Java正则匹配之 淘宝信息爬取
爬取页面分析:
1)每件商品以?开头,以?结尾
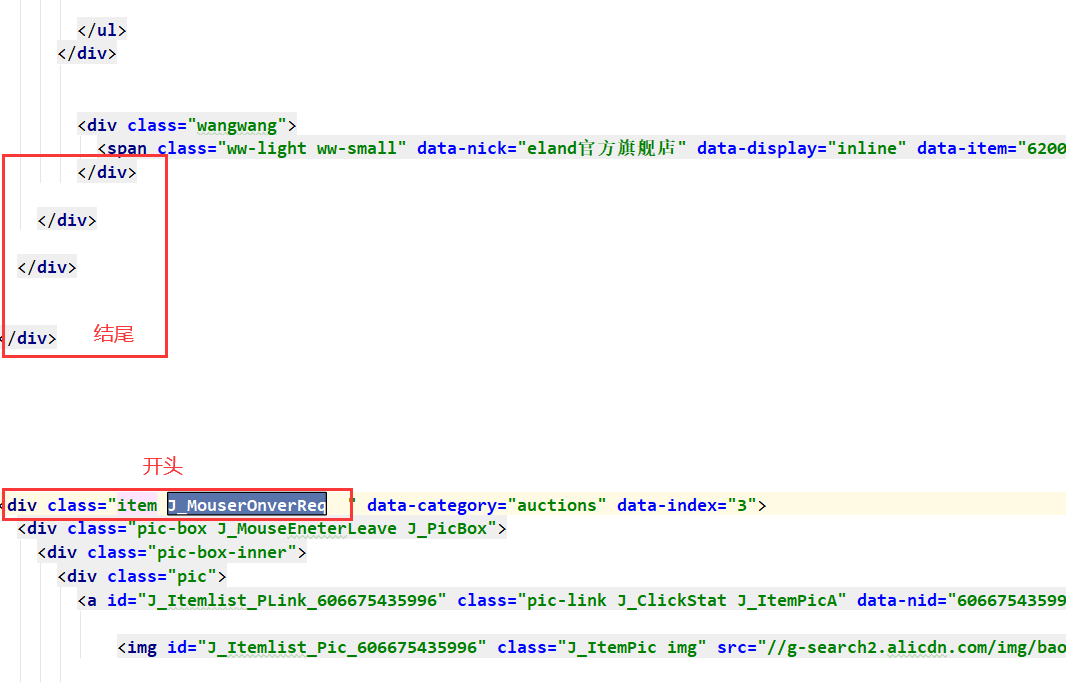
2) 商品中有用的数据为

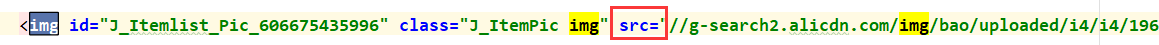

一、工具类 DataCenter
package cn.kgc.regex.file; import java.io.*; import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; public class DataCenter { // 每一个商品中有一个list的数据 private List<List<String>> list = new ArrayList<>(); // 文件解析到String public StringBuilder combine(String file){ BufferedReader br = null; StringBuilder builder = new StringBuilder(); try { br = new BufferedReader(new FileReader(file)); String line = null; while (null != (line=br.readLine())){ if((line=line.trim()).length()==0){ continue; } builder.append(line); } } catch (Exception e) { e.printStackTrace(); return null; } finally { if (null != br) { try { br.close(); } catch (IOException e) { e.printStackTrace(); } } } return builder; } // 页面筛选之 商品筛选 public List<String> split(String regex, String src){ List<String> list = new ArrayList<>(); Matcher matcher = Pattern.compile(regex).matcher(src); while (matcher.find()){ list.add(matcher.group()); } return list; } // 商品解析 public void parse(String regex,String src){ List<String> list = new ArrayList<>(4); Matcher matcher = Pattern.compile(regex).matcher(src); if (matcher.find()) { list.add(matcher.group(1)); list.add(matcher.group(2)); list.add(matcher.group(3)); list.add(matcher.group(4)); list.add(matcher.group(5)); list.add(matcher.group(6)); list.add(matcher.group(7)); } this.list.add(list); } // 当作状态值,为了判断是否解析结束 public int getCount(){ return list.size(); } // 遍历输出展示 public void foreach(){ for (List<String> strs : list) { for (String str : strs) { System.out.print(str+"\t"); } System.out.println(); } } }
二、App类
package cn.kgc.regex; import cn.kgc.regex.file.DataCenter; import java.util.Iterator; import java.util.List; /** * Hello world! * */ public class App { public static void main( String[] args ) throws InterruptedException { DataCenter dc = new DataCenter(); // 1. 文件流读取到String中 String src = dc.combine("D:\\JAVA学习资料\\Java正则爬取信息\\regexdemo\\src\\main\\java\\cn\\kgc\\regex\\file\\tb-shirt.html") .toString(); // 2.regex1: 每一件商品,都在这种结构中 final String regex = "<div class=\"item J_MouserOnverReq .*?</div></div></div></div>"; // regex2:每一件商品中各种类型的数据在(.*?)中 final String regex2 = ".*?trace-nid=\"(.*?)\" .*? trace-price=\"(.*?)\" .*?><img.*?src=\"(.*?)\".*?alt=\"(.*?)\".*?<div class=\"deal-cnt\">(.*?)</div>.*?<div class=\"location\">(.*?)</div>.*?data-nick=\"(.*?)\".*?"; // list的size = 商品数量 List<String> split = dc.split(regex, src); // for (String s : split) { // System.out.println(s); // } Iterator<String> it = split.iterator(); while (it.hasNext()) { final String line = it.next(); // 3. 遍历商品,每一行(件)开一个线程匹配 new Thread(()->{ dc.parse(regex2,line); }).start(); } // 4. 状态值判定线程结束 while (dc.getCount()<split.size()){ Thread.sleep(200); } // 5. 多线程读取结束后遍历取值 dc.foreach(); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号