

Linux kernel features for high-speed networking
From: http://syuu.dokukino.com/2013/05/linux-kernel-features-for-high-speed.html
There's a bunch of features for high-speed networking on Linux kernel.
This article introduce some of them, briefly.
* RPS (Receive Packet Steering)
RPS is software implementation of RSS.
Which offers packet distribution functionality to mono-queue NIC, by kernel.
More details are here:
netperf benchmark result on lwn.net:
e1000e on 8 core Intel
Without RPS: 90K tps at 33% CPU
With RPS: 239K tps at 60% CPU
foredeth on 16 core AMD
Without RPS: 103K tps at 15% CPU
With RPS: 285K tps at 49% CPU
Usage of RPS:
# echo "f" > /sys/class/net/eth0/queues/rx-0/rps_cpus
It can configure CPU affinity per-device-queue, disabled by default.
* RFS (Receive Flow Steering)
RFS is an extension of RPS, it updates RPS hash table(called rps_dev_flow table) to deliver packets to the CPU where application running on.
It improves data locality, may increase datacache hit-rate. Also latency will decrease.
Here's a graph which describes why we need it.
Without RFS, packet may across three different CPUs to deliver packet to a process, on worst case:
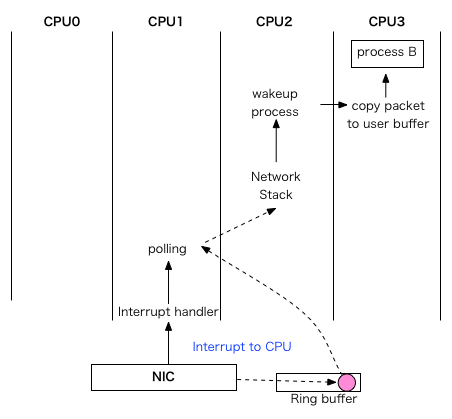
With RFS, it aligns packet process CPU:

To prevent TCP reordering, RFS doesn't update rps_dev_flow table directly.
It requires two steps:
- It has another hash table for RFS called rps_sock_flow_table, RFS updates CPU number during call to recvmsg/sendmsg at first.
- Then it updates rps_dev_flow table when NIC ring buffer is empty.
More details are here:
netperf benchmark result on lwn.net:
e1000e on 8 core Intel
No RFS or RPS 104K tps at 30% CPU
No RFS (best RPS config): 290K tps at 63% CPU
RFS 303K tps at 61% CPU
RPC test tps CPU% 50/90/99% usec latency StdDev
No RFS or RPS 103K 48% 757/900/3185 4472.35
RPS only: 174K 73% 415/993/2468 491.66
RFS 223K 73% 379/651/1382 315.61
Usage of RFS:
# echo 32768 > /proc/sys/net/core/rps_sock_flow_entries
# echo 4096 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt
Set rps_sock_flow table(it's global table) size, and set rps_dev_flow table(it's per-device-queue table).
* Accelerated RFS
Accelerated RFS is RFS feature for multiqueue NIC.
RFS calls device driver function named ndo_rx_flow_steer instead of update rps_dev_flow table.
The function definition is like this:
int (*ndo_rx_flow_steer)(struct net_device *dev, const struct sk_buff *skb, rxq_index, u32 flow_id);
Also, RFS need to know which queue is assigned to which CPU, so they addedcpu_rmap(CPU affinity reverse-mapping), it tells cpu:queue assignment information from driver to network stack.
Currently, it only supported on Solarflare sfc driver, and Mellanox mlx4 driver.
More details are here:
* XPS(Transmit Packet Steering)
XPS is cpu:tx-queue assignment configuration interface for user.
More details are here:
netperf benchmark result on lwn.net:
bnx2x on 16 core AMD
XPS (16 queues, 1 TX queue per CPU) 1234K at 100% CPU
No XPS (16 queues) 996K at 100% CPU
Usage of XPS:
# echo 1 > /sys/class/net/eth0/queues/tx-0/xps_cpus
# echo 2 > /sys/class/net/eth0/queues/tx-1/xps_cpus
# echo 4 > /sys/class/net/eth0/queues/tx-2/xps_cpus
# echo 8 > /sys/class/net/eth0/queues/tx-3/xps_cpus
* RSS configuration interface(balance configuration on RSS)
There's a command on ethtool which able to change weight between receive queue.
