Kafka学习总结
一、为什么要使用Kafka
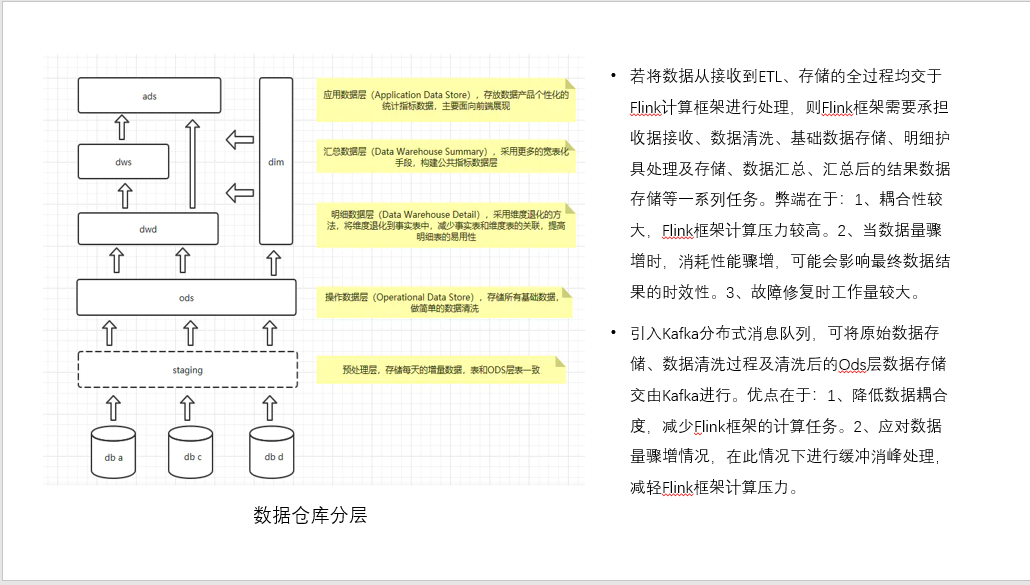
- 如果直接使用flink进行元数据接收、数据处理、元数据及处理后数据存储的整个过程,压力较大,且耦合性较高,故障修复需要将整个过程一起修复,故为了降低flink计算压力,降低元数据与计算过程之间的耦合度,考虑使用kafka组件与flink结合使用。
- 未经过ETL的数据大多较为冗余,且并非必须数据,这样的数据交由flink处理,消耗性能,为了使flink实时计算性能更好的发挥
二、Kafka的应用场景
- 消峰
- 解耦
- 异步通信
三、什么是Kafka
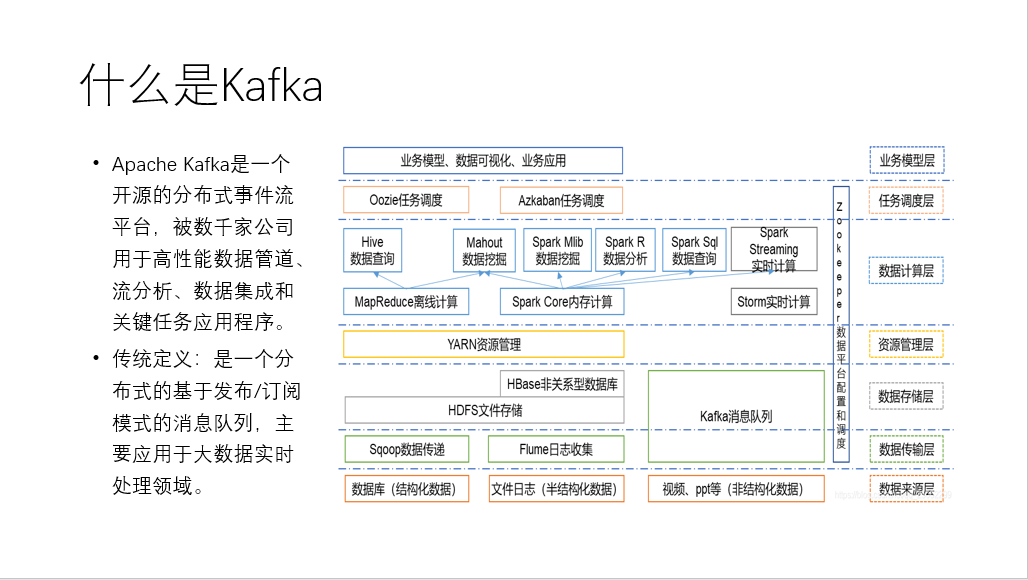
- Apache Kafka是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序。
- 传统定义:是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
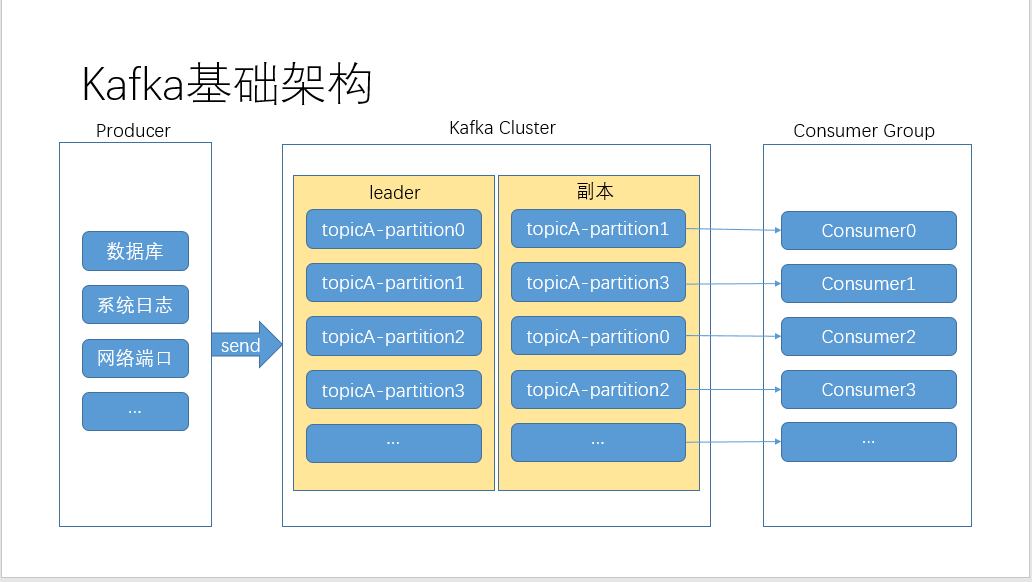
四、Kafka的基础架构
