
内置的re模块
re(正则表达式)
字符匹配:
普通字符匹配:re.findall("alex","shfalexjaf"),直接查找符合的字符
元字符: . ^ $ * + ? {} [] () | \
import re re.findall("alex","asfjsuisjafjxds") #完全匹配 re.findall("a..x","asfjsuisjafjxds") #通配符 . 一个点代表一个任意字符,模糊匹配,注意不能匹配\n re.findall("^a..x","asfjsuisjafjxds") # ^ 只从开头寻找匹配,第一个字符找不到对应的则为空 re.findall("a..x$","asfjsuisjafjxds") # $ 只看末尾是否有匹配的 re.findall("d*","asdddddddddddghiu") # * 重复多次(0-∞)匹配这个字符,匹配不上返回空 re.findall("alex+","sdfalexxxxxgs") # + 重复多次(1-∞)匹配 re.findall("alex?","sdfalexxxxxgs") # ? 只取(0,1)个 #注意 * , + , ? 这个三个多次匹配的区别,* 可以匹配 0个 ,+ 必须最少匹配1个 # ? 还有一个作用 ,将贪婪匹配变成惰性匹配,惰性匹配,按最少的次数匹配,如“alex*?”这个就只做0次匹配 # 而{}可以自己设置匹配多少次如{2,5}等

re.findall("x[yz]p","sddxypsfxzpd") #[] 放在这里的字符有一个满足匹配就可以,是一个或的作用 re.findall("x[a*z]","sdxfpfhjxzpfgk") #在元字符【】中没有特殊字符,这里*不代表匹配多次a re.findall("x[a-z]","sdxfpfhjxzpfgk") #【】这个字符集中只有 - ,^ , \ 这三个有正常功能 re.findall("x[a-z]*","sdxfpfhjxzpfgk") re.findall("x[^a-z]","sdxfpfhjx32gk") #【】字符集中加上 ^ ,此时这个不在表示开头匹配,而表示非

""" 反斜杠后边跟元字符去除特殊功能,比如\. 反斜杠后边跟普通字符实现特殊功能,比如\d \d 匹配任何十进制数;它相当于 [0-9]。 \D 匹配任何非数字字符;它相当于 [^0-9]。 \s 匹配任何空白字符;它相当于 [ \t\n\r\f\v]。 \S 匹配任何非空白字符;它相当于 [^ \t\n\r\f\v]。 \w 匹配任何字母数字下划线字符;它相当于 [a-zA-Z0-9_]。 \W 匹配任何非字母数字下划线字符;它相当于 [^a-zA-Z0-9_] \b 匹配一个特殊字符边界,比如空格 ,&,#等 """
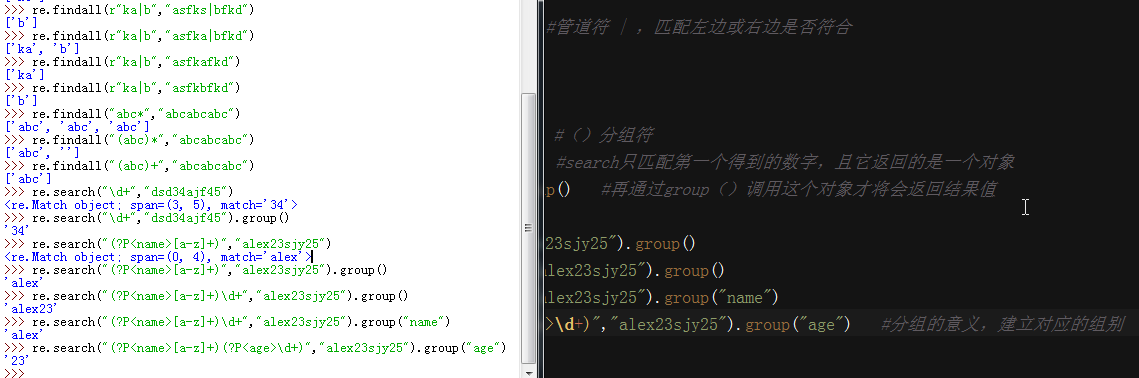
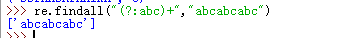
#re模块的方法 re.findall("a","fhajsaja") #匹配所有符合的内容,并将结果返回到一个列表中 re.search("a","sjasfaska") #匹配到第一个内容就返回结果,注意这个返回的是一个对象,需要用group()方法调用 re.match("a","askfjl") #同search,但是匹配开头第一个是否符合 re.split("[ |]","hello abc|def") #分割,可以按照多个字符进行分割 re.split("[ab]","asdabcd") #按照顺序依次分割,注意当左边不存在字符时分割它会出现空字符 re.sub("\d+","AA","sajf23af22sj") #替换,需要三个参数,(匹配规则,替换的字符,原字符串) re.sub("\d","A","ssf23shf45lk2",3) #第四个参数是匹配替换多少次 re.subn("\d","A","ssf23shf45lk2") #统计匹配替换的次数 res = re.compile("\d") #编译一个规则,下次可以直接用编译好的规则 res.findall("sfkla23jak1j42lk2") re.finditer("\d","as23ha24ah5a") #得到的是一个迭代对象,调用时next().group() re.findall("www\.(baidu|163)\.com","aswww.baidu.comaf") #findall()优先给出组内的结果,而不是全部的匹配结果 re.findall("www\.(?:baidu|163)\.com","aswww.baidu.comaf") #在组()内加上?:表示取消优先级

 浙公网安备 33010602011771号
浙公网安备 33010602011771号