
- 根据 image 重新生成各镜像文件(包括 disk,disk.local 和 disk.swap)
- 连接各个 volume
- 将各个 interface 挂到 OVS 上
- 重新生成和应用 iptales 规则
- Define domain (conn.defineXML)
- Launch domain (domain.createWithFlags)
可见,hard reboot 是真正的 reboot 一个虚机。来比较一下 hard reboot 前后的虚机的磁盘和xml 文件:
#reboot 前
root@compute2:/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd# ls -l total 2608 -rw-rw---- 1 root root 20126 Jun 10 12:38 console.log -rw-r--r-- 1 libvirt-qemu kvm 2162688 Jun 10 12:40 disk -rw-r--r-- 1 nova nova 246 Jun 10 07:54 disk.info -rw-r--r-- 1 libvirt-qemu kvm 393216 Jun 10 12:39 disk.local -rw-r--r-- 1 libvirt-qemu kvm 197120 Jun 10 07:54 disk.swap -rw-r--r-- 1 nova nova 3452 Jun 10 12:39 libvirt.xml
#reboot 后 root@compute2:/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd# ls -l total 2608 -rw-rw---- 1 root root 20126 Jun 10 12:38 console.log -rw-r--r-- 1 libvirt-qemu kvm 2162688 Jun 10 12:57 disk -rw-r--r-- 1 nova nova 246 Jun 10 07:54 disk.info -rw-r--r-- 1 libvirt-qemu kvm 393216 Jun 10 12:57 disk.local -rw-r--r-- 1 libvirt-qemu kvm 197120 Jun 10 07:54 disk.swap -rw-r--r-- 1 nova nova 3452 Jun 10 12:57 libvirt.xml root@compute2:/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd# diff libvirt.xml libvirt.xml.ori 10c10 < <nova:creationTime>2015-06-10 04:57:25</nova:creationTime> #domain 除了创建时间不同别的都相同 --- > <nova:creationTime>2015-06-10 04:39:14</nova:creationTime> 84c84 < <source host="127.0.0.1" mode="bind" service="10002"/> --- > <source host="127.0.0.1" mode="bind" service="10001"/>
2. Rescue (拯救)和 Unrescue
Rescue 是个很有意思的功能。它的一个使用场景是,虚机的启动盘的一个文件被误删除了导致无法再次启动了,或者 admin 的密码忘记了。Rescue 功能提供一个解决这类问题的手段。
执行 nova rescue 命令后的主要过程是:
(1)保存目前domain 的 xml 配置到 unrescue.xml 文件
(2)根据 image 重新生成启动盘 disk.swap (大小不受 falvor.root_disk_size 控制,尽可能小的一个文件)
root@compute2:/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd# qemu-img info disk.rescue image: disk.rescue file format: qcow2 virtual size: 39M (41126400 bytes) #不是 falovr 里面定义的 1G 大小 disk size: 1.6M cluster_size: 65536 backing file: /var/lib/nova/instances/_base/fbad3d96a1727069346073e51d5bbb1824e76e34 Format specific information: compat: 1.1 lazy refcounts: false
(3)构造一个新的 domain 的 xml 配置,使用 disk.rescue 做启动盘,将原来的 disk 挂载到该 domain,其他的盘和volume不会被挂载。
