

理解OpenShift(5):从 Docker Volume 到 OpenShift Persistent Volume
理解OpenShift(1):网络之 Router 和 Route
理解OpenShift(5):从 Docker Volume 到 OpenShift Persistent Volume
** 本文基于 OpenShift 3.11,Kubernetes 1.11 进行测试 ***
1. 从 Docker Volume 到 OpenShift/Kubernetes Persistent Volume
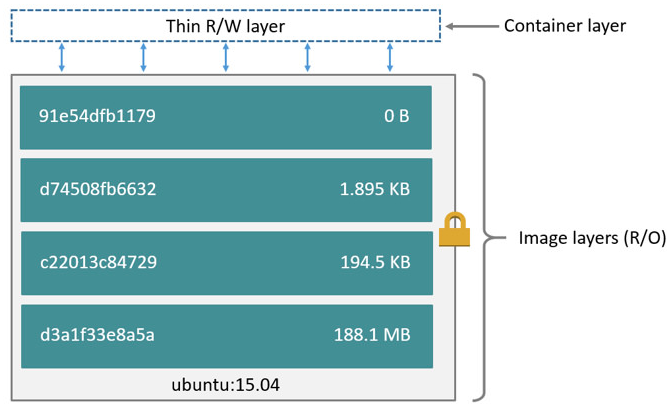
1.1 Docker 容器层(Container layer)
Docker 镜像是不可修改的。使用一Docker 镜像启动一个容器实例后,Docker 会在镜像层之上添加一个可读写的容器层(Container layer)。容器中所有新增或修改的数据都保存在该容器层之中。在容器实例被删除后,该层也会随之被自动删除,因此所有写入的或修改的数据都会丢失。具体可阅读Docker 相关文档,比如 https://docs.docker.com/v17.09/engine/userguide/storagedriver/imagesandcontainers/。
1.2 Docker Volume
在容器的可写层中保存数据是可能的,但是有一些缺点:
- 当容器实例不在运行时,数据不会被保存下来,因此数据是易失性的,不是持久性的。
- 很难将容器中的数据弄到容器外面,如果其它进行需要访问它的话。
- 容器的可写层和容器所在的宿主机紧耦合,数据无法被移动到其它宿主机上。
- 向容器的可写层中写入数据需要通过存储驱动(storage driver,比如AUFS,Brtfs,OverlayFS等)来管理文件系统。存储驱动利用Linux内核提供联合文件系统(union file system),这会降低IO性能。
为了解决以上问题,Docker 提供了 Volume (卷)功能。本质上,一个数据卷(data volume)是 Docker 容器所在宿主机上的一个目录或文件,它被挂载(mount)进容器。Docker 卷具有自己独立的生命周期,可以使用 Docker volume 命令独立地被创建和管理。在容器实例被删除后,卷依然存在,因此卷中的数据会被保留,从而实现数据持久化。而且,数据卷直接将数据写入宿主机文件系统,性能相比容器的可写层有提高。
Docker 提供三种方式将宿主机文件或文件夹挂载到容器中:
- volume(卷):卷保存在宿主机上由Docker 管理的文件系统中,通常在 /var/lib/docker/volumes/ 目录下。
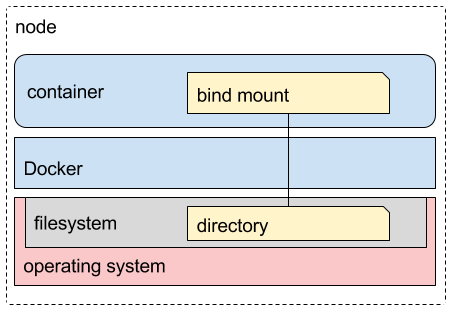
- bind mount(绑定挂载):被挂载的文件或文件夹可以在宿主机上文件系统的任何地方。
tmpfsvolume:数据保存在宿主机内存中,而不写入磁盘。
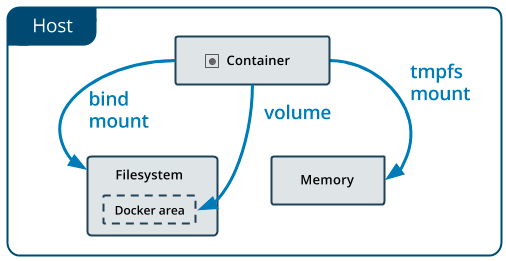
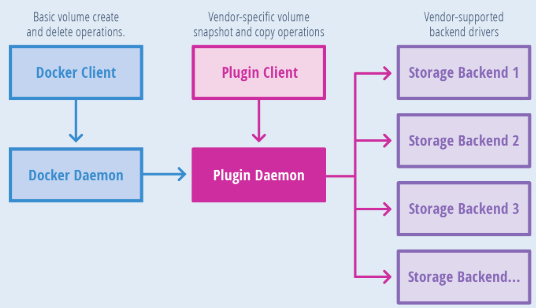
三种方式各自有合适的场景,通常建议使用 Docker Volume。Docker Volume 还支持通过各种卷插件(volume plugin),接入各种外置存储。本质上,都是存储插件将存储的卷挂载到Docker宿主机上的某个目录,然后Docker 将目录在挂载给容器。
更详细信息,请阅读 https://docs.docker.com/v17.09/engine/admin/volumes/#good-use-cases-for-tmpfs-mounts 等官方文档。
1.3 Kubernetes/OpenShift Volume
OpenShift 利用 Kubernetes 的存储机制来实现其 Volume 功能。和Docker volume 概念类似,本质上,一个 K8S Volume 也是一个能被Pod 中的容器访问的目录。至于该目录是怎么来的,后端介质是什么,内容是什么,则是由所使用的具体卷类型(volume type)决定的。Kubernetes Volume 支持多种存储类型:

关于 K8S Volume 概念的更多信息,请阅读相关文档。
1.3.1 K8S NFS Volume 示例
下面以 Glusterfs Volume 为例介绍 K8S Volume 的使用:
(1)OpenShift 管理员在集群中创建一个 endpoints 对象,指向 Glusterfs 服务器的 IP 地址。在我的测试环境中,由两台服务器提供Glusterfs服务。


172.20.80.7:glusterfsvol1 on /var/lib/origin/openshift.local.volumes/pods/bd8914b5-00d9-11e9-a6cf-fa163eae8505/volumes/kubernetes.io~glusterfs/glustervol1 type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
(5)然后,宿主机上的这个目录会通过 Docker bind mounted 挂载进容器

1.3.2 K8S/OpenShfit Volume 使用方式总结
从上面过程可以看出,使用卷的过程需要至少有存储工程师和开发人员。要使用某种卷,开发人员需要了解后端存储的具体配置信息。

但是实际上,存储信息对于应用开发人员来说,其实是不需要可见的。他们只关心有没有满足要求的存储可用,而不需要关心后端是什么存储。
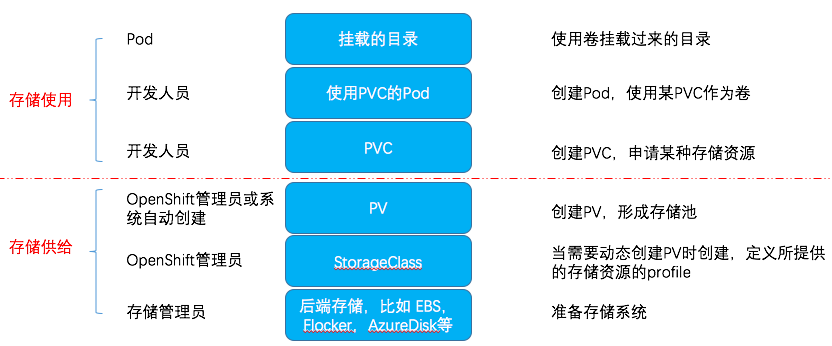
为了解耦存储供给和存储使用(pod中的存储定义),Kubernetes 创建了两个概念:PV (Persistent Volume)和 PVC (Persistent Volume Claim)这些概念。
1.4 Kubernetes/OpenShift Persistent Volume
1.4.1 概念
- PV:Persistent Volume。由 OpenShfit 管理员创建,后端是各种类型的存储,比如 AWS EBS,GCE Disk,NFS 等。管理员可以创建多个PV,形成一个存储池,供开发人员使用。
- StorageClass:在需要动态创建 PV 时由 OpenShfit 管理员创建。 管理员利用 StorageClass 来描述他们所提供的存储的类型(classes)。Storage class 向管理员提供了一种方式,用于描述他们所提供的存储的信息。不同的class 可映射到不同的 SLA,备份策略,等等。每个 StorageClass 包括 provisoner、parameters、reclaimPolicy 字段。
- PVC:Persistent Volume Claim。由开发人员创建,一个实例表示对某种存储资源的一个申请。每当开发人员创建一个新的PVC后,Kubernetes 会在已有的PV 池中进行搜索,找到一个最佳匹配的PV 来使用。PVC 中只包含通用的存储需求,比如访问模式(AccessModes)、容量(request)等,而不需要关心后端存储的具体信息。 Pod 通过 PVC 使用 PV,PV 由实际的存储系统提供物理存储。
以 Glusterfs 为例,这是各种概念之间对照图(来源: http://blog.leifmadsen.com/blog/2017/09/19/persistent-volumes-with-glusterfs/):

根据 PV 的不同创建方式,又可以分为静态创建PV 和 动态创建PV两种方式。前面一种PV由OpenShift 管理员手工创建,后者一种的PV由系统自动创建。具体可参考后面的两个例子。
1.4.2 PV 的生命周期
- 供给:分为静态供给和动态供给。
- 静态供给是指管理员会预先创建好一定数目的PV,每个PV 包含供集群使用的真实后端存储的详细信息,这些PV形成一个持久化卷的资源池。
- 动态供给是集群管理员预先创建 StorageClass,然后PVC申请StorageClass,然后集群会动态创建PV,供PVC消费。 动态卷供给是 Kubernetes独有的功能,这一功能允许按需创建存储建。在此之前,集群管理员需要事先在集群外由存储提供者或者云提供商创建存储卷,成功之后再创建PersistentVolume对象,才能够在kubernetes中使用。动态卷供给能让集群管理员不必进行预先创建存储卷,而是随着用户需求进行创建。
- 绑定:用户在部署容器应用时会定义PVC,其中会声明所需的存储资源的特性,如大小和访问方式。K8S 的一个控制器(controller)会负责在PV 资源池中寻找匹配的PV,并将PVC与目标PV 进行对接。这是PV和PVC的状态将变成 Bound,即绑定状态。PV 和 PVC 之间的绑定是1:1的,这意味着PVC对PV的占据是独占的、排它的。 使用:Pod 通过使用 PVC 来通过卷(volume)来使用后端存储(storage)资源。Pod 和它要使用的 PVC 必须在同一个 project 中。
- 集群为 pod 在同一个 project 中定位到 PVC。
- 通过 PVC 找到 PV。如果没找到且存在合适的StorageClass,则自动创建一个PV。
- 存储卷挂载到宿主机,然后被 pod 使用。
- 释放:当应用不再使用存储时,可以删除PVC,此时PV的状态为 released,即释放。Kubernetes 支持使用保护模式(Storage Object in Use Protection)。当该功能启用后,如果用户删除被一个正被pod 使用着的 PVC,该 PVC 不会马上被删除,而是会推迟到 pod 不再使用该PVC时。如果用户删除PV,它也不会被马上删除,而是会等到该PV不再绑定到PVC 的时候。是否启用了该保护,可以从 PV 和 PVC 的 finalizers: - kubernetes.io/pvc-protection 上看出来。
- 回收:当 PV 的状态变为 released,K8S 会根据 PV 定义的回收策略回收持久化卷。
- retain:保留数据,人工回收持久化卷。
- recycle:通过执行 rm -rf 删除卷上所有数据。目前只有 NFS 和 host path 支持。
- delete:动态地删除后端存储。需要底层 iaas 支持,目前 AWS EBS,GCE PD 和 OpenStack Cinder 支持。
2. 静态创建PV示例及Volume 权限(以NFS为例)
2.1 静态创建PV的流程
(1)存储管理员准备 NFS 环境
网上有很多关于NFS安装步骤的文章,这里不再重复。我的测试环境上,NFS 服务器的IP 地址为 172.20.80.4,它暴露了三个文件夹供客户端使用:

