离线数据分析之 人物兴趣取向分析(五)SparkStreaming介绍
相关链接:https://www.cnblogs.com/fishperson/p/10447033.html


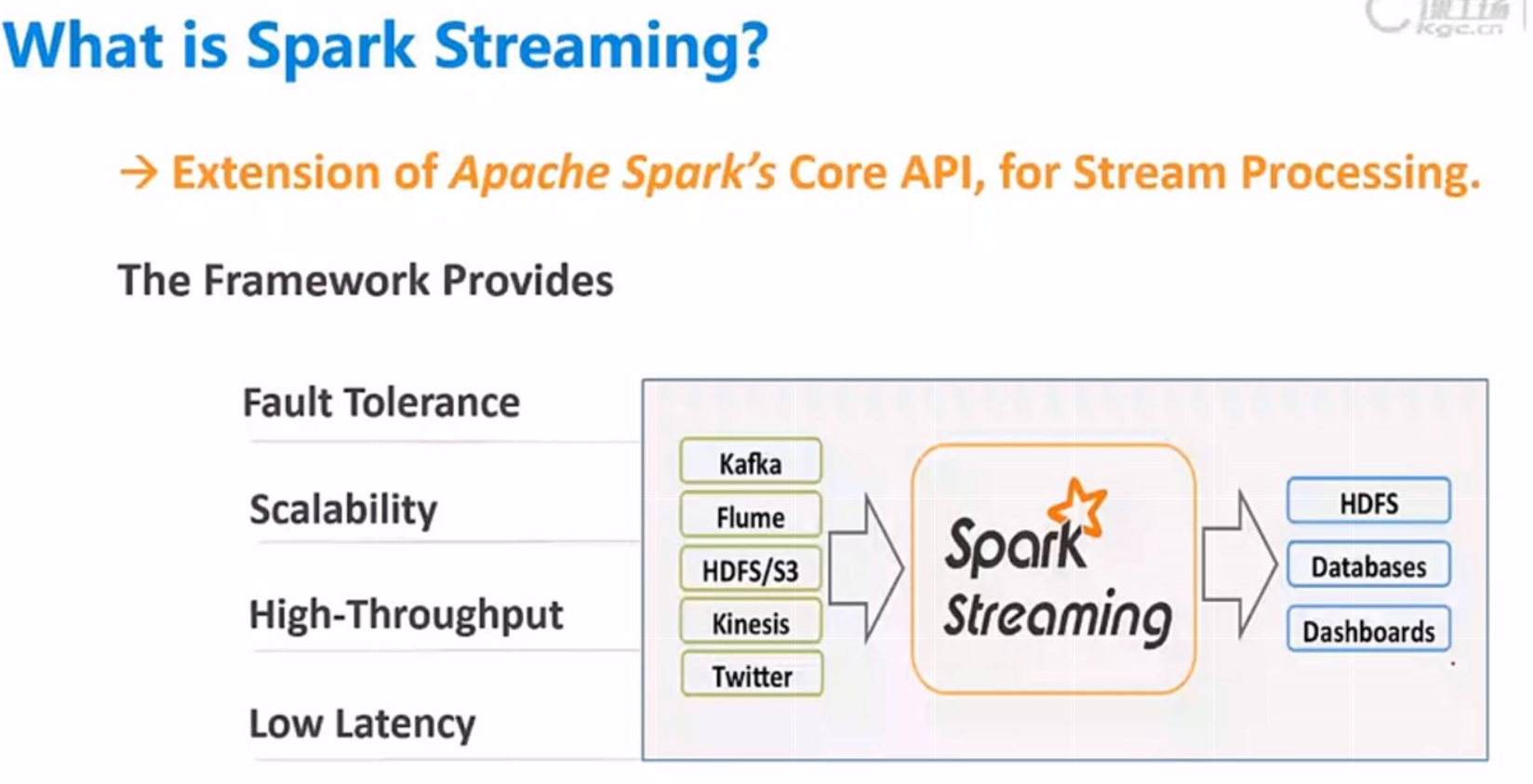