<disk type="file" device="disk"> <driver name="qemu" type="qcow2" cache="none"/> <source file="/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd/disk.rescue"/> #新构造的启动盘 <target bus="virtio" dev="vda"/> </disk> <disk type="file" device="disk"> <driver name="qemu" type="qcow2" cache="none"/> <source file="/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd/disk"/> #原来的启动盘 <target bus="virtio" dev="vdb"/> </disk>
(4)将原来的 domain destroy 掉 (virt_dom.destroy)
(5)定义新的 domain (conn.defineXML(xml))
(6)启动新的 domain (domain.createWithFlags)
至此,nova rescue 的过程完成。用户可以 ssh 到新的虚机,修改 “Vdb“分区中的受损害的文件。然后执行 ”nova unrescue“命令。其主要过程是:
(1)读取之前保存的 unrescue.xml 文件
(2)将 rescued domain destroy 掉
(3)定义和启动新的domain(同上面5和6)
(4)删除 unrescue.xml 文件
注意,这时候文件夹中的 libvirt.xml 文件和新运行的 domain 的 xml 不一致,因为代码中没有将新的 domain 的xml 写到该文件。
3. Shelve (搁置)和 unshelve
当一个虚机不需要使用的时候,可以将其 shelve 起来。该操作会创建该虚机的一个快照并传到 Glance 中,然后在 Hypervisor 上将该虚机删除,从而释放其资源。
其主要过程为:
- destroy 虚机 (virt_dom.destroy())
- snapshot 该 domain
- 如果 CONF.shelved_offload_time == 0 的话,将domain 的各种资源(interface,volume,实例文件等),然后将其undefine (virt_dom.undefine())
其只存在于数据库和 Glance 中。运行 nova list 能看到一条记录:
| 8352e969-0a25-4abf-978f-d9d0ec4de0cd | vm11 | SHELVED_OFFLOADED | - | Shutdown | demo-net2=10.0.10.14; demo-net=10.0.0.41 |
运行 glance image-list 能看到其image:
| 6ed6eb92-ce42-46d1-ab46-259e3e235304 | vm11-shelved | qcow2 | bare | 19988480 | active |
能看到该 image 的 instance 相关的属性:
s1@controller:~$ glance image-show 6ed6eb92-ce42-46d1-ab46-259e3e235304 +---------------------------------------+--------------------------------------+ | Property | Value | +---------------------------------------+--------------------------------------+ | Property 'base_image_ref' | bb9318db-5554-4857-a309-268c6653b9ff | | Property 'image_location' | snapshot | | Property 'image_state' | available | | Property 'image_type' | snapshot | | Property 'instance_type_ephemeral_gb' | 1 | | Property 'instance_type_flavorid' | 129f237e-8825-49fa-b489-0e41fb06b70e | | Property 'instance_type_id' | 8 | | Property 'instance_type_memory_mb' | 50 | | Property 'instance_type_name' | tiny2 | | Property 'instance_type_root_gb' | 1 | | Property 'instance_type_rxtx_factor' | 1.0 | | Property 'instance_type_swap' | 30 | | Property 'instance_type_vcpus' | 1 | | Property 'instance_uuid' | 8352e969-0a25-4abf-978f-d9d0ec4de0cd | | Property 'network_allocated' | True | | Property 'owner_id' | 74c8ada23a3449f888d9e19b76d13aab | | Property 'user_id' | bcd37e6272184f34993b4d7686ca4479 |