(2)OpenShift 管理员创建 PV, 后端使用上述 NFS 存储的
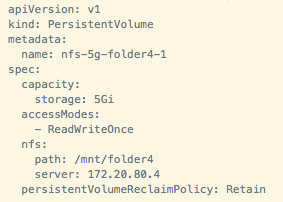
(3)开发人员创建一个 PVC,使用上一步骤中创建的PV。该 PVC实例会存在于某个project 之中,而PV则是在集群范围内共享的。
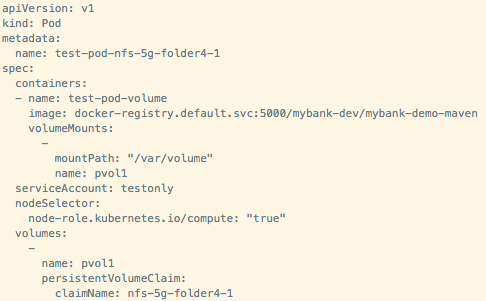
(4)NFS folder4 文件夹被挂载到Pod 所在的宿主机上。
172.20.80.4:/mnt/folder4 on /var/lib/origin/openshift.local.volumes/pods/863e9b2d-01a0-11e9-a6cf-fa163eae8505/volumes/kubernetes.io~nfs/pv-folder4-2 type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=172.22.122.8,local_lock=none,addr=172.20.80.4)
(5)宿主机上的目录被 bind mounted 给容器,成为其 /var/volume 文件夹。

