「BUAA OO Unit 4 HW16」第四单元总结与课程回顾
「BUAA OO Unit 4 HW16」第四单元总结与课程回顾
Part 0 第四单元作业架构设计
架构设计概要
本单元的设计目标为扩展UML解析器,使之支持对UML类图、状态图和顺序图的分析,可以通过输入相应的指令来进行相关查询,并能根据UML规则进行一定的规范性验证。
整个第四单元的三次作业是依次迭代的,没有进行重构,因此这里以第15次作业为例介绍架构设计如下图示。
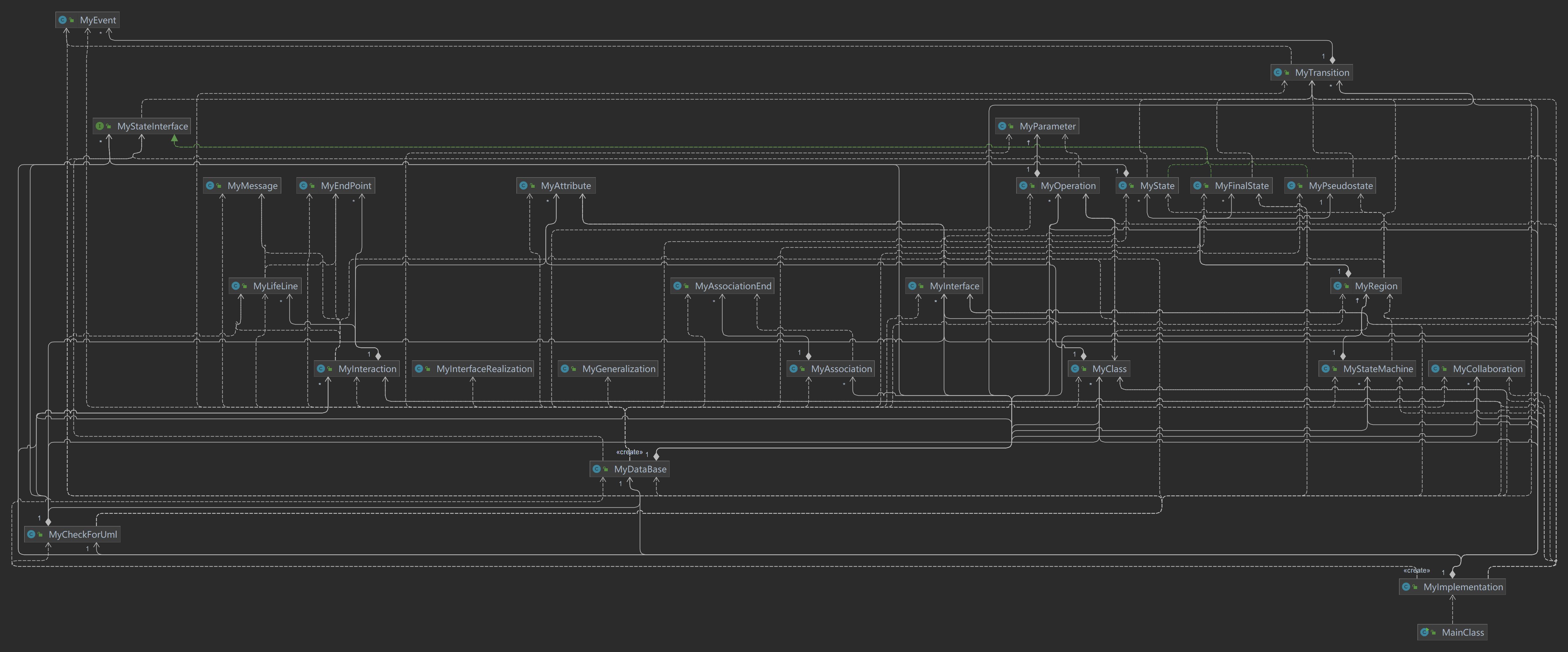
在本次作业中,我主要遵循以下几个原则进行设计:
- 将所有
UML*封装为My*,以便于统一管理和增设属性。 - 将数据管理功能抽离出来,形成
MyDataBase,其他类需要使用数据时,只需将引用指向MyDataBase中对象即可。 - 将规范性检查功能抽离出来,形成
MyCheckForUml。 - 根据输入的特点,遵循静态图构建->查询并记忆化维护间接属性的原则进行代码实现。
上述原则是在作业实现中逐步摸索出来的,以下以AppRunner官方包代码简析与架构设计初步、层次化循环读入建模————以泛化和接口实现为例和基于静态图的架构分析、设计与实现逐步深入介绍我对第四单元认识从稚嫩到成熟的过程。在这一部分的最后,我还将介绍异常处理的层次化这一小技巧。
AppRunner官方包代码简析与架构设计初步
本部分由两部分组成:
- 第一部分通过分析AppRunner具体代码清晰地了解官方包如何实现相应的接口和参数传递。这部分有利于理清官方包的实现,了解黑盒程序如何通过输入得到输出。
- 第二部分基于第一部分对官方包的理解,界限分明地标识我们工作的范围和需要完成的工作,并提出了一种可能的设计思路和架构,以供参考。
一、AppRunner工作逻辑和流程
将阅读官方包的收获记录在此
1. 属性
1.1 interaction
我们完成的UML解析器的实例化对象
1.2 status
标记此时AppRunner行为
2. 行为
主体运算逻辑在run中。
2.1 run
public void run(String[] args) {
try {
beforeStartEvent();
Scanner scanner = new Scanner(inputStream);
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
lineProcessEvent(line);
}
scanner.close();
afterCompleteEvent();
} catch (Exception e) {
exceptionProcessEvent(e);
}
}
以下步骤均在AppRunner中实现
为方便表示,下文用MyImplementation指代我们实现的UML解析器。
Step 1 输入与解析模型
run方法中调用beforeStartEvent方法,设置当前状态为PROCESSING_MODEL- 在
lineProcessEvent中,对传入的每行字符串进行解析,将蕴含的模型信息通过modelProcessEvent处理为UmlElement对象,并存入elementList容器 - 当读到字符串
END_OF_MODEL时,判断模型解析过程结束 - 调用
