python 之sparkSQL连接hive
可参考 https://blog.csdn.net/m0_46651978/article/details/111618085#comments_14329527
一、首先,linux上
====单节点方法====
1. 先把spark stop了:sbin/stop-all.sh
2. 把hive里面的hive-site.xml拷贝到spark234/conf中
cp /opt/bigdata/hadoop/hive110/conf/hive-site.xml /opt/bigdata/spark/spark234/conf/
3. 把mysql-connector拉到/opt/bigdata/spark/spark234/jars
4. 重启spark:sbin/start-all.sh
====集群方法,集群还是用黑界面吧====
以上过程中第2点增加: 把hive里面的core-site.xml & hdfs-site.xml拷贝到spark234/conf中
二、windows上
====单节点方法====
1. 配环境变量:SPARK_HOME:D:\spark-2.3.4-bin-hadoop2.6
path :%SPARK_HOME%\bin
2. 把一中linux中的spark234/conf直接覆盖到spark-2.3.4-bin-hadoop2.6/conf
(注意改hive-site.xml中的地址为虚拟机地址)
3. 把一中linux中的spark234/jars直接覆盖到spark-2.3.4-bin-hadoop2.6/jars
4.Pycharm中:
settings -> interpreter ->
+ joblib 存取模型
+ matplotlib
+ numpy
+ pyspark
+ scikit-learn
代码:
if __name__ == '__main__': spark=SparkSession.builder.appName("test")\ .master("spark://192.168.56.111:7077")\ .enableHiveSupport().getOrCreate() df=spark.sql("select * from dm_events.dm_usereventfinal limit 3") df.show()
报错:2020-12-24 21:44:54 WARN TaskSchedulerImpl:66 - Initial job has not accepted any resources;
解决方法:./spark-shell,使用命令 sc.getConf.getAll.foreach(println)
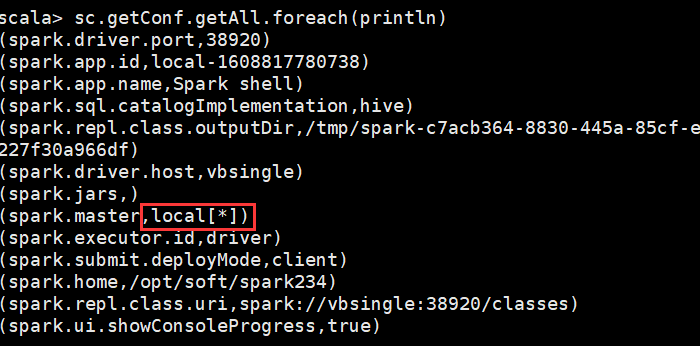
于是改成
from pyspark.sql import SparkSession if __name__ == '__main__': spark=SparkSession.builder.appName("test")\ .master("local[*]")\ .enableHiveSupport().getOrCreate() df=spark.sql("select * from dm_events.dm_usereventfinal limit 3") df.show()
成功!
