hbase 之 读写原理 & 什么是LSM树?
一、认识B、B+树
B树: 叶节点不构成有序链表
树的高度很高时,磁盘访问的次数增加,访问磁盘的速度慢
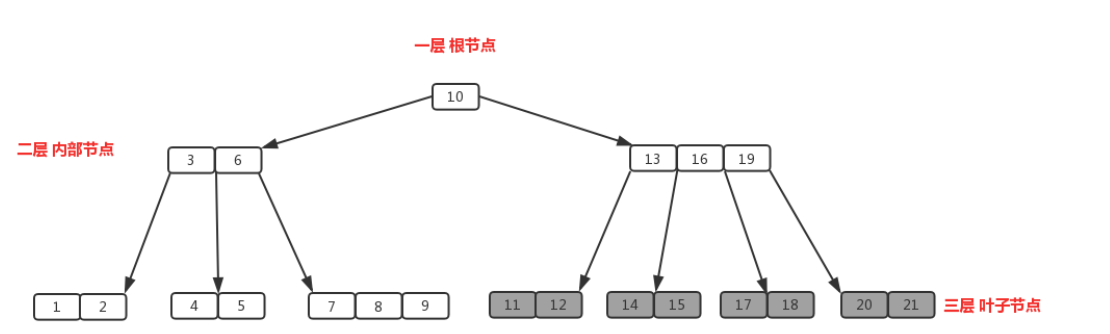
B+树:
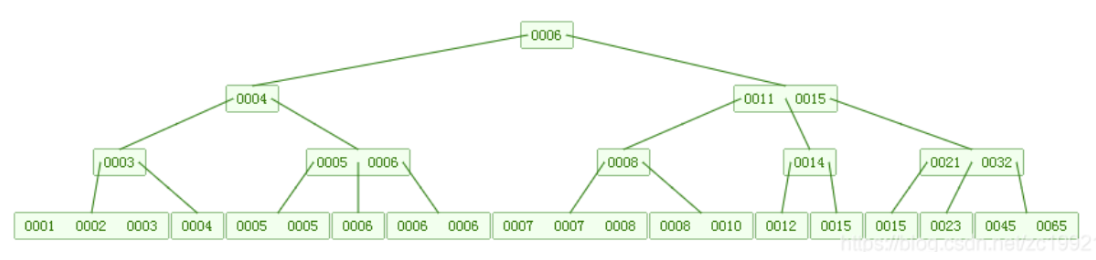
非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中;
树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录;
遍历整棵树可以一次性遍历所有叶子节点(B树只能进行中序遍历)!且数据顺序排列且相连,便于区间查找(数据库使用B+树的主要原因,B树不支持)和搜索。
二、
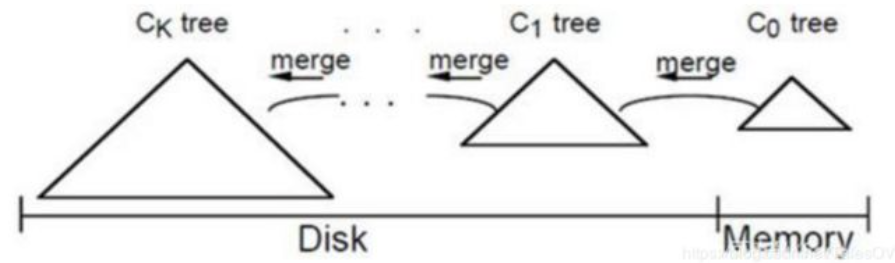
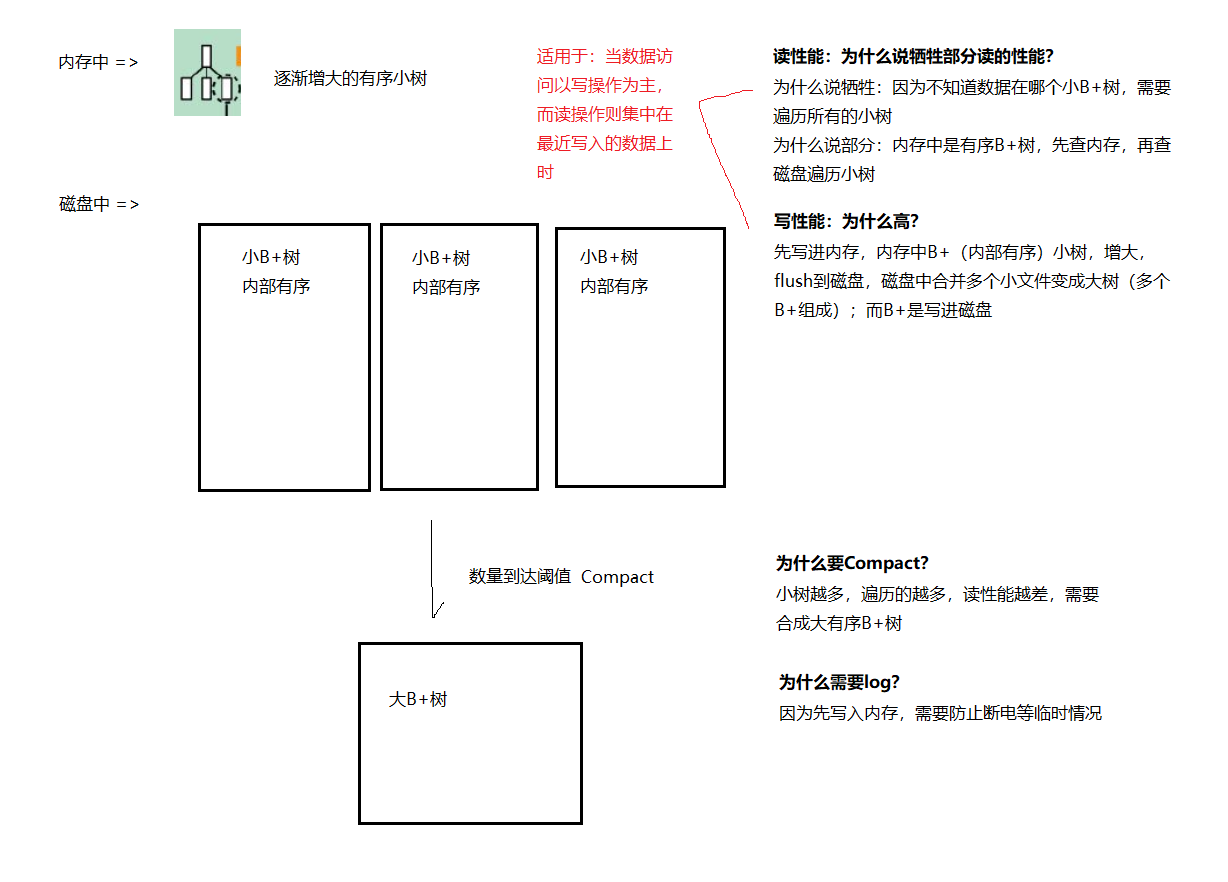
- LSM树插入记录时,先写日志,然后在内存中插入,内存中的树称为C0树。内存中的数据达到一定阈值,或经过一段时间间隔,C0树合并到磁盘C1中。C1中的数据可以进一步合并到C2中。
三、hbase的读写结合LSM树
(一)读流程
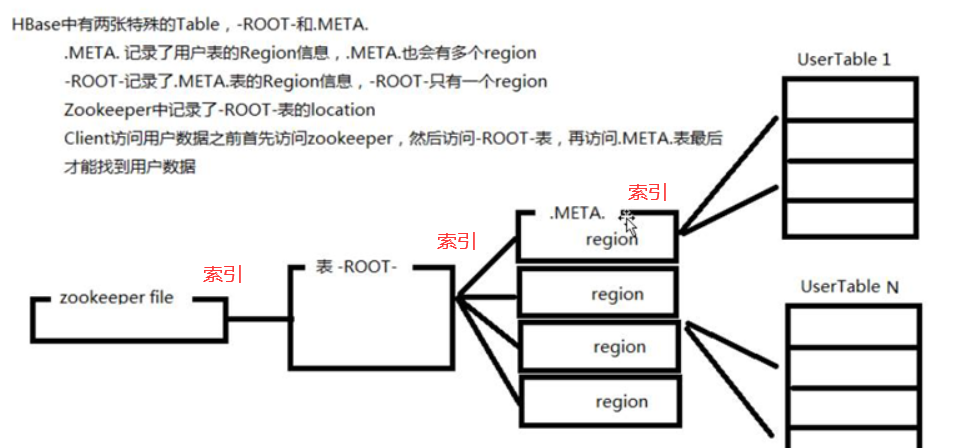
1. Client访问Zookeeper,查找-ROOT-表,获取.META.表信息。
2. 从.META.表查找,获取存放目标数据的Region信息,从而找到对应的RegionServer。
3. 通过RegionServer获取需要查找的数据。