endOfModelProcessEvent,设置当前状态为PROCESSING_INSTRUCTION,并将elementList中的数据作为参数传给MyImplementation
Step 2 输入与指令获取
经过 Step 1 ,当前状态为
PROCESSING_INSTRUCTION
- 仍在
lineProcessEvent中运行。由于当前状态为PROCESSING_INSTRUCTION,进入else if分支 - 对于每行非空指令,调用
instructionProcessEvent解析 - 在
instructionProcessEvent中,调用runAsArguments解析,通过预先设置好的PROCESSORS映射,调用该指令类型的处理函数,如runAsClassCount
Step 3 输出
经过 Step 2 ,我们已经将每条非空合法指令传入其对应的解析方法中
- 在具体指令处理函数(如
runAsClassCount)中,调用MyImplementation的相应方法(如getClassCount),获取返回值并按规格打印
二、我们的工作
1. 解析和存储元素
经过上述分析,我们知道AppRunner在run中通过Step 1将储存UmlElement对象的容器作为参数传给了MyImplementation。因此,我们需要解析这些UmlElement对象。
1.1 输入顺序
值得注意的是,输入并没有保证顺序。也就是说,两个类的继承关系的指令可能早于这两个类的指令,即元素的依赖不一定早于元素出现,即乱序。
因此,一个不错的思路是多轮遍历读入:设计三个独立的循环,第一轮处理UML_CLASS、UML_INTERFACE和UML_ASSOCIATION;第二轮处理UML_ATTRIBUTE、UML_OPERATION、UML_ASSOCIATION_END、UML_GENERALIZATION;第三轮处理UML_PARAMETER、UML_INTERFACE_REALIZATION、UML_GENERALIZATION。
通过上述的三轮循环遍历读入,我们保证了自上向下建模。
我这里还没有想得很清楚,欢迎大家批评
1.2 元素封装
官方包提供的元素类并不能直接完全回答作业要求的查询问题,一种可行的办法是自行为每一种元素封装单独的类,并通过容器将其组织起来,形成一棵类似第一单元表达式树的元素树。
举例而言,对于UmlClass,我们封装MyClass继承(或者将UmlClass对象作为MyClass类的一个属性)其,增加Myclass parent,ArrayList<MyClass> sons等属性,尽可能丰富地表达其特征,方便后续查询。
2. 查询
AppRunner的run在将模型信息传入MyImplement后,会解析每一条查询指令并调用MyImplement的相应方法。
通过上一步中的解析和存储元素后,我们可以在其中直接维护一些查询量,对于不便维护的查询量,也可以通过我们完善的元素树方便地获取。
层次化循环读入建模————以泛化和接口实现为例
背景
传入MyImplement的参数UmlElement... elements不保证顺序,因此需要多轮读入。这里,介绍一种层次化循环读入建模的设计架构。
这里主要针对类和接口的泛化与接口的实现,对于作业中其他的属性以及后续作业的新要求,可以利用类似的思想
示意图
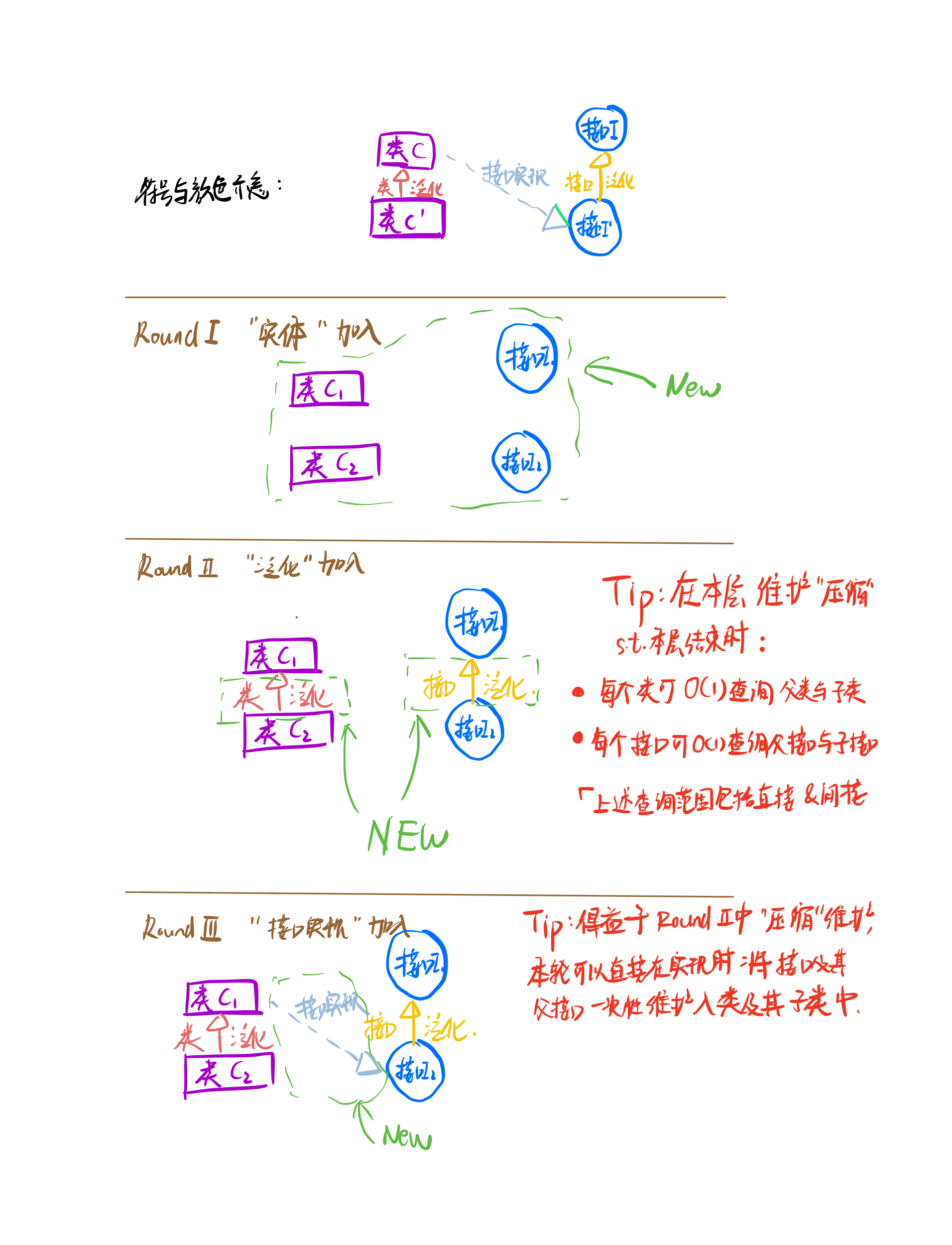
上图展示了三轮循环的工作实现与要点,以下结合该图逐个介绍。