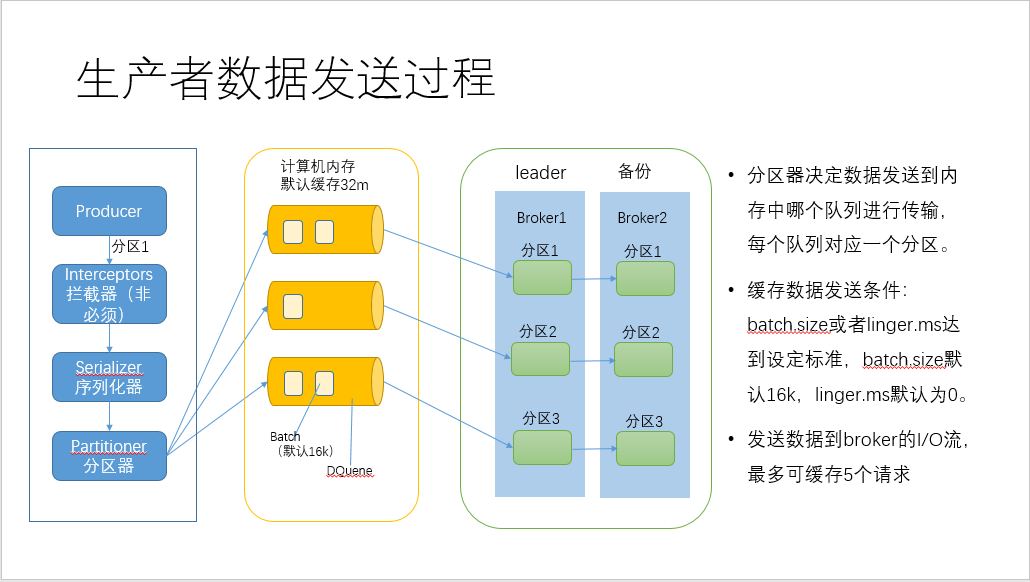
1、生产者
producer,send到拦截器,经过序列化,到分区器进行分区,默认缓存最大32m,默认每16k发送一个批次或者没0毫秒发送一批,即实时传输,来一条数据传输一条数据,默认压缩属性为不压缩;可通过调节各种参数设置来优化生产环境性能。
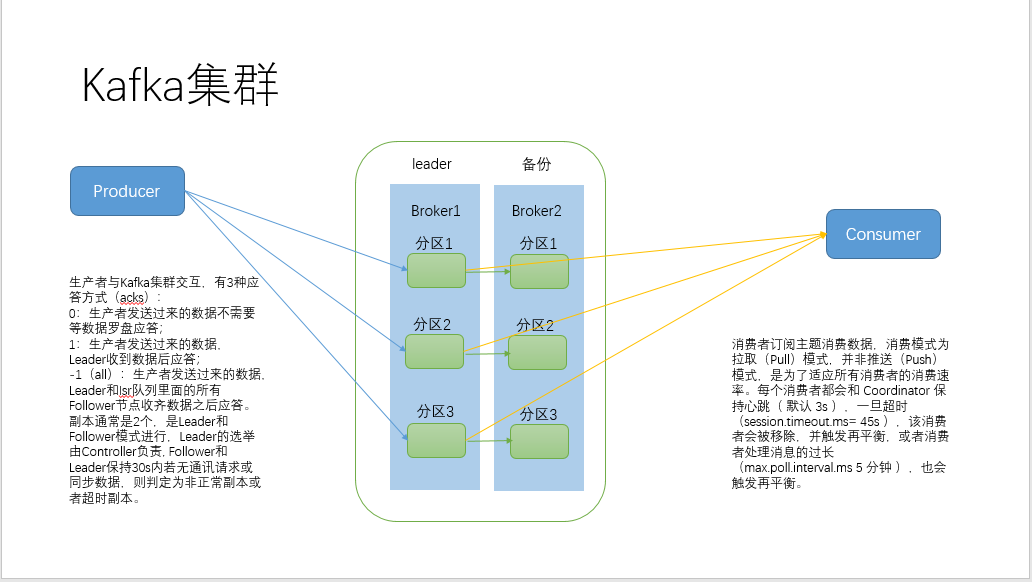
2、Broker分区
生产者通过sender线程将数据传输到broker的leader分区,交互有三种应答模式:0—生产者发送过来的数据,不需要等数据罗盘应答;1—生产者发送过来的护具,leader收到数据后应答;-1(all)--生产者发送过来的数据,leader收和isr队列里面的所有节点收齐数据后应答。副本数通常是2个,是leader和follower模式进行,leader的选举由controller负责,可以通过groupid的hashcode % 50(50为存储leader、follower信息topic的分区数)来决定leader是哪个分区,follower和leader保持30s内若无通讯请求或同步数据,则判定为非正常副本或者超时副本。
