分布式核心
1. CAP理论
cap理论是分布式系统的理论基石
Consistency (一致性):
“all nodes see the same data at the same time”,即更新操作成功并返回客户端后,所有节点在同一时间的数据完全一致,这就是分布式的一致性。一致性的问题在并发系统中不可避免,对于客户端来说,一致性指的是并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
Availability (可用性):
可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。
Partition Tolerance (分区容错性):
即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,对于用户而言并没有什么体验上的影响。
如果你你是一个分布式系统,那么你必须要满足一点:分区容错性
二、取舍策略
CAP三个特性只能满足其中两个,那么取舍的策略就共有三种:

CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。
CP without A:如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。典型的应用就如某米的抢购手机场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。
2. Base理论
分布式系统中的一致性是 弱一致性 单数据库 mysql的一致性 强一致性
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。BASE理论是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结, 是基于CAP定理逐步演化而来的。BASE理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。接下来看一下BASE中的三要素:
1、基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性—-注意,这绝不等价于系统不可用。比如:
(1)响应时间上的损失。正常情况下,一个在线搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障,查询结果的响应时间增加了1~2秒
(2)系统功能上的损失:正常情况下,在一个电子商务网站上进行购物的时候,消费者几乎能够顺利完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面
2、软状态
软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时
3、最终一致性
最终一致性强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统的事物ACID特性是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性和BASE理论往往又会结合在一起。
分布式事务
1. 两/三阶段提交
●两阶段提交(2PC, Two-phase Commit)
●TCC 补偿模式
●基于本地消息表实现最终一致性
●最大努力通知
●基于可靠消息最终一致性方案
两阶段提交又称2PC,2PC是一个非常经典的中心化的原子提交协议。
这里所说的中心化是指协议中有两类节点:一个是中心化协调者节点(coordinator)和N个参与者节点(partcipant)。
两个阶段:第一阶段:投票阶段 和第二阶段:提交/执行阶段。
举例 订单服务A,需要调用 支付服务B 去支付,支付成功则处理购物订单为待发货状态,否则就需要将购物订单处理为失败状态。
那么看2PC阶段是如何处理的
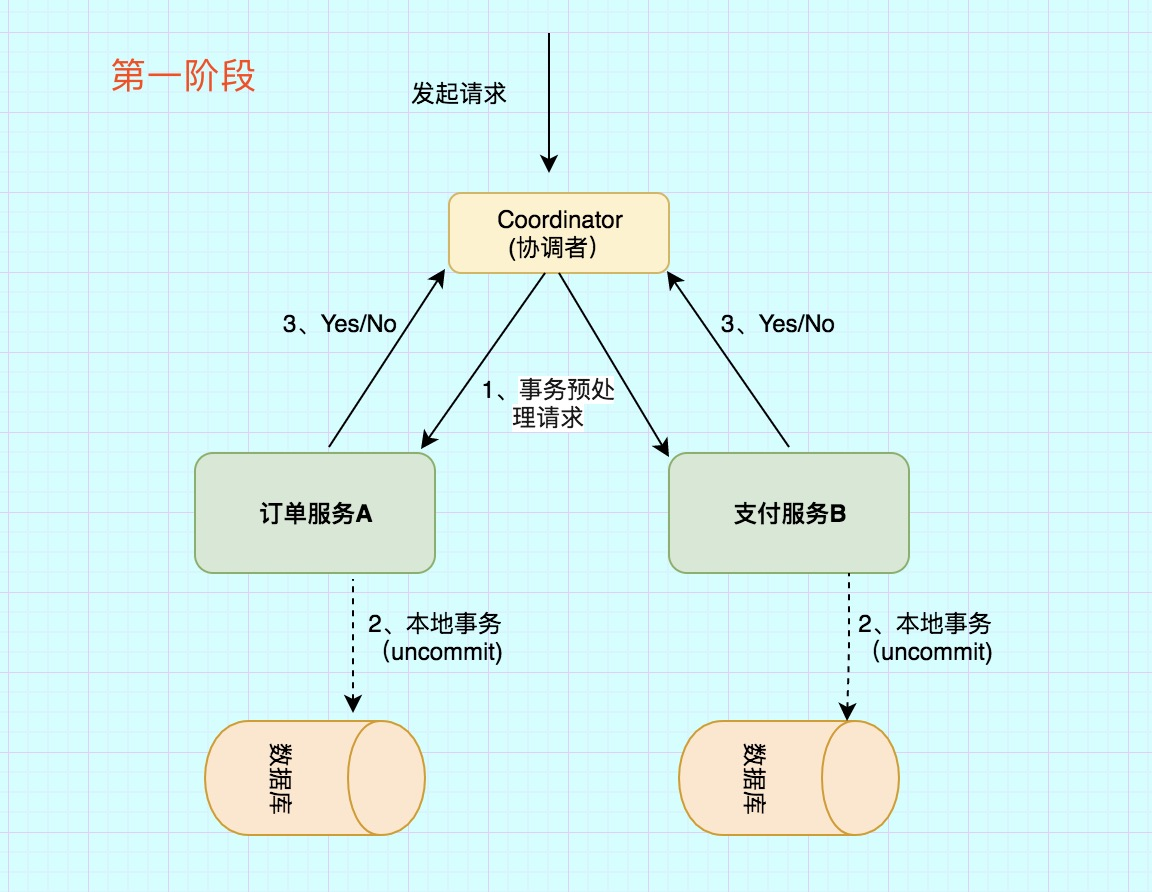
第一阶段主要分为3步
1)事务询问
协调者 向所有的 参与者 发送事务预处理请求,称之为Prepare,并开始等待各 参与者 的响应。
2)执行本地事务
各个 参与者 节点执行本地事务操作,但在执行完成后并不会真正提交数据库本地事务,而是先向 协调者 报告说:“我这边可以处理了/我这边不能处理”。.
3)各参与者向协调者反馈事务询问的响应
如果 参与者 成功执行了事务操作,那么就反馈给协调者 Yes 响应,表示事务可以执行,如果没有 参与者 成功执行事务,那么就反馈给协调者 No 响应,表示事务不可以执行。
第一阶段执行完后,会有两种可能。1、所有都返回Yes. 2、有一个或者多个返回No。
成功条件:所有参与者都返回Yes。
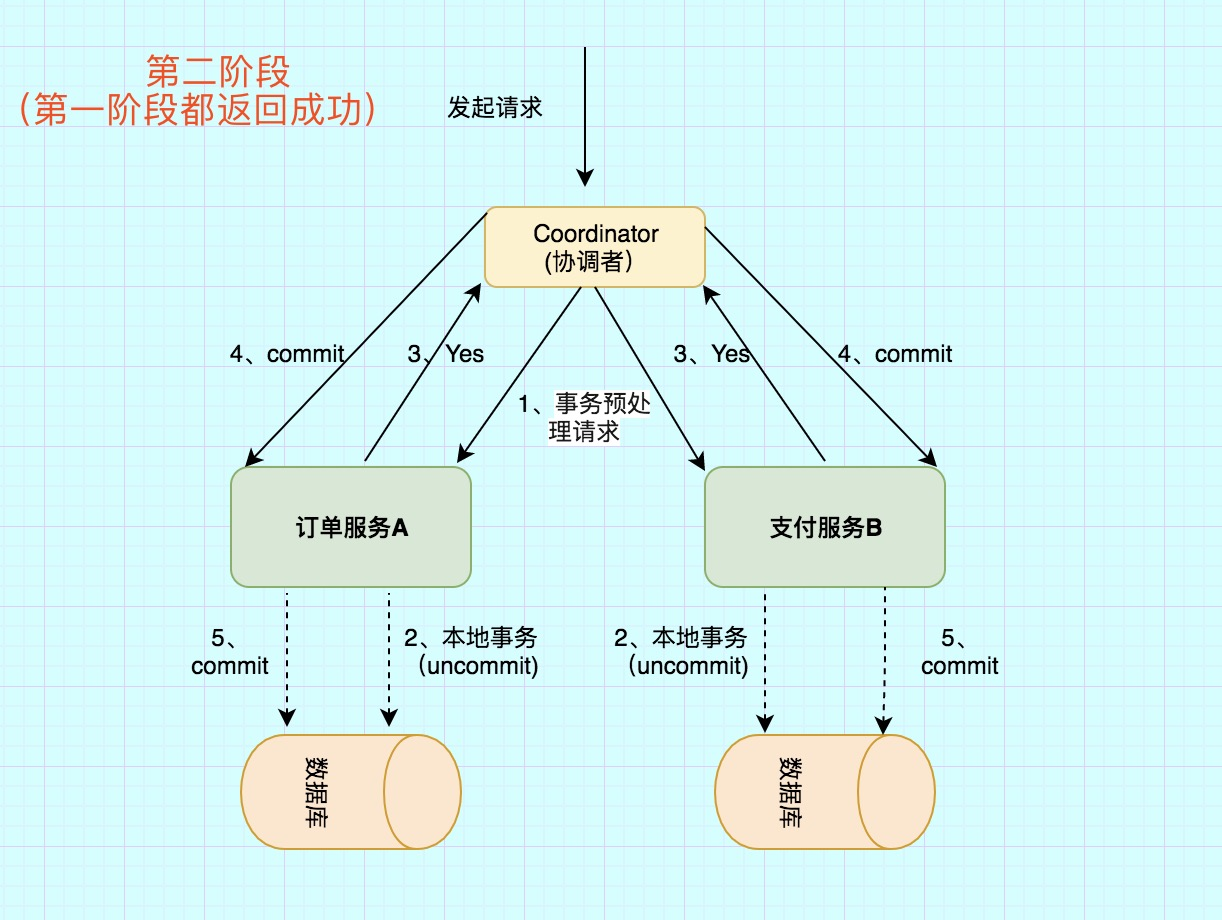
第二阶段主要分为两步
1)所有的参与者反馈给协调者的信息都是Yes,那么就会执行事务提交
协调者 向 所有参与者 节点发出Commit请求.
2)事务提交
参与者 收到Commit请求之后,就会正式执行本地事务Commit操作,并在完成提交之后释放整个事务执行期间占用的事务资源。
异常条件:任何一个 参与者 向 协调者 反馈了 No 响应,或者等待超时之后,协调者尚未收到所有参与者的反馈响应。