流程
Round 1 “实体”加入
第一轮遍历,加入类和接口实体,这时候泛化和接口实现等关系尚未加入,彼此处于孤立状态。
Round 2 “泛化”加入
第二轮遍历,将泛化关系加入图中。
值得注意的是,我们在本层循环动态维护了每个类的所有子类和所有父类,每个接口的所有子接口和所有父接口。在本轮循环结束时,我们可以通过 的复杂度查询每个类(接口)的子类(接口)和父类(接口)信息(其实这是一种ensures)。
在这一轮中,值得注意的是实际上我们形成了类和接口两片森林,他们之间还没有发生关系。
Round 3 “接口实现”加入
第三轮遍历,将“接口实现”加入图中。
在本轮遍历中,我们实际的操作类似于进行树的合并,在合并的时候应当注意动态维护类所实现的所有接口,类似于“压缩”思想:即每个类储存了所有实现接口的信息,通过 查询即可,无需通过查找树到根以获得父亲信息。
基于静态图的架构分析、设计与实现
在上文中,我们介绍了在对图建模过程中动态维护间接属性从而以 代价完成查询操作的层次化循环读入建模思路。
在本文中,依托前两篇文章的工作,我们介绍一种基于静态图的架构分析、设计与实现。
- Part 0简要介绍本次作业的实际工作内容
- Part 1元素封装以统一管理的方法
- Part 2架构分析
- Part 3架构设计
- Part 4架构优点
以上为文章概要,可自取所需。
本文基于前述两篇文章继续分析,有兴趣的同学可以回顾。传送门:AppRunner官方包代码简析与作业架构设计初步、层次化循环读入建模————以泛化和接口实现为例 。
Part 0 背景
本次作业的工作内容为:
- 给定不定长数组
UmlElement... elements适当建模 - 给定指令查询图的相关信息
明确上述两点后,我们逐层展开分析。
Part 1 元素封装
官方包给出了UML所有元素的数据结构,但是对于本单元作业而言信息并不充分,一种值得推荐的方法是对所有UML元素进行封装,保证了统一性。经zsm助教提醒,这里突出强调了统一封装,我们对此展开讲讲:对于一些UmlElement,可能官方包提供的信息已经较为充足,事实上无需另外封装;但是封装一部分而不封装另外一部分,可能会出现需要不时确认此处应当用Myxxx还是用Umlxxx的困惑,不便于开发和维护。
在自行封装的元素类内部,我们可以声明各种有助于查询的间接量,下文也将结合具体要求介绍如何实际应用。
Part 2 架构分析
静态图
根据上文对AppRunner的分析,我们知道首先传入不定长的UmlElement数组,接着输入若干指令进行查询。基于这样的交互保证,我们可以把工作进一步抽象为:
- 根据不定长的
UmlElement数组获得一张静态图 - 根据给定指令查询静态图相关信息
值得注意的是,事实上,在第一条查询指令之前,我们就已经对整张图建模结束。此时,所有直接与间接信息已经完全确定,只是可能还没有计算出来。
记忆化
在静态图分析中,我们知道查询时信息已经完全确定,因此,针对这张图的每次查询都会获得准确的答案,这使得我们可以利用记忆化的方式减小时间复杂度与栈的深度。
举例而言,在一些指令中,如指令 7:类实现的全部接口,我们如果先查询了某个类classA实现的全部接口,在查询其(直接)子类classB实现的全部接口时只需要将classB自己实现的接口与classA查询得到的接口做并集即可。
Part 3 架构设计与实现