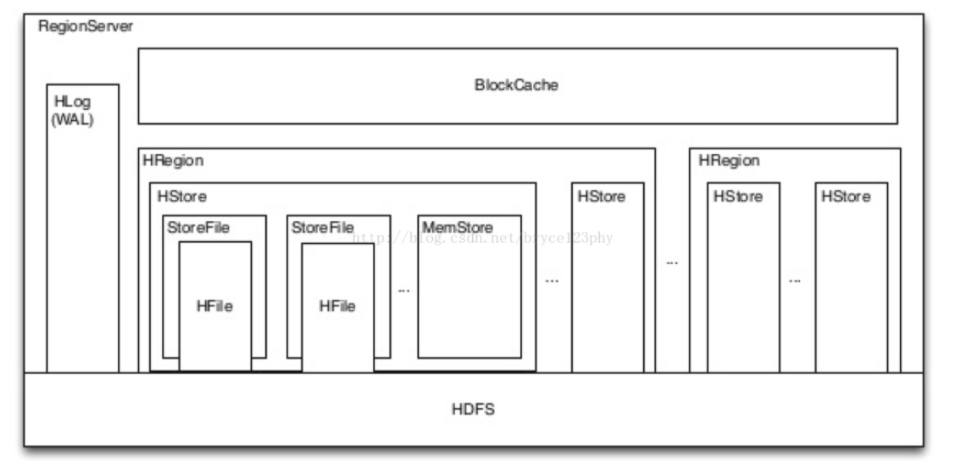
4. Regionserver的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。
读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
-
StoreFiles中的HFile:数据有序的排列在Hfile中,Hfile中是LSM树结构
-
【顺序读写性能高于随机读写】机械硬盘由于其物理结构的原因,顺序读写相邻的磁块比起随机读写可以有效减少磁头的移动次数,从而顺序读写的性能高于随机读写
-
LSM牺牲了部分读的性能 => 但是读取时,由于不知道数据在哪棵小树上,因此必须遍历所有小树,每棵小树内部数据是有序的。查询是先查内存中的部分,再去查磁盘上的部分。
读取过程:client–>Zookeeper–>-ROOT-表–>META表–>RegionServer–>Region–>client
(好处)
-
MemStore对于读性能也至关重要,
-
假如没有MemStore,读取刚写入的数据就需要从文件中通过IO查找,这种代价显然是昂贵的!
-
BlockCache称为读缓存,HBase会将一次文件查找的Block块缓存到Cache中,
-
以便后续同一请求或者邻近数据查找请求,可以直接从内存中获取,避免昂贵的IO操作。
(二)写流程
1.Client通过Zookeeper调度获取表的元数据信息;
2.Cilent通过rpc协议与RegionServer交互,通过-ROOT-表与.META.表找到对应的对应的Region;