异常流程第二阶段也分为两步
1)发送回滚请求
协调者 向所有参与者节点发出 RoollBack 请求.
2)事务回滚
参与者 接收到RoollBack请求后,会回滚本地事务。
通过上面的演示,很容易想到2pc所带来的缺陷
1)性能问题
无论是在第一阶段的过程中,还是在第二阶段,所有的参与者资源和协调者资源都是被锁住的,只有当所有节点准备完毕,事务 协调者 才会通知进行全局提交,
参与者 进行本地事务提交后才会释放资源。这样的过程会比较漫长,对性能影响比较大。
2)单节点故障
由于协调者的重要性,一旦 协调者 发生故障。参与者 会一直阻塞下去。尤其在第二阶段,协调者 发生故障,那么所有的 参与者 还都处于
锁定事务资源的状态中,而无法继续完成事务操作。(虽然协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
2PC出现单点问题的三种情况
(1)协调者正常,参与者宕机
由于 协调者 无法收集到所有 参与者 的反馈,会陷入阻塞情况。
解决方案:引入超时机制,如果协调者在超过指定的时间还没有收到参与者的反馈,事务就失败,向所有节点发送终止事务请求。
(2)协调者宕机,参与者正常
无论处于哪个阶段,由于协调者宕机,无法发送提交请求,所有处于执行了操作但是未提交状态的参与者都会陷入阻塞情况.
解决方案:引入协调者备份,同时协调者需记录操作日志.当检测到协调者宕机一段时间后,协调者备份取代协调者,并读取操作日志,向所有参与者询问状态。
(3)协调者和参与者都宕机
1发生在第一阶段: 因为第一阶段,所有参与者都没有真正执行commit,所以只需重新在剩余的参与者中重新选出一个协调者,新的协调者在重新执行第一阶段和第二阶段就可以了。
2)发生在第二阶段 并且 挂了的参与者在挂掉之前没有收到协调者的指令。也就是上面的第4步挂了,这是可能协调者还没有发送第4步就挂了。这种情形下,新的协调者重新执行第一阶段和第二阶段操作。
3)发生在第二阶段 并且 有部分参与者已经执行完commit操作。就好比这里订单服务A和支付服务B都收到协调者 发送的commit信息,开始真正执行本地事务commit,但突发情况,Acommit成功,B确挂了。这个时候目前来讲数据是不一致的。虽然这个时候可以再通过手段让他和协调者通信,再想办法把数据搞成一致的,但是,这段时间内他的数据状态已经是不一致的了! 2PC 无法解决这个问题。
2. TCC
总结一下,你要玩儿TCC分布式事务的话:
- 首先需要选择某种TCC分布式事务框架,各个服务里就会有这个TCC分布式事务框架在运行。
- 然后你原本的一个接口,要改造为3个逻辑,Try-Confirm-Cancel。
- 先是服务调用链路依次执行Try逻辑
- 如果都正常的话,TCC分布式事务框架推进执行Confirm逻辑,完成整个事务
- 如果某个服务的Try逻辑有问题,TCC分布式事务框架感知到之后就会推进执行各个服务的Cancel逻辑,撤销之前执行的各种操作。
- 这就是所谓的TCC分布式事务。
- TCC分布式事务的核心思想,说白了,就是当遇到下面这些情况时,
- 某个服务的数据库宕机了
- 某个服务自己挂了
- 那个服务的redis、elasticsearch、MQ等基础设施故障了
- 某些资源不足了,比如说库存不够这些
- 先来Try一下,不要把业务逻辑完成,先试试看,看各个服务能不能基本正常运转,能不能先冻结我需要的资源。
- 如果Try都ok,也就是说,底层的数据库、redis、elasticsearch、MQ都是可以写入数据的,并且你保留好了需要使用的一些资源(比如冻结了一部分库存)。
- 接着,再执行各个服务的Confirm逻辑,基本上Confirm就可以很大概率保证一个分布式事务的完成了。
- 那如果Try阶段某个服务就失败了,比如说底层的数据库挂了,或者redis挂了,等等。
- 此时就自动执行各个服务的Cancel逻辑,把之前的Try逻辑都回滚,所有服务都不要执行任何设计的业务逻辑。保证大家要么一起成功,要么一起失败。
终极大招
- 如果有一些意外的情况发生了,比如说订单服务突然挂了,然后再次重启,TCC分布式事务框架是如何保证之前没执行完的分布式事务继续执行的呢?
- TCC事务框架都是要记录一些分布式事务的活动日志的,可以在磁盘上的日志文件里记录,也可以在数据库里记录。保存下来分布式事务运行的各个阶段和状态。
- 万一某个服务的Cancel或者Confirm逻辑执行一直失败怎么办呢?
- 那也很简单,TCC事务框架会通过活动日志记录各个服务的状态。
- 举个例子,比如发现某个服务的Cancel或者Confirm一直没成功,会不停的重试调用他的Cancel或者Confirm逻辑,务必要他成功!
- 当然了,如果你的代码没有写什么bug,有充足的测试,而且Try阶段都基本尝试了一下,那么其实一般Confirm、Cancel都是可以成功的!
- 如果实在解决不了,那么这个一定是很小概率的事件,这个时候发邮件通知人工处理
TCC优缺点
优点:
1.解决了跨服务的业务操作原子性问题,例如组合支付,订单减库存等场景非常实用
2.TCC的本质原理是把数据库的二阶段提交上升到微服务来实现,从而避免了数据库2阶段中锁冲突的长事务低性能风险。
3.TCC异步高性能,它采用了try先检查,然后异步实现confirm,真正提交的是在confirm方法中。
缺点:
1.对微服务的侵入性强,微服务的每个事务都必须实现try,confirm,cancel等3个方法,开发成本高,今后维护改造的成本也高。
2.为了达到事务的一致性要求,try,confirm、cancel接口必须实现等幂性操作。
(定时器+重试)
3.由于事务管理器要记录事务日志,必定会损耗一定的性能,并使得整个TCC事务时间拉长,建议采用redis的方式来记录事务日志。
4. tcc需要通过锁来确保数据的一致性,会加锁导致性能不高
3. 基于本地消息表的最终一致性
通过本地事务保证数据业务操作和消息的一致性,然后通过定时任务将消息发送至消息中间件,待确认消息发送给消费方成功再将消息删除。但是如图方案如何解决网络抖动?

