「BUAA OO Unit 1 HW1」面向测试小白的简易评测机
「BUAA OO Unit 1 HW1」面向测试小白的简易评测机
声明:本评测机所使用数据生成来自郭鸿宇同学,这对本评测机非常重要
Part 0 前言
笔者的配置与环境
- Windows10家庭版
- Pycharm 2021.3.2
- Anaconda1.9.7,其中用于python项目的python版本为3.6,但是应该是python3就可以
- IDEA 2021.3.2
面向人群
所有人,无论是否有python基础或者评测机搭建经验。
定位
基于本篇博客,您可以从零迅速搭建一个适合您的评测机,并且对您的项目路径没有要求。得益于数据输入输出和数据生成模块的解耦合,您可以快速迁移本评测机的输入输出,并更换您需要的数据生成模块,提高了泛用性。
Part 1 准备工作
- 若没有,则安装Anaconda,并安装一个python3的环境,这将在Part5附录部分介绍
- 若没有,则安装IDEA和Pycharm
Part 2 获取java jar包
目的
为了避免不同同学的Java项目结构目录、依赖包等的不同导致的无谓的麻烦,将Java项目打包为jar包,方法可移植性强。
过程
-
在IDEA中创建项目,并将代码置于其中,测试可以运行即可。如果有依赖包,则需要导入依赖包。
-
File->Project Structure->Artifacts->+->JAR->From modules with dependencies...
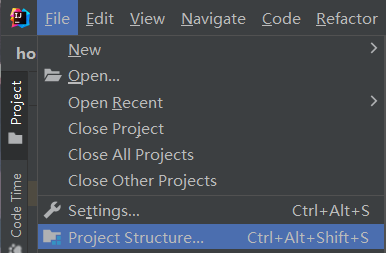
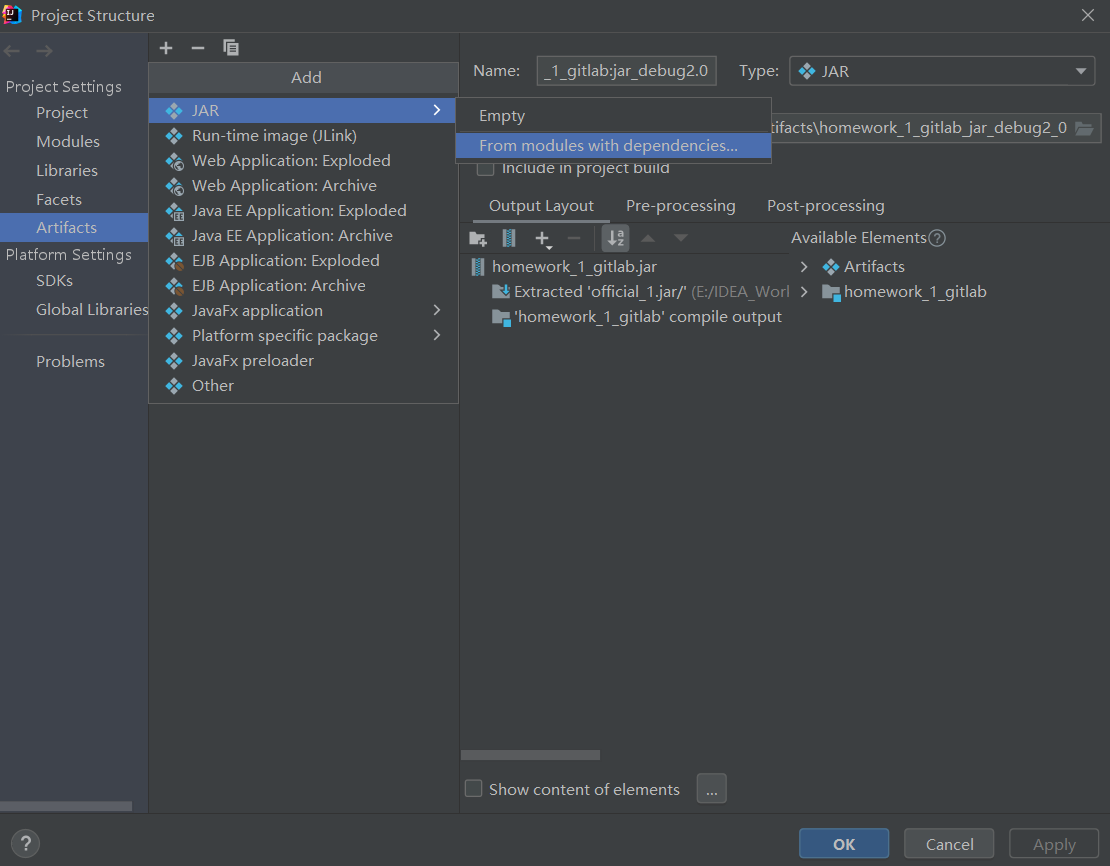
-
Main Class中选中程序入口类->OK->Cancel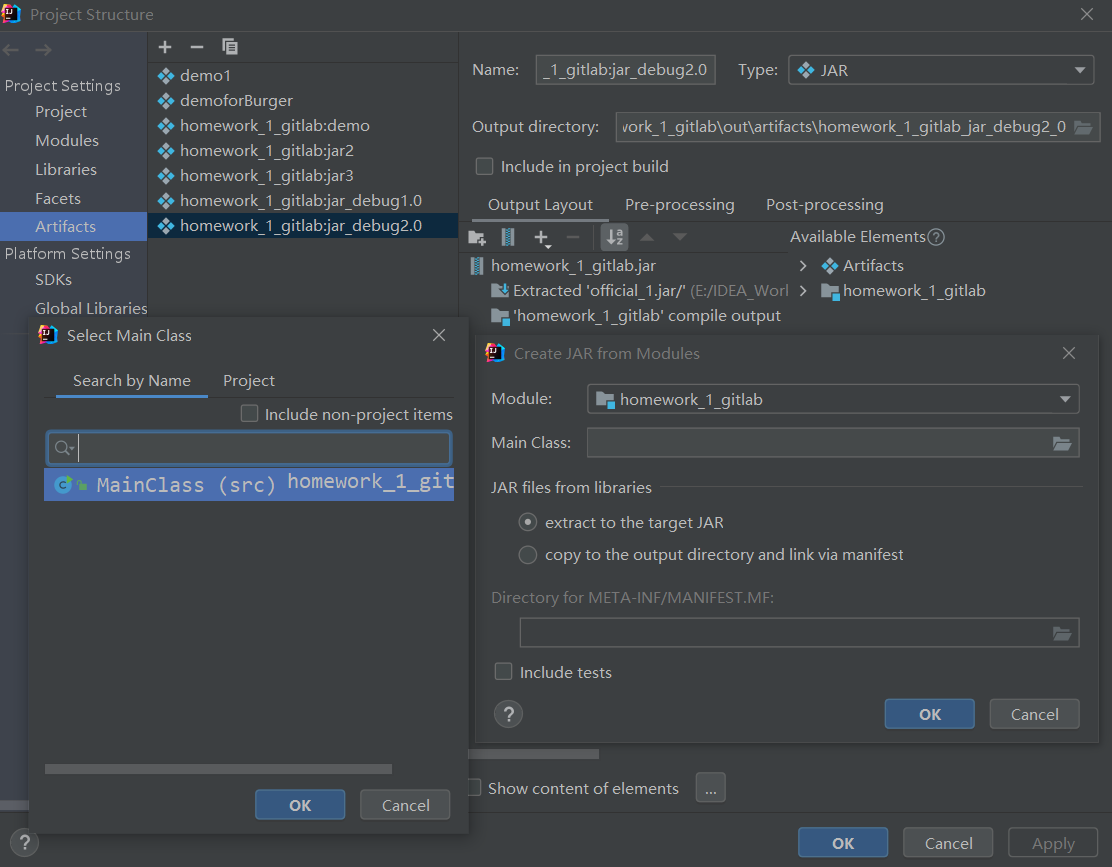
-
修改
Name(也可以不改)->Apply->OK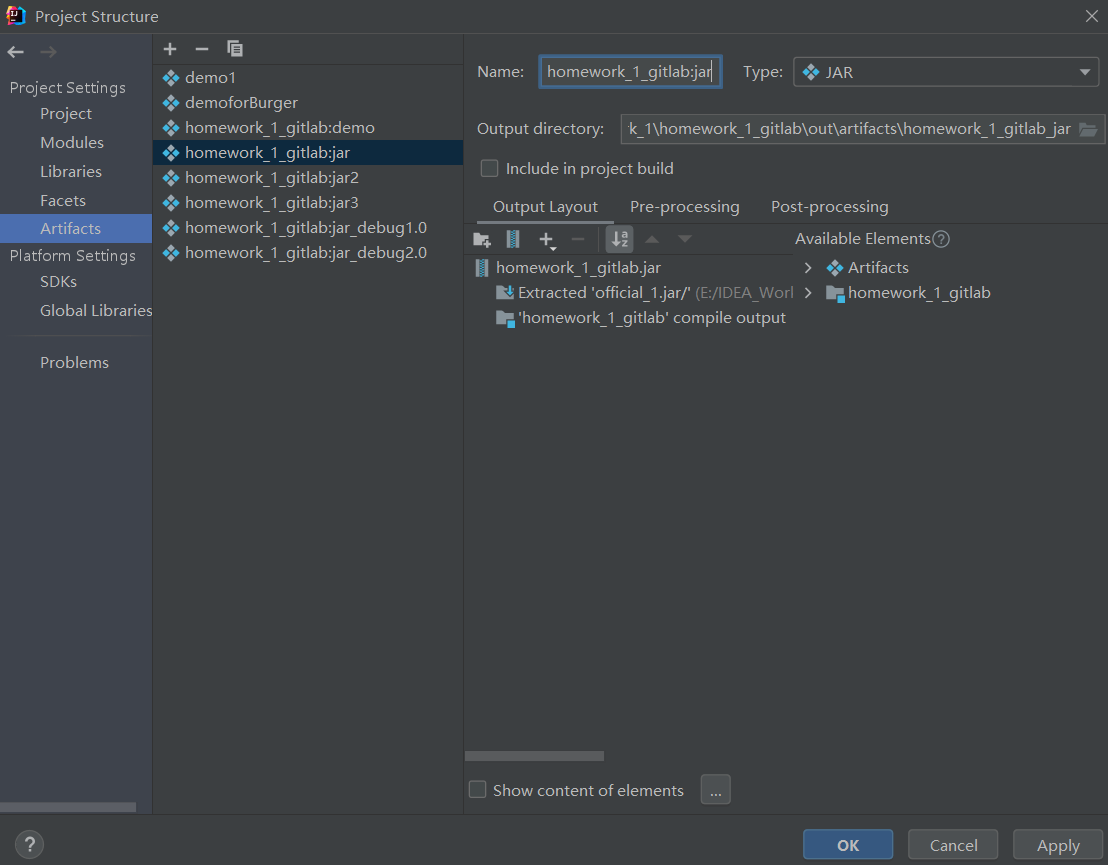
-
Build->Build Artifacts,然后在其中选择刚才Name的项,然后Build
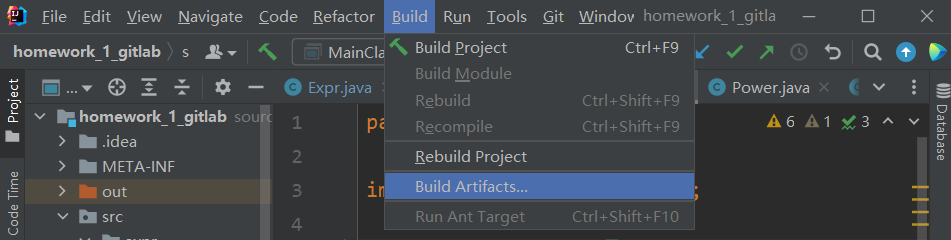
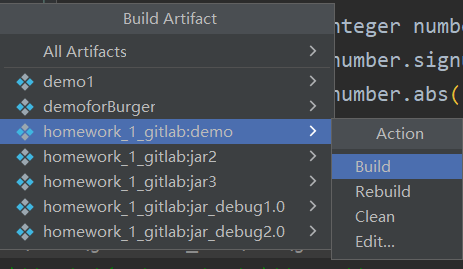
- 在项目目录/out/artifacts/
Name下可以找到生成的jar包
须知
