
微服务系列之分布式日志 ELK
1.ELK简介
ELK是ElasticSearch+LogStash+Kibana的缩写,是现代微服务架构流行的分布式日志解决方案,旨在大规模服务的日志集中管理查看,极大的为微服务开发人员提供了排查生产环境的便利。如果规模较小的日志量,直接使用ElasticSearch、Logstash、Kibana是可以满足其应用的,但是对于日志量较大的中大规模服务集群来说,这3个中间会引入Filebeat、Kafka、Zookpeer三个中间来大幅度提升采集性能、可靠性、可扩展性。目前来说,大部分公司使用的解决方案架构如下图:
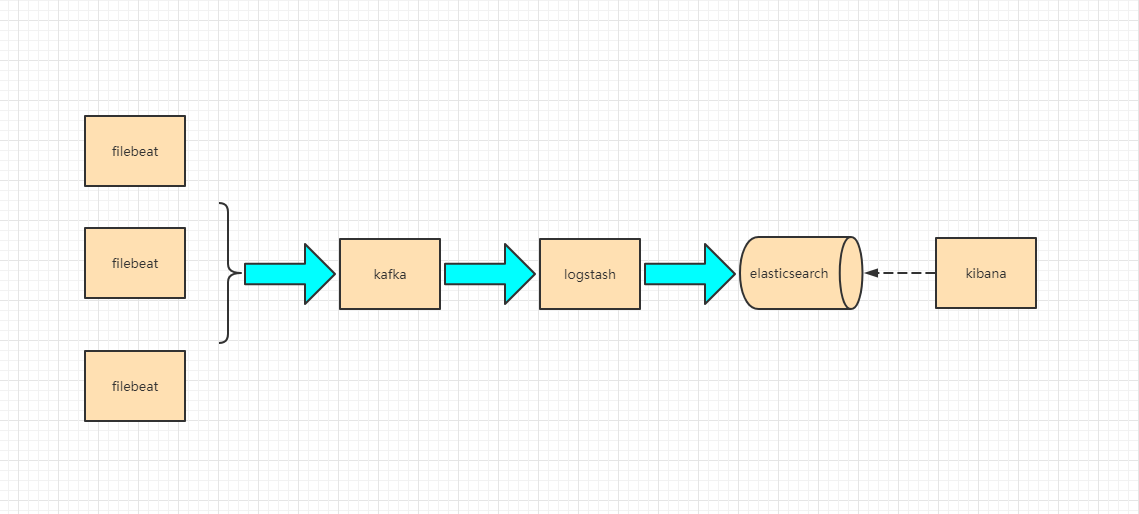
此篇文章,我们一起来熟悉整个流程的搭建,为了方便演示,环境基于docker(正常情况下,因为这套系统是直接linux部署的,因为开销实在是很大)。
2.API服务
先建一个api服务,使用过滤器,让请求前后都会产生日志
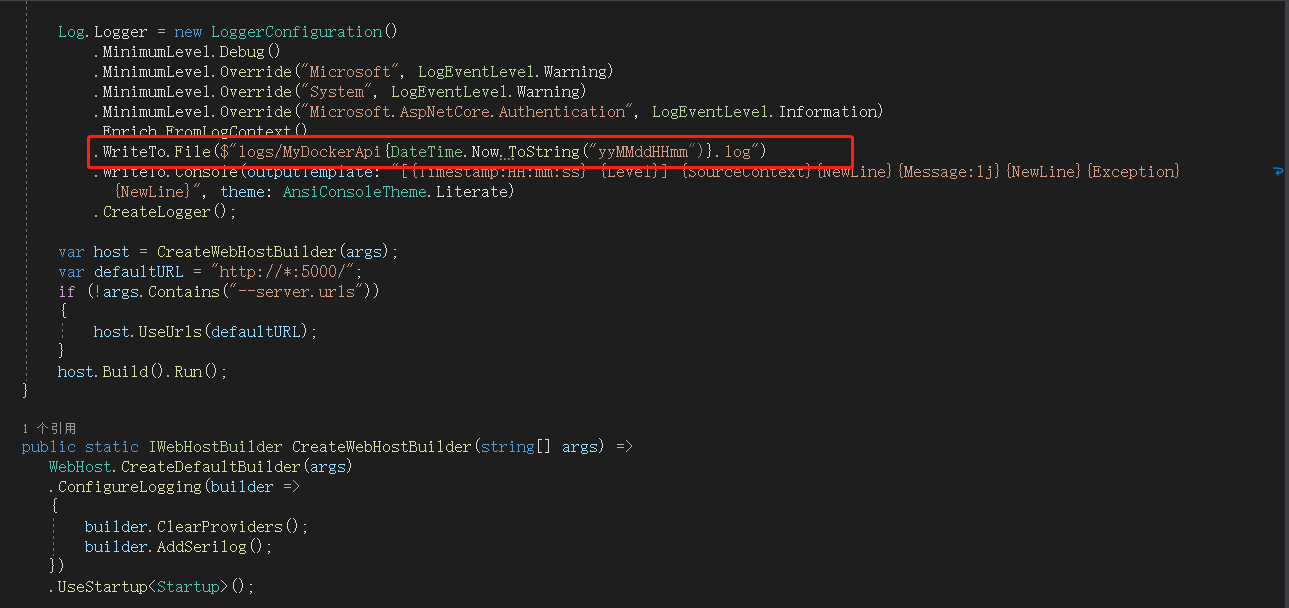
我这里,将日志写到根目录下logs文件夹,以MyDockerApi *.log产生日志文件,接下来,发布,并上传到linux服务器,并用docker启动,不会的同学传送门:https://www.cnblogs.com/saltlight-wangchao/p/16646005.html。

由于docker的隔离性,想要采集日志,必须给服务docker挂载到linux宿主机的盘内,上图就是我为该API服务创建的日志写入目录,因为可能一个宿主机上可能有多个API服务,所以,可以按照规则,继续新建服务文件夹,用于存放不同API服务的日志,我这里就弄了一个先。
docker run --name API8082 -p 8081:5000
-v /etc/localtime:/etc/localtime --解决 docker 容器时间与本地时间不一致
