选取机器sam01作为主节点,并进行分布式文件的配置
1.进入Hadoop配置文件路径/usr/local/hadoop/etc/hadoop(这里我把Hadoop安装在/usr/local目录下)
2.配置core-site.xml文件
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<!-- 在Hadoop1.x的版本中,默认使用的端口是9000。在Hadoop2.x的版本中,默认使>用端口是8020 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://sam01:8020</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
3.配置hdfs-site.xml文件
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sam02:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>sam01:50070</value>
</property>
</configuration>
4.配置mapred-site.xml
这里初始为mapred-site.xml.template文件,需要复制为mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sam02:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>sam01:50070</value>
</property>
</configuration>
6.配置yarn-site.xml
<configuration>
<!-- 指定yarn的shuffle技术-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sam01</value>
</property>
<!--下面的可选-->
<!--指定shuffle对应的类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>sam01:8032</value>
</property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sam01:8030</value>
</property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sam01:8031</value>
</property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sam01:8033</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sam01:8088</value>
</property>
</configuration>
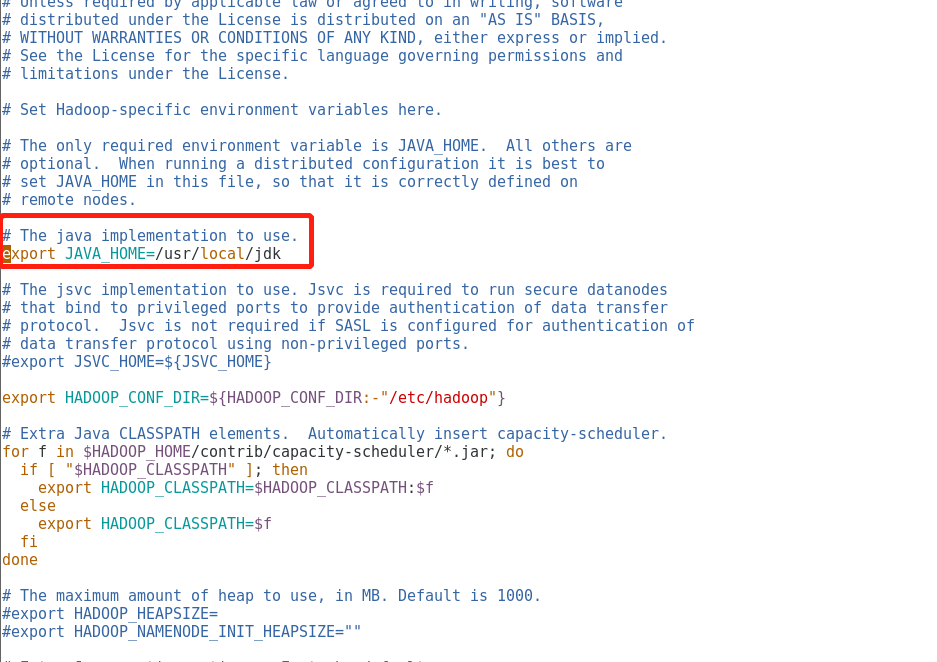
7.配置hadoop-env.sh文件
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk
![image]()
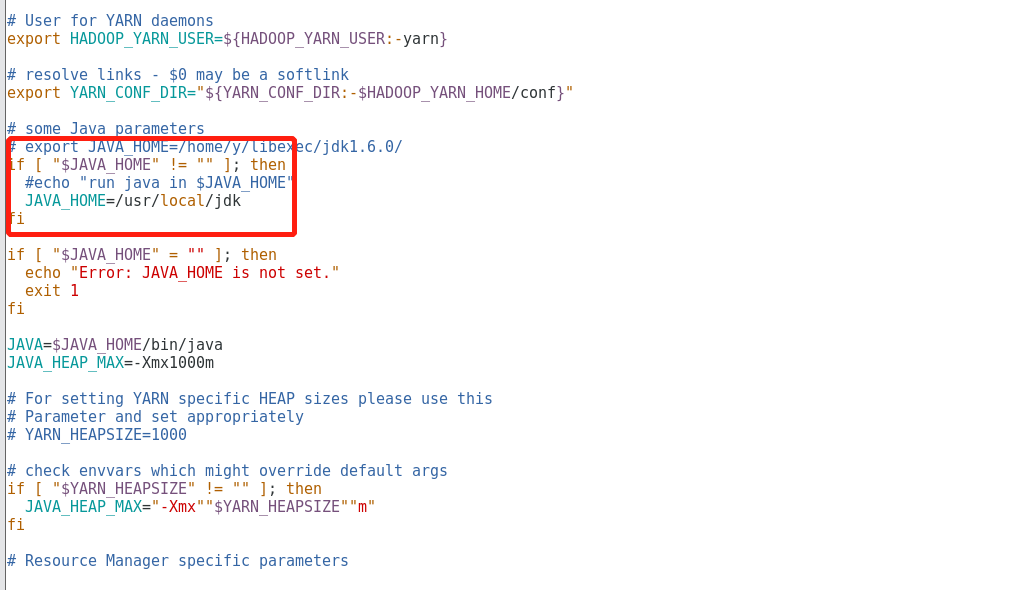
8.配置yarn-env.sh文件
#echo "run java in $JAVA_HOME"
JAVA_HOME=/usr/local/jdk
![image]()
9.配置slaves文件,此文件用于指定datanode守护进程所在的机器节点主机名
sam01
sam02
sam03
10.同步Hadoop配置文件到其余的节点
cd /usr/local
scp -r hadoop/ sam02:$PWD
scp -r hadoop/ sam03:$PWD



 浙公网安备 33010602011771号
浙公网安备 33010602011771号