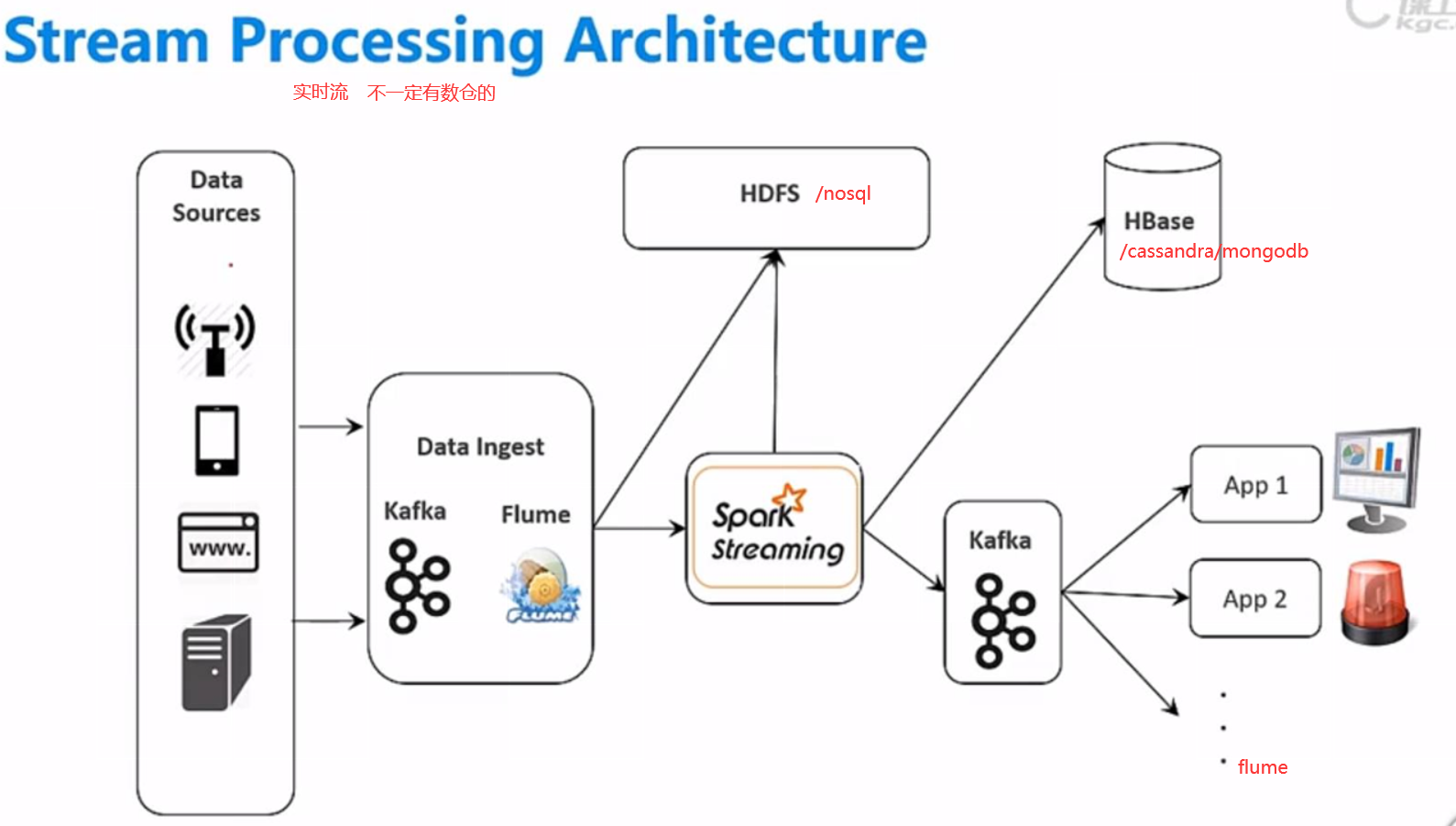
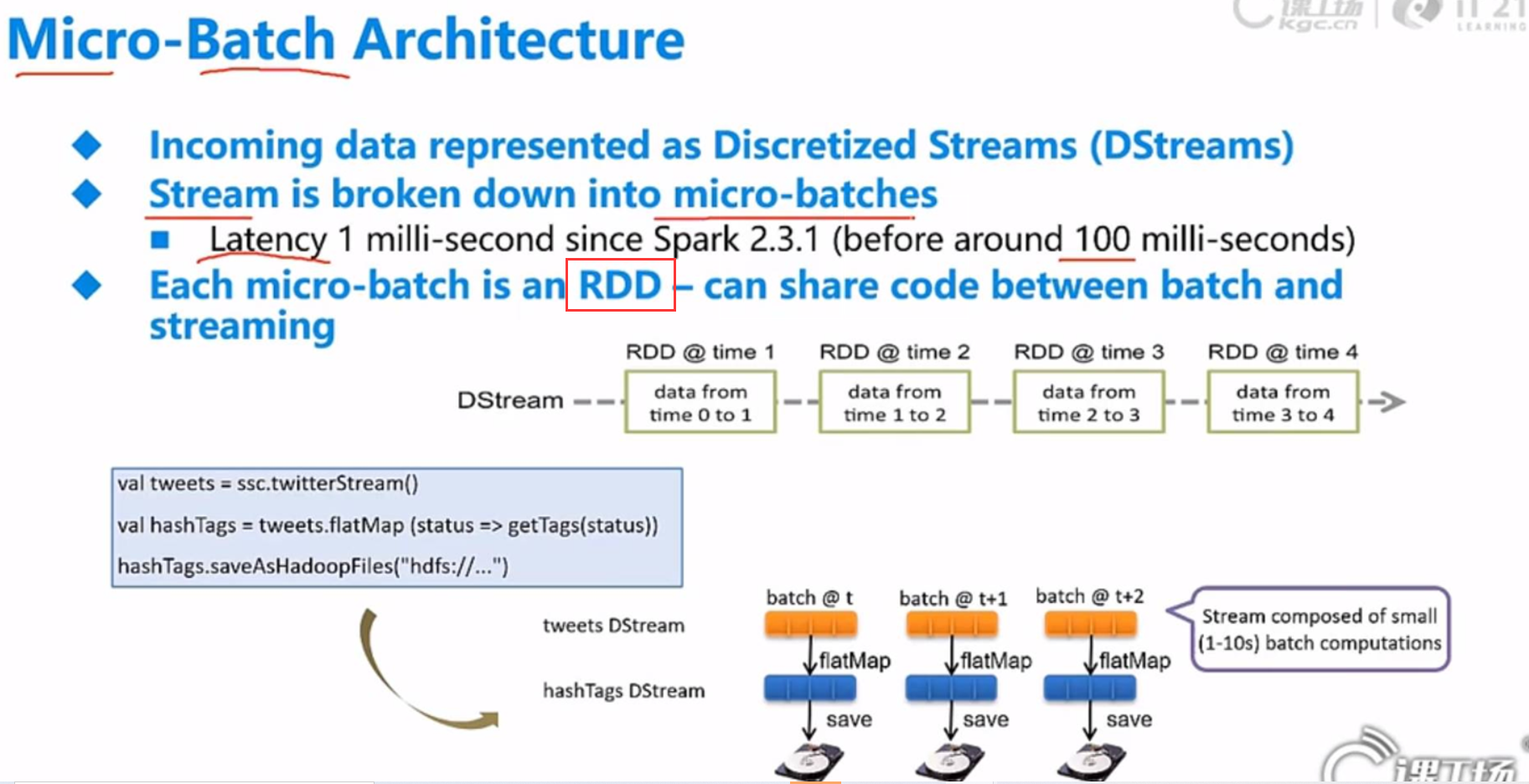

/
+
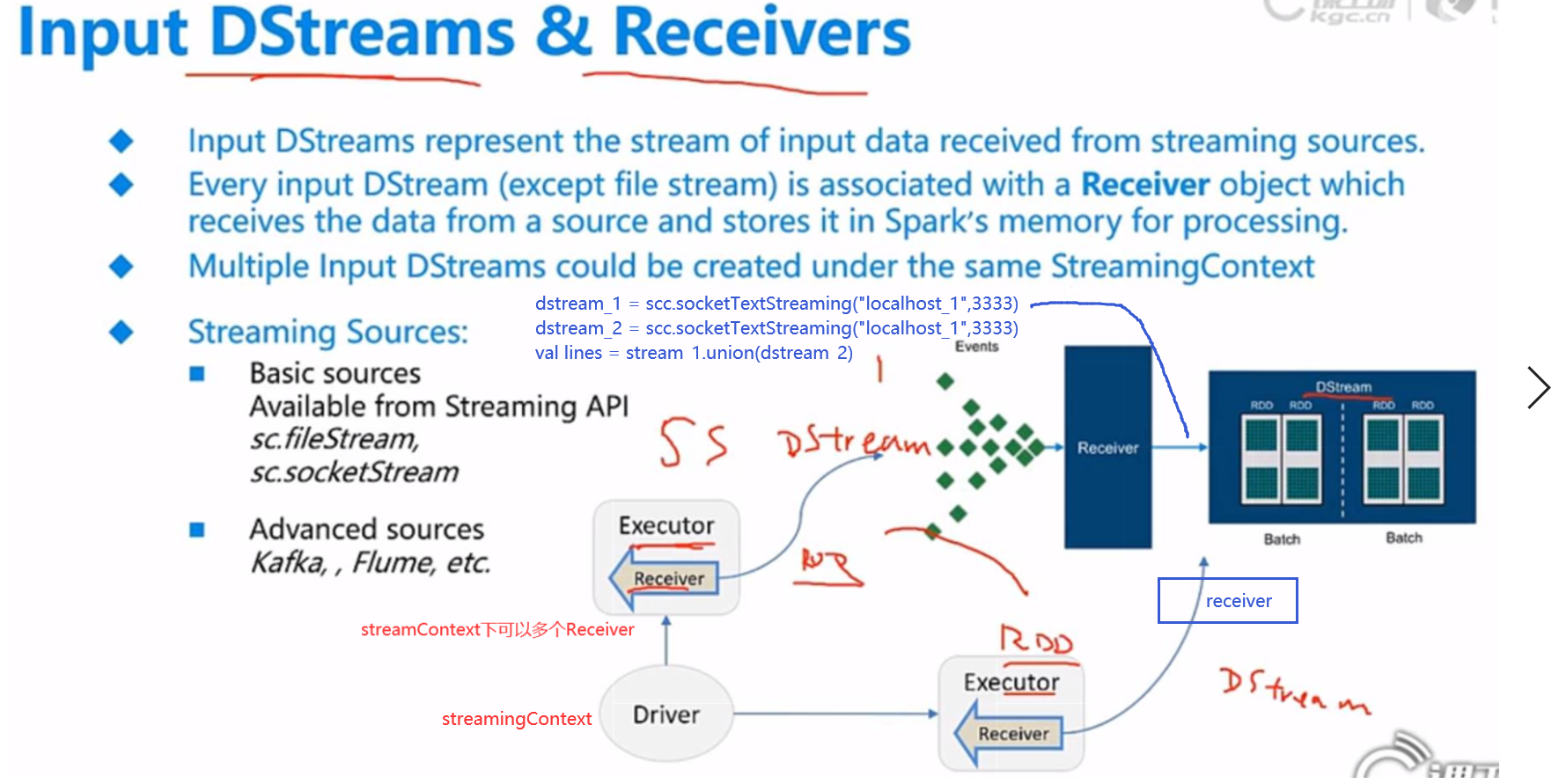





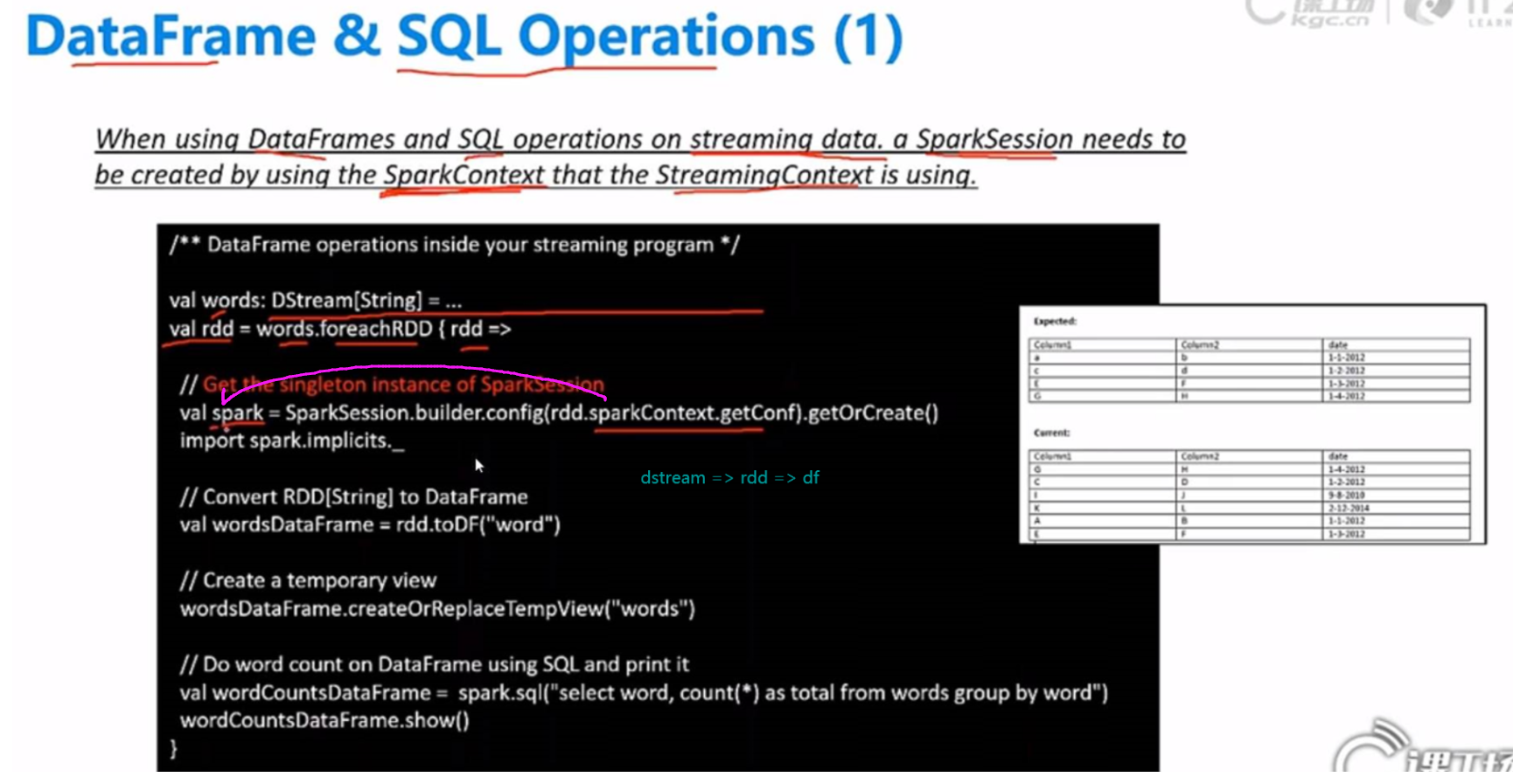
