LangChain: Tutorial: ChatGPT Over Your Data
来源:
https://blog.langchain.dev/tutorial-chatgpt-over-your-data/
https://github.com/hwchase17/chat-your-data
High Level Walkthrough
At a high level, there are two components to setting up ChatGPT over your own data: (1) ingestion of the data, (2) chatbot over the data. Walking through the steps of each at a high level here:
Ingestion of data:
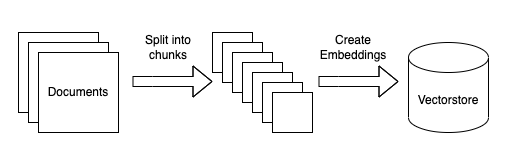
具体步骤:
- Load data sources to text: this involves loading your data from arbitrary sources to text in a form that it can be used downstream. This is one place where we hope the community will help out!
- Chunk text: this involves chunking the loaded text into smaller chunks. This is necessary because language models generally have a limit to the amount of text they can deal with, so creating as small chunks of text as possible is necessary.
- Embed text: this involves creating a numerical embedding for each chunk of text. This is necessary because we only want to select the most relevant chunks of text for a given question, and we will do this by finding the most similar chunks in the embedding space.
- Load embeddings to vectorstore: this involves putting embeddings and documents into a vectorstore. Vecstorstores help us find the most similar chunks in the embedding space quickly and efficiently.
Querying of Data
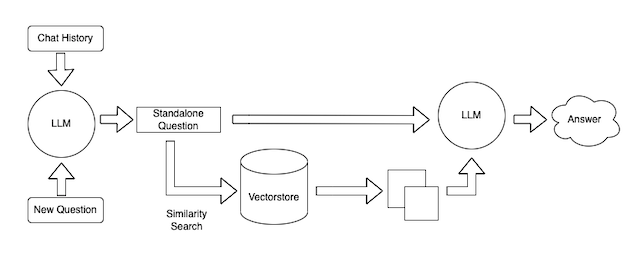
步骤如下:
- Combine chat history and a new question into a single standalone question. This is necessary because we want to allow for the ability to ask follow up questions (an important UX consideration).
- Lookup relevant documents. Using the embeddings and vectorstore created during ingestion, we can look up relevant documents for the answer
- Generate a response. Given the standalone question and the relevant documents, we can use a language model to generate a response
以上只是摘抄,具体步骤和code见来源的两个link

 浙公网安备 33010602011771号
浙公网安备 33010602011771号