数据仓库之 案例(基础篇)
一、销售案例步骤
(一)ODS层
- 建立源数据库并生成初始的数据
- 在Hive中创建源数据过渡区和数据仓库的表
- 日期维度的数据装载
- 数据的ETL => 进入dwd层,本案例简单,不需要清洗
(二)DW层
- dwd层:ETL清洗,本案例不需要
- dws层:建模型+轻聚合,本案例只需要建模型,太简单,不需要聚合。
- 轻聚合后建模 => 星型模型【注意,是轻聚合后,成为星型模型】
(三)DM层
- dm层:-> 宽表
- 存放在hive -> 太慢!适合复杂计算,用来机器学习/数据挖掘
- 存放在mysql/oracle等分析型数据库 -> 快!用来数据分析
- 接口暴露:springboot 暴露接口
数据仓库分层
- ODS(operational Date store) 源数据层
- DW(Data WareHouse) 数据仓库层
- DM(Data Market) 数据集市层
二、数据仓库之 构建步骤
(一)ODS层
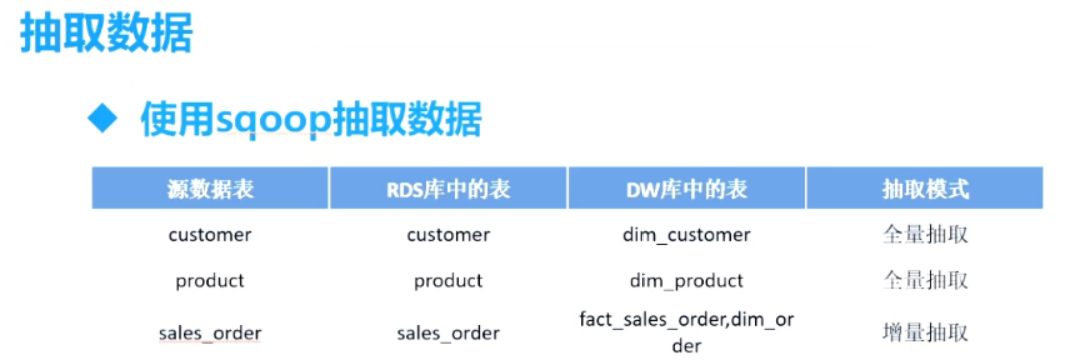
(1)建立源数据库mysql并生成初始的数据
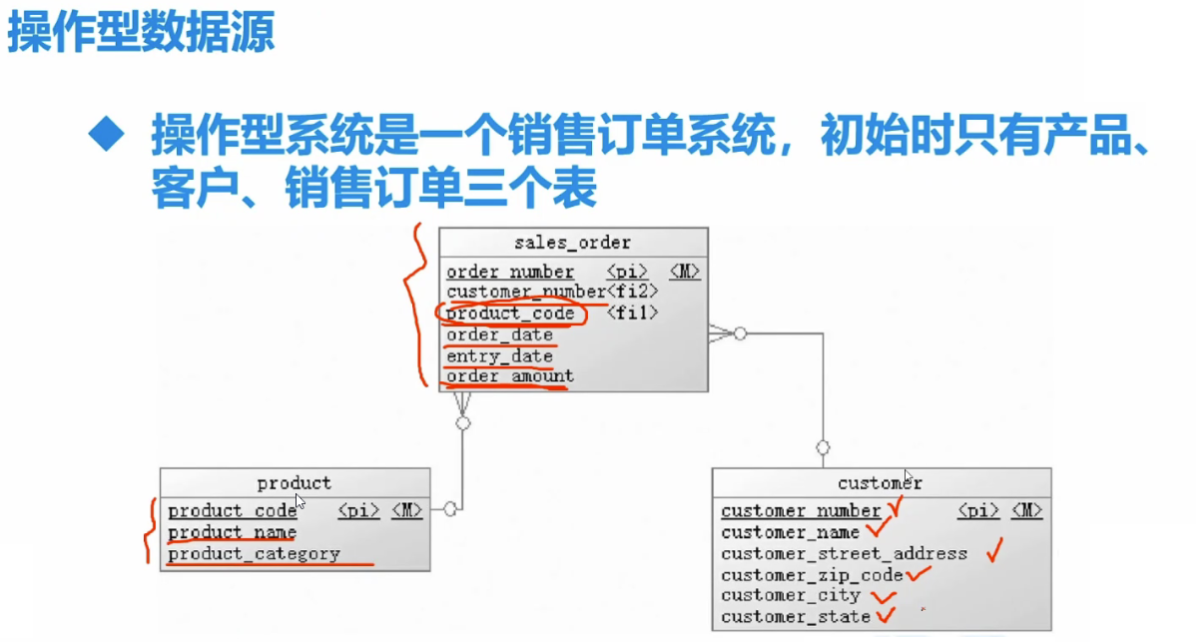
/***************************************************** create database sales_source ******************************************************/ drop database if exists sales_source; create database sales_source default charset utf8 collate utf8_general_ci; use sales_source; /***************************************************** create table ******************************************************/ -- Table:Customer drop table if exists Customer; create table customer( customer_number int primary key not null auto_increment, customer_name varchar(32) not null, customer_street_address varchar(256) not null, customer_zip_code int not null, customer_city varchar(32) not null, customer_state varchar(32) not null ); -- Table:Product drop table if exists product; create table product( product_code int primary key not null auto_increment, product_name varchar(128) not null, product_category varchar(32) not null ); -- Table:Sales_order drop table if exists sales_order; create table sales_order( order_number int primary key not null auto_increment, customer_number int not null, product_code int not null, order_date date not null, entry_date date not null, order_amount int not null ); -- add constraint alter table sales_order add constraint fk_cust_order foreign key (customer_number) references customer(customer_number); alter table sales_order add constraint fk_product_order foreign key (product_code) references product(product_code);