接下来分为三步介绍架构具体设计与实现,其中的Step2和Step3事实上可以合并,这将在本Part最后介绍。
Step 1 静态图构建
根据Part 2 架构分析,我们知道,在静态图完全建模完成之前,间接属性会随着图的完善而不断变化,因此,在层次化循环读入建模————以泛化和接口实现为例中提出的动态维护的思维复杂度主要原因在此。针对这一问题,我们首先完成静态图的构建,只维护直接属性(如类的直接继承、接口的直接实现等),对于可能在建图过程中动态变化的信息(如类实现的全部接口,类的全部直接与间接子类等)在本阶段不做维护,以极大化简思维复杂度。
确定了当前阶段只维护直接属性,我们依旧需要多轮读入。以下提供一种分轮循环读入建模思路并简述其合理性:
Round 1 读入实体
- UML_CLASS
- UML_INTERFACE
- UML_ASSOCIATION
这部分相当于在图中建立节点,还没有加入节点之间的关系
Round 2 读入较独立的关系
- UML_ATTRIBUTE
- UML_OPERATION
- UML_ASSOCIATION_END
- UML_GENERALIZATION
这部分读入了和自己或和自己同类相关的关系
Round 3 读入较依赖的关系
- UML_PARAMETER
- UML_INTERFACE_REALIZATION
这部分读入了和如接口实现这种跨类相关的关系
Tip : 上述分轮只是一种大致思路,实际上并非严格顺序依赖。举例而言:UML_INTERFACE_REALIZATION只需要前置UML_CLASS、UML_INTERFACE读入完成即可
Step 2 计算所有会被查询的间接属性
Part 3 Step 1 静态图构建中完成了图的建构及所有必要直接属性,这已经蕴含所有信息,我们这一阶段只需要根据需求遍历检索所有间接属性即可。以下,我们以指令 7:类实现的全部接口为例介绍具体操作。
根据Part 2 架构分析中的记忆化思路,我们首先为MyClass增加属性Set<MyInterface> interfaces,其含义为MyClass对象所实现的所有接口,并在构造器中将其初始化为null。接着,我们遍历MyImplementation中维护的MyClass容器中的全部对象调用Set<Interface> getImplementInterfaceList方法进行查找,该方法流程如下:
- 如果该对象的
Set<MyInterface> interfaces非空,说明之前检索过,直接返回interfaces - 如果
Set<MyInterface> interfaces为空,说明未曾检索过,执行interfaces = myInterfaces.merge(this.parent.getImplementInterfaces)。其中,myInterfaces是在静态图构建中维护的类对象自己实现的接口。
经过这样的遍历,我们计算了所有MyClass的实现全部接口,若再需要查询,直接 返回即可。
Step 3 查询
在Step 2中,我们计算了所有可能被查询的间接属性,因此,对大部分指令,我们可以以 返回。
上述Step 2和Step 3显然可以优化:我们建图结束后直接进入查询部分,对于查询过的信息记忆化维护即可。
Part 4 架构优点
思维复杂度低
将实现分为了两步走:静态图构建->查询并记忆化维护间接属性。避免了建图过程中动态维护的繁琐。
面向对象
