机器学习 之 聚类 之 K-means算法
一、聚类定义
- 聚类分析(cluster analysis)就是给你一堆杂七杂八的样本数据把它们分成几个组,组内成员有一定的相似,不同组之间成员有一定的差别。
- 区别与分类分析(classification analysis) 你事先并不知道有哪几类、划分每个类别的标准。
- 比如垃圾分类就是分类算法,你知道猪能吃的是湿垃圾,不能吃的是干垃圾……;打扫房间时你把杂物都分分类,这是聚类,你事先不知道每个类别的标准。
二、划分聚类方法: K-means:
对于给定的样本集,按照样本之间的距离(也就是相似程度)大小,将样本集划分为K个簇(即类别)。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
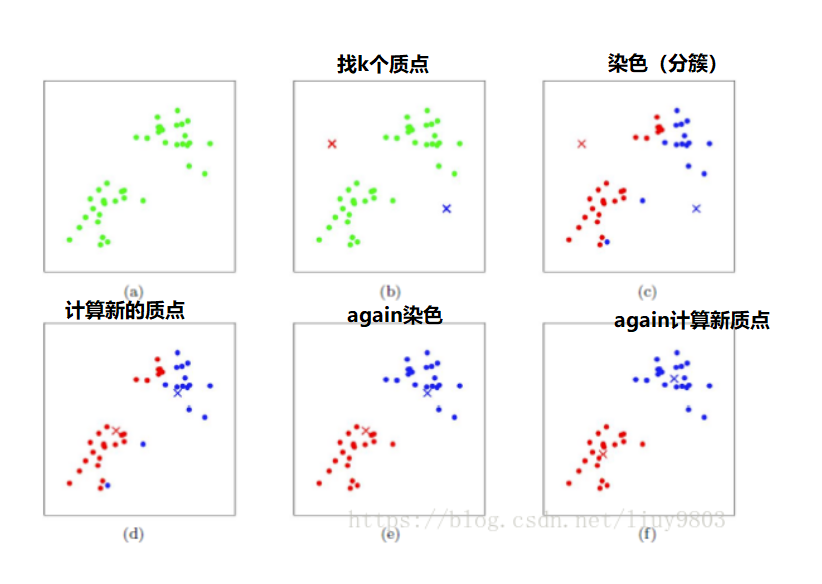
- 步骤1:随机取k个初始中心点
- 步骤2:对于每个样本点计算到这k个中心点的距离,将样本点归到与之距离最小的那个中心点的簇。这样每个样本都有自己的簇了
- 步骤3:对于每个簇,根据里面的所有样本点重新计算得到一个新的中心点,如果中心点发生变化回到步骤2,未发生变化转到步骤4
- 步骤4:得出结果