

理解OpenShift(6):集中式日志处理
理解OpenShift(1):网络之 Router 和 Route
理解OpenShift(5):从 Docker Volume 到 OpenShift Persistent Volume
** 本文基于 OpenShift 3.11,Kubernetes 1.11 进行测试 ***
1. Docker 容器日志处理的几种方式
(1)由应用自己处理日志,而不需要容器引擎参与
比如一个使用Log4j2 日志组件的Java应用, 它通过日志组件将日志发往一个远端日志服务器。此时,不利用容器引擎的日志功能。
(2)使用数据卷(Data volume)
使用数据卷,容器内应用将日志写入数据卷中。此时,也不利用容器引擎的日志功能。
(3)使用 Docker 日志驱动(logging driver)
Docker 日志驱动会读取容器中主进程的 stdout(标准输出) 和 stderr(错误输出),然后将内容写入容器所在的宿主机上的文件中。
Docker 支持多种日志驱动。
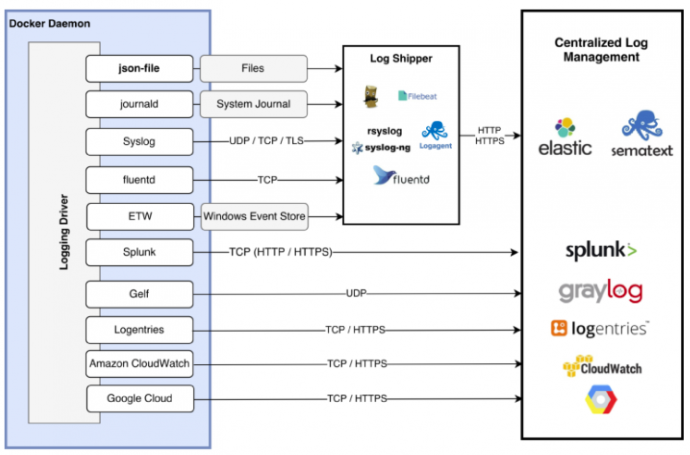
(图片来源:https://jaxenter.com/docker-logging-gotchas-137049.html)
几个比较常见的:
- json-file: 这是默认驱动。容器主进程(PID 为1的进程)的 stdout 和 stderr 会被输出到宿主机上的 JSON 文件。该文件可以在 docker inspect 命令的"LogPath"输出中看到,比如 "LogPath": "/var/lib/docker/containers/a44b41506dc48a469fd69ddbdf84ad16d14f16191164361a69606c579c506a2c/a44b41506dc48a469fd69ddbdf84ad16d14f16191164361a69606c579c506a2c-json.log"。
- syslog: 将日志信息发送到 syslog 服务器
- journald: 将容器日志信息写入journald (journald 是 systemd 提供的一个日志服务)
- gelf: 将日志消息写入一个 GELF 端点,比如 Logstash
- fluentd: 将日志信息发送到 Fluentd 服务
更多日志驱动,可以查看 https://docs.docker.com/config/containers/logging/configure/#supported-logging-drivers。
Docker 还支持插件形式的更多日志驱动,具体请看 https://docs.docker.com/config/containers/logging/plugins/。
(4)使用专门的日志容器