Usage of set-rxfh-indir option:
# ethtool --set-rxfh-indir eth3 equal 2
# ethtool --show-rxfh-indir eth3
RX flow hash indirection table for eth3 with 2 RX ring(s):
0: 0 1 0 1 0 1 0 1
8: 0 1 0 1 0 1 0 1
16: 0 1 0 1 0 1 0 1
24: 0 1 0 1 0 1 0 1
# ethtool --set-rxfh-indir eth3 weight 6 2
# ethtool --show-rxfh-indir eth3
RX flow hash indirection table for eth3 with 2 RX ring(s):
0: 0 0 0 0 0 0 0 0
8: 0 0 0 0 0 0 0 0
16: 0 0 0 0 0 0 0 0
24: 1 1 1 1 1 1 1 1
# ethtool --set-rxfh-indir eth3 weight 1 2
# ethtool --show-rxfh-indir eth3
RX flow hash indirection table for eth3 with 2 RX ring(s):
0: 0 0 0 0 0 0 0 0
8: 0 0 1 1 1 1 1 1
16: 1 1 1 1 1 1 1 1
24: 1 1 1 1 1 1 1 1
More detais are on man ethtool(8):
Also there's an article about rxfh-indir command:
* RSS configuration interface(changing hash behavior)
There's a command on ethtool which change hash behavior.
For example:
To include UDP port numbers in RSS hashing run:
# ethtool -N eth1 rx-flow-hash udp4 sdfn
To exclude UDP port numbers from RSS hashing run:
# ethtool -N eth1 rx-flow-hash udp4 sd
To display UDP hashing current configuration run:
# ethtool -n eth1 rx-flow-hash udp4
More detais are on man ethtool(8):
Also there's an article which describes the command:
* Flow Steering
Even RSS hash function output is 32bit, NIC only uses lower few bits when lookup hash table due to table size(on ixgbe, 128 entry).
On such condition, hash will easily conflict, flows required to share same entry on the hash table.
So RSS is good for packet distribution across CPUs, but not so good to steer specific flow.
To resolve this problem, Flow Steering was produced.
On Flow Steering supported NIC, device driver can insert 4-tuple or 5-tuple classification rule to the NIC.
NIC will deliver packet to queue following the rule.
NIC may uses hash table internally, but it's not easily causes collision, and software doesn't really need to think about hash table. Insert/update/delete classification rule and it justworks.
On Accelerated RFS article, I noticed sfc and mlx4 driver are supported this feature, both driver using flow steering for it, not RSS.
In these driver, ndo_rx_flow_steer function parse the skb, extract 4-tuple or 5-tuple and insert the rule to the NIC.
Related document:
* Flow Steering on ixgbe
ixgbe also has flow steering function called "Intel Ethernet Flow Director", but not supportsAccelerated RFS.
It does almost same thing inside their driver, not cooperate with a kernel.
But there's a paper Flow Director may causes TCP reordering on high load:
* Flow Steering rule configuration interface(RX NFC)
There's generic flow steering rule configuration interface on ethtool, called RX NFC.
Accelerated RFS configures Flow Steering automatically, RX NFC offers manualconfiguration feature to user.
Usage of ethtool RX NFC configuration:
# ethtool -K eth0 ntuple on
# ethtool -k eth0|grep ntuple
ntuple-filters: on
# ethtool --config-nfc ix00 flow-type tcp4 src-ip 10.0.0.1 dst-ip 10.0.0.2 src-port 10000 dst-port 10001 action 6
Added rule with ID 2045
# ethtool --show-nfc ix00
12 RX rings available
Total 1 rules
Filter: 2045
Rule Type: TCP over IPv4
Src IP addr: 10.0.0.1 mask: 0.0.0.0
Dest IP addr: 10.0.0.2 mask: 0.0.0.0
TOS: 0x0 mask: 0xff
Src port: 10000 mask: 0x0
Dest port: 10001 mask: 0x0
VLAN EtherType: 0x0 mask: 0xffff
VLAN: 0x0 mask: 0xffff
User-defined: 0x0 mask: 0xffffffffffffffff
Action: Direct to queue 6
More detais are on man ethtool(8):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号