2.2 Pod volume 权限
2.2.1 NFS 权限控制
每种存储后端都有其自己的权限管理方式。在NFS 中,在 /etc/exports 文件中国年,可以使用以下原语来设置每个将被共享出来的文件夹的权限:
- 读写模式
- ro:共享目录只读;
- rw:共享目录可读可写;
- 用户管理
- all_squash:所有访问用户都映射为匿名用户或用户组;
- no_all_squash(默认):访问用户先与本机用户匹配,匹配失败后再映射为匿名用户或用户组;
- root_squash(默认):将来访的root用户映射为匿名用户或用户组;
- no_root_squash:来访的root用户保持root帐号权限;
- anonuid=<UID>:指定匿名访问用户的本地用户UID,默认为nfsnobody(65534);
- anongid=<GID>:指定匿名访问用户的本地用户组GID,默认为nfsnobody(65534);
- 端口管理
- secure(默认):限制客户端只能从小于1024的tcp/ip端口连接服务器;
- insecure:允许客户端从大于1024的tcp/ip端口连接服务器;
- 数据写入方式
- sync:将数据同步写入内存缓冲区与磁盘中,效率低,但可以保证数据的一致性;
- async:将数据先保存在内存缓冲区中,必要时才写入磁盘;
- wdelay(默认):检查是否有相关的写操作,如果有则将这些写操作一起执行,这样可以提高效率;
- no_wdelay:若有写操作则立即执行,应与sync配合使用;
- 文件夹权限
- subtree_check(默认) :若输出目录是一个子目录,则nfs服务器将检查其父目录的权限;
- no_subtree_check :即使输出目录是一个子目录,nfs服务器也不检查其父目录的权限,这样可以提高效率;
NFS 用户认证及权限控制基于 RPC。在 NFS 3 和 4 版本中,最常用的认证机制是 AUTH_Unix。客户端系统上的 uid 和 gid 通过 RPC 调用传到 NFS 端,然后这些 id 所拥有的权限会被校验,以确定能否访问目标资源。因此,客户端和服务器端上的 uid 和 gid 必须相同。同时,可以使用一些设置来做特定处理:
- all_squash:将所有用户和组都映射为匿名用户和组。默认为 nfsnobody 用户(id 为 65534)和 nfsnodbody 组(id 为 65534)。也可以通过 anonuid 和 anongid 指定。
- no_all_squash:访问用户先与本机用户通过 id 进行匹配,如果有 id 相同的用户则匹配成功,若匹配失败后再映射为匿名用户或用户组。这是默认选项。
- root_squash:将来访的 root 用户(id 为 0)映射为匿名用户。这是默认选型,可以使用 no_root_squash 不进行这种映射,而保持为 root 用户。
在我们当前的例子中,folder4 的文件夹权限为 /mnt/folder4 172.22.122.0/24(insecure,rw,sync,no_root_squash,no_all_squash)。这表示它:
- 允许 172.22.122.0/24 网段的客户端访问(备注:这个网段实际上是宿主机所在的网段,而不是Pod 网段,因为 NFS 实际上是被挂载给宿主机的,然后再 bind mount 给容器的)。
- insecure:允许通过端口号大于 1024 的 tcp 连接访问它。
- no_root_squash:保持客户端 root 用户,将其映射为服务器端 root 用户。理论上这是一种危险的配置。
- no_all_squash:先将通过 PRC 传入的 uid 和 gid 在本地进行匹配。成功则使用 NFS 服务器上的同id 的用户或组;否则使用匿名用户或组。