Docker 日志驱动这种实现方式有一些限制:
- 只支持日志转发,不会做日志解析和处理
- 只支持容器内应用发到 stdout 和 stderr 的日志,不支持其它日志,比如日志文件内的日志
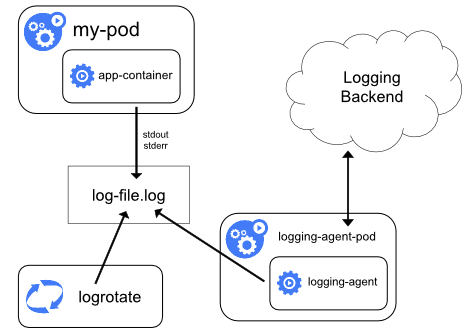
对于这些不支持的场景,比如应用有将日志写到日志文件,此时可以利用在同一个Pod中的专门日志容器。它会以边车(sidecar)形式读取应用容器中的日志产生,然后做处理和转发,比如转发到 stdout 和 stderr。

另外,某些这种场景还有另外一种更简单的处理方式。以 Nginix 为例,它默认写入日志文件,然后通过下面的方式,将日志也输出到 stdout 和 stderr。这种方式有一些限制,具体可参考 https://github.com/moby/moby/issues/19616:
# forward request and error logs to docker log collector RUN ln -sf /dev/stdout /var/log/nginx/access.log \ && ln -sf /dev/stderr /var/log/nginx/error.log
2. Kubernetes/OpenShfit 日志处理
2.1 EFK 概述
OpenShift/Kubernetes 环境的日志处理可分为三个发展阶段,或三种处理类型:
| 类型 | 说明 | 使用方式 |
| 容器本地日志(container local logging) | 写到容器内部的标准输出(standard output)和标准错误流(stand error),或者容器内日志文件。这种日志的问题是当容器死掉后,日志也会丢失,也就无法再访问了。 | 需登录进容器查看日志文件,或使用容器命令获取日志。OpenShift 提供 oc rsh 命令以进入容器,oc logs 命令以获取日志。 |
| 节点本地日志(node-level logging) | 容器引擎将容器中所有的标准输出和标准错误输出都转发到容器所在的本地节点上。Docker 可利用其日志驱动(logging driver)。为了避免容器中的日志将节点撑爆,可以做 log rotation。这种方式比 local logging 方式要好,但是还不是非常好,因为日志会保存在本地节点上。 | 需登录宿主机,查看本地日志文件 |
| 集群集中日志(cluster-level-loggin) | 这需要另外的后端来存储、分析和查询日志。后端可以在集群内,也可在集群外。一个 node-level 日志处理插件(比如 Fluentd)会运行在每个节点上,将节点上的日志发到集中的日志处理后端。还有一个可视化组件,让用户可以可视化地查看日志。 | 可通过浏览器或其它可视化界面在线查看日志 |