Dstream.foreachRDD :每个interval时间段中的RDD
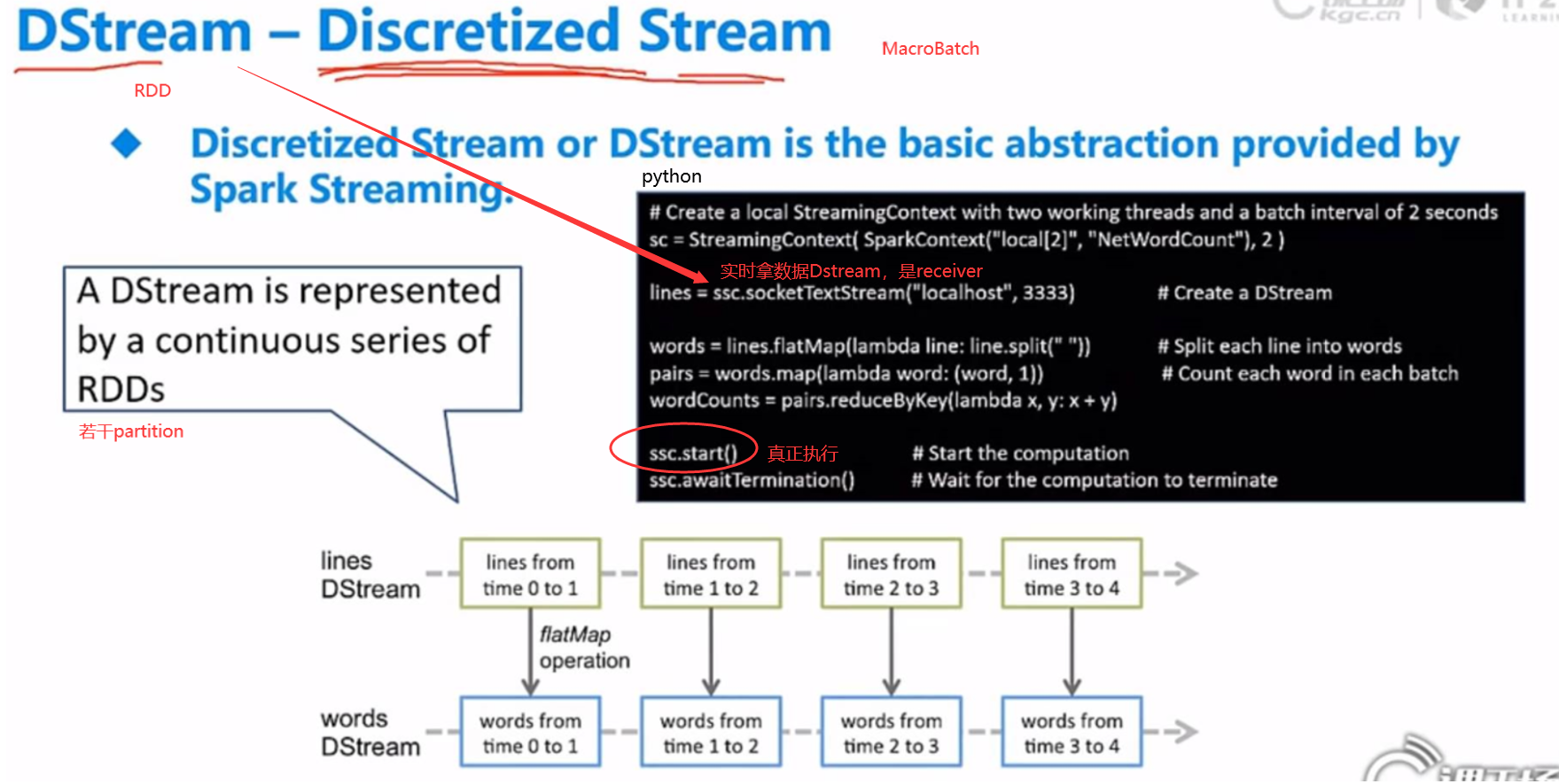
Dstream和RDD的关系? 1对1
补充:只有序列化才能远程传输!!!
