Sqoop 之 操作
一、sqoop作用?
1.sqoop是一个数据交换工具,最常用的两个工具是导入导出。
导入导出的参照物是hadoop,向hadoop导数据就是导入。
- RDBMS <-> Hadoop(HDFS/HIVE/HBASE)
2.命令翻译成MapReduce并行操作,如何确认数据没有丢失?
- wc -l 显示行数。
- 统计count两边数据一致
二、sqoop的版本?
sqoop目前有两个版本,1.4.X为sqoop1;1.99.X为sqoop2。两个版本不兼容。
三、使用sqoop列出mysql下的所有数据库
复制代码
(my_python_env)[root@hadoop26 ~]#
sqoop list-databases --connect jdbc:mysql://localhost:3306 --username root --password 123456
information_schema
hive
mysql
test
复制代码
四、Import工具的使用
4.1将mysql中的某张表导入到hdfs上,现在test下有一张person表
4.2执行sqoop语句
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 -table person
4.3在hdfs用户的家目录下,产生了一个person文件夹
复制代码
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls
Found 2 items
drwx------ - root supergroup 0 2016-07-03 23:00 .Trash
drwxr-xr-x - root supergroup 0 2016-07-21 22:30 person
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person
Found 3 items
-rw-r--r-- 1 root supergroup 0 2016-07-21 22:30 person/_SUCCESS
-rw-r--r-- 1 root supergroup 17 2016-07-21 22:30 person/part-m-00000
-rw-r--r-- 1 root supergroup 12 2016-07-21 22:30 person/part-m-00001
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person/part-*
1,zhangsan,false
2,lisi,true
复制代码
4.4 delete-target-dir参数
当再次执行sqoop语句的时候,会报错,因为person文件夹已经存在了,我们需要先删除这个文件夹再运行sqoop语句。
也可以使用sqoop提供的delete-target-dir参数
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 -table person --delete-target-dir
4.5 append参数
如果目标文件夹在hdfs上已经存在,那么再次运行就会报错。可以使用--delete-target-dir来先删除目录。也可以使用append来往目录下追加数据。append和delete-target-dir是相互冲突的。
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table person --append
执行完成后,查看hdfs上的文件
复制代码
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person
Found 5 items
-rw-r--r-- 1 root supergroup 0 2016-07-21 22:50 person/_SUCCESS
-rw-r--r-- 1 root supergroup 17 2016-07-21 22:50 person/part-m-00000
-rw-r--r-- 1 root supergroup 12 2016-07-21 22:50 person/part-m-00001
-rw-r--r-- 1 root supergroup 17 2016-07-21 23:48 person/part-m-00002
-rw-r--r-- 1 root supergroup 12 2016-07-21 23:48 person/part-m-00003
复制代码
4.6 target-dir参数
上述的所有操作都是吧mysql中的数据写到一个默认的目录下,可以使用target-dir来指定hdfs的目录名
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table person --append --target-dir person-mysql
查看hdfs上的目录
复制代码
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls
Found 4 items
drwx------ - root supergroup 0 2016-07-03 23:00 .Trash
drwxr-xr-x - root supergroup 0 2016-07-21 23:53 _sqoop
drwxr-xr-x - root supergroup 0 2016-07-21 23:48 person
drwxr-xr-x - root supergroup 0 2016-07-21 23:53 person-mysql
复制代码
4.7 map的个数
现在mysql表person中的数据增加到了11条
再次执行sqoop语句来导入
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --table person --target-dir person-mysql
查看hdfs上的目录
复制代码
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person-mysql
Found 5 items
-rw-r--r-- 1 root supergroup 0 2016-07-21 23:59 person-mysql/_SUCCESS
-rw-r--r-- 1 root supergroup 41 2016-07-21 23:59 person-mysql/part-m-00000
-rw-r--r-- 1 root supergroup 35 2016-07-21 23:59 person-mysql/part-m-00001
-rw-r--r-- 1 root supergroup 24 2016-07-21 23:59 person-mysql/part-m-00002
-rw-r--r-- 1 root supergroup 37 2016-07-21 23:59 person-mysql/part-m-00003
复制代码
从上面的结果可以发现,这个作业启动了4个map任务,所以sqoop默认配置就是4个map,用户也可以通过-m参数,自己指定map的数量
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --table person --target-dir person-mysql -m 1
查看hdfs上的目录发现,这次只启动了一个map任务
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person-mysql
Found 2 items
-rw-r--r-- 1 root supergroup 0 2016-07-22 00:02 person-mysql/_SUCCESS
-rw-r--r-- 1 root supergroup 137 2016-07-22 00:02 person-mysql/part-m-00000
