2020软件工程实践个人编程
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 大数据处理 |
| 学号 | 031802619 |
目录
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 10 | 60 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 60 | 60 |
| Design Spec | 生成设计文档 | 60 | 30 |
| Design Review | 设计复审 | 30 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 30 | 90 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 60 | 90 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 10 | 20 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| Total | 合计 | 490 | 620 |
二、解题思路
在仔细阅读题目并查找题目相关资料后,我了解到这次题目属于一个常见的大数据处理题目,类似题目如各个网站的用户数据分析,而这类题目难点在于:
用户行为往往成正态分布,极活跃用户的行为数远高于一般用户,但这一群体数量较少;同理,不活跃用户同样数量不多,但是仍不可遗漏。如果给每个用户分配同样的行为记录空间,则会造成大量的冗余。
综上,如何减少遍历次数与合理分配储存空间便是我们需要关注的重点。
需求分析
1.根据所给数据格式,我了解到需要先学习读入json数据
2.如何读取大量用户数据,并且尽可能缩短处理时间

3.将处理后的用户数据转存,并尽可能方便的查找
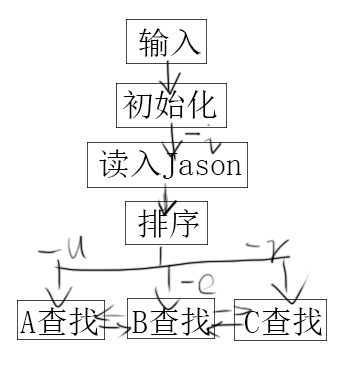
思路设计
1.对于需求1,需要逐条读入
2.对于需求2,我认为使用python提供的字典快速排序可以将用户ID与行为快速分类,以减少遍历次数
3.将排序后的字典的各个项目通过用户id和项目id进行索引,方便快速查找
三、流程图
四、代码说明
初始化
输入+读入jason+排序并将排序后的结果归纳并存入列表
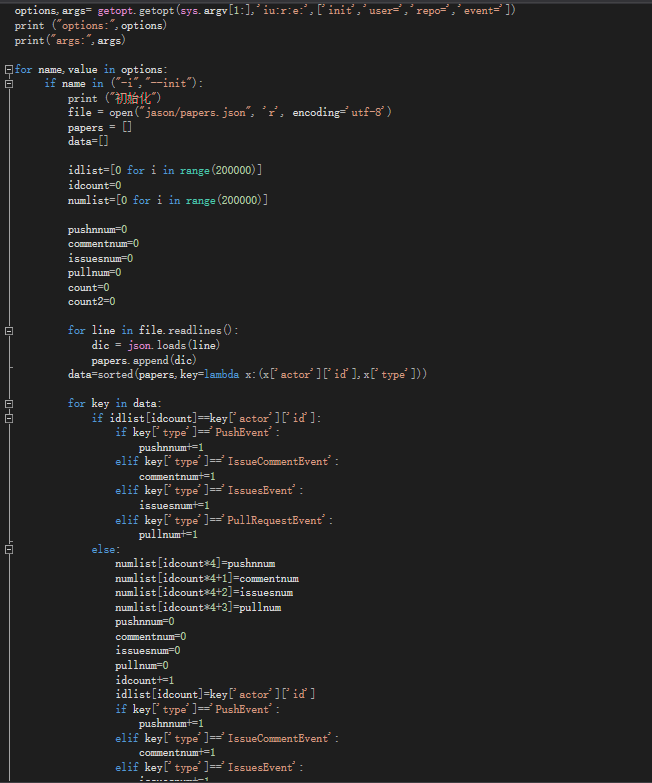
A搜索,查找用户的某项事件数量

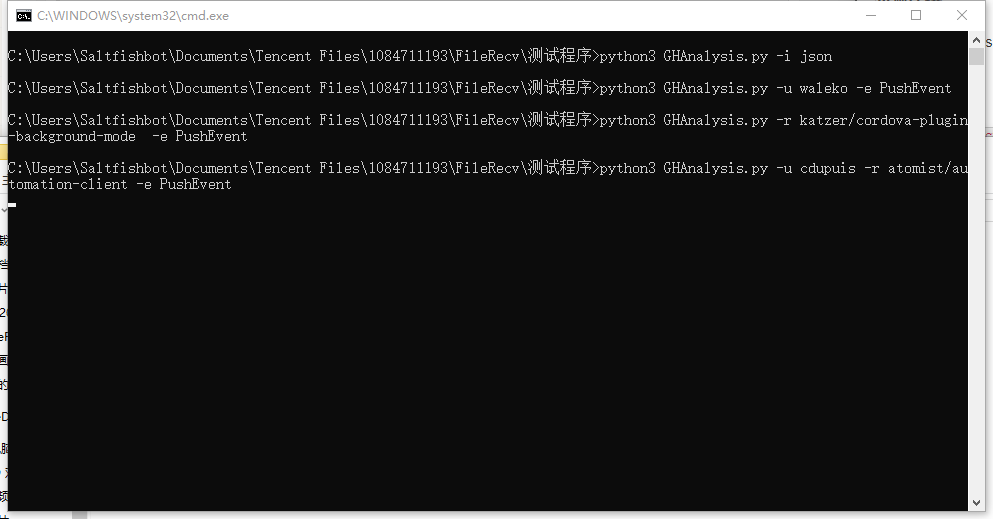
五、单元测试截图和描述
六、单元测试覆盖率优化和性能测试,性能优化截图和描述
覆盖率测试学习


