数据库不只是Mysql,你需要知道这些才能拿到offer
数据库不只是Mysql,你需要知道这些才能拿到offer
有大半年的时间没有跟新微信公众号了。
上半年疫情的影响,过年之后一直在家办公。直到快4月才开始去公司办公。疫情期间在线教育快速发展,7-9月教育行业暑期大战,持续忙了3个多月,因此也把公众号丢了下来。很欣慰的看到参与的项目快速发展,慢慢走向正轨。自己也逐渐把公众号捡了起来。
今天想跟大家聊一聊,数据库相关的话题。
数据库全景图
提到数据库,大多数人脑海中浮现都是mysql,sqlserver,oracle。其实,数据库不只是这些。它还包括例如MongoDB,Cassandra,Es等其他的存储形式。
那么,常见的数据库有哪些?并且怎么分类这些数据,以及该怎么在不同场景下选择不同数据库呢?
首先,放一张"451Group"分析报告中的数据库的全景图
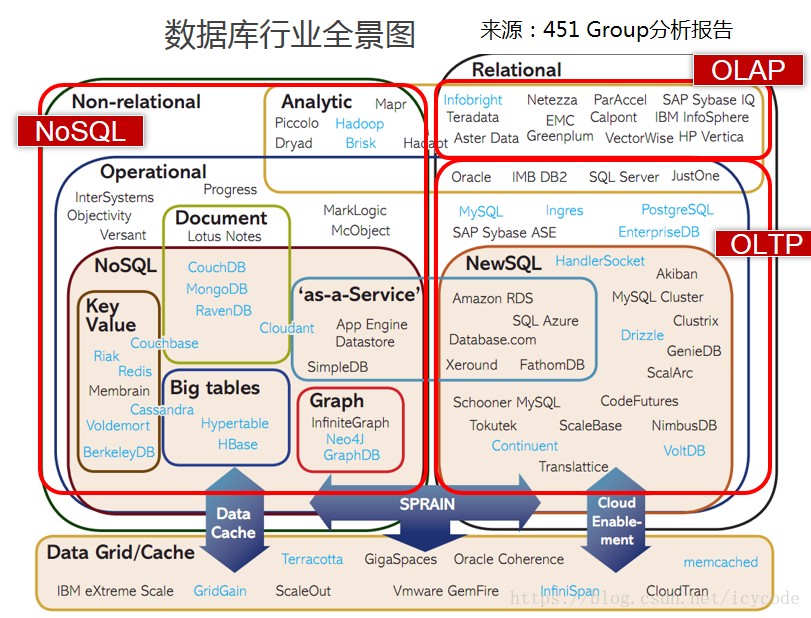
从图中,可以看出,数据库行业保罗万象。包括了很多不同分类的产品。
数据库分类
数据库总的来看可以分为三类:
- 关系型数据库:例如mysql,sqlserver,oracle等
- NoSql(非关系型数据库): 例如Redis,MongoDB,HBase等
- NewSql:是对各种新的可扩展/高性能数据库的简称,这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。包括例如:lustrix、GenieDB、ScalArc、Schooner等。
下面分别介绍这三种类型的数据库。
传统的关系型数据库
首先给出关系型数据库一个官方定义:
关系型数据库:指采用了关系模型来组织数据的数据库。关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
关系型数据库的优点:
1.容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
2.使用方便:通用的SQL语言使得操作关系型数据库非常方便
3.易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率
关系型数据库存在的问题:
-
高并发支持不够:网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
-
海量数据的挑战:网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的
-
横向扩展困难:在基于web的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。当需要对数据库系统进行升级和扩展时,往往需要停机维护和数据迁移。
-
性能欠佳:在关系型数据库中,导致性能欠佳的最主要原因是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。为了保证数据库的ACID特性,必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一个格式化的数据结构。
数据库事务必须具备ACID特性,ACID分别代表Atomic(原子性),Consistency(一致性),
Isolation(隔离性),Durability(持久性)。
当今十大主流的关系型数据库
Oracle,Microsoft SQL Server,MySQL,PostgreSQL,DB2,
Microsoft Access, SQLite,Teradata,MariaDB(MySQL的一个分支),SAP。
NoSQL
针对传统关系型数据库的缺点,为了更好的适应现代互联网高并发,高性能,高可用以及海量数据的挑战的需要,出现了不同的NoSQL数据库。
NoSQL放弃了传统SQL的强事务保证和关系模型,重点放在数据库的高可用性和可扩展性。
NoSQL 的主要优势:
- 高可用性和可扩展性,自动分区,轻松扩展
- 不保证强一致性,性能大幅提升
- 没有关系模型的限制,极其灵活
NoSQL主要的劣势: - 不保证强一致性:对于普通应用没问题,但还是有不少像金融一样的企业级应用有强一致性的需求。
