离线数据分析之 人物兴趣取向分析(2-3) 使用pyspark构建Kmeans/随机森林完成分类预测
一、下载包
settings -> interpreter ->
+ joblib 存取模型
+ matplotlib
+ numpy
+ pyspark
+ scikit-learn
二 、先确定pyCharm能用spark.sql连接hive成功
见 https://www.cnblogs.com/sabertobih/p/14183397.html
三、Kmeans目的:使用train集给events分label
(1) 确定k值
注意,其中的features字段在用工具执行kafka->hbase的过程中将_c0,_c1,_c2...多列合并成了一列string
而Kmeans中的VectorAssembler需要列名的Array集合
import numpy as np from matplotlib import pyplot as plt from pyspark.sql import SparkSession from pyspark.ml.clustering import KMeans from pyspark.sql.functions import split from pyspark.sql.types import DoubleType from pyspark.ml.feature import VectorAssembler if __name__ == '__main__': spark=SparkSession.builder.appName("test")\ .master("local[*]")\ .enableHiveSupport().getOrCreate() df = spark.sql("select eventid,features from dm_events.dm_usereventfinal").cache() #先从dataframe中将指定列进行分割 并获得返回新的dataframe spno 101列 和原来的df 一一对应 spno = split(df["features"],",") # 将101列的值通过withcolumn都补充到df上 同时将所有的列都转为double类型 for i in range(101): df = df.withColumn("c_"+str(i),spno.getItem(i).cast(DoubleType())) # 删除不需要的列 features df = df.drop("features") # 使用VectorAssembler 将c_0~c_100都组装为feature的向量列 ass = VectorAssembler(inputCols=["c_{0}".format(i) for i in range(101)],outputCol="feature") re = ass.transform(df) # 只保留需要的两列 re = re.select("eventid","feature") # 准备一个点数组 points = [i for i in range(2,50)] # 定义一个距离数组 distance=[] for po in points: print("point...........",po,"\n") # 使用kmeans指定特征列为feature clf = KMeans(k=po, featuresCol="feature") # 计算模型 model = clf.fit(re) # 计算所有到质心的平均距离 并存放到距离数组中 distance.append(model.computeCost(re)) # 绘制对应的折线图 plt.plot(points,distance,color="red") plt.show()
结果:
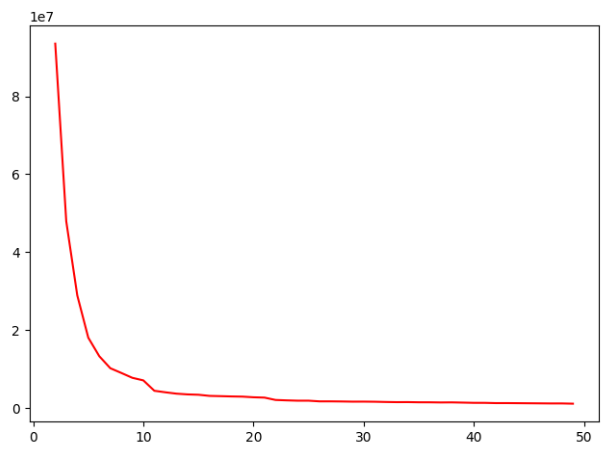
(2) 使用k训练模型
import numpy as np from matplotlib import pyplot as plt from pyspark.sql import SparkSession from pyspark.ml.clustering import KMeans from pyspark.sql.functions import split from pyspark.sql.types import DoubleType from pyspark.ml.feature import VectorAssembler from pyspark.ml.clustering import KMeans,KMeansModel if __name__ == '__main__': spark=SparkSession.builder.appName("test")\ .master("local[*]")\ .enableHiveSupport().getOrCreate() df = spark.sql("select eventid,features from dm_events.dm_usereventfinal").cache() #先从dataframe中将指定列进行分割 并获得返回新的dataframe spno 101列 和原来的df 一一对应 spno = split(df["features"],",") # 将101列的值通过withcolumn都补充到df上 同时将所有的列都转为double类型 for i in range(101): df = df.withColumn("c_"+str(i),spno.getItem(i).cast(DoubleType())) # 删除不需要的列 features df = df.drop("features") # 使用VectorAssembler 将c_0~c_100都组装为feature的向量列 ass = VectorAssembler(inputCols=["c_{0}".format(i) for i in range(101)],outputCol="feature") re = ass.transform(df) # 只保留需要的两列 re = re.select("eventid","feature") # 准备一个点数组 # points = [i for i in range(2,50)] # # 定义一个距离数组 # distance=[] # for po in points: # print("point...........",po,"\n") # # 使用kmeans指定特征列为feature # clf = KMeans(k=po, featuresCol="feature") # # 计算模型 # model = clf.fit(re) # # 计算所有到质心的平均距离 并存放到距离数组中 # distance.append(model.computeCost(re)) # # # 绘制对应的折线图 # plt.plot(points,distance,color="red") # plt.show() # 根据图形 得到最优的K值为10 clf = KMeans(k=10, featuresCol="feature") model = clf.fit(re) ## 训练成一个通用model,存起来以备复用 #### 模型存储方法1:上传hdfs KMeansModel.write(model).overwrite().save("hdfs://192.168.56.115:9000/party/model") #### 模型存储方法2:joblib #save model joblib.dump(clf,'../../data/model/randomforest.pkl',compress=3) #load model to clf clf = joblib.load('../../data/model/randomforest.pkl')
(3)模型读取,并将结果写入hive表中
# 读取模型 对数据进行分组 分组后存放到hive中 # transform是给model传参数,返回id,features,prediction => 直接drop掉向量列 dff = KMeansModel.load("hdfs://192.168.56.115:9000/party/model") \ .transform(re).select("eventid", "prediction") dff.write.mode("overwrite").saveAsTable("dm_events.dm_eventType")
四、RF目的:预测test集的label(if interested?)
from pyspark.sql import SparkSession from pyspark.ml.feature import VectorAssembler from pyspark.sql.types import DoubleType from pyspark.ml.classification import RandomForestClassifier,RandomForestClassificationModel from pyspark.ml.evaluation import BinaryClassificationEvaluator if __name__ == '__main__': spark = SparkSession.builder.master("local[*]") \ .appName("test").enableHiveSupport().getOrCreate() df = spark.sql("select * from dm_events.dm_final").distinct().cache() ## 1.选取作为features的列 cols = df.columns cols.remove("label") cols.remove("userid") cols.remove("eventid") cols.remove("age") # 该字段为null,不能变成向量 ## 2.预features列转成DoubleType for c in cols: df = df.withColumn(c,df[c].cast(DoubleType())) ## 3.预features列转成向量,并加入df中 ass = VectorAssembler(inputCols=cols,outputCol="features") ## df中加入向量列,取出features+label df= ass.transform(df) model_df = df.select(["features","label"])\ .withColumn("label",df["label"].cast(DoubleType())) # 4.将df 2 8分开 train_df,test_df = model_df.randomSplit([0.8,0.2],seed=1225) # 5.训练模型,用RF训练 rf = RandomForestClassifier(labelCol="label",numTrees=128,maxDepth=9) model = rf.fit(train_df) # 用train结果生成模型,用fit # 6.存储模型 RandomForestClassifier.write(model).overwrite().save("d:/rfc")
# 7.读取模型,并测试准确性:0.7896044629820028 mod = RandomForestClassificationModel.load("d:/rfc") res = mod.transform(test_df) # 读取模型用transform,用来获得test结果 rfc_auc = BinaryClassificationEvaluator(labelCol="label").evaluate(res) print(rfc_auc) spark.stop()