性能测试学习

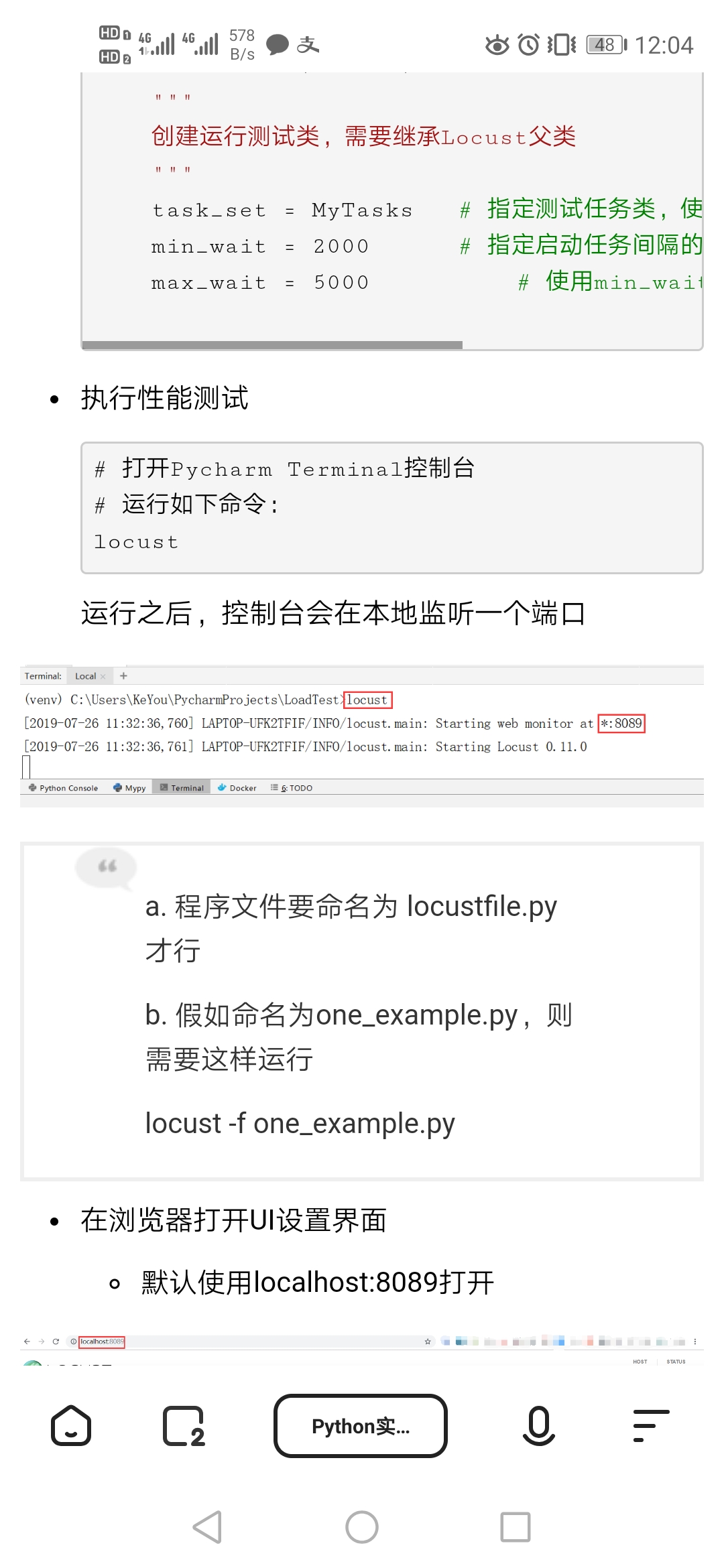
因为能力不足,无法将这部分功能实现,在一段时间的学习无果后,仅将以上学习过程贴出,希望助教和老师给予讲解。
七、代码规范的链接
https://github.com/Rainy12138/2020-personal-python/blob/master/codestyle.md
八、总结本次作业
之前从未尝试过这种类型的编程,从一开始拿到题目时开始解读,到后来学会读入jason后对数据处理的一系列思考,不得不说以前学过的数据结构在这时就有些“书到用时方恨少”的感觉了。虽然曾经在参加项目时听过大佬讲解架构与计划,但是到自己处理接口和规划结构时才知道其中的困难,甚至最后因为时间不足直接将函数全部放进main函数了,只能说勉强达到了功能。对于命令行输入仍然不是很理解,会在下次作业中花更多时间研究。
