Python-爬取新浪每日热门数据
1. 初实现
最初是计划爬取页面后,使用xpath进行数据解析,并输出至文件
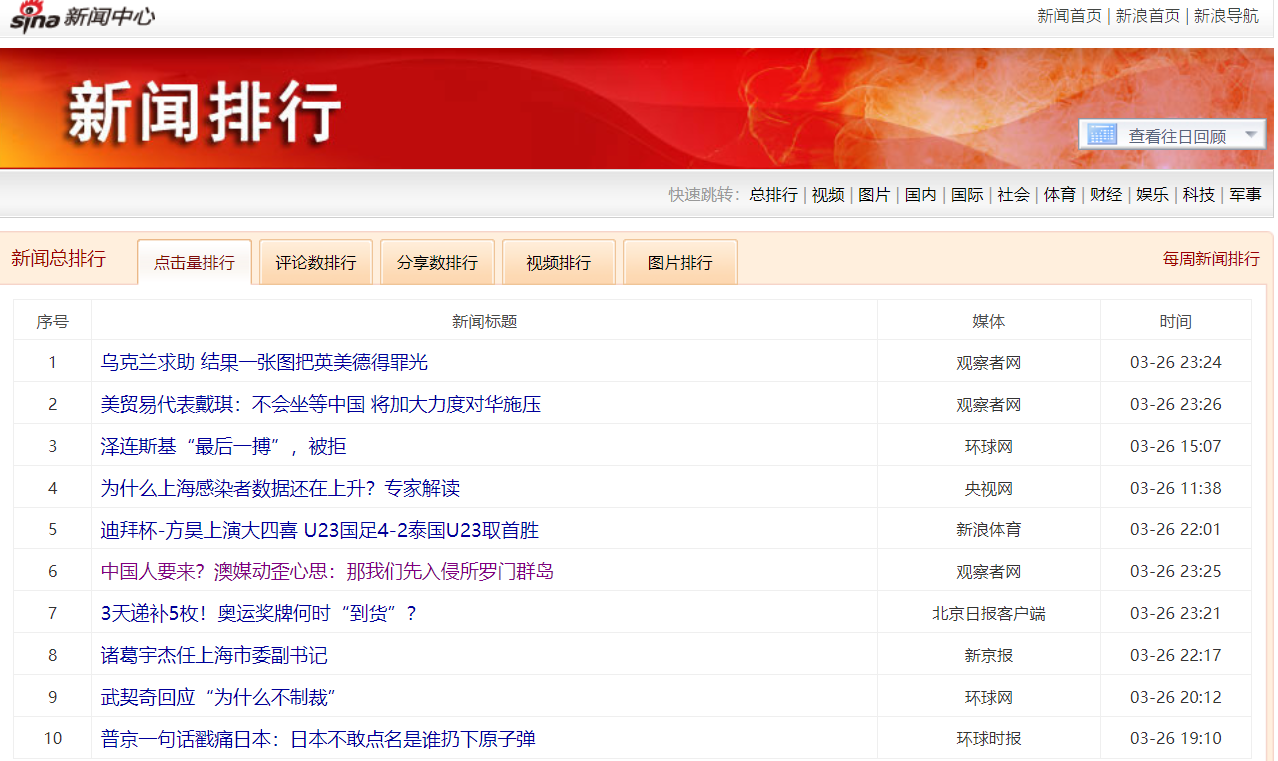
代码如下:
import requests
from lxml import etree
# url = "https://news.sina.com.cn/hotnews/index_weekly.shtml"
url = "https://news.sina.com.cn/hotnews/"
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"}
response = requests.get(url, headers=dic)
response.encoding = response.apparent_encoding
# 对td进行处理
html = etree.HTML(response.text)
# xpath路径
target_xpath = '/html/body/div[1]/div[5]/div[2]/table'
div = html.xpath(target_xpath)[0]
# 当前元素中的所有td列表 去除第一个多余项
td_list = div.xpath('//td')[1:]
item_list = []
# 遍历td元素列表
for td in td_list:
title = td.xpath('./a[1]/text()')
# 若存在子元素,则获取title
if len(title) > 0:
# print(title)
item_list.append(title)
else:
# 若不存在 直接获取文本值
item = td.xpath('./text()')
# 若无文本数据 赋空值
if len(item) == 0:
item = ['']
item_list.append(item)
print(item_list)
# 遍历item_list
# 将item_list中的分离的内容合并到字典列表中
# 每四个(序号、标题、媒体、时间)一组
news_list = [] # 字典列表
i = 0
while i < len(item_list):
try:
num = item_list[i]
title = item_list[i + 1]
media = item_list[i + 2]
time = item_list[i + 3]
i += 4 # 每四个一组
news_dic = {"num": num[0], "title": title[0], "media": media[0], "time": time[0]} # 加入字典
news_list.append(news_dic) # 将字典加入列表
except:
print("循环结束")
break
# 结果写入文件result.txt
for news in news_list:
# 根据需要切换参数mode a-追加内容 w-写入内容(覆盖)
with open("result.txt", mode='a', encoding="utf-8") as fs:
fs.write(str(news) + "\n")
2. 出现的问题
- 只能当天的数据可以在网页中显示,对其他时间的数据爬取存在困难
- xpath解析table元素存在问题,直接使用"//td"后处理数据复杂
3. 解决办法
转变思路,在使用调试工具找到获取数据的链接