增加本地消息表记录日志,cron job扫描日志如果发现消息没有成功返回就retry
消费者完成后发送ack(消息确认),删除日志

消息会重复发送,应该实现幂等:Idempotence

There are bottlenecks in the throughput and performance of relational databases, and frequent reading and writing of messages will put pressure on the database.
4. 基于可靠消息的最终一致性- 最常用
能保证本地事务,若因网络uncommitted,有定时回查(schehduled transaction review),保证本地事务执行完后能commit

-
The Producer sends the half message to the
RocketMQ Broker. -
After the
RocketMQ Brokerpersists the message successfully, it returns an Ack to the Producer confirming that the message was sent successfully and it is a half message. -
The Producer starts executing the local transaction.
-
The Producer submits a second acknowledgement (Commit or Rollback) to the server based on the result of the local transaction, and the server receives the acknowledgment and processes the logic as follows.
- If the second acknowledgement result is Commit: the server marks the half message as deliverable and delivers it to the Consumer.
- If the second acknowledgement result is Rollback: the server will rollback the transaction and will not deliver the half message to the Consumer.
-
In the special case of network disconnection or the Producer restarts, if the server does not receive the second acknowledgment result from the Producer, or the second acknowledgment result received by the server is Unknown, the server will initiate a transaction status check to a Producer after a fixed time.
The procedure of the transaction status check are as follows.
- After receiving the transaction status check request, the Producer needs to verify the final result of the local transaction of the corresponding message.
- The producer submits the second acknowledgment again based on the final result of the local transaction, and the server side will still processes the half message according to step 4.
5. 最大努力通知
1. 支付:异步mq -> notification system
2. 通知:通知商户,最大努力的通知商户,第一次比如1s,2s,5s,10s,最多20s后retry
3. 给商户提供查询接口(防止没有通知到位)

What is the difference between best effort notification and reliable message consistency?
1. Different solution ideas
Reliable message consistency. The initiating notification party needs to ensure that the message is sent out and sent to the receiving notification party. The key to the reliability of the message is guaranteed by the notification sender.
Best effort notification, the party initiating the notification tries its best to notify the receiving party of the business processing results, but the message may not be received. In this case, the receiving party needs to actively call the interface of the initiating party to query the business processing results and the reliability of the notification. The key is on receiver.
2. The business application scenarios of the two are different.
Reliable message consistency focuses on the transaction consistency of the transaction process and completes the transaction in an asynchronous manner.
Best effort notification focuses on post-transaction notification matters, that is, reliably notifying transaction results.
3. Different technical solution directions
Reliable message consistency requires the consistency of messages from sending to receiving.
Best-effort notification cannot guarantee the consistency of messages from sending to receiving, but only provides a reliability mechanism for message reception. The reliable mechanism is to try its best to notify the receiver of the message. When the message cannot be received by the receiver, the receiver takes the initiative to query the message (business processing result).
方案1: 采用MQ的ack机制

本方案是利用MQ的ack机制由MQ向接收通知方发送通知,流程如下:
1、发起通知方将通知发给MQ。使用普通消息机制将通知发给MQ。
注意:如果消息没有发出去可由接收通知方主动请求发起通知方查询业务执行结果。(后边会讲)
2、接收通知方监听 MQ。
3、接收通知方接收消息,业务处理完成回应ack。
4、接收通知方若没有回应ack则MQ会重复通知。
MQ会按照间隔1min、5min、10min、30min、1h、2h、5h、10h的方式,逐步拉大通知间隔 (如果MQ采用rocketMq,在broker中可进行配置),直到达到通知要求的时间窗口上限。
5、接收通知方可通过消息校对接口来校对消息的一致性。