4.8 where参数
where参数可以进行一些简单的筛选
sqoop import --connect jdbc:mysql://localhost:3306/test --where "gender=0" --username root --password 123456 --delete-target-dir --table person --target-dir person-mysql -m 1
复制代码
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person-mysql/part*
1,zhangsan,false
3,003,false
4,004,false
6,006,false
7,007,false
8,008,false
9,009,false
11,011,false
复制代码
4.9 query/columns过滤
query参数就可以让用户随意写sql语句来查询了。query和table参数是互斥的。
query+where >> 必须加 $CONDITIONS
sqoop import --connect jdbc:mysql://localhost:3306/test --query "select * from person where name='003' and gender=0 and \$CONDITIONS" 或者 --columns "order_id,order_date" --username root --password 123456 --delete-target-dir --target-dir person-mysql -m 1
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person-mysql/part-*
3,003,false
4.10 压缩
如果想要使得导入到hdfs上的数据被压缩,就可以使用-z或者--compression-codec来进行压缩,-z压缩方式是gzip压缩,--compression-codec可以自定义压缩方式
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --target-dir person-mysql -m 1 --table person -z
查看hdfs上的结果:
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person-mysql
Found 2 items
-rw-r--r-- 1 root supergroup 0 2016-07-22 00:38 person-mysql/_SUCCESS
-rw-r--r-- 1 root supergroup 99 2016-07-22 00:38 person-mysql/part-m-00000.gz
使用Snappy方式压缩
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --target-dir person-mysql -m 1 --table person --compression-codec org.apache.hadoop.io.compress.SnappyCodec
4.11 空值处理
像如图id=12的记录是没有name和gender的,如果不加处理,导入到hdfs上是这样子的:
复制代码
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person-mysql/part*
1,zhangsan,false
2,lisi,true
3,003,false
4,004,false
5,005,true
6,006,false
7,007,false
8,008,false
9,009,false
10,010,true
11,011,false
12,null,null
复制代码
sqoop提供了--null-string来处理字符类型的空值,提供了--null-non-string来处理非字符类型的空值。
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --target-dir person-mysql -m 1 --table person --null-string "" --null-non-string "false"
执行结果是:
复制代码
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person-mysql/part*
1,zhangsan,false
2,lisi,true
3,003,false
4,004,false
5,005,true
6,006,false
7,007,false
8,008,false
9,009,false
10,010,true
11,011,false
12,,false
复制代码
4.12 --split-by 按字段分区
-
--m设置mapper的数量。通过这两个参数分解生成m个where子句,进行分段查询。因此sqoop的split可以理解为where子句的切分。
- 所以即使没有where子句,为了使用mapper分区,需要 where 1 =1 and \$CONDITIONS
sqoop import \ --connect jdbc:mysql://192.168.56.111:3306/test \ --driver com.mysql.jdbc.Driver \ --query "select * from scores where 1=1 and \$CONDITIONS" \ --split-by project \ --username root \ --password root \ --delete-target-dir \ --target-dir /mytmp/datas/test2 \ -m 3
问题:使用project列分区出现问题:part-m-00000和00002有值,00001没值,发生数据倾斜
解决:加盐列,--split-by hs
select * from ( select a.*,u.name ,concat(a.userid,'-',u.name) as hs from (select userid , max(case project when 'chinese' then score else 0 end ) 'chinese' , max(case project when 'math' then score else 0 end ) 'math' from scores group by userid) a inner join user u on a.userid=u.userid ) s
where 1=1 and \$CONDITIONS
4.13 增量导入

举例:给pet表增加一条数据
insert into pet(petName,petBreed,petSex,birthday,description)
values('笨蛋',2,2,now(),'123')
sqoop import \ --connect jdbc:mysql://192.168.56.111:3306/test \ --driver com.mysql.jdbc.Driver \ --table pet \ --username root \ --password root \ --incremental append \ --check-column birthday \ --last-value '2020-07-20' \ --target-dir /mytmp/datas/orders \ -m 1
验证:hdfs dfs -text /mytmp/datas/orders/part-*

Question:场景:今天是12号凌晨1点,请问last-vaue写多少?