https://top.news.sina.com.cn/ws/GetTopDataList.php?top_type=day&top_cat=www_www_all_suda_suda&top_time=20220327&top_show_num=10&top_order=DESC
对此链接进行分析,可以知道其参数的作用:
如top_time为日期,top_show_num为请求数量,top_order为排序方式,top_type为日期范围
但是获取到的是js代码,并不是我期望的json正确格式

这个var data = 就很烦,使用strip()方法去除掉,并且使用split()方法将最后的分号也去掉
text = response.text.strip('var data=').split(";")[0]
这样就获得了完美的json数据,并且通过几个参数就可以想要的对应时间、日期范围和数量的数据
4. 完整代码
import requests
import json
# json数据输出为json_data.json文件
def output_to_file(data, mode='w'):
# 写入文件
with open("json_data.json", mode=mode) as fw:
fw.write(json.dumps(data))
top_show_num = 10 # 爬取数据数
top_time = "20220327" # 时间
top_type = "day" # 日期类型 day week month
url = f"https://top.news.sina.com.cn/ws/GetTopDataList.php?" \
f"top_type={top_type}&top_cat=www_www_all_suda_suda&top_time={top_time}" \
f"&top_show_num={top_show_num}&top_order=DESC"
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"}
response = requests.get(url, headers=dic)
response.encoding = response.apparent_encoding
# print(response.text)
# 截取多余元素
text = response.text.strip('var data=').split(";")[0]
print(text)
# json格式化 并获取data数据
json_data = json.loads(text)["data"]
print(json_data)
index = 0 # 序号
for item in json_data:
print(index, item['id'], item['title'], item['media'], item['url'], item['time'])
index += 1
# 所有json输出至json_data.json
output_to_file(json_data)
可以看到json数据的框架:
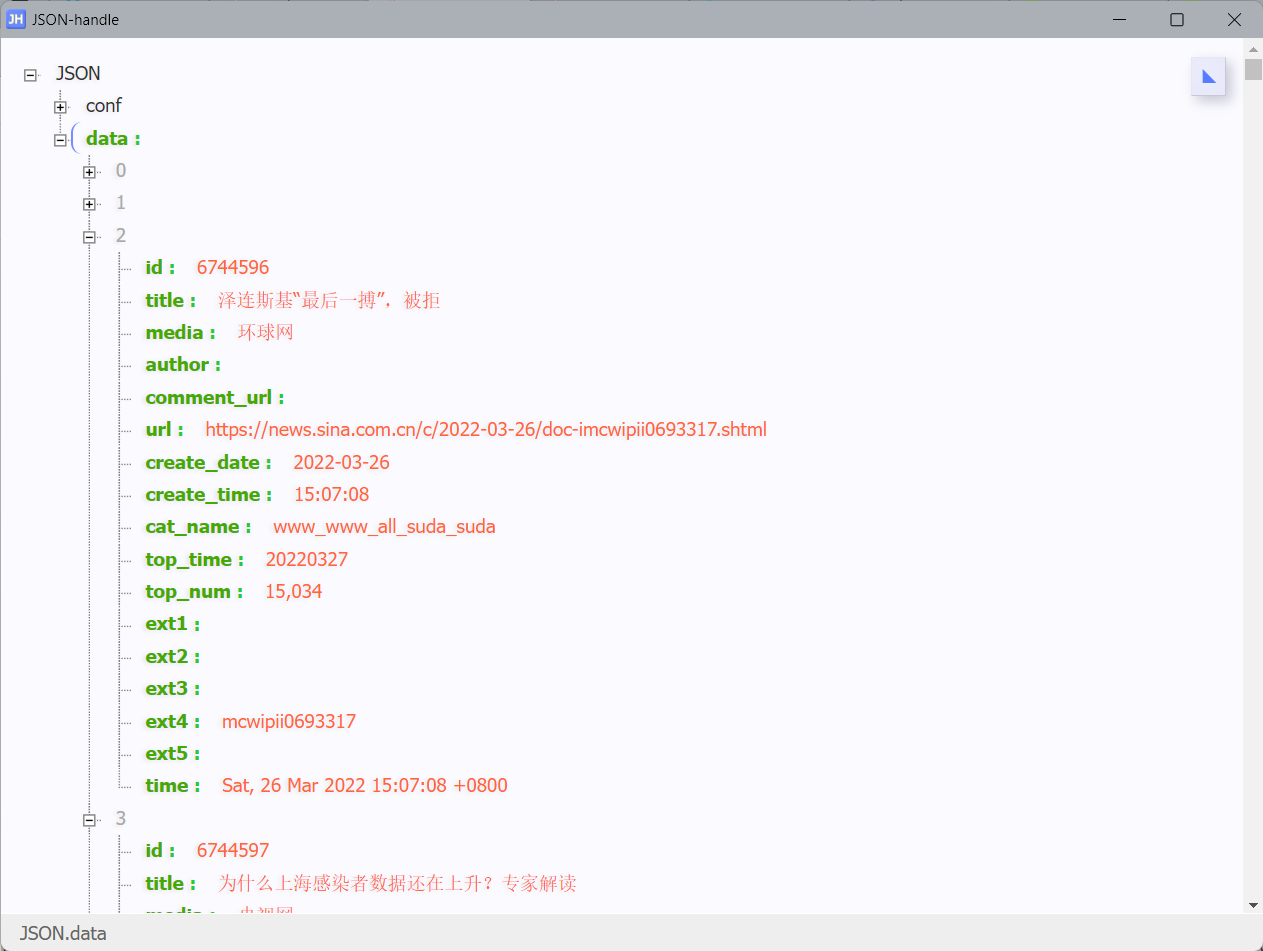
根据需要,对json_data提取相应数据就可以啦!
5. 参考链接
https://blog.csdn.net/hanchaobiao/article/details/73150405
https://www.runoob.com/python/att-string-strip.html
https://www.runoob.com/python/att-string-split.html
https://cloud.tencent.com/developer/article/1651280