我们没有忘记OO课程的初心,尽可能地进行抽象与分层建模,为每个类设计状态和行为,使之彼此协作,避免了类似一main到底的实现策略。
可拓展
得益于静态图的特点和实现架构,我们基本1:1模拟实现了UmlElement提供的直接信息,避免了建图时动态维护属性带来的高复杂度和低可维护性。
异常处理的抽象与层次化
对于部分异常情况较多的方法,一次性直接处理显然是困难而背离层次抽象原则的。因此,一种值得推荐的方法是处理本层次的异常,并调用下一层次的方法且将其他异常交由其处理。
举例而言:getParticipantCreator有六种异常,分别是:
-
InteractionNotFoundException -
InteractionDuplicatedException -
LifelineNotFoundException -
LifelineDuplicatedException -
LifelineNeverCreatedException -
LifelineCreatedRepeatedlyException
其中,在MyImplementation中,我们处理前两个关于交互不存在或有重名交互的情况;得到正确的唯一交互后,在MyInteraction中我们处理中间两个关于生命线不存在或有重名生命线的情况;最后,在得到正确的唯一生命线后,我们处理不存在创建消息或重复创建的情况。
具体的方法原型可以参考如下:
MyInplementation中
@Override
public UmlLifeline getParticipantCreator(String interactionName, String lifelineName)
throws InteractionNotFoundException, InteractionDuplicatedException,
LifelineNotFoundException, LifelineDuplicatedException,
LifelineNeverCreatedException, LifelineCreatedRepeatedlyException {
/* TODO */
}
MyInteraction中
public UmlLifeline getParticipantCreator(String interactionName, String lifelineName)
throws LifelineNotFoundException, LifelineDuplicatedException,
LifelineNeverCreatedException, LifelineCreatedRepeatedlyException {
/* TODO */
}
MyLineLine中
public UmlLifeline getParticipantCreator(String interactionName, String lifelineName)
throws LifelineNeverCreatedException, LifelineCreatedRepeatedlyException {
/* TODO */
}
Part 1 四个单元中架构设计思维和OO方法理解的演进
抽象
与Pre2中已经给出具体类如何设计不同,四个单元的作业内容不再给出如此具体的类搭建方法,需要一定的抽象能力。从第一单元的表达式,到第二单元的电梯,到第三单元的JML,到第四单元的UML,如何划分清晰的状态和功能特征,给出合适的抽象类至关重要。一种好的抽象可以有效提高代码的鲁棒性和健壮性,并降低代码重构的可能。