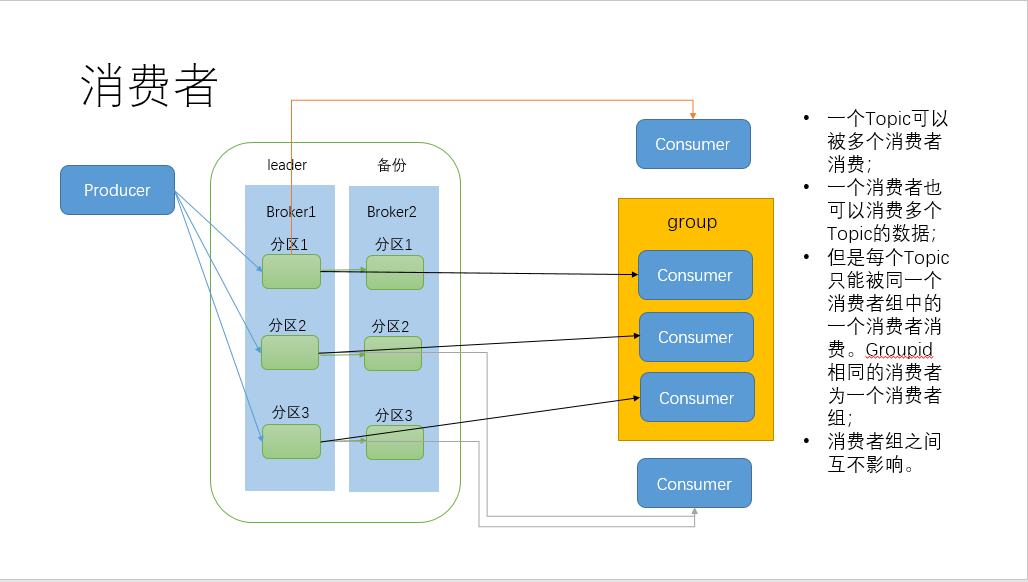
3、消费者
消费者订阅主题消费数据,消费模式为拉取(pull)模式,并非推送(push)模式,为了适应所有消费者的消费速率)。每个消费者都会和 coordinator 保持心跳( 默认 3s ),一旦超时(session.timeout.ms= 45s ),该消费者会被移除,并触发再平衡,或者消费者处理消息的过长(max.poll.interval.ms 5 分钟 ),也会触发再平衡。
五、特点
- 可进行精确一次的消费,避免数据漏消费和重复消费。生产端使用幂等方式传输,开启事务避免数据重复,(幂等性:就是指 Producer 不论向 Broker 发送多少次重复数据 Broker 端都只会持久化一条 保证了不重复 );broker集群:至少一次,ack= -1,分区副本数>=2,ISR 最小副本数量 2;消费者支持事务处理。
![image]()
![image]()
六、以下为本人整理PPT介绍,转载请注明出处




 浙公网安备 33010602011771号
浙公网安备 33010602011771号