交互流程如下:
1、发起通知方将通知发给MQ。
使用可靠消息一致方案中的事务消息保证本地事务与消息的原子性,最终将通知先发给MQ。
2、通知程序监听 MQ,接收MQ的消息。
方案1中接收通知方直接监听MQ,方案2中由通知程序监听MQ。
通知程序若没有回应ack则MQ会重复通知。
3、通知程序通过互联网接口协议(如http、webservice)调用接收通知方案接口,完成通知。
通知程序调用接收通知方案接口成功就表示通知成功,即消费MQ消息成功,MQ将不再向通知程序投递通知消息。
4、接收通知方可通过消息校对接口来校对消息的一致性。
方案1和方案2的不同点:
1、方案1中接收通知方与MQ接口,即接收通知方案监听 MQ,此方案主要应用与内部应用之间的通知。
2、方案2中由通知程序与MQ接口,通知程序监听MQ,收到MQ的消息后由通知程序通过互联网接口协议调用接收通知方。此方案主要应用于外部应用之间的通知,例如支付宝、微信的支付结果通知。
MQ
adv:
1. system decoupling, enhance fault tolerance
2. peak traffic clipping
3. data distribution
4. dont need to change the interface for motifications of new system
disadv:
- 系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。
如何保证MQ的高可用? - 系统复杂度提高
MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。
如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性? - 一致性问题 (分布式事务问题)
A系统处理完业务,通过MQ给B、C、D三个系统发消息数据,如果B系统、C系统处理成功,D系统处理失败。
如何保证消息数据处理的一致性?
RocketMQ
- 延迟消息简单高效
- 死信队列
- 完善的事务消息功能
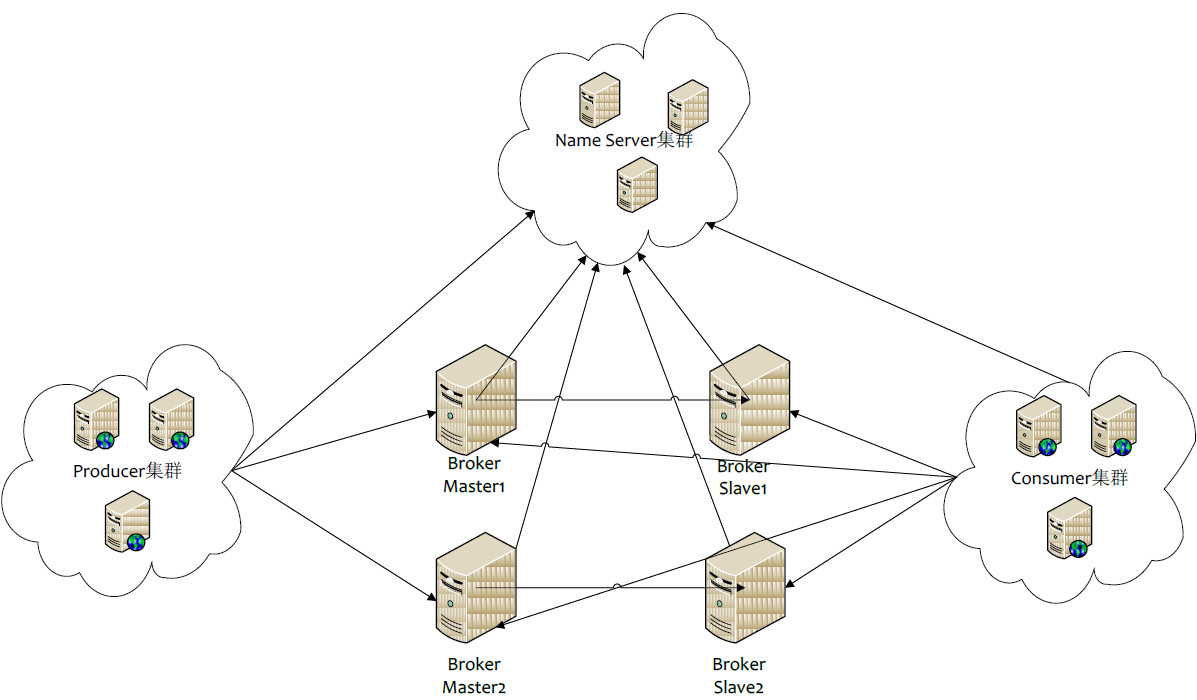
- Producer:消息的发送者;举例:发信者
- Consumer:消息接收者;举例:收信者
- Broker:暂存和传输消息;举例:邮局
- NameServer:管理Broker;举例:各个邮局的管理机构
- Topic:区分消息的种类;一个发送者可以发送消息给一个或者多个Topic;一个消息的接收者可以订阅一个或者多个Topic消息
- Message Queue:相当于是Topic的分区;用于并行发送和接收消息
分布式锁
1. 使用 mutual exclusive lock: release after commit
var l sync.Mutex // reduce inventory // 本地事务保证 input[1:5, 2:10, 3:20]全部执行,不能保证多线程下数据一致 func (s *StocksServer) Sell(c context.Context, sell *proto.SellInfo) (*emptypb.Empty, error) { tx := global.DB.Begin() // start local transaction l.Lock() for _, g := range sell.GoodsInvInfo { var inv model.Inventory if result := global.DB.Where(&model.Inventory{Goods: g.GoodsId}).First(&inv); result.RowsAffected == 0 { tx.Rollback() // rollback return nil, status.Errorf(codes.InvalidArgument, "inventory not found") } if inv.Stocks < g.Num { tx.Rollback() // rollback return nil, status.Errorf(codes.ResourceExhausted, "inventory not enough") } inv.Stocks -= g.Num // 数据一致要靠分布式锁 tx.Save(&inv) } tx.Commit() // commit l.Unlock() return &emptypb.Empty{}, nil }
问题:can only lock goroutines on one server -> not distributed!!!

solution:distributed lock
同一个数据库:pessimistic lock

1. for update #mysql pessimistic lock#
set autocommit = 0 当前窗口有效

goods是index,所以 for update 是 row lock
如果 where stocks = 101 => table lock
如果remove for update 重新运行,成功 => 不影响read
1.1 Gorm for update
只需在查询的时候把db换成 tx.Clauses(clause.Locking{Strength: "UPDATE"}).
2. optimistic lock #add version#

开启10个goroutine秒杀1件库存
要求:1个goroutine成功,9个失败,最后0个库存
=> GORM 如何设置zero value?updates前select: Select("stocks", "verson").
func (s *StocksServer) Sell(c context.Context, sell *proto.SellInfo) (*emptypb.Empty, error) { tx := global.DB.Begin() // start local transaction for _, g := range sell.GoodsInvInfo { var inv model.Inventory for { // retry if result := global.DB. Where(&model.Inventory{Goods: g.GoodsId}).First(&inv); result.RowsAffected == 0 { tx.Rollback() // rollback return nil, status.Errorf(codes.InvalidArgument, "inventory not found") } if inv.Stocks < g.Num { tx.Rollback() // rollback return nil, status.Errorf(codes.ResourceExhausted, "inventory not enough") } //inv.Stocks -= g.Num // 数据一致要靠分布式锁 // upate inventory where goods = inv.goodid, version = inv.version set stocks = inv.Stocks- g.num and version = inv.version+1 if result := global.DB.Model(&model.Inventory{}).Select("stocks", "verson"). Where("goods = ? and verson = ?", inv.Goods, inv.Verson). Updates(model.Inventory{Stocks: inv.Stocks - g.Num, Verson: inv.Verson + 1}); result.RowsAffected == 0 { zap.S().Info("reducing stocks failed") // fail -> retry } else { break } } } tx.Commit() // commit return &emptypb.Empty{}, nil }
3. redis lock: redsync
package main import ( "fmt" goredislib "github.com/go-redis/redis/v8" "github.com/go-redsync/redsync/v4" "github.com/go-redsync/redsync/v4/redis/goredis/v8" "sync" "time" ) func main() { // Create a pool with go-redis (or redigo) which is the pool redisync will // use while communicating with Redis. This can also be any pool that // implements the `redis.Pool` interface. client := goredislib.NewClient(&goredislib.Options{ Addr: "192.168.2.112:6379", }) pool := goredis.NewPool(client) // or, pool := redigo.NewPool(...) // Create an instance of redisync to be used to obtain a mutual exclusion // lock. rs := redsync.New(pool) mutexname := "421" var gnum = 10 var wg sync.WaitGroup wg.Add(gnum) for i := 0; i < gnum; i++ { go func() { defer wg.Done() // Obtain a new mutex by using the same name for all instances wanting the // same lock. mutex := rs.NewMutex(mutexname) fmt.Println("start getting lock") if err := mutex.Lock(); err != nil { panic(err) } fmt.Println("get the lock") time.Sleep(time.Second) if ok, err := mutex.Unlock(); !ok || err != nil { panic("unlock failed") } fmt.Println("unlock") }() } wg.Wait() // Obtain a lock for our given mutex. After this is successful, no one else // can obtain the same lock (the same mutex name) until we unlock it. // Do your work that requires the lock. // Release the lock so other processes or threads can obtain a lock. }
result:

错误原因:redis lock默认8s过期,可根据业务修改源码
集成业务:每个goroutine都要执行:421 422 423 goods 分别sell 10 个
一个goroutine在执行A goods操作的时候,允许另一个goroutine对B goods 操作
func (s *StocksServer) Sell(c context.Context, sell *proto.SellInfo) (*emptypb.Empty, error) { tx := global.DB.Begin() // start local transaction for _, g := range sell.GoodsInvInfo { var inv model.Inventory mutex := global.Redsync.NewMutex(fmt.Sprintf("goods_%d", g.GoodsId)) if err := mutex.Lock(); err != nil { return nil, status.Errorf(codes.Internal, "redsync lock error") } if result := global.DB. Where(&model.Inventory{Goods: g.GoodsId}).First(&inv); result.RowsAffected == 0 { tx.Rollback() // rollback return nil, status.Errorf(codes.InvalidArgument, "inventory not found") } if inv.Stocks < g.Num { tx.Rollback() // rollback return nil, status.Errorf(codes.ResourceExhausted, "inventory not enough") } inv.Stocks -= g.Num // 数据一致要靠分布式锁 tx.Save(&inv) if ok, err := mutex.Unlock(); !ok || err != nil { return nil, status.Errorf(codes.Internal, "redsync unlock error") } // upate inventory where goods = inv.goodid, version = inv.version set stocks = inv.Stocks- g.num and version = inv.version+1 //if result := global.DB.Model(&model.Inventory{}).Select("stocks", "verson"). // Where("goods = ? and verson = ?", inv.Goods, inv.Verson). // Updates(model.Inventory{Stocks: inv.Stocks - g.Num, Verson: inv.Verson + 1}); result.RowsAffected == 0 { // zap.S().Info("reducing stocks failed") //} else { // break //} } tx.Commit() // commit return &emptypb.Empty{}, nil }
3.2 redsync 原理
1.setnx:SET if Not eXists - atomic operation

redsync源码解读
- setnx的作用: 将获取和设置值变成原子性的操作 (这个命令表示SET if Not eXists,即如果 key 不存在,才会设置它的值,否则什么也不做。)
两个客户端进程可以执行这个命令,达到互斥,就可以实现一个分布式锁。
客户端 1 申请加锁,加锁成功: SETNX lock 1
-
如果我的服务挂掉了- 死锁
- 设置过期时间: atomic operation after Redis 2.6.12: SET lock 1 EX 10 NX
- 如果你设置了过期时间,那么如果过期时间到了我的业务逻辑没有执行完怎么办?
- 在过期之前刷新一下 Extend()
- 需要manually去启动协程完成延时的工作
- 如果auto,子延时的接口可能会带来负面影响 - 如果其中某一个服务hung住了, 2s就能执行完,但是你hung住那么你就会一直去申请延长锁,导致别人永远获取不到锁,这个很要命
-
分布锁需要解决的问题 - lua脚本去做
- 互斥性 - setnx
- 死锁
- 安全性
- 锁只能被持有该锁的用户删除,不能被其他用户删除(server A lock过期还没执行完操作,server B 拿到lock执行完后不能release)
- 当时设置的value值是多少只有当时的g才能知道 (generateFunc)
- 在删除的时取出redis中的值和当前自己保存下来的值对比一下
- 锁只能被持有该锁的用户删除,不能被其他用户删除(server A lock过期还没执行完操作,server B 拿到lock执行完后不能release)
-
即使你这样实现了分布式但是还是会有问题 - redlock
- 问题:srv1 use `setnx` to lock A, master not yet sync to slaves, master fail => src2 request A, A not locked
- 解决:(redlock)在5台(odd)master上异步发送setnx请求,超过半数就拿到锁。(quorum变量)
- 问题:客户端存在clock drift, 如何计算TTL
-
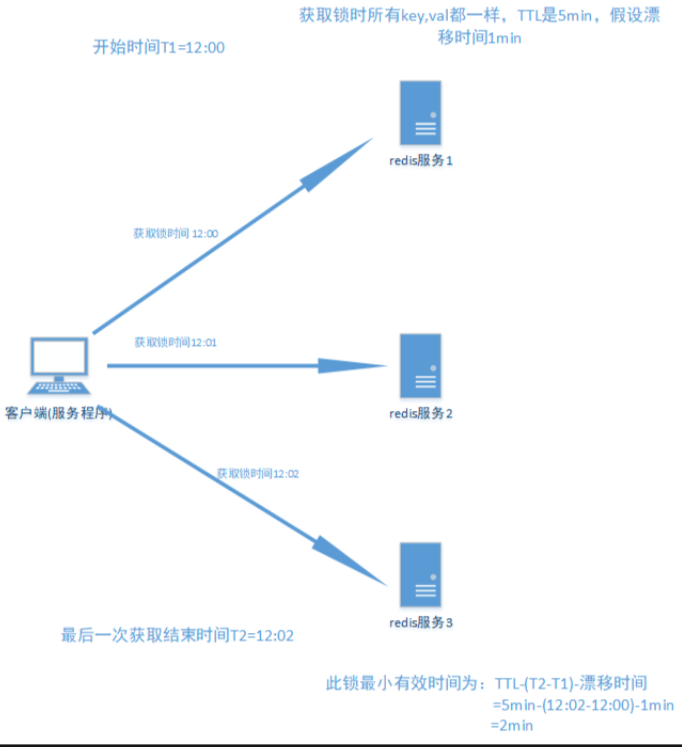
RedLock失败重试
当client不能获取锁时,应该在随机时间后重试获取锁;并且最好在同一时刻并发的把set命令发送给所有redis实例;而且对于已经获取锁的client在完成任务后要及时释放锁,这是为了节省时间;
RedLock释放锁
由于释放锁时会判断这个锁的value是不是自己设置的,如果是才删除;所以在释放锁时非常简单,只要向所有实例都发出释放锁的命令,不用考虑能否成功释放锁
clock drift会导致什么?
server1去拿锁A,redis clock is ahead of the server1, 导致server1刚拿到锁,还没执行就过期,这个时候server2拿到了锁。多个server同时持有锁
计算TTL时加入factor,来offset clock drift的影响
总结:
1.TTL时长 要大于正常业务执行的时间+获取所有redis服务消耗时间+时钟漂移
2.获取redis所有服务消耗时间要 远小于TTL时间,并且获取成功的锁个数要 在总数的一半以上:N/2+1
3.尝试获取所有锁失败后 重新尝试一定要有一定次数限制
4.A获得锁,redis崩溃(无论一个还是所有),要延迟TTL时间再重启redis(使用AOF持久到磁盘per second,并等待TTL时间重启,防止B获得锁,影响mutual exclusive,即同时两个server拥有锁)
Transaction Example based on reliable message
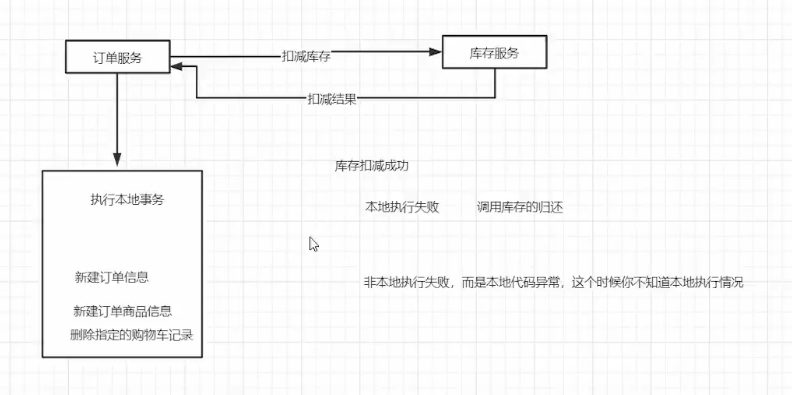
first reduce the inventory success
1. local order transaction fails -> return back the inventory fails
(disk is full, service fail; network problem
- retry: but network jitter and block
- set timeout
- avoid duplicate invoking (idempotence)
)
2. local code exception -> state: unknown