对于本次作业,课程组提供的官方输入输出包需要被注释掉,同时需要自行将原MainClass中的Scanner切换回标准的Scanner SCANNER = new Scanner(System.in)。同时,本评测机暂不支持预解析模式输入。
Part 2 修改评测机参数
pipline.py
import sympy # 如果报错显示没有这个包,就需要导入
from xeger import Xeger
import random
import subprocess
from subprocess import STDOUT, PIPE
from gendata import genData
def execute_java(stdin):
cmd = ['java', '-jar', 'archer.jar']# 更改为自己的.jar包名
proc = subprocess.Popen(cmd, stdin=PIPE, stdout=PIPE, stderr=STDOUT)
stdout, stderr = proc.communicate(stdin.encode())
return stdout.decode().strip()
x = sympy.Symbol('x')
X = Xeger(limit=10)
cnt = 1
while True:
cnt = cnt + 1
if cnt % 1000 == 0:
print(cnt)
poly, ans = genData()
#print(poly)
f = sympy.parse_expr(poly)
strr = execute_java(poly)
#print(strr)
g = sympy.parse_expr(strr)
if sympy.simplify(f).equals(g) :
print("AC : " + str(cnt))
else:
print("!!WA!! with " + "poly : " + poly + " YOURS: " + strr)
上述代码中需要改jar包为自己的包名。
其他不修改即可正常使用,也可根据需求自行修改。
gendata.py
"""
Auther: GHY
Date: 20222022/3/5
"""
import random
import sympy
intPool = [0,1,2,3,4] # 常量池
hasWhiteSpace = False # 是否加入空白字符
