

Hadoop 分布式文件系统 - HDFS
当数据集超过一个单独的物理计算机的存储能力时,便有必要将它分不到多个独立的计算机上。管理着跨计算机网络存储的文件系统称为分布式文件系统。Hadoop 的分布式文件系统称为 HDFS,它 是为 以流式数据访问模式存储超大文件而设计的文件系统。
- “超大文件”是指几百 TB 大小甚至 PB 级的数据;
- 流式数据访问:HDFS 建立在这样一个思想上 - 一次写入、多次读取的模式是最高效的。一个数据集通常由数据源生成或者复制,接着在此基础上进行各种各样的分析。HDFS 是为了达到高数据吞吐量而优化的,这有可能以延迟为代价。对于低延迟访问,HBase 是更好的选择。
- 商用硬件:即各种零售店都能买到的普通硬件。这种集群的节点故障率蛮高,HDFD需要能应对这种故障。
因此,HDFS 还不合适某些领域:
- 低延迟数据访问:需要低延迟数据访问在毫秒范围内的应用不合适 HDFS
- 大量的小文件:HDFS 的 NameNode 存储着文件系统的元数据,因此文件数量的限制也由NameNode 的内存量决定。
- 多用户写入、任意修改文件:HDFS 中的文件只有一个写入者,而且写操作总是在文件的末尾。它不支持多个写入者,或者在文件的任意位置修改。
1. Hadoop V1 中HDFS 的架构和原理
1.1 HDFS 的结构
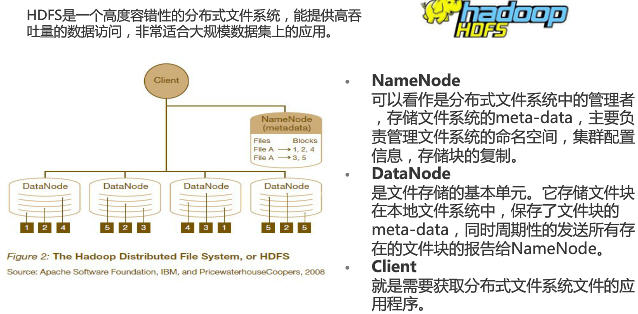

这里的 Client 代表用户通过名称节点和数据节点交互来访问整个文件系统。它提供一个类似于 POSIX 的文件系统接口,因此用户在编程时并不需要知道名称节点和数据节点及其功能。
Client 通过 RPC 来调用 NameNode 和 DataNode。


1.2 HDFS 中的文件操作
1.2.1 文件读取
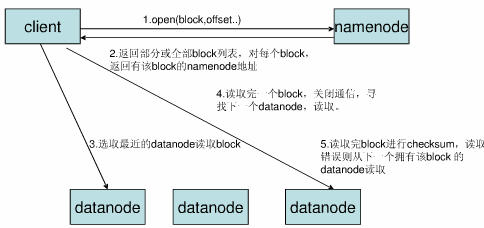
1.2.2 文件写入

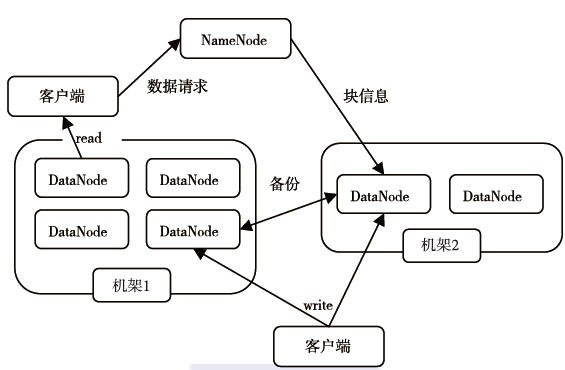
1.2.3 副本放置策略
- 一份放置在于客户端相同的节点上。若客户端运行在集群之外,NameNode 会随即选择节点,不过系统会避免挑选那些太满或者太忙的节点。
- 一份放在与与第一份不同的随即选择的机架上(离架)
- 最后一份放在与第二份相同的机架上,但放在不同的节点上。