NFS 上的 folder4 的目录权限为:drwxr--r-x 2 nfsnobody nfsnobody 4096 Dec 17 10:11 folder4。这意味着 nfsnobody 用户可以对它做读写,其它用户(包括nfsnobody组内的用户和其它用户)都只能读。
Pod 中的用户 id 为:uid=1001(default) gid=0(root) groups=0(root)。
查询共享目录OK。
写入失败:Permission denied。这是因为本地用户 uid 1001 在 NFS 服务器上有匹配的用户 (cloud-user2:x:1001:1001::/home/cloud-user2:/bin/bash),而该用户并没有 folder4 文件夹写权限。
2.2.2 几种权限做法
从上面对 NFS 权限控制原理的分析可以看出有几种方式来保证Pod 中的用户的写入成功。
(1)将 NFS 暴露出来的文件夹的所有者修改为 nfsnobody:nfsnobody,然后在文件夹上设置 all_squash,这会将所有客户端 uid 和 gid 映射为NFS服务器端的 nfsnobody 用户和 nfsnobdy 组。
在 pod 中的 id: uid=1001(default) gid=0(root) groups=0(root)
在 pod 中写入文件,然后在 NFS 上查看:

可见是uid 和 gid 都是映射成功了的。
(2)上述方法一将所有客户端的用户都映射为 nfsnobody:nfsnobody,这有了统一性,但是也消灭了独特性。有时候还需要保留客户端上的已知uid。此时会在 NFS 共享的文件夹上设置 no_all_squash,这样会先做匹配找到两地都有的user,匹配不成功则走步骤(1)中的做法。
这种情况下,如果匹配成功,则NFS 会对服务器端的同 uid 和 gid 的用户的权限进行校验。通常情况下,NFS 服务器端匹配到的用户不会是 nfsnobdy,根据文件夹上的权限设置,此时Pod 中是无法写入文件的。这就是 2.2.1 中说描述的场景的结果。此时有两种处理方式:
(a)将文件夹上 other user 加上写权限。这种做法比较简单粗暴,权限暴露过大,不推荐使用。
chmod o+w folder5 -R
(b)使用 supplemental group id
Linux 系统中, supplemental group ID 是进程所拥有的附加组的一个集合。在 Linux 上,文件系统的用户(user)、组(group)的 ID,连同辅助组(supplementary group)的ID,一起确定对文件系统的操作权限,包括打开(open)、修改所有者(change ownership)、修改权限(permission)。具体请阅读相关 Linux 文档。
首先修改NFS 文件夹的 gid 为某个数值,比如下面的命令修改gid为 2000(这里实际上是 gid,不是 supplemental gid。gid 对文件夹有意义,而 supplemental gid 对文件夹无意义而对进程有意义)。
chown :2000 folder4 -R
然后在 pod 上进行配置,使得 Pod 中的主进程的辅助组id 为这里所设置的gid。
2.2.3 设置Pod 中主进程的 uid 和 supplemental gid
(1)Pod 的 uid,gid 和 supplemental gid
Kubernets 目前还不支持设置 gid,因此所有 pod 中运行主进程的 gid 都是 0。
对一个非 cluster admin role 用户启动的 pod,它的默认 service account 为 restricted。它要求 uid 必须在指定的区间内,而它自己并没有指定用户id 区间:

此时 pod 的 uid 区间受pod 所在的 project 上的定义的相应 annotation 限制:

此时pod 中的 uid 和 suppenmental gid 如下图所示:(备注:与前面的例子中的 uid 不同,是因为前面的 pod 是 cluster admin user 启用的,因此 pod 的 scc 为 anyuid):

在不显式指定 uid 和 supplemental gid 的情况下,会使用区间的最小值作为默认值。
(2)修改 Pod 的 uid
根据前面对 NFS 权限管理的分析,可以将 Pod 中的 uid 修改为 nfsnobody 对应的 uid,这样Pod 就会具有 NFS 共享目录的写入权限。但是,默认的 nfsnobdy 的 uid 为 65534,这个 uid 并不在service account restricted 允许的 uid 区间 [1000000000, 1000009999] 之内,因此无法将 uid 设置为 65534.
此时,可以基于 restricted scc 创建一个新的 scc,别的配置不变,除了将 RunAsUser 策略修改为 RunAsAny 以外。此时,就可以在 Pod 中指定 uid 为 65534 了。
新的scc:

pod 中指定 uid:

pod 的 uid:

挂载的文件夹可写。操作成功。
(3)修改 supplementantal gid
因为 uid 会和太多因素关联,所以直接修改 uid 这种做法比较重。除了 uid 外,Pod 中还可以:
- 设置 fsGroup,它主要面向向块存储
- 设置 suppmental gid,它主要面向共享文件系统
因为 Glusterfs 是共享文件存储,因此需设置辅助组id。具体步骤包括:
- 修改 pod 的 suppemental gid,其做法与修改 uid 的做法类似,不再重复。
- 修改 NFS 文件夹的 group 权限,加上 w 和 x,并设置其 gid 为 pod 所使用的 suppemental gid。
这两,在NFS客户端(pod)和服务器端(文件夹)上通过 group id 将把权限打通了。
更详细说明,请阅读 OpenShift 官方文档 https://docs.okd.io/latest/install_config/persistent_storage/pod_security_context.html。
3. 动态创建PV示例(以Clusterfs 为例)
3.1 流程概述
3.1.1 从 OpenShift 角度看