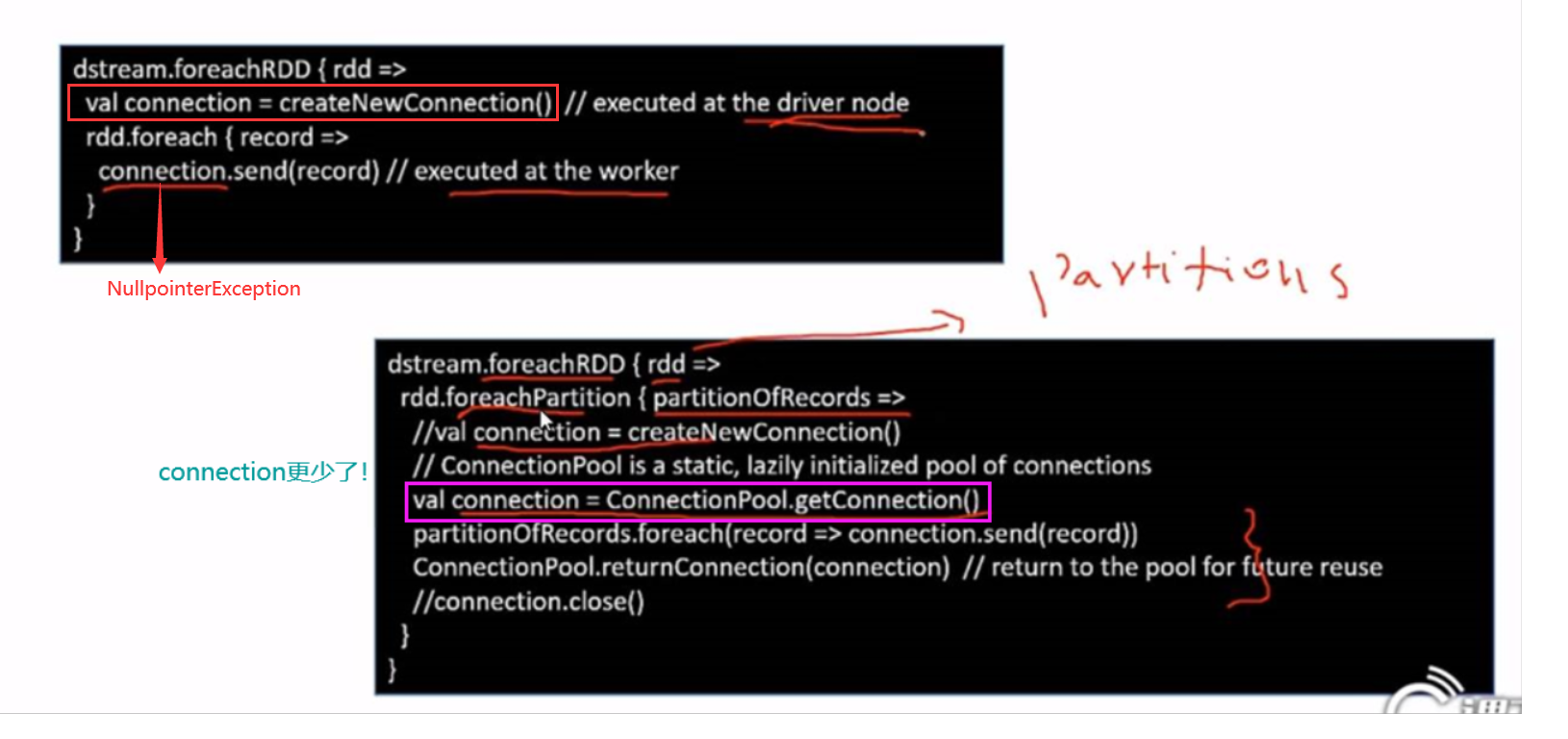
Connection是昂贵资源,非托管资源(不由垃圾回收器托管,比如有网络传输,连接数据库,io流)。永远保持链接,很危险,一定要close。
序列化到哪里?
- 序列化写到媒体介质上!!!!
序列化的目的?
- 把内存对象 -> 进行文件落盘 -> 用于网络传输