-Answer: 12号凌晨可以获得11号的完整数据,所以取10号以后的所有数据append到HDFS的11号文件夹(分区)中
优化:写进shell脚本
shell关于时间的操作:https://www.cnblogs.com/Gxiaobai/p/11197677.html
tm=`date -d"2 day ago ${date}" +%Y-%m-%d` sqoop import \ --connect jdbc:mysql://192.168.56.111:3306/test \ --driver com.mysql.jdbc.Driver \ --table pet \ --username root \ --password root \ --incremental append \ --check-column birthday \ --last-value '$tm' \ --target-dir /mytmp/datas/orders \ -m 1
4.14 导入导出
-- 文件格式
- --as-textfile # text
- --as-avrodatafile # avro
- --as-sequencefile # sequence
- --as-parquetfile # parquet
ORC和PARQUET是基于列式存储的
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;并且SEQUENCEFILE是存储为二进制文件
读写测试链接:https://blog.csdn.net/weixin_36714575/article/details/80091578
结论:建议工作中原始日志写入hive的存储格式都采用ORC或者parquet格式,这和目前主流的做法一致。
-- 从HDFS导入hive
# 创建外部表 create external table pet( petId BIGINT, petName STRING, petBreed INT, petSex INT, birthday TIMESTAMP , description STRING ) row format delimited fields terminated by ',' lines terminated by '\n' load data inpath '/mytmp/datas/test1' overwrite into table pet # 1-16条 load data inpath '/mytmp/datas/orders' into table pet # 第17条
-- 从mysql 直接导入hive
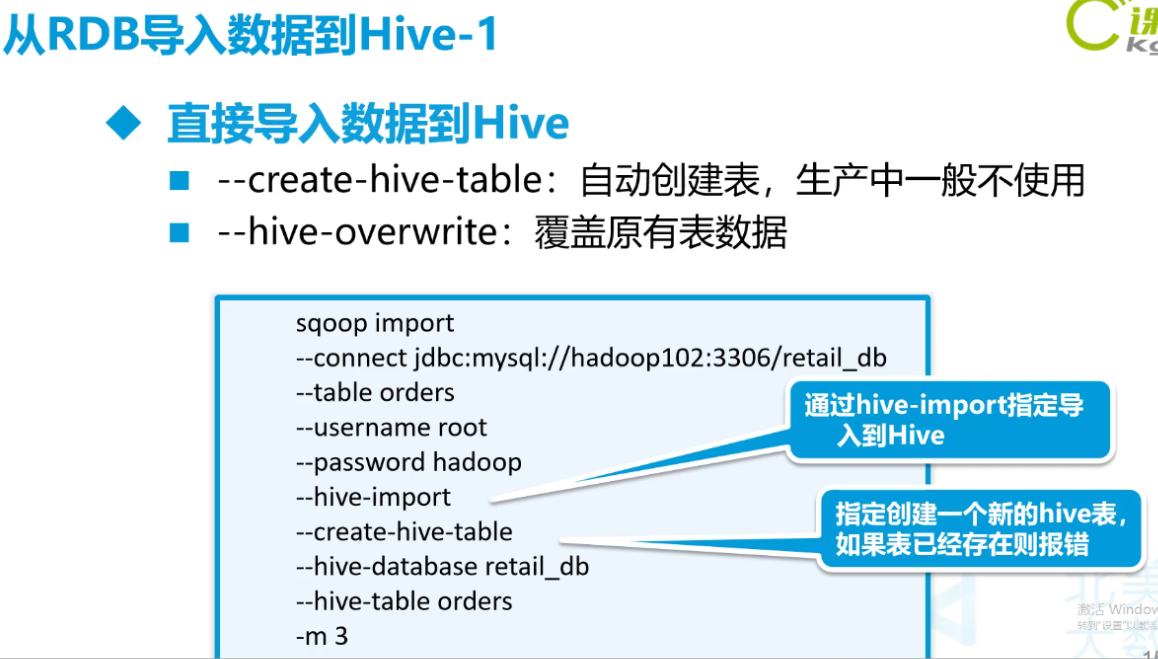
# 创建hive内部表 create table pet_internal( petId BIGINT, petName STRING, petBreed INT, petSex INT, birthday TIMESTAMP , description STRING ) row format delimited fields terminated by '\u0001' lines terminated by '\n' sqoop import \ --connect jdbc:mysql://192.168.56.111:3306/test \ --driver com.mysql.jdbc.Driver \ --table pet \ --username root \ --password root \ --hive-import \ --hive-database default \ --hive-table pet_internal \ -m 3 ## 每失败一次,都需要删除一次hdfs上的目录 hdfs dfs -rm -R /user
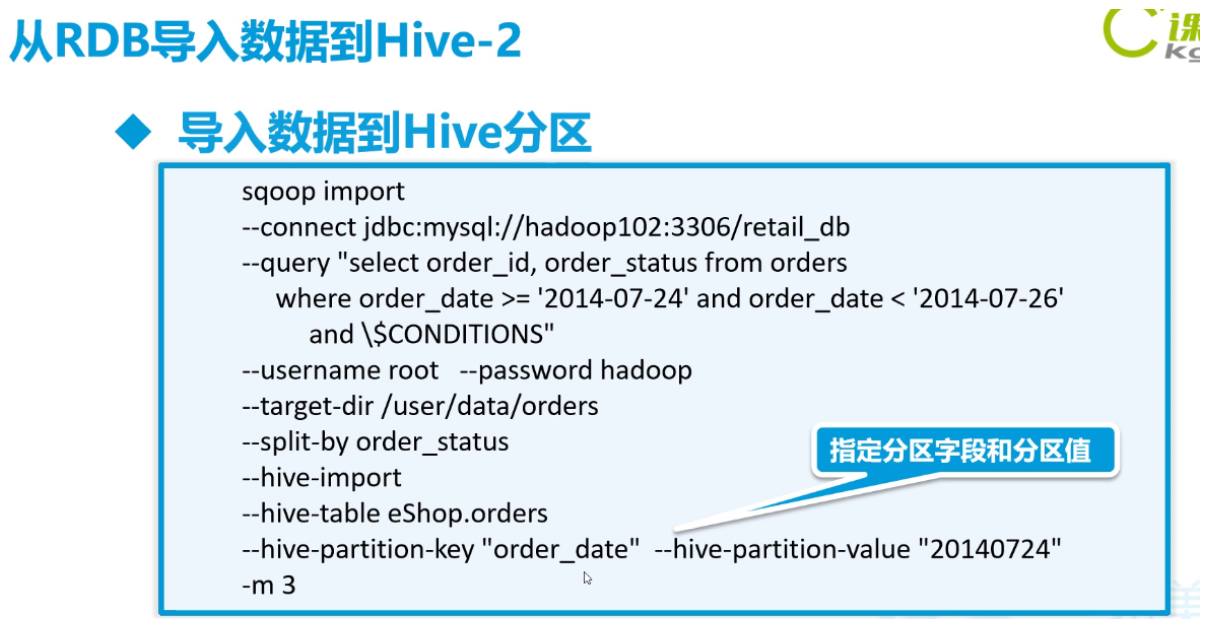