EFK(ElasticSearch - Fluentd - Kibana)是一种能够实现集群集中日志处理的开源套件。其中,
- Fluentd 作为日志代理,在每个节点上负责日志收集。其官网为 https://www.fluentd.org/。
- ElasticSearch 负责日志集中存储。其官网为 https://www.elastic.co/products/elasticsearch。
- Kibana 负责日志展示和查询。用户可以通过浏览器访问。其官网为 https://www.elastic.co/products/kibana。
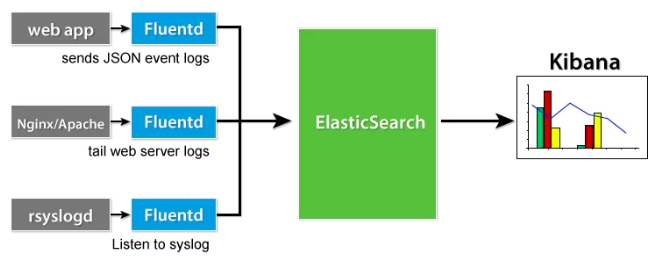
三个组件中,Fluentd 会直接和Docker/K8S/OKD打交道,而 ES 和 Kibana 则相对独立,不和容器集群有直接关系,除了用户校验以外。Fluentd 致力于解决多种日志来源和多种日志存储之间的复杂问题。它作为日志和日志存储之间的中间件,负责日志的收集、过滤和转发工作。
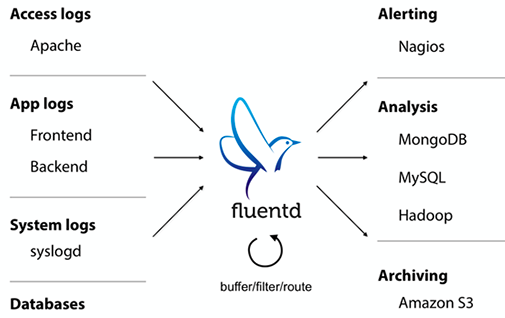
Fluentd 采用插件形式的架构,支持为了满足各种需求的日志采集、过滤、缓存和输出等功能。其v0.12 版本架构如下:
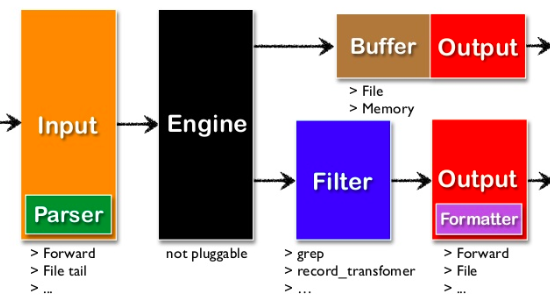
其中:
- Input: 告诉 Fluentd 引擎待收集的日志
- Engine: 主引擎,实现核心功能,比如缓存(buffering)、错误处理、消息路由等
- Output: 告诉 Fluentd 将输出的日志发往何处,通过插件支持多种目的,比如 ElasticSearch、MongoDB 或数据库等。
2.2 OpenShift 环境中的EFK
2.2.1 EFK 部署
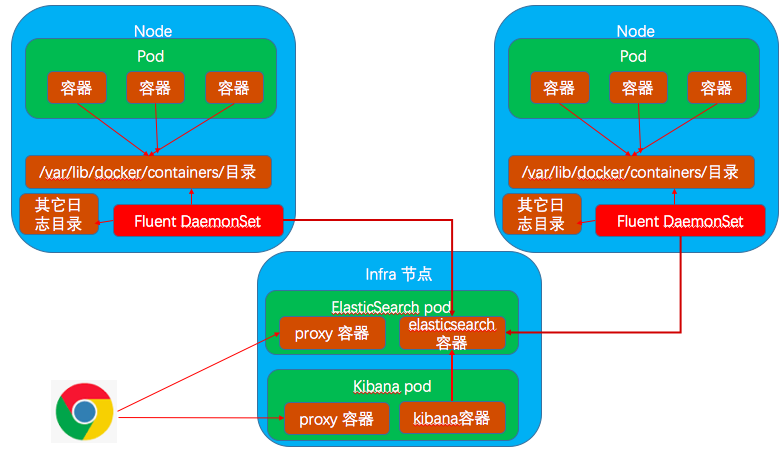
2.2.2 Fluentd
在 K8S/OKD 环境中,Fulentd 以 DeamonSet 形式运行在每个节点上。它会以 Volume 形式将所在宿主机上的多个保存日志的目录或文件挂载进容器,以被容器中的Fluentd进程所读取:
- /run/log/journal:这是系统 systemd 输出日志的目录。
- /var/log:这是系统所有日志的根目录。
- /var/lib/docker:Docker 容器引擎通过日志驱动将本机上所有容器的标准输出和标准错误输出保存在该目录中,每个容器一个文件。
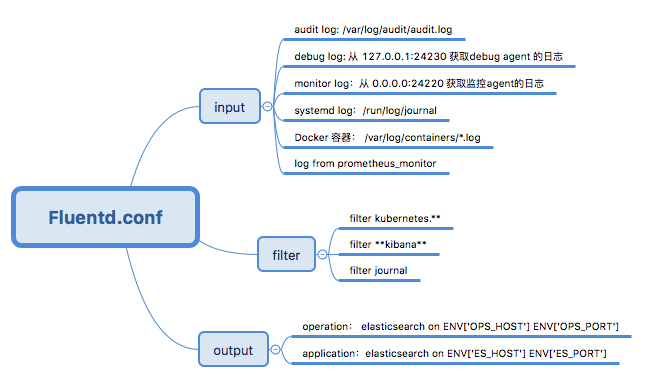
Fluentd 的配置文件被创建了一个 OpenShfit ConfigMap 对象(名为logging-fluentd),然后该对象被以 Volume 形式挂载为Fluentd容器目录 /etc/fluent/configs.d/user。其中的配置文件 fluentd.conf 指定了Fluentd 所使用的 input、filter 和 output 插件及其配置:

其中
- input 指定了将被收集的日志,主要包括 audit log、容器 log 和 systemd log 等。
- filter 部分则指定了各种过滤和处理被收集到的日志的方式。
- output 定义了目标 ElasticSerach。K8S/OKD EFK 允许存在两个 ES 集群,一个用于保存容器中应用的日志,一个用于保存系统日志。
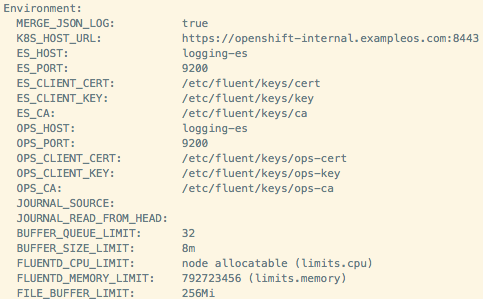
ES 环境的信息以环境变量的形式保存在 Fluentd pod 上:
2.3 采用EFK后的好处和影响
| 被影响人员 | 影响(好的方面) | 影响(不好的方面)/要求 |
| 容器云平台运维人员 |
|
|
| 容器应用开发人员 |
|
|
| 容器云平台研发团队 |
|
|
3. 日志系统的集中部署模式
备注:本部分内容引用自 http://blog.51cto.com/13527416/2051506。
3.1 简单架构
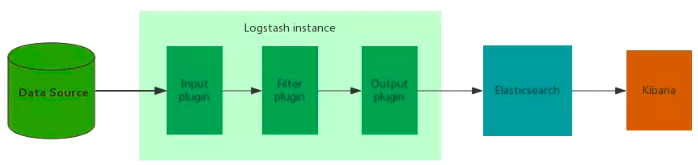
这种架构只适合于开发测试环境,以及小型生产环境。
3.2 集群架构
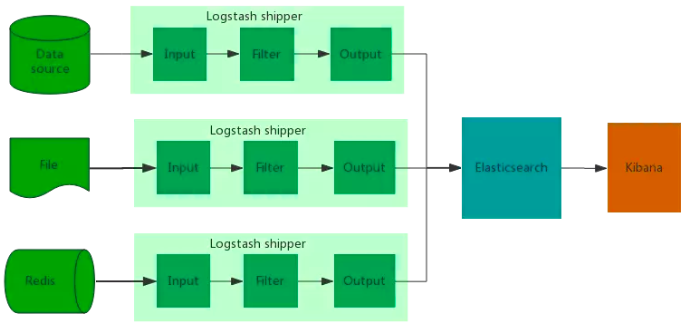
这种架构适合于较大型但是日志产生量不大及频率不高的环境。
3.3 引入消息队列

在日志产生量大频率高的情况下,需要引入消息队列,以减轻对后端日志存储的压力,减少日志丢失概率。
3.4 多机房部署 - 独立部署
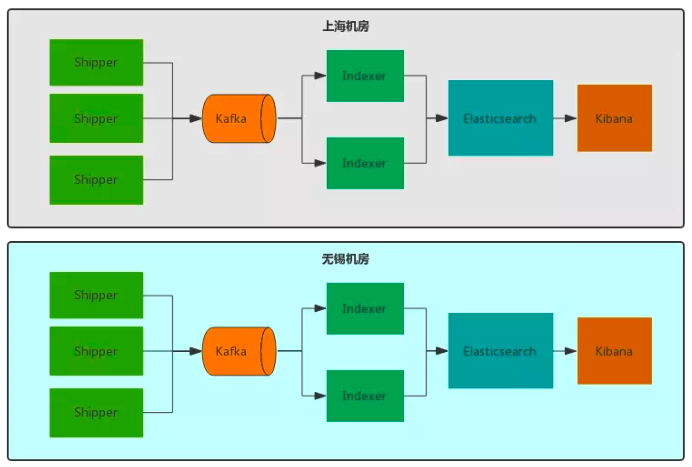
3.5 多机房部署 - 跨机房部署
目前没有特别成熟的方案,估计大部分的架构还是前面的架构,这种跨机房架构更多地在大型互联网公司有落地。通常有几种方案供参考:
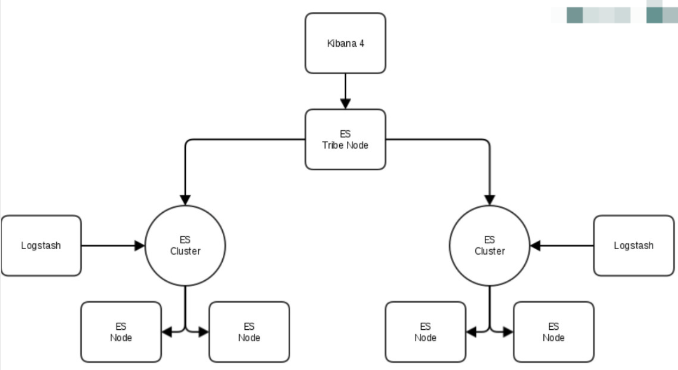
参考连接:
- https://jaxenter.com/docker-logging-gotchas-137049.html
- https://www.loggly.com/blog/top-5-docker-logging-methods-to-fit-your-container-deployment-strategy/
- https://www.cloudtechnologyexperts.com/deploy-fluentd-on-kubernetes/
- http://blog.51cto.com/13527416/2051506
感谢您的阅读,欢迎关注我的微信公众号:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号