下图展示了从 OpenShift 角度看的动态创建PV的流程。在步骤 3.2,当开发人员创建好PVC以后,OpenShift 会在当前StorageClass中查找满足要求的 StorageClass。一旦找到,就会根据PVC中的配置自动创建一个PV,并调用StorageClass中的 storage provisioner 自动创建一个存储volume。在开发人员创建使用该 PVC 的 Pod 后,存储卷就会被挂载给Pod 所在的宿主机,然后通过 bind mounted 被挂载给Pod。
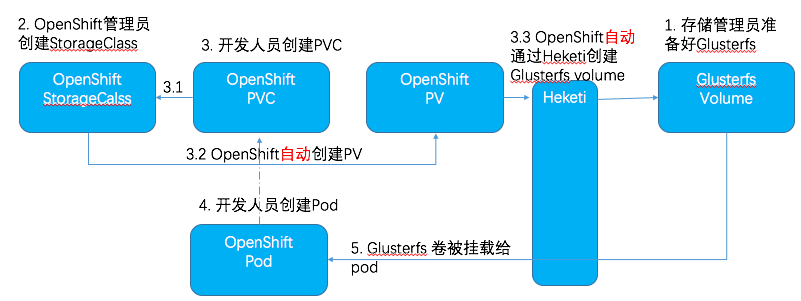
这么做的好处是显而易见的,比如:
- 集群管理员不需要预先准备好PV
- PV的容量和PVC的容量是一样的,这样就不会存在存储浪费。
- 在删除PVC时,PV 会被自动删除,存储卷也会被自动删除。
另一方面,OpenShift 会为每个PVC 在后端存储上创建一个卷。这样,在有大量PVC时,存储中将出现大量的小容量卷,这对某些存储会产生相当大的压力,特别是对于一些传统存储。这些存储可能就不能满足现代容器云平台对存储的要求了。
3.1.2 从存储角度看
因为 Glusterfs 本身不提供 REST API,因此需要在它前面部署一个Proxy。Heketi 就是一种开源的这种Proxy,它的项目地址是 https://github.com/heketi/heketi。它暴露Gluster Volume 操作的REST API,并通过 SSH 来运行 Glusterfs 命令,完成各种卷相关的操作,比如创建,映射等。OpenShift 通过调用 Heketi API 来实现 Gluesterfs 卷的动态创建和管理。
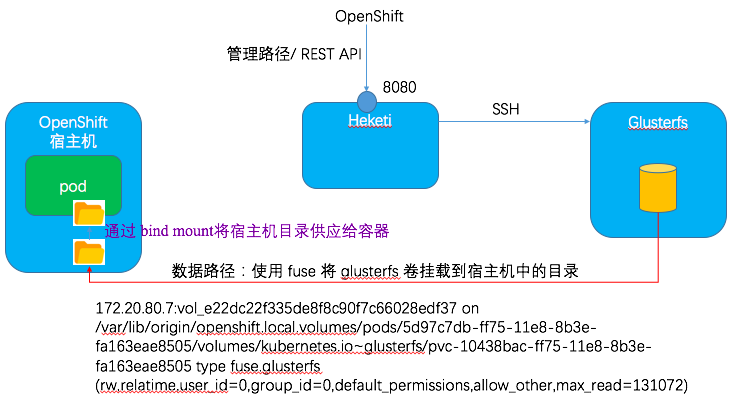
3.2 示例
(1)OpenShift 管理员创建 StorageClass
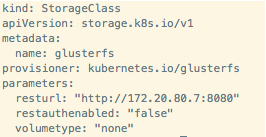
每个 StorageClass 会包含几个属性:
- provisioner:指定创建PV所使用的存储插件(volume plugin)。Kubernets/OpenShift 带有它们所支持的存储插件。
- parameters:后端存储的各种参数。
- reclaimPolicy:存储空间回收策略。
关于StorageClass的详细说明,请阅读 https://kubernetes.io/docs/concepts/storage/storage-classes/。
(2)开发人员创建一个PVC
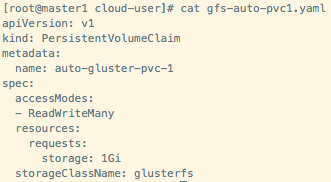
其中关键的一项是在 storageClassName 中制定 StorageClass 的名称。
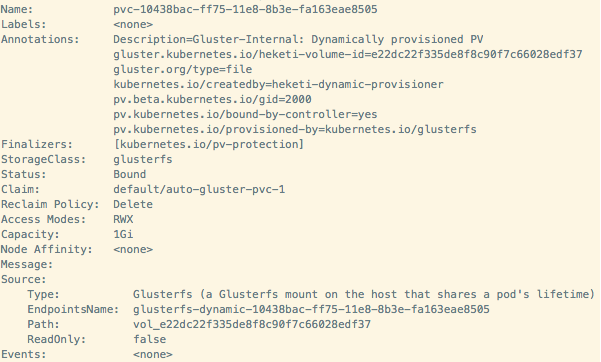
(3)OpenShfit 自动创建一个PV,以及其它资源。
OpenShfit 会根据 StorageClass 及 PVC 中的有关属性,动态创建一个 PV。
以及 Service:

及其 Endpoints:

OpenShift 是通过该 service 调用 storage provisioner 的。
(4)Volume plugin 会自动地创建存储卷

Heketi 在 Glusterfs 中创建改卷的过程大致如下:
(a)Glusterfs 系统初始化时会为每个物理磁盘创建一个 Volume Group:
pvcreate --metadatasize=128M --dataalignment=256K '/dev/vde' vgcreate --autobackup=n vg_c04281d30edfa285bb51f0f323ab7690 /dev/vde

gluster --mode=script volume create vol_e22dc22f335de8f8c90f7c66028edf37 172.20.80.7:/var/lib/heketi/mounts/vg_c04281d30edfa285bb51f0f323ab7690/brick_97d37975df78714e2e0bfea850a9e4aa/brick mkdir -p /var/lib/heketi/mounts/vg_c04281d30edfa285bb51f0f323ab7690/brick_97d37975df78714e2e0bfea850a9e4aa lvcreate --autobackup=n --poolmetadatasize 8192K --chunksize 256K --size 1048576K --thin vg_c04281d30edfa285bb51f0f323ab7690/tp_97d37975df78714e2e0bfea850a9e4aa --virtualsize 1048576K --name brick_97d37975df78714e2e0bfea850a9e4aa mkfs.xfs -i size=512 -n size=8192 /dev/mapper/vg_c04281d30edfa285bb51f0f323ab7690-brick_97d37975df78714e2e0bfea850a9e4aa mount -o rw,inode64,noatime,nouuid /dev/mapper/vg_c04281d30edfa285bb51f0f323ab7690-brick_97d37975df78714e2e0bfea850a9e4aa /var/lib/heketi/mounts/vg_c04281d30edfa285bb51f0f323ab7690/brick_97d37975df78714e2e0bfea850a9e4aa
#这个目录是在 Glusterfs 节点上实际保存数据的目录
mkdir /var/lib/heketi/mounts/vg_c04281d30edfa285bb51f0f323ab7690/brick_97d37975df78714e2e0bfea850a9e4aa/brick
#该命令会目录的 gid 修改为前述第(3)步中的 gid
chown :2000 /var/lib/heketi/mounts/vg_c04281d30edfa285bb51f0f323ab7690/brick_97d37975df78714e2e0bfea850a9e4aa/brick chmod 2775 /var/lib/heketi/mounts/vg_c04281d30edfa285bb51f0f323ab7690/brick_97d37975df78714e2e0bfea850a9e4aa/brick

(5)开发人员创建一个使用上述PVC的 Pod

(6)Pod 启动时,系统会
[root@node2 cloud-user]# mount | grep gluster 172.20.80.7:vol_e22dc22f335de8f8c90f7c66028edf37 on /var/lib/origin/openshift.local.volumes/pods/5d97c7db-ff75-11e8-8b3e-fa163eae8505/volumes/kubernetes.io~glusterfs/pvc-10438bac-ff75-11e8-8b3e-fa163eae8505 type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
然后该宿主机目录作为一个 mountpoint 被挂载给容器:


172.20.80.7:vol_e22dc22f335de8f8c90f7c66028edf37 on /var/volume type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
查看用户,它有id 为 2000 辅助组。


- 在 Ubuntu 16.04 上安装 Glusterfs:https://wiki.centos.org/zh/HowTos/GlusterFSonCentOS 和 https://www.itzgeek.com/how-tos/linux/ubuntu-how-tos/install-and-configure-glusterfs-on-ubuntu-16-04-debian-8.html
- 以 Volume 形式使用 Glusterfs:https://github.com/kubernetes/examples/tree/master/staging/volumes/glusterfs
- http://blog.leifmadsen.com/blog/2017/09/19/persistent-volumes-with-glusterfs/
- Docker、Kubernetes 和 OpenShift 官方文档
感谢您的阅读,欢迎关注我的微信公众号:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号