序列化了什么?
- 只序列化值:保存类的状态!!!!!(取出来的时候用对象接,方法不用传)
所以,RDD需要序列化 => 包装后序列化,广播发送到executors上
典型序列化例子:mapreduce 的每一个传参都是序列化的。Text有read write方法可以序列化
1.典型错误
2.每个partition中用连接池获取conn,前提是分区不太多
3.每行一个conn,不推荐的方法
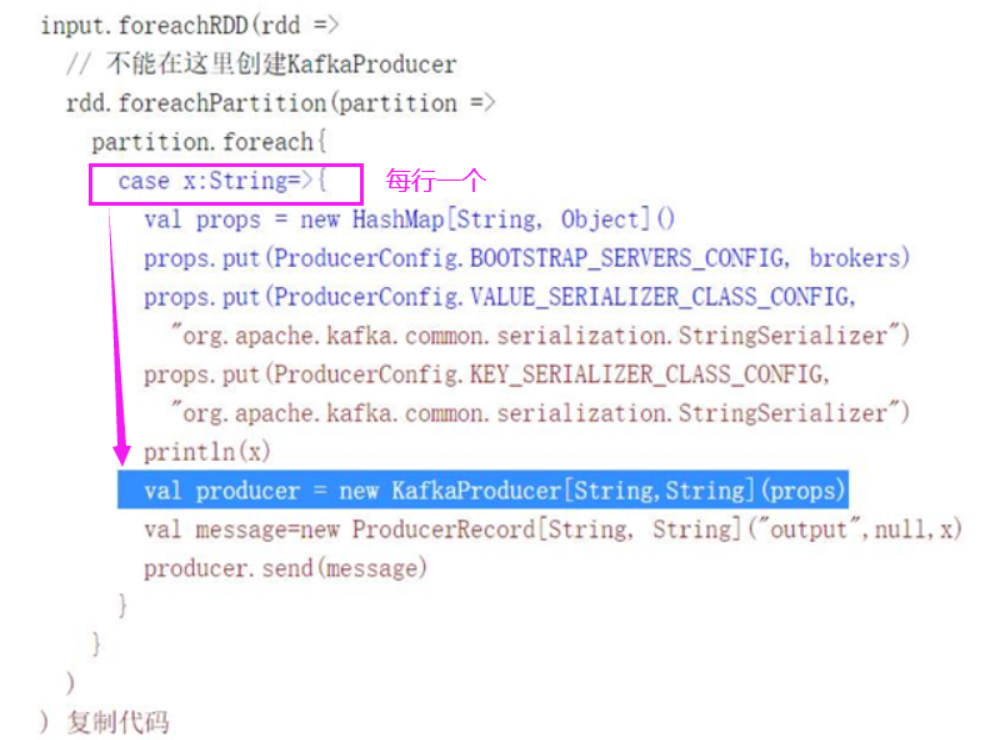
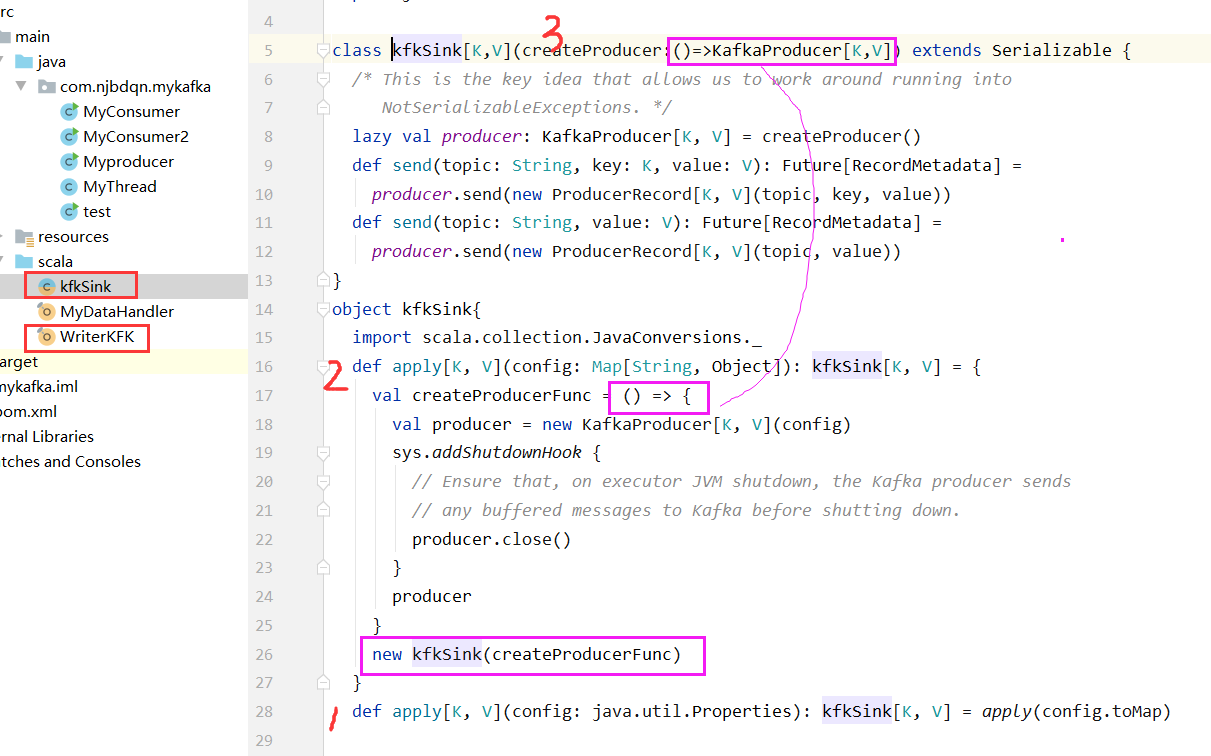