层次化
当使用面向对象的眼光来审视我们的任务时,模糊的层次化概念会在我们脑中朴素地浮现,但是,这是远远不够的,我们需要更清晰,更具体的抽象与层次化构建,搭建出既精简,又易扩展,还好维护的架构。第一单元的表达式层次化构建相对简单,training中也给出了具体的表达式因子->项->表达式的层次,并暗含递归关系;第二单元的电梯中,我采用了相对简单的无单独调度器的设计,基本只有电梯,候乘区和输入线程三种层次;第三单元中,JML规格已经限制了层次化设计;第四单元中,封装My*类、MyDataBase类和MyCheckForUml类的层次化设计令我受益匪浅。
封装与解耦
OO课程引入的checkstyle是我最喜欢的课程工具之一。这个工具从量化角度限制了空白符的使用,换行的使用,import的使用,类、方法与文件的行数等形式化规约。虽然看似只是限制了表面的代码风格,但实际上暗含了解耦的需求:面向过程的一main到底的设计方式将不再可取!
四个单元的演进过程中,我对于解耦的理解也逐渐深化:对于什么样的共性功能,可以抽象出来一个公共接口?既具有公共行为,又具有公共状态的类之间应如何设计关系?简单的功能是否还需要封装为一个方法,或者说复杂的方法应该解耦到多大粒度才合适?
除此之外,checkstyle确实让代码风格变得统一而优雅,这对于互测时会检查roommate代码源文件的同学是个不错的消息。
设计模式
理论课介绍了相当多的设计模式,其中,工厂模式、单例模式和生产者-消费者模型我较为熟悉,应用较多。
工厂模式对于new行为的封装符合SOLID原则,给出了更一般化的生产对象方法。
单例模式将一个应用广泛的对象的类封装为唯一实例,避免了在不同类的方法之间相互传递该对象的引用带来的繁琐。在第二单元中,对安全输出类的封装让我受益匪浅。
生产者-消费者模型是重要的多线程模型,在OS的理论课和实验课中也多有涉及。在第二单元中,生产者-消费者模型的优点得到了淋漓尽致的表现,我在该单元的设计基本依托于生产者-消费者模型展开。
Part 2 四个单元中测试理解与实践的演进
在OO作业中,对于每单元作业,我都以独立或合作的形式完成了评测姬的设计与实现,这样的锻炼让我收获良多。
第一单元中,我主要利用python的科学计算库sympy,直接随机生成输入数据,并计算答案的正确与否。同时,通过设置常量池,对于部分边缘数据进行较为有效的覆盖。
第二单元中,评测机主要采用随机数据生成与状态验证的办法,同时,由于本单元对CPU时间有较高要求,因此在linux中利用其计时工具检查是否存在轮询。
第三和第四单元,评测机主要采用随机数据生成与对拍的方式进行验证。这两个单元中,官方数据的压力较小,为了保证我们随机数据的覆盖性,我们加大了数据的强度,尽可能保证评测机有效性。
值得注意的是,上述评测机除了第一单元我亲自全流程完成过一个外,其他大多为和同学合作/修改学长的评测机,不得不说这是一个非常耗时耗力的工作,同时,经验尚浅的我很可能不能保证随机数据的强度和覆盖性。
尽管如此,搭建与修改评测机的过程依然收获良多,随机数据与边缘数据的生成,调用合适的库避免重复造轮子,与小伙伴对拍降低正确性验证难度等都让我在课程之外学到了更多知识,也更加让我意识到测试的重要性:你不会指望未来的生产中也总有官方评测机测试你的代码!