-v /home/fileBeate/logs/mydockerapi1:/app/logs --挂载目录,降容器的app/logs目录挂载到宿主机,我们要指定该服务采集的目录
my1api
启动后,请求该服务
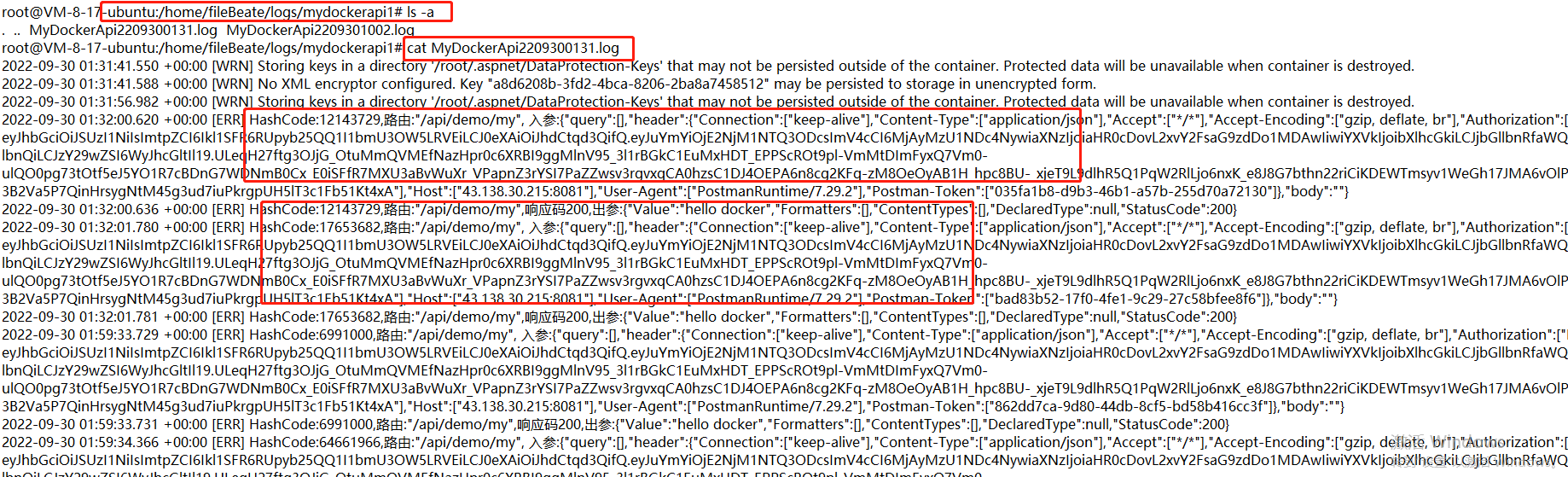
至此,api服务所产生的日志,已经写到我们要采集的指定目录里。
3.Filebeat
Filebeat是用于监视、采集、转发指定位置的文件轻量级开源工具,使用golang编写,就采集来说,其性能和资源利用率远好于基于jvm的logstash。
在这里,filebeat做为kafka的生产者
1)拉取filebeat镜像
docker pull docker.elastic.co/beats/filebeat:6.4.2
2)创建filebeat.yml配置文件,进行vim修改
基础的配置

--- filebeat.inputs: - type:log enabled: true fields: log_topics: mydockerapi1 --命名以服务名字,注意,因为一台宿主机可能有多个服务,而我们采集也要分开,再来一组-type paths: - /usr/share/filebeat/mydockerapi1-logs/*.log --这里是docker内的路径,千万别写错了。如果是 output.kafka: hosts: - "10.0.8.17:9092" --kafka的地址 topic: "elk-%{[fields][log_topics]}" --消息队列的topic
3)运行
docker run --restart=always --name filebeat -d
-v /home/filebeat.yml:/usr/share/filebeat/filebeat.yml
-v /home/fileBeate/logs/mydockerapi1/:/usr/share/filebeat/mydockerapi1-logs