1.2.4 文件复制
1.3 HDFS 适用的场景

1.4. Hadoop 1.0 中 HDFS 的缺陷
当前namenode中的namespace 和 block management 的结合使得这两层架构耦合在一起,难以让其他可能namenode实现方案直接使用block storage。
2. namenode扩展性
HDFS的底层存储是可以水平扩展的(解释:底层存储指的是datanode,当集群存储空间不够时,可简单的添加机器已进行水平扩展),但namespace不可以。当前的namespace只能存放在单个namenode上,而namenode在内存中存储了整个分布式文件系统中的元数据信息,这限制了集群中数据块,文件和目录的数目。
3. 性能
文件操作的性能制约于单个namenode的吞吐量,单个namenode当前仅支持约60K的task,而下一代Apache MapReduce将支持多于100K的并发任务,这隐含着要支持多个namenode。
4. 隔离性
现在大部分公司的集群都是共享的,每天有来自不同group的不同用户提交作业。单个namenode难以提供隔离性,即:某个用户提交的负载很大的job会减慢其他用户的job,单一的namenode难以像HBase按照应用类别将不同作业分派到不同namenode上。
2. Hadoop 2 中的 HDFS
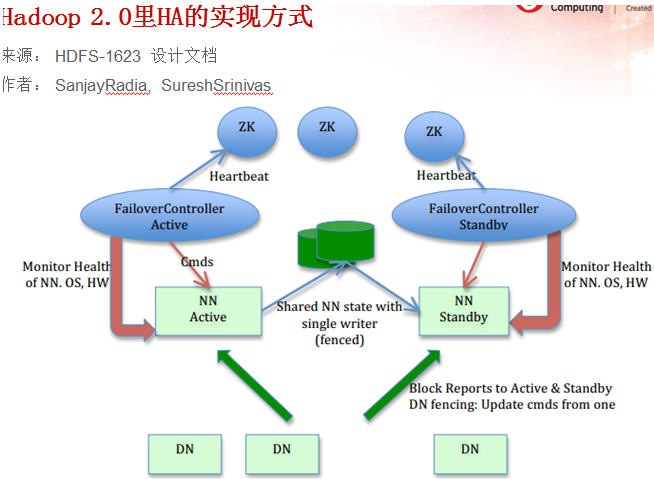
2.1 HDFS HA:解决 NameNode 单点故障
在Hadoop 2.0之前,也有若干技术试图解决 NameNode 单点故障的问题,在这里做个简短的总结
- Secondary NameNode:它不是HA,它只是阶段性的合并edits和fsimage,以缩短集群启动的时间。当NameNode(以下简称NN)失效的时候,Secondary NN并无法立刻提供服务,Secondary NN甚至无法保证数据完整性:如果NN数据丢失的话,在上一次合并后的文件系统的改动会丢失。
- Backup NameNode (HADOOP-4539)。它在内存中复制了NN的当前状态,算是Warm Standby,可也就仅限于此,并没有failover等。它同样是阶段性的做checkpoint,也无法保证数据完整性。
- 手动把name.dir指向NFS。这是安全的Cold Standby,可以保证元数据不丢失,但集群的恢复则完全靠手动。
- Facebook AvatarNode。Facebook有强大的运维做后盾,所以Avatarnode只是Hot Standby,并没有自动切换,当主NN失效的时候,需要管理员确认,然后手动把对外提供服务的虚拟IP映射到Standby NN,这样做的好处是确保不会发生脑裂的场景。其某些设计思想和Hadoop 2.0里的HA非常相似,从时间上来看,Hadoop 2.0应该是借鉴了Facebook的做法。
- 还有若干解决方案,基本都是依赖外部的HA机制,譬如DRBD,Linux HA,VMware的FT等等。
2.2 HDFS Federation:解决 NameNode 扩展性和性能问题
2.2.1 HDFS Federation 架构
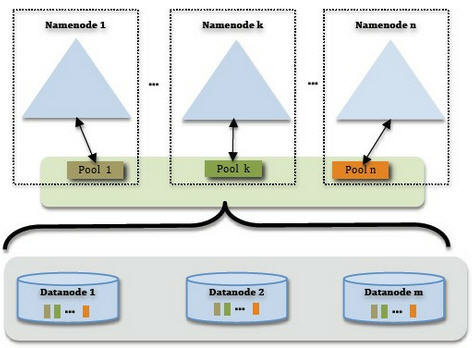
为了水平扩展namenode,Federation使用了多个独立的 namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
一个block pool由属于同一个namespace的数据块组成,每个datanode可能会存储集群中所有block pool的数据块。
每个block pool内部自治,也就是说各自管理各自的block,不会与其他block pool交流。一个namenode挂掉了,不会影响其他namenode。
某个namenode上的namespace和它对应的block pool一起被称为namespace volume。它是管理的基本单位。当一个namenode/nodespace被删除后,其所有datanode上对应的block pool也会被删除。当集群升级时,每个namespace volume作为一个基本单元进行升级。
2.2.2 HDFS Federation 优点
扩展性和隔离性:支持多个namenode水平扩展整个文件系统的namespace。可按照应用程序的用户和种类分离namespace volume,进而增强了隔离性。
通用存储服务:Block Pool 抽象层为HDFS的架构开启了创新之门。分离block storage layer使得:
<1> 新的文件系统(non-HDFS)可以在block storage上构建
<2> 新的应用程序(如HBase)可以直接使用block storage层
<3> 分离的block storage层为将来完全分布式namespace打下基础
设计简单:Federation 整个核心设计实现大概用了4个月。大部分改变是在Datanode、Config和Tools中,而Namenode本身的改动非常少,这样 Namenode原先的鲁棒性不会受到影响。虽然这种实现的扩展性比起真正的分布式的Namenode要小些,但是可以迅速满足需求,另外Federation具有良好的向后兼容性,已有的单Namenode的部署配置不需要任何改变就可以继续工作
2.2.3 HDFS Federation不足
1.单点故障问题
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。
2. 负载均衡问题
HDFS Federation采用了Client Side Mount Table分摊文件和负载,该方法更多的需要人工介入已达到理想的负载均衡。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端