Unshelve 是 shelve 的反操作。它的主要过程是:
- 从 DB 中获取 network_info 和 block_device_info
- 从 Glance 中获取 image
- 象新建一个虚拟那样 spawn 新的虚机
- 调用 image API 将 image 删除
4. VNC (VNC 连接)
VNC 操作的过程:(来源)
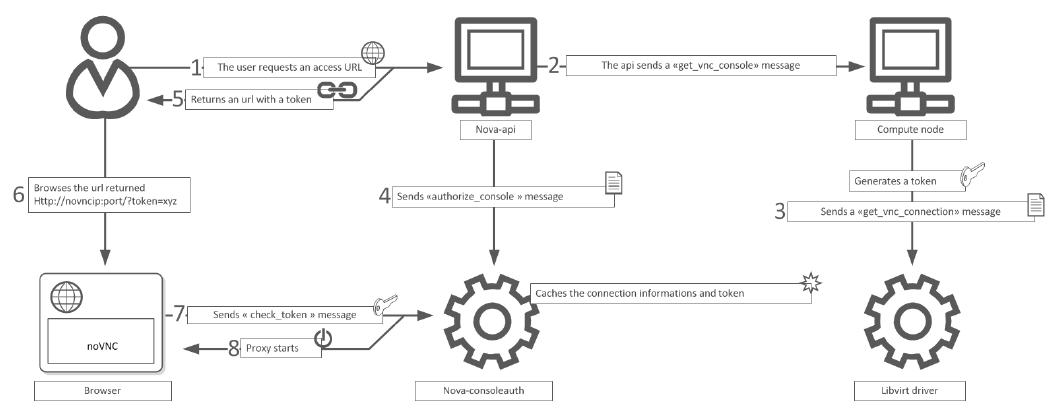
(1)用户查询 VNC 的访问 URL。
Nova CLI 对应的命令为 “nova get-vnc-console <server> <console-type>”。 REST API 的数据格式为:{"os-getVNCConsole": {"type": "novnc"}}
“type” 参数值可以是 “novnc” 或者 “xvpvnc”。
(2)通过 RPC 调用虚机所在的 node 上的 Nova 生成一个 UUID(长度为 4)格式的 token,以及格式为 ‘<base_url>?token=<token>' 的 Access URL。
- base_url 从 CONF.novncproxy_base_url (比如 http://192.168.1.20:6080/vnc_auto.html)或者 CONF.xvpvncproxy_base_url 读取。
(3)本地Nova 调用 libvirt driver 从 domain xml 中获取 port,比如下面例子中的 5900,以及从 confi.vncserver_proxyclient_address 获取 host。
<graphics type='vnc' port='5900' autoport='yes' listen='0.0.0.0' keymap='en-us'>
<listen type='address' address='0.0.0.0'/>
</graphics>
(4)通过 RPC,调用 consoleauth 的 authorize_console 方法,它将 Access URL, host,port 保存到 memcached。
(5)返回 Access URL 给客户端,比如 http://192.168.1.20:6080/vnc_auto.html?token=8dc6f7cb-2e2d-4fbe-abab-3334fe3a19dc
在 Contoller 节点上运行着一个service “/usr/bin/python /usr/bin/nova-novncproxy --config-file=/etc/nova/nova.conf”。该 service 默认在 6080 端口(可由 CONF.novncproxy_port 配置)监听来自所有地址(可由 CONF.novncproxy_host 配置)的请求。
(6)在客户端浏览器上打开 Access URL,由 Controller 上的 nova-novncproxy 接收并处理
(7)nova-novncproxy 通过 RPC 调用 consoleauth.check_token() 方法,获取 console_type 和 port 等 connect info。期间还会到目的node上去校验这些信息。
{u'instance_uuid': u'7c53af66-765b-48f3-b8a2-a908feb63968', u'internal_access_path': None, u'last_activity_at': 1434670235.591856, u'console_type': u'novnc', u'host': u'192.168.1.15', u'token': u'10bffd07-e11c-48bb-880a-bc1a49c871d7', u'port': u'5900'}
(8)连接到目的 node,握手,开始 proxying。
与 NOVNC 有关的配置参数:
| 节点 | 配置文件 | 参数 | 默认配置 | 说明 |
| Controller | /etc/nova/nova.conf | novncproxy_port | 6080 | /usr/bin/nova-novncproxy 服务所在的节点(通常是 Controller 节点)上 该 service 所监听的端口。奇怪的是 nova 文档中没说明该配置参数。 |
| novncproxy_host | 0.0.0.0 | nova-novncproxy service 所监听的请求来源地址。0.0.0.0 表示接收所有来源的请求。奇怪的是 nova 文档中没说明该配置参数。 | ||
| nova-compute | /etc/nova/nova.conf | vncserver_proxyclient_address | 虚机所在的 nova compute 节点的 management 网卡的 IP 地址 | |
| vncserver_listen | 127.0.0.1 | 虚机所在的 nova compute 节点的 vnc service 所监听的端口,需要修改默认配置为其 0.0.0.0 | ||
| novncproxy_base_url |
http://127.0.0.1:6080/ |
nova 客户端通过 get_vncconsole 命令获取到的访问虚机的 VNC URL。需要修改其值为
