hive 之 调优
一、结论
每个窗口函数都有orderby
- 结论:改成全局一次orderby
子查询:MR
- 结论:最好不要子查询
优先干死多余数据
- 【对hive来说】=> 先inner join(不会MR),再where(会MR)
- 【对mysql来说】=> 先 where(筛数据) 再 on(where在前,多个条件,从右向左,先干大的)
三个innerjoin会不会三个mr
- 结论:不启动mr,可以使用 innerjoin
group by 不影响mr
- 结论:有 groupby 不影响性能,可以使用
in不如大于小于:因为in要做全表扫描
- 结论:范围><代替in
from XXX insert XXX
- hive独有写法,提前预加载tmp

二、案例
链接中的DM层:https://www.cnblogs.com/sabertobih/p/13965010.html
>>>
需求:当天-> 顾客,产品,日期,订单个数,当天金额 && 近两天 -> 订单个数,近两天金额
<<<
原始hql:
select d_date,customer_sk,product_sk, `order_num`, `order_dailyamount`, sum(`order_dailyamount`) over(rows between 1 PRECEDING and current row) as recent_amount, sum(`order_num`) over(rows between 1 PRECEDING and current row) as recent_num from ( select dss.d_date, d.customer_sk, d.product_sk, count(d.order_sk) as `order_num`, sum(d.order_amount) as `order_dailyamount` from dw_sales_source.dwd_fact_sales_order d inner join dw_sales_source.dwd_dim_date dss on d.date_sk = dss.date_sk group by dss.d_date,d.customer_sk,d.product_sk order by dss.d_date )T
改进:
- 不想要子查询: sum(order_dailyamount) over() 有错,但可以 sum(sum(d.order_amount)) over()
- 窗口函数里有重复order by,挪到全局
select dss.d_date,d.customer_sk,d.product_sk, count(d.order_sk) as order_num, sum(d.order_amount) as order_dailyamount, sum(sum(d.order_amount)) over(rows between 1 PRECEDING and current row) as recent_amount, sum(count(d.order_sk)) over(rows between 1 PRECEDING and current row) as recent_num from dw_sales_source.dwd_fact_sales_order d inner join dw_sales_source.dwd_dim_date dss on d.date_sk = dss.date_sk group by dss.d_date,d.customer_sk,d.product_sk order by dss.d_date
>>>
需求:2018-10-20 -> 顾客,产品,日期,订单个数,当天金额 && 近两天 -> 订单个数,近两天金额
<<<
使用窗口函数还是group by?
取决于需求!
- groupby => 一组一个
- 窗口函数 => 逐日连续
PS: case when?见行转列 https://www.cnblogs.com/sabertobih/p/13589760.html
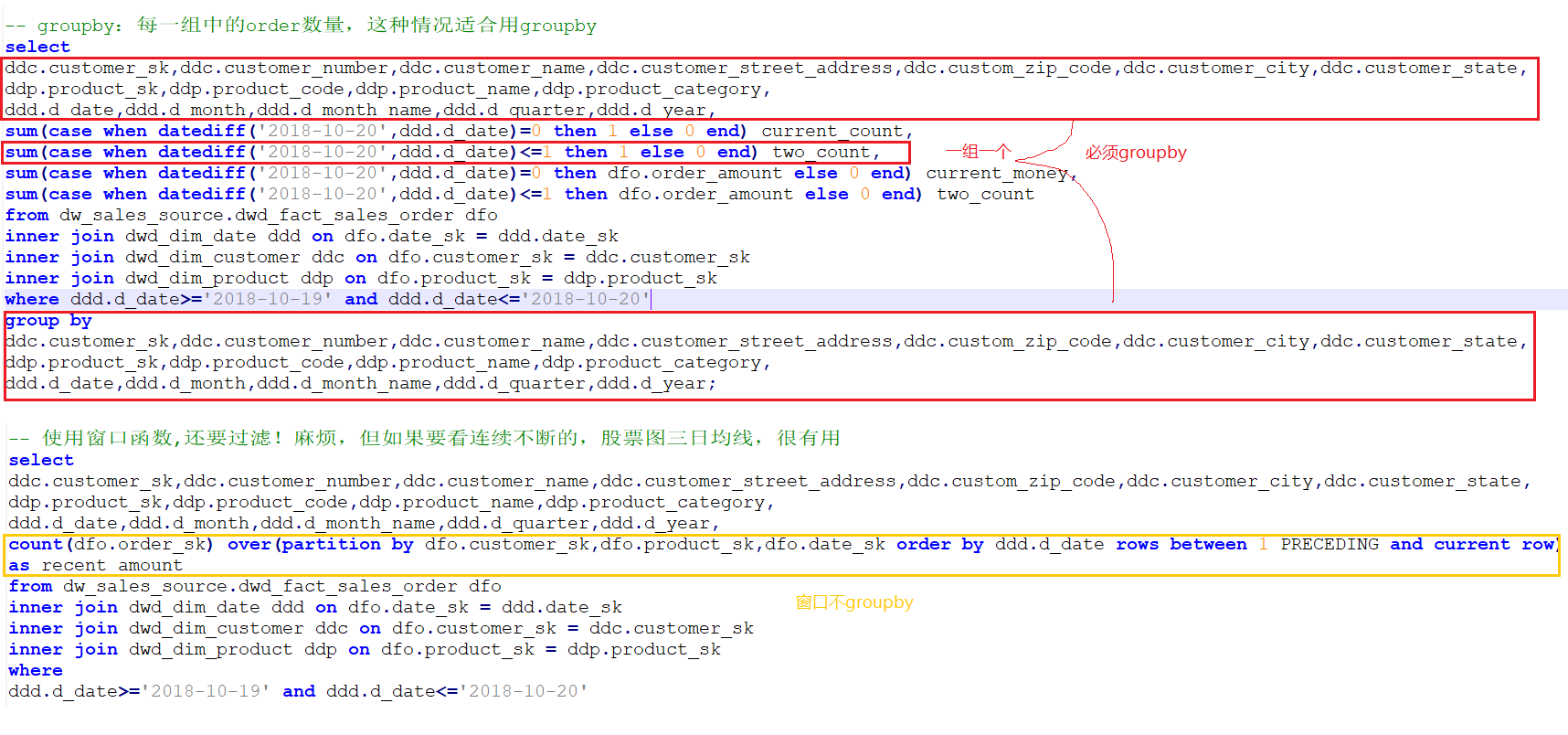