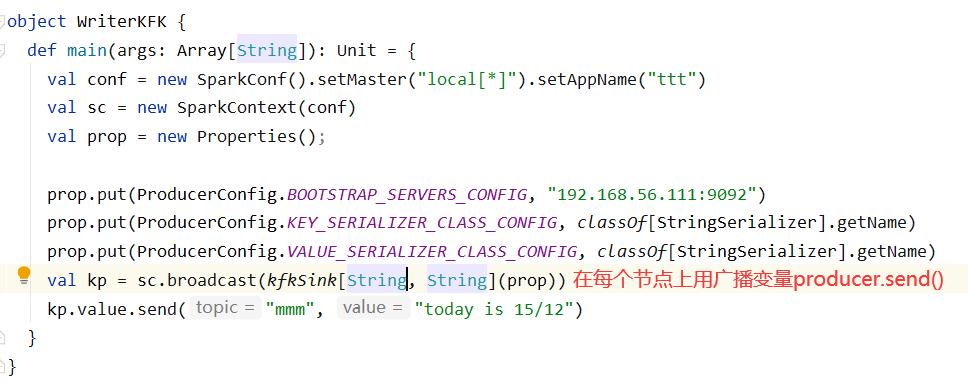
4.利用广播变量的形式,将KafkaProducer广播到每一个executor
见:https://www.cnblogs.com/importbigdata/p/10765558.html