docker.elastic.co/beats/filebeat:6.4.2
进入filebeat容器内部如下图,可以看到已经采集到日志文件

使用 docker logs -f filebeat 命令,查看filebeat日志

上图可见,采集完日志后,像kafka发送了
4.Zookeeper/Kafka
kafka是结合zookeeper一起使用的,kafka通过zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。producer使用push模式将消息发布到broker,consumer使用pull模式从broker订阅并消费消息,这里不过多描述,感兴趣的可以去详细查看。
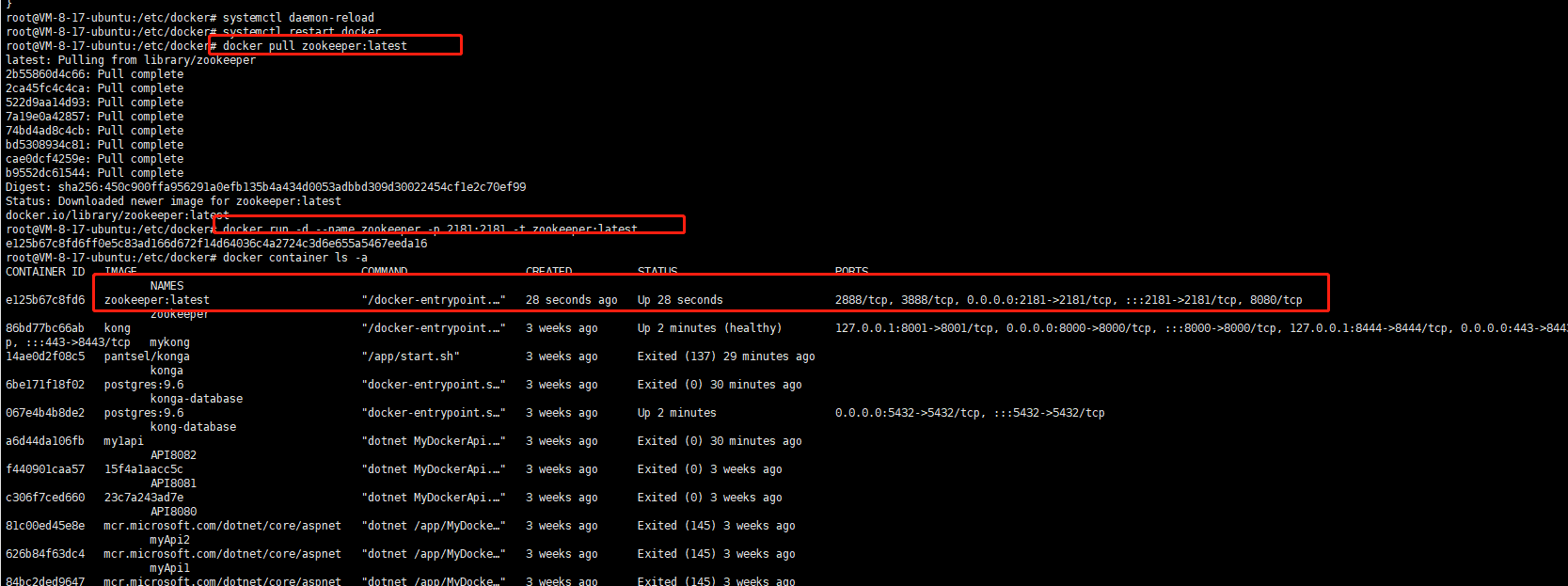
1)拉取zookeeper镜像并运行
docker pull zookeeper:latest docker run -d --name zookeeper -p 2181:2181 -t zookeeper:latest
2)拉取kafka镜像并运行
docker pull wurstmeister/kafka:latest docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=10.0.8.17:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://10.0.8.17:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka:latest
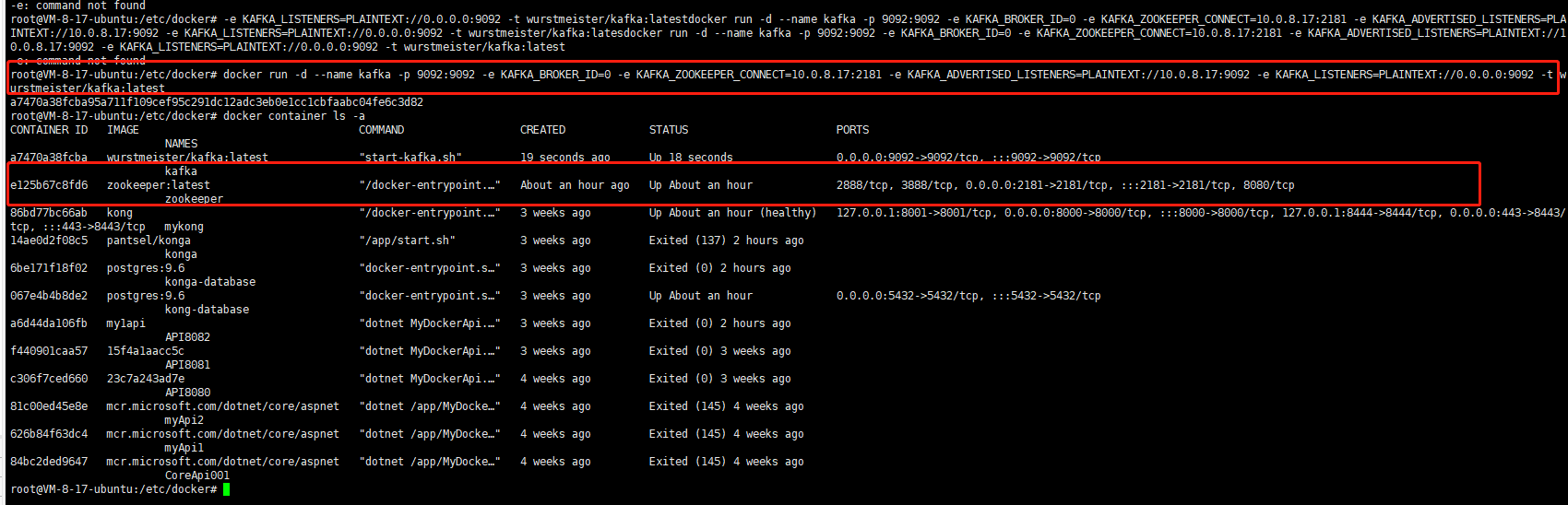
3)查看filebeat是否采集完日志,是否之前配置的topic写进来,直接执行下面命令