/************************************************* insert data ***********************************************/ -- insert customer insert into customer ( customer_name,customer_street_address,customer_zip_code, customer_city,customer_state ) values ('Big Customers','7500 Louise Dr.',17050,'Mechanicsbrg','PA'), ('Small Stroes','2500 Woodland St.',17055,'Pittsubtgh','PA'), ('Medium Retailers','1111 Ritter Rd.',17055,'Pittsubtgh','PA'), ('Good Companies','9500 Scott St.',17050,'Mechanicsbrg','PA'), ('Wonderful Shops','3333 Rossmoyne Rd.',17050,'Mechanicsbrg','PA'), ('Loyal Clients','7070 Ritter Rd.',17055,'Mechanicsbrg','PA'); -- insert product insert into product (product_name,product_category) values ('Hard Disk','Storage'), ('Floppy Driver','Storage'), ('Icd panel','monitor'); -- insert sales_orders -- customer_numer int,product_code int,order_date,entry_date,order_amount drop procedure if exists proc_generate_saleorder; delimiter $$ create procedure proc_generate_saleorder() begin -- create temp table drop table if exists temp; create table temp as select * from sales_order where 1=0; -- declare var set @begin_time := unix_timestamp('2018-1-1'); set @over_time := unix_timestamp('2018-11-23'); set @i :=1; while @i <= 100000 do set @cust_number := floor(1+rand()*6); set @product_code := floor(1+rand()*3); set @tmp_data := from_unixtime(@begin_time+rand()*(@over_time-@begin_time)); set @amount := floor(1000+rand()*9000); insert into temp values(@i,@cust_number,@product_code,@tmp_data,@tmp_data,@amount); set @i := @i+1; end while; -- clear sales_orders truncate table sales_order; insert into sales_order select null,customer_number,product_code,order_date,entry_date,order_amount from temp; commit; drop table temp; end$$ delimiter ; call proc_generate_saleorder();
PS:
1.为什么要用constraint约束? 详见 => https://www.cnblogs.com/sabertobih/p/13966709.html
2.为什么存储过程中涉及批量插表的时候要用到临时表?
- 已知commit一次是从内存表到物理表的过程,用不用临时表有什么不一样?