-- groupby:每一组中的order数量,这种情况适合用groupby select ddc.customer_sk,ddc.customer_number,ddc.customer_name,ddc.customer_street_address,ddc.custom_zip_code,ddc.customer_city,ddc.customer_state, ddp.product_sk,ddp.product_code,ddp.product_name,ddp.product_category, ddd.d_date,ddd.d_month,ddd.d_month_name,ddd.d_quarter,ddd.d_year, sum(case when datediff('2018-10-20',ddd.d_date)=0 then 1 else 0 end) current_count, sum(case when datediff('2018-10-20',ddd.d_date)<=1 then 1 else 0 end) two_count, sum(case when datediff('2018-10-20',ddd.d_date)=0 then dfo.order_amount else 0 end) current_money, sum(case when datediff('2018-10-20',ddd.d_date)<=1 then dfo.order_amount else 0 end) two_count from dw_sales_source.dwd_fact_sales_order dfo inner join dwd_dim_date ddd on dfo.date_sk = ddd.date_sk inner join dwd_dim_customer ddc on dfo.customer_sk = ddc.customer_sk inner join dwd_dim_product ddp on dfo.product_sk = ddp.product_sk where ddd.d_date>='2018-10-19' and ddd.d_date<='2018-10-20' group by ddc.customer_sk,ddc.customer_number,ddc.customer_name,ddc.customer_street_address,ddc.custom_zip_code,ddc.customer_city,ddc.customer_state, ddp.product_sk,ddp.product_code,ddp.product_name,ddp.product_category, ddd.d_date,ddd.d_month,ddd.d_month_name,ddd.d_quarter,ddd.d_year; -- 使用窗口函数,还要过滤!麻烦,但如果要看连续不断的,股票图三日均线,很有用 select ddc.customer_sk,ddc.customer_number,ddc.customer_name,ddc.customer_street_address,ddc.custom_zip_code,ddc.customer_city,ddc.customer_state, ddp.product_sk,ddp.product_code,ddp.product_name,ddp.product_category, ddd.d_date,ddd.d_month,ddd.d_month_name,ddd.d_quarter,ddd.d_year, count(dfo.order_sk) over(partition by dfo.customer_sk,dfo.product_sk,dfo.date_sk order by ddd.d_date rows between 1 PRECEDING and current row) as recent_amount from dw_sales_source.dwd_fact_sales_order dfo inner join dwd_dim_date ddd on dfo.date_sk = ddd.date_sk inner join dwd_dim_customer ddc on dfo.customer_sk = ddc.customer_sk inner join dwd_dim_product ddp on dfo.product_sk = ddp.product_sk where ddd.d_date>='2018-10-19' and ddd.d_date<='2018-10-20'