hasLeadZeros = False # 数字是否有前导零,如果传入sympy的表达式中数字有前导零,sympy将无法识别
maxTerm = 10 # 表达式中的最大项数
maxFactor = 3 # 项中最大因子个数
specialData = ["1","x-x","-1"] # 可以放一些特殊数据
globalPointer = 0
def rd(a,b) :
return random.randint(a,b)
def getWhiteSpace():
if hasWhiteSpace==False:
return ""
str = ""
cnt = rd(0,2)
for i in range(cnt):
type = rd(0,1)
if type==0:
str = str + " "
else:
str = str + "\t"
return str
def getSymbol():
if rd(0,1)==1:
return "+"
else:
return "-"
def getNum(positive):
result = ""
integer = intPool[rd(0,len(intPool)-1)]
iszero = rd(0,2)
for i in range(iszero):
result = result + "0"
if hasLeadZeros==False:
result = ""
result = result + str(integer)
if rd(0,1)==1:
if positive==True:
result = "+" + result
else:
result = getSymbol() + result
# print("num:"+result)
return result
def getExponent():
result = "**"
result = result + getWhiteSpace()
case = rd(0,2)
if rd(0,1)==1:
result = result + "+"
if case==0:
result = result + "0"
elif case==1:
result = result + "1"
else:
result = result + "2"
# result = result + getNum(True)
# print("exponent:"+result)
return result