Part 3 课程收获
本学期的OO课程是大二以来体验最好的一门课。作为一门核心专业课,它不愧对“重课”“难课”的头衔,任务量与难度上都很难说轻松。但另一方面,这种“踮踮脚就可以够得到”的核心专业课,既做到了让我们走出舒适区,又不使课程难度过高而让人望而却步,为我带来了巨大的收获。
课程中老师、助教和同学们的悉心帮助是我能够完成OO的重要原因,没有如此负责而高水平的老师和助教,没有热心的同学们,就没有完成了课程的我,在这里再次向大家表示最诚挚的谢意。
OO课程中的闪光点令人惊叹:
- 区别于某些高校,我们注重实战训练,每周平均1k行代码的代码量避免同学们止步于理论和空谈。"Talk is cheap, show me the code"。
- 短平快的开发模式。一周一作业,三周一单元的开发进度恰属于“大家踮踮脚就可以够到”的水平。一方面,代码量保证了大家的训练量不会小,另一方面,我们的难度又不会设置的太高,三次作业迭代下来的3k行代码初具工程特点,短平快的特性又使得训练的性价比很高。
- checkstyle, git, starUML等现代工具的应用。我们拥抱了变化与未来,积极对接前沿的与主流的技术,checkstyle规范了代码风格,git规范了版本迭代与管理,starUML训练了使用统一建模语言进行跨越编程语言与领域的沟通能力。
- 阶梯式测试。中测、强测与互测的三个维度既兼顾了保证一般水平的同学可以通过本门课程,又保证水平更高的同学不至于“吃不饱”,在测试中提高面向对象的能力的理念也十分先进。
Part 4 课程改进建议
当下的OO课程已经十分优秀,但根据个人体验及与同学的讨论,或许以下方面仍有可以再进一步的空间。
预习课程
本学期OO Pre的体验很不错,特别是其中的pre1和pre2部分分别介绍了工具链与面向对象的基本思想。
关于pre1,希望可以增加简单介绍如何打一个jar包并使用命令行或python进行运行的简介,并可以在pre2中介绍利用这种方法进行自动化数据测试。
关于pre2,希望可以在现有基础上增加一个设计数据生成器与搭建自动评测(对拍)机的环节,鼓励同学们在pre阶段就能完成架构设计->代码编写->评测(对拍)机搭建->自动化测试的流程,为正式课程奠定基础。同时,可以增加几个简单的异常抛出例子,比如在本学期的冒险者游戏中,可以设置如果使用了不存在的武器则抛出异常。
关于pre3,根据不严谨的身边统计学观察,大家在unit1中大多选择了递归下降法,因此也可以在pre3中用一个简单的例子介绍这种方法,并给出类似本学期第一次training的框架,或许可以有效降低第一次作业的挑战性。
第二单元
- 训练部分已经介绍了生产者消费者模式和观察者模式,这让我受益匪浅,这一部分也可以增加介绍单例模式,尤其可以简化调度器在各个类的传递。
- 本单元有同学完成了电梯的可视化,或许可以在训练或实验中增加该项目,给出大致框架后使得同学们拥有一个自己的电梯可视化代码。
第三单元
- 可以增加介绍在vscode中使用Java+JML的语言模式来高亮JML,减轻阅读注释代码难度,具体效果可以参考http://oo.buaa.edu.cn/assignment/356/discussion/1194
- 可以增加小测试,让同学们对某几个方法的JML用自然语言描述,并比较JML和自然语言的优劣,并可以适当引入UML进行更大范围的比较
第四单元
- 在“测验”中可以增加对单元架构的理解,如“AppRunner”的运行模式等,确保同学们对单元要求有基本的正确理解。
- 可以增加官方包代码导读文档,如介绍各个package大致功能以及协作关系,或以小测试形式进行检验。
Part 5 后记
本学期的OO课程到此告一段落,回首一学期的四个月,每周的生活里都留下了OO的印记,尽管过程中不可不说遇到了相当程度的挑战与挫折,但是在老师、助教和同学们的帮助下,我最终也得以幸运地完成了全部课程。在这里,再次向大家表示诚挚的谢意。
尽管OO2022即将结束,但我与OO的缘分似乎还没有走到尽头,在接下来的一年里,我将作为OO2023助教团队的一员,通过参与课程建设的方式继续OO之旅,和大家一起让OO变得更好!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!