
数据表的操作
数据库表的操作
创建表
CREATE TABLE tab_name(
filed1 TYPE [约束条件], /*名字,类型,每项用逗号隔开*/
filed2 TYPE
);
约束条件:
PRIMARY KEY (非空且唯一,能够唯一区分当前内容的字段称之为主键)
UNIQUE
NOT NULL
AUTO_INCREMENT (主键字段必须为数字类型)
外键约束 foreign key
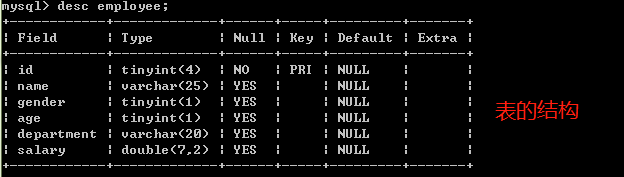
查看表
desc tab_name; /*查看表结构*/
show columns from tab_name; /*查看表结构*/
show tables; /*查看当前数据库中所有的表*/
show create table tab_name; /*查看创建表的代码语句*/
修改表的结构
增加字段
alter table tab_name add 列名 约束条件 [frist|after 字段名] /*把新增的字段放到某个字段前或后*/
增加多个字段
alter table tab_name add 列名1,
add 列名2;
删除字段
alter table tab_name drop 列名;
删除多个字段
alter table tab_name drop 列名1,
drop 列名2;
删除表
drop table tab_name;
修改字段
alter table tab_name modify 列名 类型 约束条件 first|after 字段名; -- 改类型
alter table tab_name change 列名 新列名 类型 约束条件 first|after 字段名; -- 改列名
修改表名
rename table 表名 to 新表名
修改表用的字符集
alter table tab_name character set utf8
删除主键
alter table tab_name modify 列名 类型;
alter table tab_name drop primary key; -- 两句合在一起才会生效
表记录的增删改查
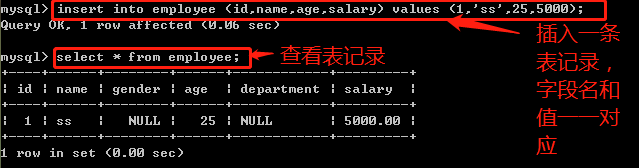
新增表记录
增加一条记录
insert [into] tab_name (filed1,filed2....) values (value1,value2,....);
注意字段名和值要一一对应
增加多条记录
insert [into] tab_name (filed1,filed2....) values (value1,value2,....),
(value1,value2,....);
/*多条记录用逗号隔开*/
set 插入
insert [into] tab_name set name=value; -- 通过键值对插入
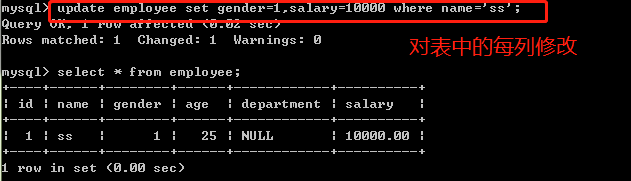
修改表记录
update tab_name set filed1=value1,filed2=value2,.... [where 语句];
update tab_name set filed1=filed1+value [where 语句];
/*
*update 可以将每行的各列更新新值替换原有的值
*也可以在原有的基础上再加减变动调整
*where 指定更新哪些行,如果不加where语句,则更新全部行
*/
删除表记录
delete from tab_name [where filed1=value1 or filed2=value2];
/*
*如果不加where语句,则删除整张表中的数据
*注意delete不能删除表,删除表用drop
*truncate table 也可以删除整张表的数据,此语句首先是摧毁表,再建新表,不可在事务中恢复
*/
查看表记录
select [distinct] *|filed1,field2... from tab_name;
-- 查看表记录,*代表所有
-- distinct代表剔除重复项,只展示表中值不同的行
select name,age+10 from tab_name;
select name as 姓名,age+10 as 年龄 from tab_name;
-- 将查询到的结果加10,注意只是显示出加10,库中的表数据还是原来的
-- 字段名 as 别名,将字段用别名显示出来
select * from tab_name where field1=value1;
-- 通过where语句过滤出符合的
/*
*where中的运算符
* 比较运算符:> < >= <= !=
* between value and value not between value and value
* in(value1,value2,...) not in 在指定的值中
* like 'ss%' not like% 搜索匹配含目标字符串的数据,%代表后面可有任意字符 _ 代表一个字符
* is null is not null 空值判断
* and not or 且 非 或
*/
在 sql 中 and 的操作符要比 or 的优先级高,因此会出现不理想的过滤结果
例:select school,age from tab_name where school = 'ss' or school = 'yy'' and age >= 15