-- 从mysql导入到hive分区
## target-dir 不指定会报错,指定后路径无效,进入默认路径
>>>

## mysql中 +-------+------------+ | ordid | orderdate | +-------+------------+ | 1 | 2020-11-10 | | 2 | 2020-11-11 | | 3 | 2020-11-11 | | 4 | 2020-11-09 | | 5 | 2020-11-09 | | 6 | 2020-11-09 | +-------+------------+ ## 创建hive分区表 create table orderinfos( orderid STRING, userid STRING ) partitioned by (orddate STRING) ## 添加静态分区 hive中: alter table orderinfos add partition (orddate='20201110'); 在外面添加分区:hive -e "use mydemo;alter table orderinfos add partition (orddate='20201111');" sqoop import \ --connect jdbc:mysql://192.168.56.111:3306/test \ --driver com.mysql.jdbc.Driver \ --query "select * from orders where orderdate = '2020-11-10' and \$CONDITIONS" \ --username root \ --password root \ --delete-target-dir \ --hive-import \ --hive-database default \ --hive-table orderinfos \ --hive-partition-key 'orddate' \ ## hive分区字段 --hive-partition-value '20201110' \ ## hive分区字段具体值 --target-dir /mytmp/orderinfos \ -m 1
-- 从HDFS导入Mysql
sqoop export \ --connect jdbc:mysql://192.168.56.111:3306/test \ --username root \ --password root \ --table pet_testsqoop \ --m 1 \ --export-dir /mytmp/datas/test1 \ --input-fields-terminated-by "," create table pet_testsqoop(petId bigint(20) primary key not null,petName VARCHAR(20) not null,petBreed INT NOT NULL,petSex INT NOT NULL,birthday TIMESTAMP NOT NULL,description VARCHAR(200))