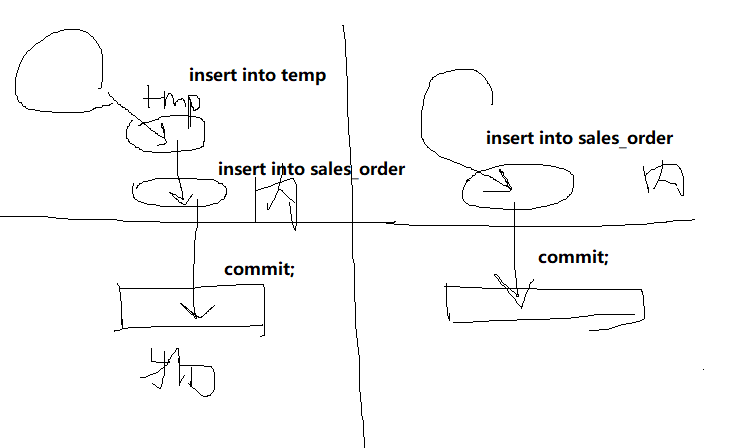
- 答:关键在于temp表是新create的表,对于新create的表,insert into是在内存里完成;
- 而对于早就存在的表,mysql默认每次insert语句都是一次commit,所以右上图是不正确的,应该是commit了100000次。
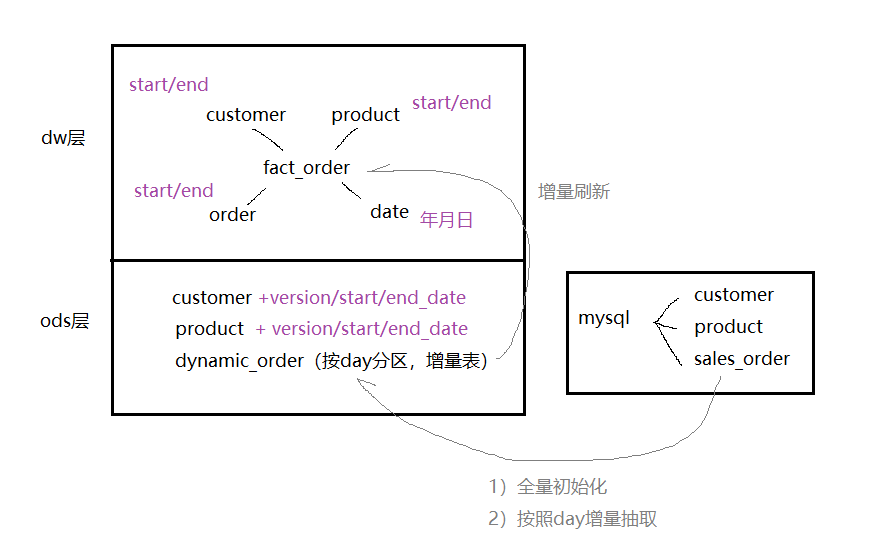
(2)在Hive中创建源数据过渡区和数据仓库的表
关于本案例中,hive的主键问题:
>>> 因为数据来源于数据库,天生自带主键当作sk,不用自己生成
>>> 否则,需要使用 row_number/ uuid/ md5生成主键,见 https://www.cnblogs.com/sabertobih/p/14031047.html
inithive.sql => 创建hive表!
drop database if exists ods_sales_source cascade; create database ods_sales_source; use ods_sales_source; drop table if exists ods_product; create table ods_product( product_code string, product_name string, product_category string, version string, ods_start_time string, ods_end_time string ) row format delimited fields terminated by '\u0001'; drop table if exists ods_customer; create table ods_customer( customer_number string, customer_name string, customer_street_address string, customer_zip_code string, customer_city string, customer_state string, version string, ods_start_time string, ods_end_time string ) row format delimited fields terminated by '\u0001'; drop table if exists ods_origin_sales_order; create table ods_origin_sales_order( order_number string, customer_number string, product_code string, order_date string, order_amount string ); drop table if exists ods_dynamic_sales_order; create table ods_dynamic_sales_order( order_number string, customer_number string, product_code string, order_date string, order_amount string ) partitioned by (ymd string);
import_hive.sh => 直接执行,直接实现从创表到自动从mysql中insert语句到hive
#! /bin/bash if [ $# = 0 ];then hive -f /opt/data/inithive.sql fi echo "import ods_product..."; #global import product sqoop import \ --connect jdbc:mysql://192.168.56.111:3306/sales_source \ --driver com.mysql.jdbc.Driver \ --username root \ --password root \ --query "select product_code,product_name,product_category,'1.0' as version,'2018-1-1' as ods_start_time,'9999-12-31' as ods_end_time from product where 1=1 and \$CONDITIONS" \ --target-dir /mytmp/ods/pro \ --hive-import \ --hive-database ods_sales_source \ --hive-table ods_product \ --hive-overwrite \ -m 1 echo "import ods_customer..."; #global import customer sqoop import \ --connect jdbc:mysql://192.168.56.111:3306/sales_source \ --driver com.mysql.jdbc.Driver \ --username root \ --password root \ --query "select customer_number,customer_name,customer_street_address,customer_zip_code,customer_city,customer_state,'1.0' as version,'2018-1-1' as ods_start_time,'9999-12-31' as ods_end_time from customer where 1=1 and \$CONDITIONS" \ --hive-import \ --target-dir /mytmp/ods/cust \ --hive-database ods_sales_source \ --hive-table ods_customer \ --hive-overwrite \ -m 1
(3)日期维度的数据装载
如何自动导入分区表?