first execute local transaction
1. inventory success but return fail -> local fail (network block -> retry times reach the upper limit)
or network block after sending the request
TCC: java seata -> go seata tcc but not support grpc -> 自研成本大 -> reliable msg

reliable msg problem: need to ensure consumer must complete the transaction!!!
-> Credits service: ok;
Inventory service: stocks have limit!!!
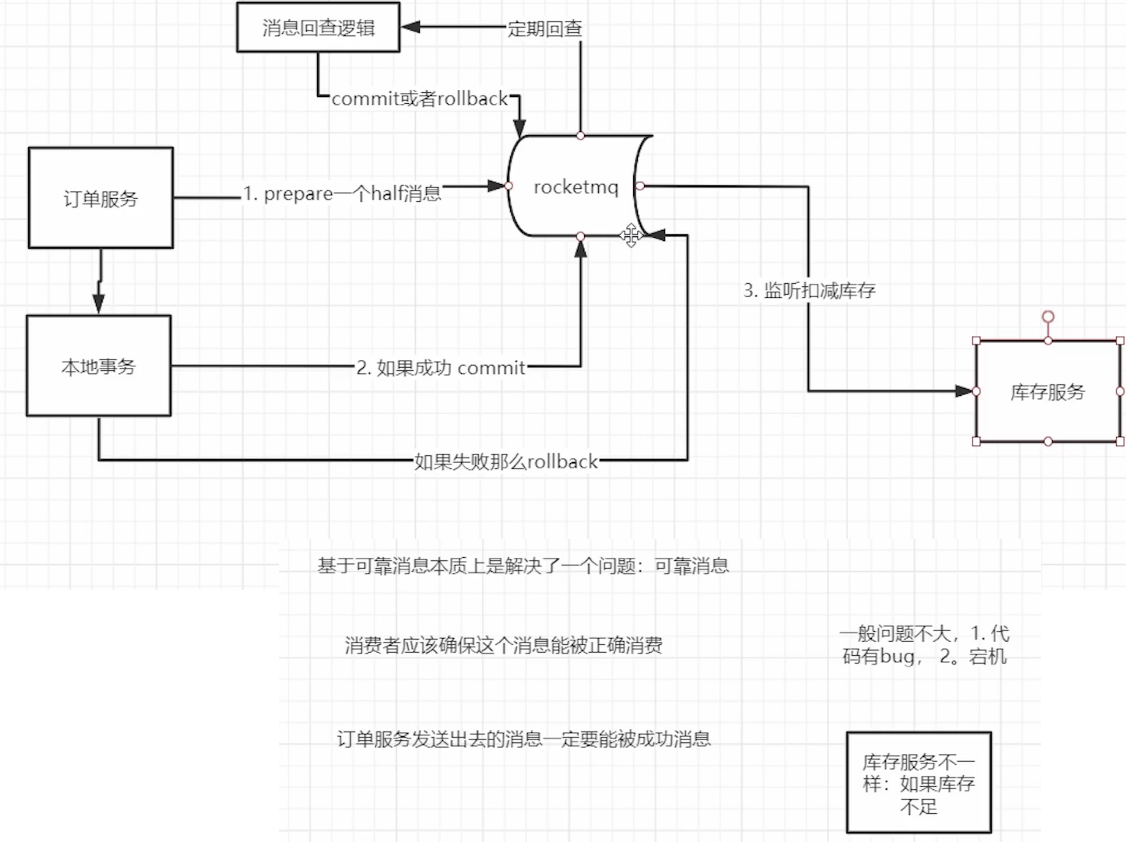
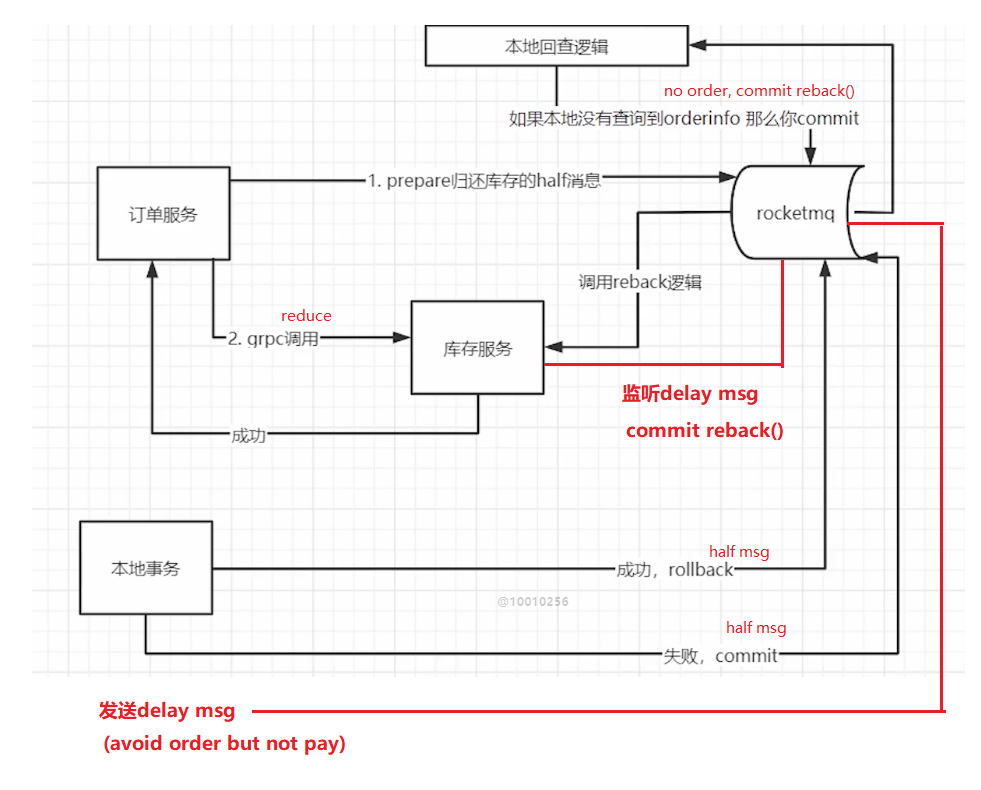
improvement:
first send half returnBack() msg + execute reduce() -> local transaction -> returnBack() commit or rollback
delay msg to act as timeout functionality
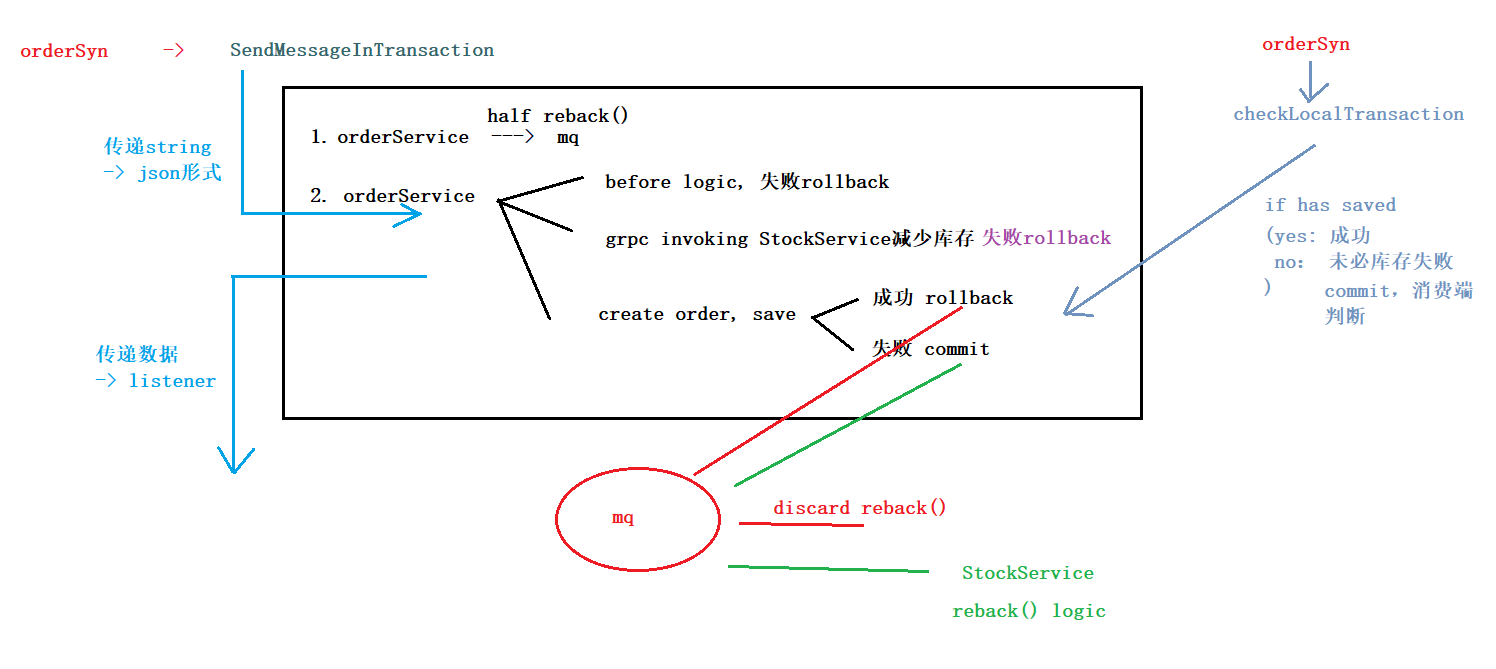
OrderService:
func (o *OrderListener) ExecuteLocalTransaction(msg *primitive.Message) primitive.LocalTransactionState { fmt.Printf("执行本地逻辑\n") order := model.OrderInfo{} _ = json.Unmarshal(msg.Body, &order) // 1. get good_ids var carts []model.ShoppingCart var cartMap = make(map[int32]int32) if result := global.DB.Where(&model.ShoppingCart{User: order.User, Checked: true}).Find(&carts); result.RowsAffected == 0 { o.Code = codes.InvalidArgument o.Detail = "no checked items!" return primitive.RollbackMessageState } var good_ids []int32 for _, cart := range carts { good_ids = append(good_ids, cart.Goods) cartMap[cart.Goods] = cart.Nums } // 2. Calling microservices across servers: good_ids -> goodsInfo -> generate ordergoods GoodsListResponse, err := global.GoodsClient.BatchGetGoods(context.Background(), &proto.BatchGoodsIdInfo{ Id: good_ids, }) if err != nil { o.Code = codes.Internal o.Detail = "invoking Goods-Service fails" return primitive.RollbackMessageState } // insert in batch var orderGoods []*model.OrderGoods var price float32 var goodsInvInfo []*proto.GoodsInvInfo for _, goods := range GoodsListResponse.Data { price += goods.ShopPrice * float32(cartMap[goods.Id]) orderGoods = append(orderGoods, &model.OrderGoods{ Goods: goods.Id, GoodsName: goods.Name, GoodsImage: goods.GoodsFrontImage, GoodsPrice: goods.ShopPrice, Nums: cartMap[goods.Id], }) goodsInvInfo = append(goodsInvInfo, &proto.GoodsInvInfo{ GoodsId: goods.Id, Num: cartMap[goods.Id], }) } // 3. reduce inventory if _, err = global.StocksClient.Sell(context.Background(), &proto.SellInfo{GoodsInvInfo: goodsInvInfo}); err != nil { // identify if it is network problem, if code is not xxx -> internet problem // ??? o.Code = codes.ResourceExhausted o.Detail = "reducing stocks fail" return primitive.RollbackMessageState } // 4. order tx := global.DB.Begin() order.OrderMount = price if result := tx.Save(&order); result.RowsAffected == 0 { tx.Rollback() o.Code = codes.Internal o.Detail = "invoking Save fails" return primitive.CommitMessageState } o.OrderMount = price o.Id = order.ID for _, og := range orderGoods { og.Order = order.ID } // insert ordergoods in batch if result := tx.CreateInBatches(&orderGoods, 100); result.RowsAffected == 0 { tx.Rollback() o.Code = codes.Internal o.Detail = "invoking CreateInBatches fails" return primitive.CommitMessageState } // 5. del from cart if result := tx.Where(&model.ShoppingCart{User: order.User, Checked: true}).Delete(&model.ShoppingCart{}); result.RowsAffected == 0 { tx.Rollback() o.Code = codes.Internal o.Detail = "delete from cart fails" return primitive.CommitMessageState } tx.Commit() fmt.Printf("执行完毕\n") return primitive.RollbackMessageState } func (o *OrderListener) CheckLocalTransaction(msg *primitive.MessageExt) primitive.LocalTransactionState { fmt.Printf("消息回查\n") order := model.OrderInfo{} _ = json.Unmarshal(msg.Body, &order) if result := global.DB.Where(&model.OrderInfo{OrderSn: order.OrderSn}).First(&order); result.RowsAffected == 0 { // 不清楚库存是否扣减,但选择commit让消费端执行reback() -> 要求消费端执行reback()的时候进行幂等判断 return primitive.CommitMessageState } return primitive.RollbackMessageState // order成功说明库存必然成功 } /* 4. CreateOrder: 1. get checked goods from cart 2. add price - visit GoodService 3. reduce stocks - visit StockService 4. order basic info 5. del from cart */ func (*OrderServer) CreateOrder(c context.Context, req *proto.OrderRequest) (*proto.OrderInfoResponse, error) { ol := OrderListener{} p, _ := rocketmq.NewTransactionProducer( &ol, producer.WithNsResolver(primitive.NewPassthroughResolver([]string{"192.168.2.112:9876"})), producer.WithRetry(2), ) err := p.Start() if err != nil { fmt.Printf("start producer error: %s", err.Error()) os.Exit(1) } order := model.OrderInfo{ User: req.UserId, OrderSn: GenerateOrderSyn(req.UserId), Address: req.Address, SignerName: req.Name, SingerMobile: req.Mobile, Post: req.Post, } jsonStr, _ := json.Marshal(order) msg := &primitive.Message{ Topic: "inventory_reback", Body: jsonStr, } res, err := p.SendMessageInTransaction(context.Background(), msg) if err != nil { return nil, status.Error(codes.Internal, "sending msg fails") } if res.State == primitive.CommitMessageState { return nil, status.Error(ol.Code, ol.Detail) } return &proto.OrderInfoResponse{Id: ol.Id, OrderSn: order.OrderSn, Total: ol.OrderMount}, nil }