docker exec -it kafka bash cd /opt/kafka/bin kafka-topics.sh --zookeeper 10.0.8.17:2181 --list

可见,我们采集的日志已经写进来了。接下来,使用exit命令退出容器。
5.Logstash
Logstash是一个接收、过滤、输出的组件,三块形成一个管道,其实这个的功能性很强大,配置起来也很繁琐,我们这里主要是收集各个API服务的日志用,所以就做基础配置即可
1)拉取镜像
docker pull docker.elastic.co/logstash/logstash:6.4.3
2)创建配置文件并配置
input{ kafka{ 数据源来自kafka,此时logstash做为消费者 bootstrap_servers => "10.0.8.17:9092" kafka地址 topics_pattern => "elk-.*" 消费的主题匹配elk-开头的 consumer_threads => 5 -消费线程数 decorate_events => true codec => "json" auto_offset_reset => "latest" } } output { elasticsearch { 输出到es hosts => ["10.0.8.17:9200"] es地址 index => "ts-mydockerapi1" es的索引 } }
上述是简单的配置,生产中在输出output块中,,要根据topic来输出到不同的索引配置如下:
output { if [@metadata][kafka][topic] == "elk-mydockerapi1" { elasticsearch { hosts => "http://10.0.8.17:9200" index => "ts-mydockerapi1" timeout => 300 } } 这里可以多个if判断,输出到不同的索引中 stdout {} }
3)运行
docker run --name logstash -d -e xpack.monitoring.enabled=false -v /home/logstash:/config-dir docker.elastic.co/logstash/logstash:6.4.3 -f /config-dir/logstash.conf

至此logstash启动成功,日志显示正常。至于繁琐的过滤配置,主做运维的同学,可以深研究下,后端同学了解下就行了。我这期间,老是遇到内存溢出的情况,可以改一下,logstash的配置文件,进入docker容器,位置在config/jvm.options,可以修改下内存使用。
6.ElasticSearch
简称es,elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。官方概念,我们本篇文章不做深入研究,只就ELK分布式日志应用来说。
1)拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.4.2
2)运行es
docker run --name myes --restart=always -p 9200:9200 -p 9300:9300 -d -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.4.2
3)查看logstash输入到es的数据
浏览器运行http://你的IP:9200/_search?pretty

日志数据已经进来了,接下来最后一步,展示日志。
7.Kibana
kibana是一个开源的分析与可视化平台,设计出来用于和elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在elasticsearch索引里的数据,使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化.