- NoSQL不支持SQL语句:兼容性是个大问题,不同的 NoSQL 数据库都有自己的 api 操作数据,学习起来比较繁琐。
NoSQL数据库的分类
1. key-value存储
以key-value对的形式存储数据。value可以是自定义的不用的数据结构。这个类型的数据库主要包括:
| 数据库 | 分类 |
|---|---|
| Redis | Key-value store,Document store,Graph DBMS,Search engine,Time Series DBMS |
| Amazon DynamoDB | Document Store,Key-value store |
| Couchbase | Document Store,Key-value store |
| etcd | Key-value store |
| Memcached | Key-value store |
| Ehcache | Key-value store |
| LevelDB | Key-value store |
2. 文档存储
以比较自由的格式(通常为JSON)的方式存储文档内容。这意味着:
- 记录不需要具有统一的结构,即不同的记录可以具有不同的列。
- 每个记录的各个列的值类型可以不同。
- 列可以具有多个值(数组)。
- 记录可以具有嵌套结构。
常见的文档存储有: MongoDB,Amazon DynamoDB,Couchbase,CouchDB。
3. 宽列存储
宽列存储(也称为可扩展记录存储)将数据存储在记录中,并且能够容纳大量动态列。由于列名和记录键不是固定的,并且一条记录可以包含数十亿列,因此宽列存储可以看作是二维键值存储。
宽列存储与文档存储共享无模式的特性,但是实现却大不相同。
在某些关系系统中,不能将宽列存储与面向列存储相混淆。这是一个内部概念,用于提高RDBMS针对OLAP工作负载的性能,并存储表中的数据,而不是逐条记录,而是逐列存储。
列存储使用场景:
行式存储对于 OLTP 场景是很自然的:大多数操作都以实体(entity)为单位,即大多为增删改查一整行记录,显然把一行数据存在物理上相邻的位置是个很好的选择。
然而,对于 OLAP 场景,一个典型的查询需要遍历整个表,进行分组、排序、聚合等操作,这样一来按行存储的优势就不复存在了。更糟糕的是,分析型 SQL 常常不会用到所有的列,而仅仅对其中某些感兴趣的列做运算,那一行中那些无关的列也不得不参与扫描。
列式存储就是为这样的需求设计的。如下图所示,同一列的数据被一个接一个紧挨着存放在一起,表的每列构成一个长数组。
常见的宽列存储数据包括:Cassandra和HBase。
4. 图存储
图DBMS,也称为面向图的DBMS或图数据库,将图结构中的数据表示为节点和边,即节点之间的关系。它们允许轻松处理该形式的数据,并且可以简单地计算图形的特定属性,例如从一个节点到另一个节点所需的步骤数。
图形DBMS通常不会在所有节点上提供索引,在这种情况下,无法基于属性值直接访问节点。
常见的图存储包括:Neo4j,Microsoft Azure Cosmos DB 。
NewSQL
NewSQL提供了与NoSQL 相同的可扩展性,而且仍基于关系模型,还保留了极其成熟的SQL 作为查询语言,保证了ACID事务特性。简单来讲,NewSQL 就是在传统关系型数据库上集成了NoSQL 强大的可扩展性。
NewSQL 的主要特性:
- SQL 支持,支持复杂查询和大数据分析。
- 支持 ACID 事务,支持隔离级别。
- 弹性伸缩,扩容缩容对于业务层完全透明。
- 高可用,自动容灾。
主流NewSQL包括:TiDB,VoltDB,ClustrixDB等。
上面介绍了三种类型数据库(关系型数据库,NoSQL,NewSQL),处了这些分类之外还有针对特定场景存储的选型。比如可以用作搜索引擎的ES,Solar等,时间序列数据库OpenTSDB,InfluxDB等。更加详细的信息以及数据库排名参见:DB-Engines。
回复“资料”,免费获取 一份独家呕心整理的技术资料!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号