这种情况下,sql会认为需筛选出school为ss的所有的数据,school为yy且age大于等于15的数据
相要修改上面的筛选结果,可以使用圆括号()调整优先级,这样就可以筛选出school 为ss或yy的age大于等于15的数据
select school,age from tab_name where (school = 'ss' or scholl = 'yy') and age >= 15
例:select age from tab_name where between 15 and 25;
--instr(源字符串,'目标字符串','开始位置','第几次出现') 查找目标字符串在源字符串是否存在,并返回位置。
后两个参数不写时默认为1,表示从源字符串第一个位置开始查找,目标字符串第一次出现的位置
没有查到返回 0,所以可以通过instr(,) > 0 过滤出含目标字符串的数据
例:select * from tab_name where instr(a.name,'ss') > 0
replace(a.name,substr(a.name,1,2),'*') --替换字符:字段,被替换的字符,新字符。substr提取字符,参数:字段,第几位开始,提多少个
order by 字段名 [asc|desc] -- 排序[正序|倒序]
例:select name from tab_name order by name;
group by -- 分组
注意:按照分组条件分组
后面接字段名
例:select name from tab_name group by name;
having语句,过滤符合条件的,分组后过滤
例:select name from tab_name group by name having sum(总成绩)>80;
-- 按 name 分组后,再过滤出总成绩大于80的
/*
*sum 聚合函数
*where语句可以用的地方,having也可以
*where是先过滤再计算,having是先分组再过滤
*where不能使用聚合函数
*/
case ... when ... then ... else ... end --什么条件下是什么,否则是什么,和其他语言的if...else类似
例:select case a.name when 'ss' then '1' when 'yy' then '2' else '3' end from tab_name a
也可以将字段名放在when里
select case when a.name = 'ss' then '1' when a.name = 'yy' then '2' else '3' end from tab_name a
聚合函数
count(字段名) -- 统计个数,注意它不能统计null
select count(ifnull(成绩,0)) from tab_name;
-- 如果要统计null,用ifnull将null转换成0
sum() -- 求和
avg() -- 平均值
max(),min() -- 不统计null
正则表达式查询
select * from tab_name where name RegExp '^ss';
外键约束
设置外键:在创建子表时
[CONSTRAINT 外键名] FOREIGN KEY (子表字段名) REFERENCES 主表名(主表字段名);
-- 注意:用外键约束的子表字段名要和关联的主表字段名数据类型相同
已经创建好表之后额外增加外键和删除外键
ALTER TABLE 子表名 ADD CONSTRAINT 外键名
FOREIGN KEY (子表字段名)
REFERENCES 主表名(主表字段名);
ALTER TABLE 表名 DROP FOREIGN KEY 外键名
外键作用:
对子表:在主表中找不到对应的候选键,则不允许update/insert
对主表:如果子表关联了主表的相应字段,则主表的这个字段不能update/delete
级联删除:
主子表关联时不能随便删除,可以在子表添加外键约束时
CONSTRAINT 外键名 FOREIGN KEY (子表字段名) REFERENCES 主表(主表字段名)
ON DELETE CASCADE;
-- 设置级联删除后,主表删除时会将子表的相应的也删除
SET NULL 方式:
外键约束加上:ON DELETE SET NULL;
-- 主表删除后,子表不会删除,但关联的相应字段会变成null
restrict方式:拒绝对主表删除操作
no action方式:在mysql中与restrict作用相同,拒绝对主表删除/更新操作
多表操作
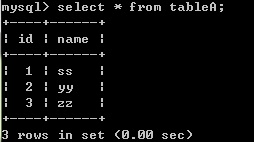
创建两张表
CREATE TABLE tableA( id TINYINT PRIMARY KEY AUTO_INCREMENT NOT NULL, name VARCHAR(25) ); CREATE TABLE tableB( id TINYINT PRIMARY KEY NOT NULL AUTO_INCREMENT, class VARCHAR(25), tA_id TINYINT );
