spark Graphx 之 Connected Components
一、Connected Components算法
Connected Components即连通体算法用id标注图中每个连通体,将连通体中序号最小的顶点的id作为连通体的id。如果在图G中,任意2个顶点之间都存在路径,那么称G为连通图,否则称该图为非连通图,则其中的极大连通子图称为连通体,如下图所示,该图中有两个连通体:
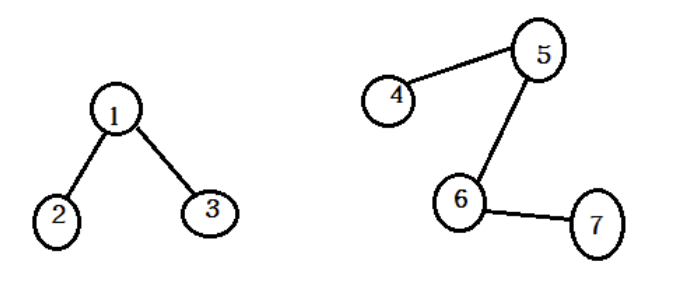
二、示例
followers.txt (起点id,终点id)
4 1 1 2 6 3 7 3 7 6 6 7 3 7
users.txt (id,first name,full name)
1,BarackObama,Barack Obama 2,ladygaga,Goddess of Love 3,jeresig,John Resig 4,justinbieber,Justin Bieber 6,matei_zaharia,Matei Zaharia 7,odersky,Martin Odersky 8,anonsys
import org.apache.spark.graphx.{Graph, GraphLoader, VertexId, VertexRDD} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Connected_Components { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local") val sc: SparkContext = new SparkContext(conf) //读取followers.txt文件创建图 val graph: Graph[Int, Int] = GraphLoader.edgeListFile(sc,"src/main/resources/connected/followers.txt") //计算连通体 val components: Graph[VertexId, Int] = graph.connectedComponents() val vertices: VertexRDD[VertexId] = components.vertices /** * vertices: * (4,1) * (1,1) * (6,3) * (3,3) * (7,3) * (2,1) * 是一个tuple类型,key分别为所有的顶点id,value为key所在的连通体id(连通体中顶点id最小值) */ //读取users.txt文件转化为(key,value)形式 val users: RDD[(VertexId, String)] = sc.textFile("src/main/resources/connected/users.txt").map(line => { val fields: Array[String] = line.split(",") (fields(0).toLong, fields(1)) }) /** * users: * (1,BarackObama) * (2,ladygaga) * (3,jeresig) * (4,justinbieber) * (6,matei_zaharia) * (7,odersky) * (8,anonsys) */ users.join(vertices).map{ case(id,(username,vertices))=>(vertices,username) }.groupByKey().map(t=>{ t._1+"->"+t._2.mkString(",") }).foreach(println(_)) /** * 得到结果为: * 1->justinbieber,BarackObama,ladygaga * 3->matei_zaharia,jeresig,odersky */ } }
最终计算得到这个关系网络有两个社区。