方法一(不推荐):使用sqoop手动分区,注意sqoop partition不可以带有特殊符号,日期只可以%Y%m%d
echo "import sales_order..." #increment import sales_order #partition day=1 md=`date -d '2018-10-23' +%j` while [ $day -lt $md ] do mdd=`date -d "2018-1-1 +$day day" +%Y%m%d` hive -e "use ods_sales_source;alter table ods_start_order add partitioned(ymd=$mdd)" sqoop import \ --connect jdbc:mysql://192.168.56.111:3306/sales_source \ --driver com.mysql.jdbc.Driver \ --username root \ --password root \ --query "select order_number,customer_number,product_code,order_date,order_amount from sales_order where date_format(order_date,'%Y%m%d')=$mdd and \$CONDITIONS" \ --target-dir /mytmp/so \ --delete-target-dir --hive-import \ --hive-database ods_sales_source \ --hive-table ods_sales_order \ --hive-partition-key "ymd" \ --hive-partition-value "$mdd" \ -m 1 let day=$day +1 done
方法二:使用hive动态分区,先在hive中导入一个全量表,再从全量表==动态分区==>导入分区表
# 全量导入 echo "import ods_origin_sales_order..." sqoop import \ --connect jdbc:mysql://192.168.56.111:3306/sales_source \ --driver com.mysql.jdbc.Driver \ --username root \ --password root \ --query "select order_number,customer_number,product_code,order_date,order_amount from sales_order where \$CONDITIONS" \ --hive-import \ --target-dir /mytmp/ods/so \ --hive-database ods_sales_source \ --hive-table ods_origin_sales_order \ --hive-overwrite \ -m 1 echo "import dynamic..." hive -f /opt/data/dynamic.sql
-- 动态分区自动导入 use ods_sales_source; set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; set hive.exec.max.dynamic.partitions.pernode=10000; set hive.exec.max.dynamic.partitions.pernode.Maximum=10000; set hive.exec.max.dynamic.partitions=10000; set hive.exec.max.created.files=10000; insert into ods_dynamic_sales_order partition(ymd) select order_number,customer_number,product_code,order_date,order_amount, date_format(order_date,'yyyyMMdd') as ymd from ods_origin_sales_order;
(4)数据的ETL
(二)DW层

(1)SQL:建dw层表语句
可以看到只有一张customer表,一张product表,说明给的数据是已经聚合后的!
createdwdinit.sql
-- 建表语句 -- 其中date表是外部表,且以textfile形式存储,方便映射数据 drop database if exists DW_SALES_SOURCE cascade; create database dw_sales_source; use dw_sales_source; drop table if exists dwd_dim_customer; create table dwd_dim_customer( customer_sk int, customer_number int, customer_name string, customer_street_address string, custom_zip_code string, customer_city string, customer_state string, version string, effectice_date string, expiry_date string ) row format delimited fields terminated by ',' stored as parquetfile; drop table if exists dwd_dim_product; create table dwd_dim_product( product_sk int, product_code int, product_name string, product_category string, version string, effectice_date string, expiry_date string ) row format delimited fields terminated by ',' stored as parquetfile; drop table if exists dwd_dim_order; create table dwd_dim_order( order_sk int, order_number int, version string, effectice_date string, expiry_date string ) row format delimited fields terminated by ',' stored as parquetfile; drop table if exists dwd_dim_date; create external table dwd_dim_date( date_sk int, d_date string, d_month int, d_month_name string, d_quarter int, d_year int ) row format delimited fields terminated by ',' stored as textfile location '/opt/dwdate'; drop table if exists dwd_fact_sales_order; create table dwd_fact_sales_order( order_sk int, customer_sk int, product_sk int, date_sk int, order_amount float ) row format delimited fields terminated by ',' stored as parquetfile;
(2)SQL:ods层导入dw层数据:customer/product/order
dwd_import.sql
insert into dw_sales_source.dwd_dim_customer select customer_number as customer_sk, customer_number, customer_name , customer_street_address , customer_zip_code , customer_city , customer_state , version , ods_start_time as effectice_date, ods_end_time as expiry_date from ods_sales_source.ods_customer; insert into dw_sales_source.dwd_dim_product select product_code as product_sk, product_code , product_name , product_category , version, ods_start_time as effectice_date, ods_end_time as expiry_date from ods_sales_source.ods_product; insert into dw_sales_source.dwd_dim_order select order_number as order_sk, order_number, '1.0' as version, order_date as effectice_date, '9999-12-31' as expiry_date from ods_sales_source.ods_dynamic_sales_order