INSERT INTO tableA (id,name) VALUES (1,'ss'), (2,'yy'), (3,'zz'); INSERT INTO tableB (class,tA_id) VALUES ('class1',2), ('class2',1), ('class3',4);
笛卡尔积查询:
select * from tableA,tableB;
将两张表以行*行的形式全部显示出来
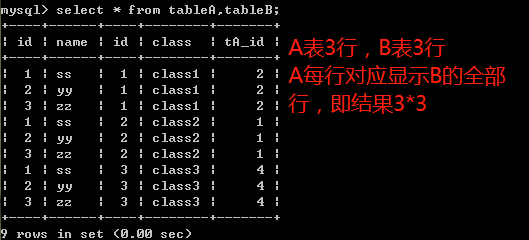
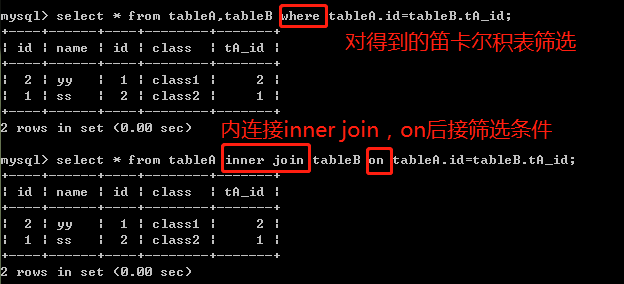
内连接:
select * from tableA,tableB where tableA.id=tableB.tA_id;
select * from tableA inner join tableB on tableA.id=tableB.tA_id;
两种方式结果相同,根据过滤条件查询出两表对应的部分,只返回两个表中联结字段相等的行
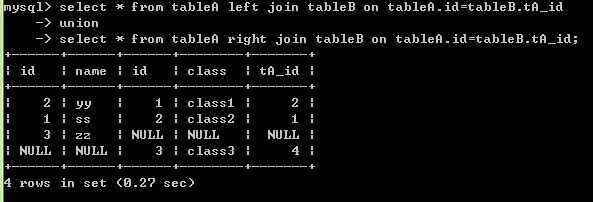
外连接:
select * from tableA left join tableB on tableA.id=tableB.tA_id;
select * from tableA right join tableB on tableA.id=tableB.tA_id;
-- left join:以左边的表为基准显示,左边表若与右边表没有对应的则显示null
-- right join:以右边表为基准显示,右边表若与左边表没有对应的则显示null
-- tableA left join tableB与tableB right join tableA结果相同

全外连接:
full join:oracle支持,mysql不支持
MySQL可以用union将左右连接结合模拟出full join
select * from tableA left join tableB on tableA.id=tableB.tA_id
UNION
select * from tableA right join tableB on tableA.id=tableB.tA_id;
mysql索引
索引:键,创建索引会消耗时间和磁盘空间,但会大大的缩减查询时间
索引分为普通索引,唯一索引(unique),全文索引(fulltext),空间索引(spatial),多列索引,主键索引(primary)
可以在创建表的时候直接设置索引
CREATE TABLE 表名( 字段名 数据类型 [完整性约束条件], 字段名 数据类型 [完整性约束条件], [UNIQUE|FULLTEXT|SPATIAL] INDEX [索引名] (字段名[(长度)]) );
如创建一个普通索引
CREATE TABLE t1( id TINYINT NOT NULL, name VARCHAR(25), INDEX index_name (name) );
在表已经存在的时候添加索引
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX [索引名] ON 表名(字段名[(长度)]);
ALTER TABLE 表名 ADD INDEX [索引名] (字段名[(长度)]);
例:CREATE INDEX index_name ON t1(name);
删除索引
DROP INDEX 索引名 ON 表名
oracle和MySQL两者之间的不同
获取不同时间格式
Oracle中的to_char()来获取到时间的不同的形式
TO_CHAR (date, 'yyyy-mm-IW-dd-Day HH24:mi:ss' )
'yyyy-mm-IW-dd-Day HH24:mi:ss' 对应 年-月-周-日-星期 时-分-秒
Mysql中data_format()来获取到时间的不同的形式
DATE_FORMAT(date,'%Y-%m-%v-%d-%W %H:%M:%s')
'%Y-%m-%v-%d-%W %H:%M:%s' 对应 年-月-周-日-星期 时-分-秒
多列拼接
oracle中可以用 || 连接多列
select a.name || '拼接', a.name || a.age from name_table a
MySQL使用函数concat连接
select conact(a.name,a.age,'拼接') from name_table a
空值
oracle里空值只有null,筛选空值是:is null
MySQL里空值里有 null 和 '' ,筛选空值是:is null 和 =''
获取数据库前n条数据
oracle中使用rownum,rownum在oracle中是作为where的一部分使用
select * from table_A where rownum = 1 (获取到第1行数据)
select * from table_A where rownum <= 10 (获取到前10条数据)
rownum不支持查询后几条或者第n条(n>1)数据
rownum = 3或者rownum > 3这种是不支持的
MySQL中使用limit,limit在MySQL中不作为where的一部分使用
select * from table_A limit 3 (查询前3条数据)
select * from table_A limit 2,4 (从第2条(序号从0开始)开始,查4条数据)