InventorySrv:
main.go中开始监听mq的reback topic
// start listening reback() c, _ := rocketmq.NewPushConsumer( consumer.WithGroupName("stock"), // sequentially consume message; load balance consumer.WithNsResolver(primitive.NewPassthroughResolver([]string{"192.168.2.112:9876"})), ) err = c.Subscribe("inventory_reback", consumer.MessageSelector{}, handler.AutoReback) if err != nil { fmt.Println(err.Error()) } // Note: start after subscribe err = c.Start() if err != nil { fmt.Println(err.Error()) os.Exit(-1) }
从mq里拿到msg里的ordersn,能够查询到是否已经重复消费,以及具体的Goods信息
要求reduce stocks的时候操作InventoryHis表,详细记录order的状态
type InventoryHistory struct { OrderSn string `gorm:"type:varchar(20);index:idx_order_sn,unique"` Status int32 `gorm:"type:int;"` // 1. refduced 2. rebacked Details GooodsInfoList `gorm:"type:varchar(200);"` }
// 用jsonstring形式存入数据库,拿出来组装进结构
type GoodsInfo struct { GoodsId int32 Num int32 } type GooodsInfoList []GoodsInfo func (g *GooodsInfoList) Scan(value interface{}) error { return json.Unmarshal(value.([]byte), &g) } func (g GooodsInfoList) Value() (driver.Value, error) { return json.Marshal(g) }
consumer消费msg时调用的方法:msg是jsonstr,转化成结构
func AutoReback(ctx context.Context, msgs ...*primitive.MessageExt) (consumer.ConsumeResult, error) { type OrderInfo struct { OrderSn string `gorm:"type:varchar(30);index"` } var oi OrderInfo for _, msg := range msgs { if err := json.Unmarshal(msg.Body, &oi); err != nil { zap.S().Debugf("JSON analysing error") return consumer.ConsumeSuccess, nil } var inv model.InventoryHistory if result := global.DB.Where(&model.InventoryHistory{OrderSn: oi.OrderSn, Status: 1}).First(&inv); result.RowsAffected == 0 { // already reback return consumer.ConsumeSuccess, nil } tx := global.DB.Begin() for _, goodsInfo := range inv.Details { if result := tx.Where(&model.Inventory{Goods: goodsInfo.GoodsId}).Update("stocks", gorm.Expr("stocks+?", goodsInfo.Num)); result.RowsAffected == 0 { tx.Rollback() return consumer.ConsumeRetryLater, nil } } if result := tx.Where(&model.InventoryHistory{OrderSn: oi.OrderSn}).Update("status", 2); result.RowsAffected == 0 { tx.Rollback() return consumer.ConsumeRetryLater, nil } tx.Commit() } return consumer.ConsumeSuccess, nil }
Delay msg
create order 同时发送delay msg,属于create order的local transaction
// 6. when we create order; we also need to send "delay msg" p, _ := rocketmq.NewProducer( producer.WithNsResolver(primitive.NewPassthroughResolver([]string{"192.168.2.112:9876"})), producer.WithRetry(2), ) err = p.Start() if err != nil { tx.Rollback() o.Code = codes.Internal o.Detail = "start delay msg fails" return primitive.CommitMessageState } m := primitive.NewMessage("order_timeout", msg.Body) m.WithDelayTimeLevel(5) // 1min _, err = p.SendSync(context.Background(), m) if err != nil { tx.Rollback() o.Code = codes.Internal o.Detail = "send delay msg fails" return primitive.CommitMessageState }
ordersrv中main.go要listen ”order_timeout“, 并调用AutoTimeout()
/* * if order state is not TRADE_SUCCESS -> TRADE_CLOSED * send normal msg reback() */ func AutoTimeout(ctx context.Context, msgs ...*primitive.MessageExt) (consumer.ConsumeResult, error) { var oi model.OrderInfo for _, msg := range msgs { if err := json.Unmarshal(msg.Body, &oi); err != nil { zap.S().Debugf("JSON analysing error") return consumer.ConsumeSuccess, nil } if result := global.DB.Where(&model.OrderInfo{OrderSn: oi.OrderSn}).First(&oi); result.RowsAffected == 0 { return consumer.ConsumeSuccess, nil } if oi.Status != "TRADE_SUCCESS" { // how to achieve idempotence? tx := global.DB.Begin() // 1. update oi.Status oi.Status = "TRADE_CLOSED" if result := tx.Save(&oi); result.RowsAffected == 0 { tx.Rollback() zap.S().Debugf("update orderInfo status error") return consumer.ConsumeRetryLater, nil } // 2. send to "inventory_reback" mq; normal msg p, _ := rocketmq.NewProducer( producer.WithNsResolver(primitive.NewPassthroughResolver([]string{"192.168.2.112:9876"})), producer.WithRetry(2), ) err := p.Start() if err != nil { tx.Rollback() zap.S().Debugf("starting mq error") return consumer.ConsumeRetryLater, nil } msg := &primitive.Message{ Topic: "inventory_reback", Body: msg.Body, } _, err = p.SendSync(context.Background(), msg) if err != nil { tx.Rollback() zap.S().Debugf("sending reback msg error") return consumer.ConsumeRetryLater, nil } //err = p.Shutdown() //if err != nil { // fmt.Printf("shutdown producer error: %s", err.Error()) //} tx.Commit() } } return consumer.ConsumeSuccess, nil }
Shutdown造成的问题
phenomena:rocket mq does not function well
Do not use different "Producer" in the same process --> share the same `Client` -> `shutdown` one producer will affect another
正常情况下mq producer发完后可以立刻shutdown, mq consumer则保持quit前持续监听,但是这个前提是producer和consumer在不同进程,有不同PID,从clientMap中拿到的client不同,不会相互影响。
如果多个producer,consumer公用一个process,则producer不可用完shutdown。<-quit 的时候会全部结束
幂等性Idempotence
service avalanche:


circuit breaker
timeout -> retry -> idempotence
retry:使用 go-grpc-middleware,作为interceptor加入grpc
problem -> http请求的类型:
- post
- put:
update 1 to 200 (ok!!)
plus 1 (no!!!)
1. HTTP methods like get/put/delete
2. sql statement: -> utilize `select` or `delete` 天生幂等;
3. select + insert
核心高并发流程不要用这种方法
4. unique identifier: creating user using phone number/UUID
5. token mechanism: Preventing duplicate page submissions
解决办法:
集群环境:采用token加redis(redis单线程的,处理需要排队)
处理流程:
1. 数据提交前要向服务的申请token,token放到redis或内存,token有效时间
2. 提交后后台校验token(通过delete token判断),生成新的token返回
( in distributed situation
6. pessimistic lock
获取数据的时候加锁获取
select * from table_xxx where id='xxx' for update;
注意:id字段一定是主键或者唯一索引,不然是锁表,会死人的
悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用
7. 乐观锁
8. distributed lock
构建全局唯一索引比较困难,例如唯一性的字段没法确定,这时候可以引入分布式锁
)
9. 对外提供接口的api如何保证幂等
source+seq在数据库里面做唯一索引,防止多次付款
当第三方调用时,先在本方系统里面查询一下,是否已经处理过,返回相应处理结果;
没有处理过,进行相应处理,返回结果