3.将数据写入HLog日志中,如出现意外可以同通过HLog恢复信息;
4.将数据写入Region的MemStore中,当MemStore达到阈值开始溢写(到磁盘),异步将其中的数据顺序写入Flush成一个StoreFile;
-
LSM:一颗大树分成N个小树,存入内存,随着小树的增长,内存中的小数flush到磁盘,磁盘中的树定期merge成大树。(LSM树不像B+树一样是一棵完整的大树,一棵LSM树就是一个个B+树合起来的大有序B+树。)
5.MemStore不断生成新的StoreFile,当StoreFile的数量到达阈值后会出发Compact合并操作,将多个StoreFile合并成一个StoreFile;
6.StoreFile文件会不断增大,当达到阈值后会出发Split操作,把当前的Region且分为两个新的Region。父Region会下线,两个子Region会被HMaster分配到相应的RegionServer。
Cli -> zookeeper -> 通过-ROOT-表与.META.表 -> RegionServer -> Region
->写入HLog -> 写入Memstore -> SPILL到StoreFile -> COMPACT -> SPLIT成新Region
(三)删除功能
删除数据不是进行实质上的删除,也就是磁盘上仍然存在此条数据。只不过是对删除的数据打上了墓碑标记。利用墓碑标记,读数据会忽略此条数据。
当进行小文件合并时,才会进行实质上删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号