1)拉取镜像
docker pull docker.elastic.co/kibana/kibana:6.4.3
2)运行
docker run -d --name kibana -p 5601:5601 -e ELASTICSEARCH_URL=http://10.0.8.17:9200 docker.elastic.co/kibana/kibana:6.4.3
3配置展示
运行起来后,打开你的ip:5601,刚进来会让你创建索引,步骤如下图
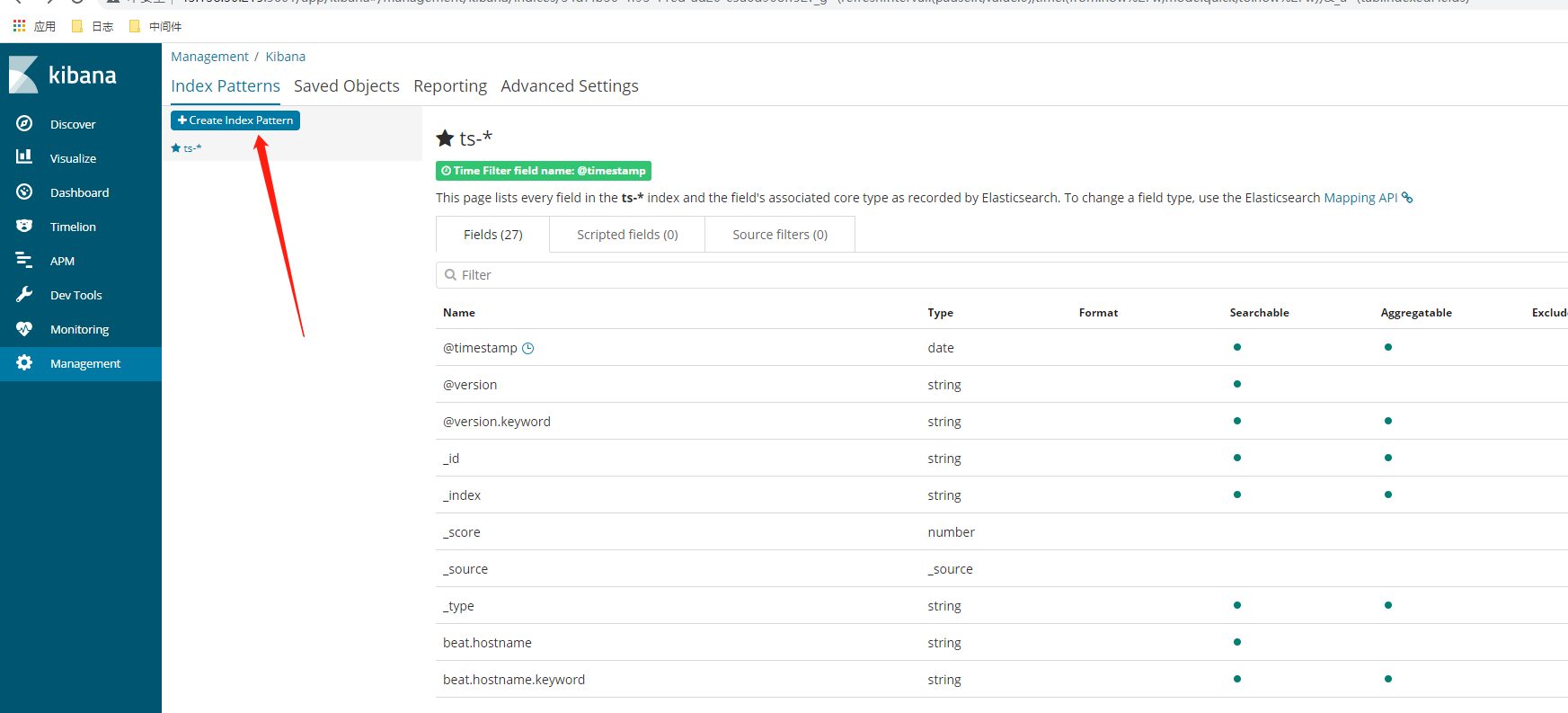
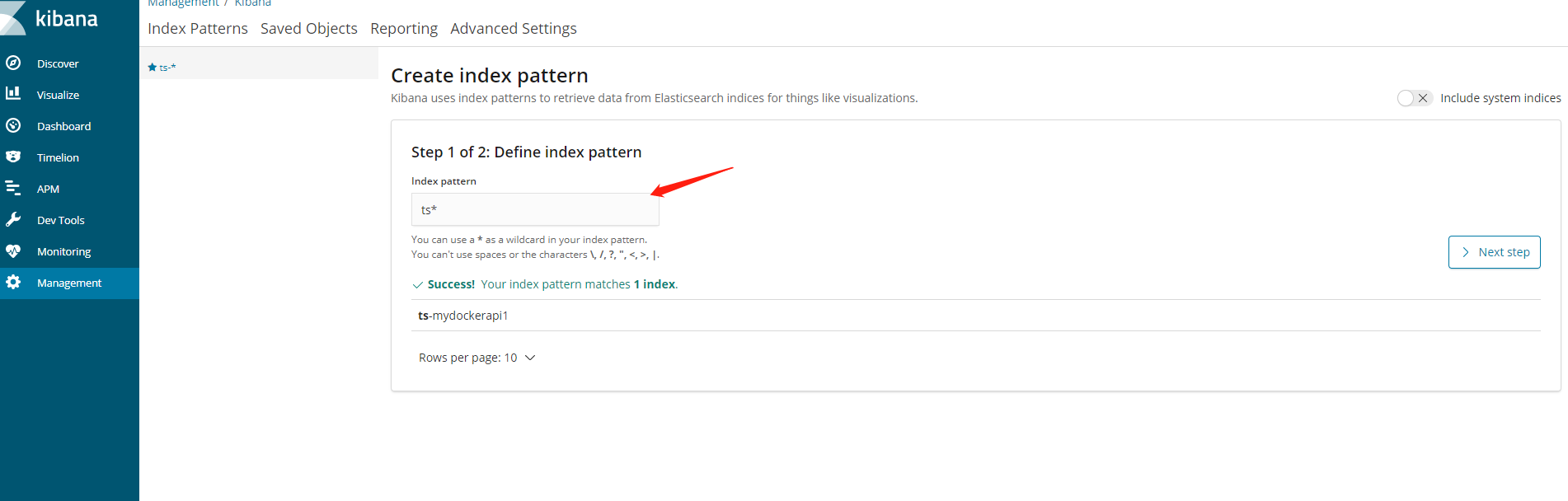
选择next step按钮,创建完毕,如下图
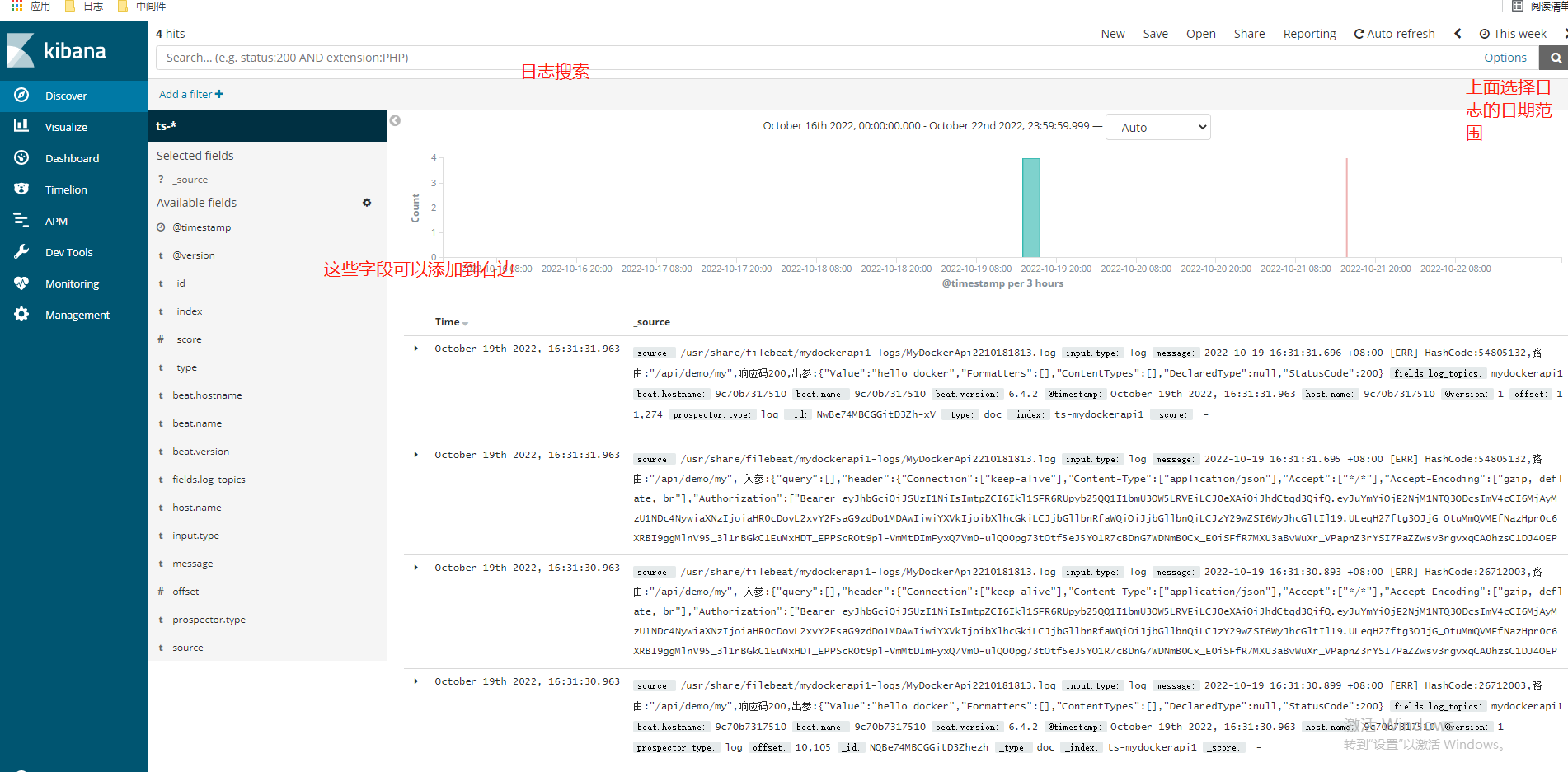
由于我这个linux服务器太弱了,ELK完全运行起来太卡了,就不继续做了,可以再建个API服务,模拟多个服务日志,通过ELK采集,在kibana里,根据logstash输入进es的索引,来展示对应服务的日志,如下图:
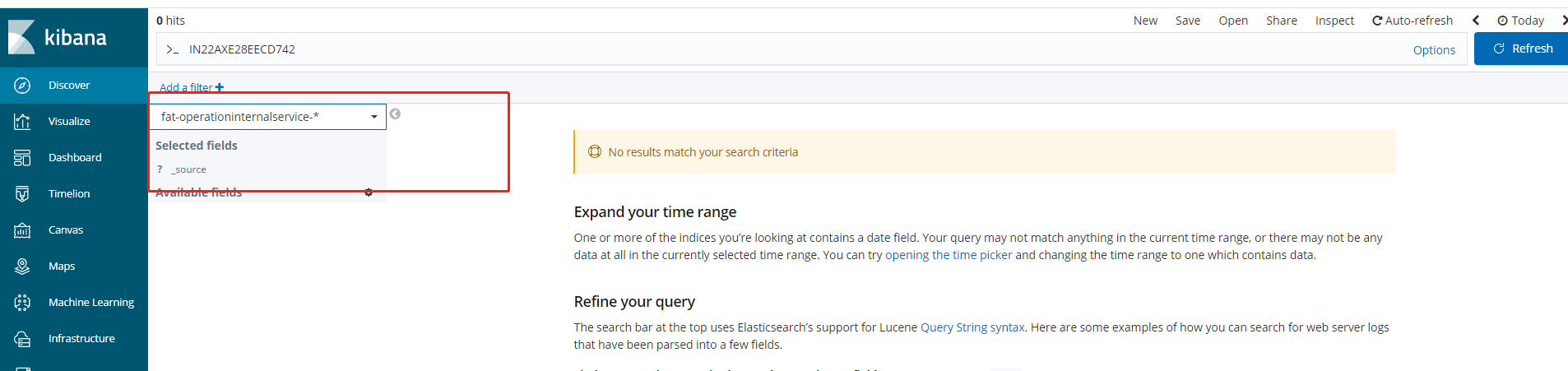
这里就可以选择对应API服务的索引日志了。。。
最后做为后端研发来说,一个有规模的做微服务的团队,ELK的搭建不是直接购买云产品,就是由运维来搭建,但是小规模团队,还是需要后端同学来搞的,总之,后端研发人员可以不实践,但是最好要了解一下整体流程。OK本文到此结束。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)