http://<nova-novncproxy-node-management-interface-ip>:<nova-novncproxy-node-nova.conf.novncproxy_port>/vnc_auto.html 比如 http://192.168.1.20:6080/ |
||
| vnc_enabled |
true |
使得虚机能够对外提供 VNC 服务 |
5. Evacuate (移机)
作用:当一个 node down 掉后,在新的 node 上根据其 DB 中保存的信息重新 build down node 上虚机。这个往往在虚机 HA 方案中用到。它尽可能地将原来的虚机在新的主机上恢复:
- 虚机的配置:从 DB 中获取,包括 image,block,network 等
- 虚机的数据:如果使用共享存储,则使用共享存储上的虚机数据;如果不使用共享存储,则无法恢复数据
- 内存状态:无法恢复
因此,HA 方案中,应该尽可能地将虚机的数据文件放在共享存储上,否则,恢复出来的虚机的价值非常有限。
Nova CLI:usage: nova evacuate [--password <password>] [--on-shared-storage] <server> [<host>]
要求:
(1)必须指定和虚机的 host 不同的 host,否则将报错“The target host can't be the same one”。
(2)虚机的host 必须处于不可用状态,否则将报错 “Compute service of compute2 is still in use.”
(3)可以指定新的 admin password,不指定的话,nova 将生成一个随机密码
(4)参数 on-shared-storage 表示虚机的 instance folder 是不是在共享存储上。
主要步骤:
(1)在做完以上各种参数检查后,调用 Conductor 的 方法:
return self.compute_task_api.rebuild_instance(context, instance=instance, new_pass=admin_password, injected_files=None, image_ref=None,
orig_image_ref=None, orig_sys_metadata=None, bdms=None, recreate=True, on_shared_storage=on_shared_storage, host=host)
如果 host 为none 的话,conductor 将调用 scheduler 的方法选择一个 host。
(2)接着调用 nova compute 的 rebuild_instance 方法。该方法从系统(DB)中获取已有的数据,然后根据这些已有的 metadata 重新构造domain。“A 'rebuild' effectively purges all existing data from the system and remakes the VM with given 'metadata' and 'personalities'.”
- 获取 image_ref,再获取 image meta
- 获取 network_info 并在新的 host 上构造网络
- 获取 BlockDeviceMappingList
- 获取 block_device_info
(3)然后调用 virt driver 的 rebuild 方法,但是 libvirt 没有实现该方法,转而调用 _rebuild_default_impl 方法。该方法:
- 从 volume 端断开其与原来 host 的连接
- 调用 driver.spawn 方法构造新的 domain,依次创建 image(如果 on_shared_storage = false 的话,则重新下载 image, 构造 instance folder;如果 on_shared_storage = true 的话,则直接使用共享存储上的 instance folder。这也可见使用共享存储的优势),network 和 domain,并设置 domain 的状态和之前一致。
(4)在坏了的 host 被重启后,nova-compute 服务调用 _destroy_evacuated_instances 方法来找到 evacuated instances 并将它们删除:
- 调用 libvirt 找到该 host 上所有 domains,然后在 nova db 中一一查找其状态,过滤出 “deleted” 为 false 的 domains
- 如果instance.host 不是本机,而且 instance.task_state 不是 { MIGRATING,RESIZE_MIGRATING,RESIZE_MIGRATED,RESIZE_FINISH} 之一,则删除该 domain,以及 network,block device 以及 instance folder。
总之,在使用共享存储的情况下,evacuate 出来的新的 domain 除了临时盘上的数据外,它和之前的 domain 的数据是一样的了,但是内存状态除外。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号