def getPower():
result = "x"
if rd(0,1)==1:
result = result + getWhiteSpace() + getExponent()
# print("Power:"+result)
return result
def getTerm(genExpr):
factorNum = rd(1,maxFactor)
result = ""
if rd(0,1)==1:
result = getSymbol()+getWhiteSpace()
for i in range(factorNum):
factor = rd(0,2)
if factor==0:
result = result + getNum(False)
elif factor==1:
result = result + getPower()
elif factor==2 and genExpr==True:
result = result + getExpr(True)
else:
result = result + "0"
if i < factorNum-1:
result = result + getWhiteSpace() + "*" + getWhiteSpace()
# print("term:"+result)
return result
def getExpr(isFactor):
termNum = rd(1,maxTerm)
result = getWhiteSpace()
genExpr = True
if isFactor==True:
genExpr = False
for i in range(termNum):
result = result + getSymbol() + getWhiteSpace() + getTerm(genExpr) + getWhiteSpace()
if isFactor==True:
result = "(" + result + ")"
if rd(0,1)==1:
result = result + getWhiteSpace() + getExponent()
# print("Expr:"+result)
return result
def genData():
global globalPointer
if globalPointer<len(specialData):
expr = specialData[globalPointer]
globalPointer = globalPointer + 1
else:
expr = getExpr(False)
x = sympy.Symbol('x')
simplifed = sympy.expand(eval(expr))
return str(expr),str(simplifed)
x = sympy.Symbol('x')
fx = "+x**+0*x**0++3++x**+1*+1"
y = sympy.expand(eval(fx))
print(y)
上述代码不修改即可正常使用,也可根据需求修改数据生成方式。
Part 3 评测机架构
本评测机仅需要将jar包、pipline.py和gendata.py放在同一目录下即可,无其他要求。
对于多个jar包,允许在多个文件夹中分别存放评测机,同时测试运行。
Part 4 有待改进的地方
- Part2中要求注释掉官方包及切换回Scanner的原因是,目前笔者没有办法在获取输出时跳过第一行,但这应该可以做到。
Part 5 附录:如何从0配置本评测机可运行的 python+Anaconda 环境
一、下载pycharm:
此步仅执行连接中步骤1.2.3,即不进行后续python安装即环境变量的配置。仅安装pycharm。
https://www.runoob.com/w3cnote/pycharm-windows-install.html
二、Anaconda安装教程
如果没有特定版本需求,可选择文中版本安装,此版本默认安装python3.7
https://zhuanlan.zhihu.com/p/75717350
三、创建python项目时关联Anaconda的python.exe
仅参考步骤五即可
https://www.cnblogs.com/yuxuefeng/articles/9235431.html
四、安装 xeger库:见链接方法一
https://www.cnblogs.com/ShineLeBlog/p/10893419.html
五、更新sympy库
同上,在此界面取消Anaconda模式后,找到sympy库双击。
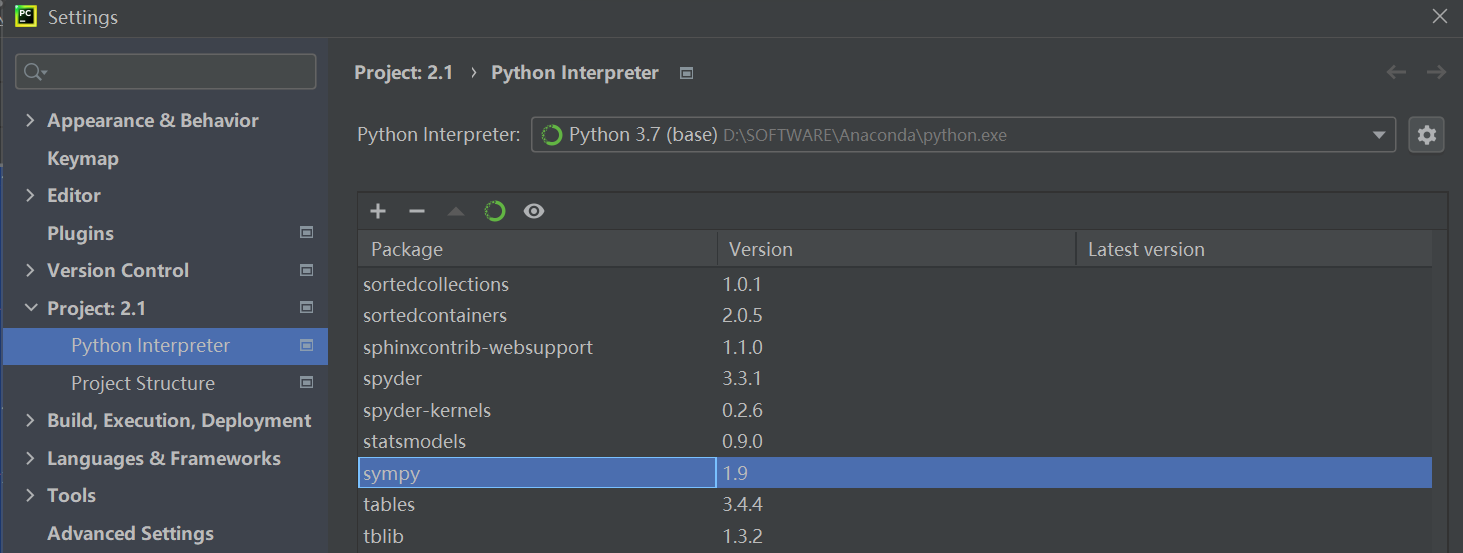
勾选 Spectify version ,选择1.9版本,点击 Install Package。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!