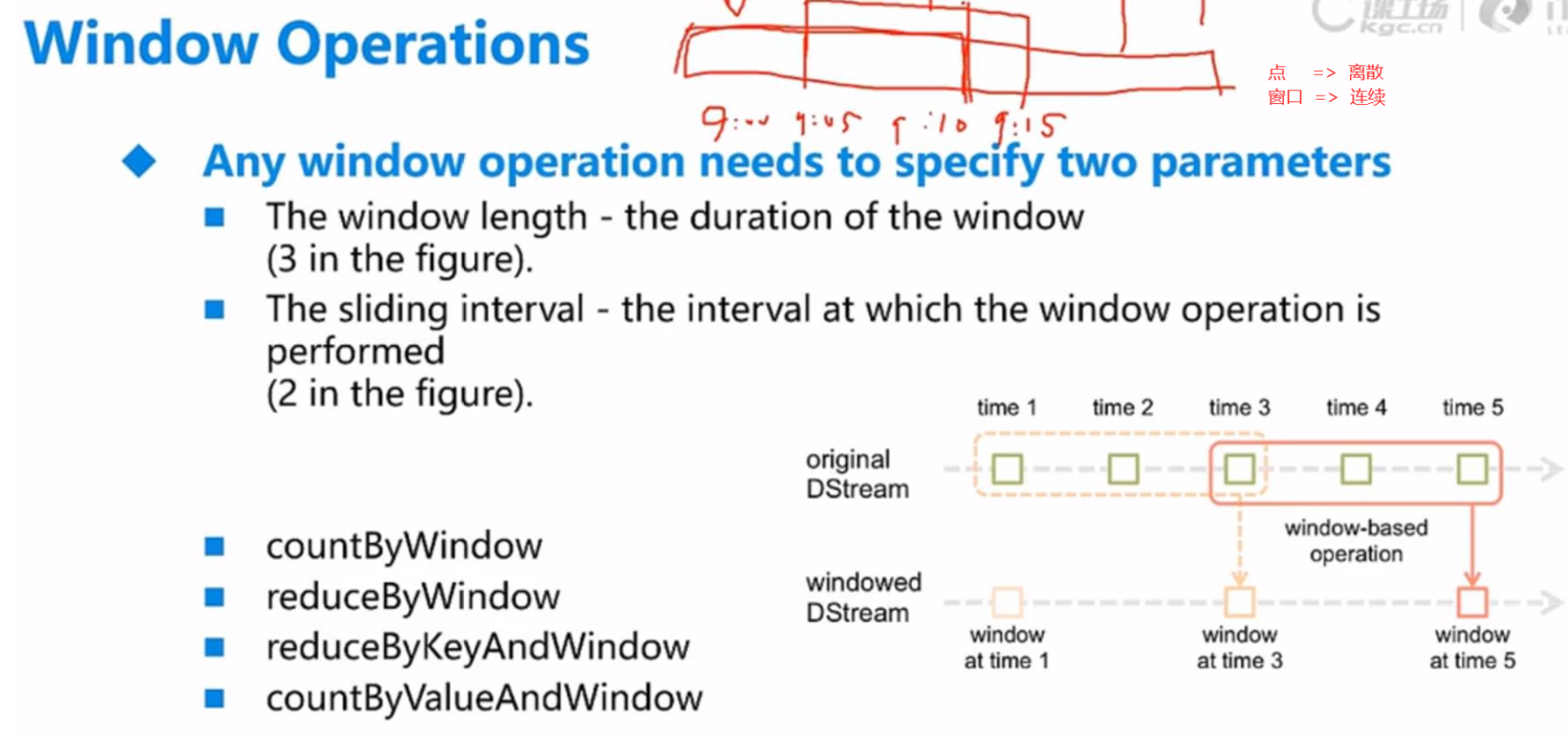
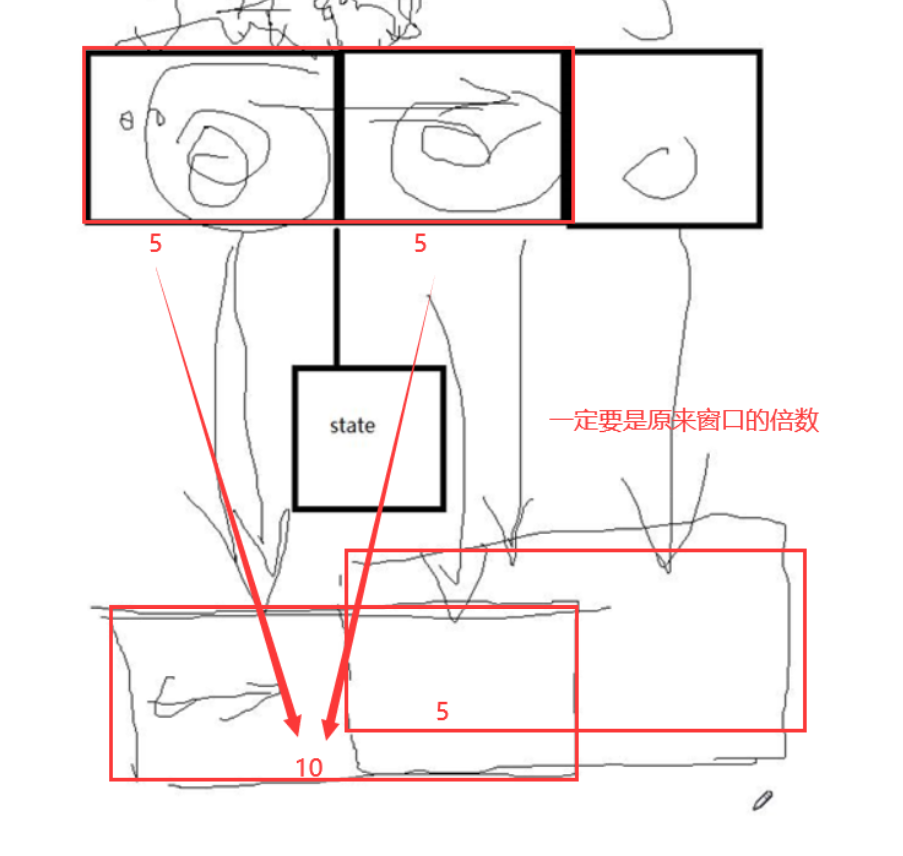
步长和sliding interval 都需要是窗口的倍数









 浙公网安备 33010602011771号
浙公网安备 33010602011771号