(3)脚本文件,生成date数据,导入dwd_fact_sales_order表
#!/bin/bash #创建dw层 echo '***********************************' echo 'create dw layout data table...' echo '***********************************' hive -f /opt/data/dw/createdwdinit.sql echo '***********************************' echo 'import data...' echo '***********************************' hive -f /opt/data/dw/dwd_import.sql echo '***********************************' echo 'generating dwd_date data...' echo '***********************************'
## hdfs判断是否有文件或目录 targetfilename=/opt/dwdate hdfs dfs -test -e $targetfilename if [ $? -eq 0 ] ;then echo 'exist' hdfs dfs -rm -R $targetfilename fi
## linux判断是否有文件 filename=/opt/data/tmp if [ -e $filename ]; then rm -rf $filename fi touch $filename num=0 while(( $num<365 )) do dt=`date -d "2018-01-01 $num days" +%Y-%m-%d` mtname=`date -d "${dt}" +%B` mt=`date -d "${dt}" +%m` if [ $mt -le 3 ]; then qt=1 elif [ $mt -le 6 ]; then qt=2 elif [ $mt -le 9 ]; then qt=3 else qt=4 fi let num=$num+1 echo "${num},${dt},${dt:5:2},$mtname,$qt,${dt:0:4}" >> $filename #hive -e'insert into dw_sales_source.dwd_dim_date values($num+1,${dt},${dt:5:2},$mtname,$qt,${dt:0:4})' done echo "date data从本地移动到hdfs" hdfs dfs -rm -R /opt/dwdate hdfs dfs -mkdir -p /opt/dwdate hdfs dfs -put /opt/data/tmp /opt/dwdate echo '***********************************' echo 'import fact_sales_order data...' echo '***********************************' hive -e 'insert into dw_sales_source.dwd_fact_sales_order select oso.order_number as order_sk, oso.customer_number as customer_sk, oso.product_code as product_sk, dss.date_sk as date_sk, oso.order_amount as order_amount from
ods_sales_source.ods_dynamic_sales_order oso inner join dw_sales_source.dwd_dim_date dss on oso.order_date = dss.d_date'
(三)DM层
(1)如何形成宽表?
① 需求:
>>>
当天-> 顾客,产品,日期,订单个数,当天金额 && 近两天 -> 订单个数,近两天金额
<<<
② 调优见:https://www.cnblogs.com/sabertobih/p/14041854.html
③ 代码:
dm_init.sql
drop database if exists dm_sales_source cascade; create database dm_sales_source; use dm_sales_source;
dm_run.sql
drop table if exists dm_sales_source.dm_sales_order_count; create table dm_sales_source.dm_sales_order_count as select dss.d_date,d.customer_sk,d.product_sk, count(d.order_sk) as order_num, sum(d.order_amount) as order_dailyamount, sum(sum(d.order_amount)) over(rows between 1 PRECEDING and current row) as recent_amount, sum(count(d.order_sk)) over(rows between 1 PRECEDING and current row) as recent_num from dw_sales_source.dwd_fact_sales_order d inner join dw_sales_source.dwd_dim_date dss on d.date_sk = dss.date_sk group by dss.d_date,d.customer_sk,d.product_sk order by dss.d_date
init.sh
#!/bin/bash hive -f /opt/data/dm/dm_init.sql hive -f /opt/data/dm/dm_run.sql
(2)sqoop从hdfs导出mysql(如果是orc等压缩格式,老实用Java!)
① sqoop:适用于textffile
如何查看某个table存放在hdfs什么地方? show create table dm_sales_source.dm_sales_order_count;

!hdfs dfs -text /hive110/warehouse/dm_sales_source.db/dm_sales_order_count/000000_0
mysql中:
drop database if exists dmdb ; create database dmdb; use dmdb; create table dm_sales_order_count( d_date varchar(20), customer_sk int, product_sk int, order_num int, order_dailyamount double, recent_amount double, recent_num int );
然后sqoop从hdfs到mysql
mysql到hive,hive-> hdfs -> mysql,都需要 ‘\001’
sqoop export \ --connect jdbc:mysql://192.168.56.111:3306/dmdb \ --username root \ --password root \ --table dm_sales_order_count \ --export-dir /hive110/warehouse/dm_sales_source.db/dm_sales_order_count \ --input-fields-terminated-by '\001' \ -m 1
② Java方法:万能!
见:https://www.cnblogs.com/sabertobih/p/14043929.html
(3)如何暴露接口?
见:https://www.cnblogs.com/sabertobih/p/14043895.html
三、数据仓库之 更新数据