
综合设计——多源异构数据采集与融合应用综合实践
综合设计 ——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | <班级的链接> |
|---|---|
| 组名、项目简介 | 组名:黑马楼:直面爬虫 项目需求:实现宠物具体种类的识别 项目目标:根据用户上传的文本和图片识别具体的宠物种类 项目开展技术路线:html,css,js,flask |
| 团队成员学号 | 102202113许煊宇,102202103王文豪,102202148路治,102202129林伟宏,102102151黄靖,172209028伊晓,102202102王子聪,102202116李迦勒 |
| 这个项目的目标 | 根据用户上传的文本和图像,识别图像内容和文本信息,确定具体的宠物种类(例如:贵宾犬,比熊犬等) |
| 其他参考文献 | 如何使用Python和大模型进行数据分析和文本生成 Python 调用常见大模型 API 全解析 |
项目介绍
名称:福宠
背景:宠物在人们的生活中扮演着越来越重要的角色,对于宠物的准确识别和分类有助于宠物饲养者更好地了解宠物的品种等信息,同时也有利于宠物相关产业的精细化管理。
意义:传统的宠物识别方法主要依赖人工观察和经验判断,效率较低且准确性难以保证。随着大模型技术在图像识别和自然语言处理领域的快速发展,利用计算机视觉和自然语言处理技术实现宠物信息的自动识别和分类成为可能。本项目旨在设计并实现一个综合的宠物信息识别与分类系统,通过整合图像分类和文本分析技术,提高宠物信息识别的准确性和效率。
功能需求:

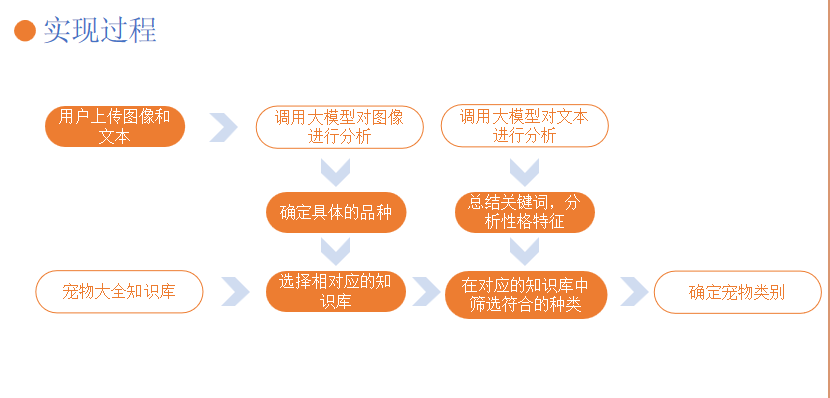
实现过程
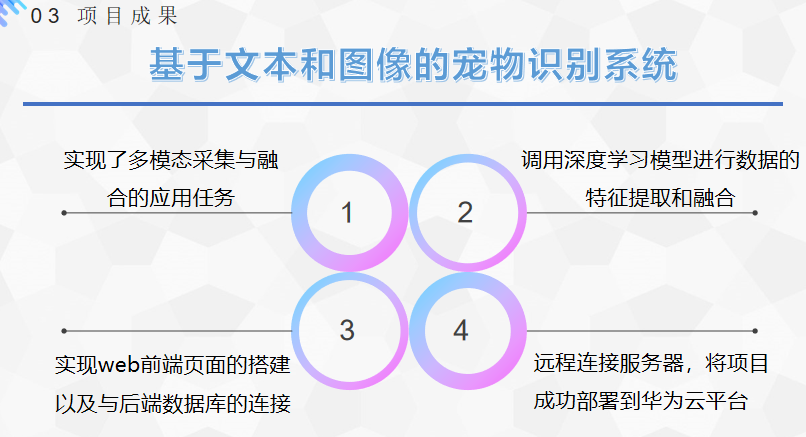
项目成果

项目优点

项目界面
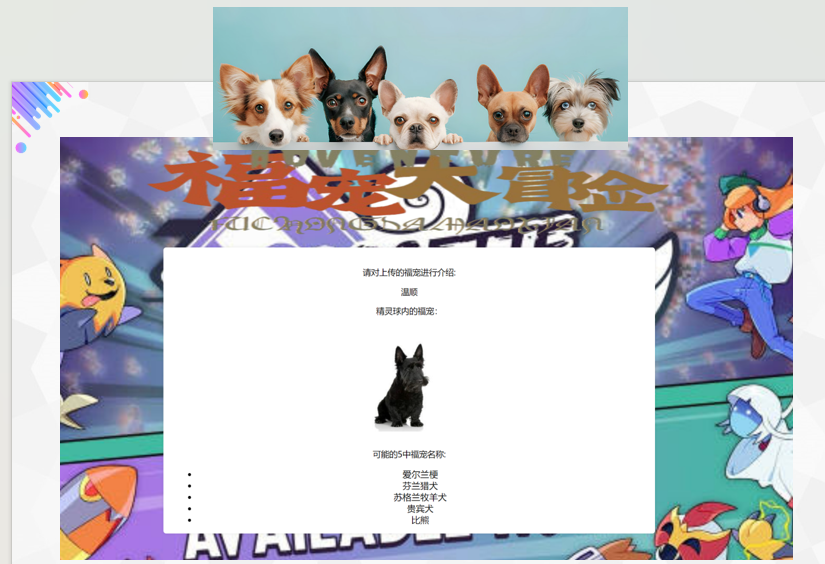
1.用户上传图片和文本:用户能够上传宠物的照片,并填写相关描述文本(生活习惯,性格特征等)。
2.图像处理与分析:通过调用星火认知大模型(图片理解)识别宠物种类(如狗、猫等)。
3.文本分析与匹配:通过调用星火认知大模型(spark4.0 ultra)分析文本描述,以补充图像分类的结果。
4.比对和分类:将图像和文本信息与本地数据库中的宠物信息进行比对,得出最终的宠物分类。
5.展示结果:将识别的宠物类型呈现给用户。
6.反馈机制:用户可以对分类结果提供反馈,帮助优化系统。
具体职责和取得的成效:
数据获取与管理:
1.负责从多个来源收集宠物相关的图片和文本数据,确保数据的多样性和覆盖面。
管理数据仓库,确保数据的安全性和可访问性,为团队成员提供数据支持。
定期检查数据的完整性和一致性,及时更新和维护数据集。
数据预处理与标注:
2.对收集到的数据进行细致的清洗,包括去除噪声、填补缺失值、纠正错误等,以提高数据质量。
与团队合作,对图像数据进行精确标注,包括宠物的种类、特征等,为模型训练提供准确的标签。
实施数据预处理流程,如图像的裁剪、旋转、缩放等,以及文本的分词、去停用词等,以适应模型训练的需要。
模型训练支持:
3.与模型训练团队紧密合作,提供预处理后的数据,确保数据格式和质量满足模型训练的要求。
根据模型训练的反馈,调整数据预处理策略,以提高模型训练的效果和效率。
点击查看代码
import requests
from bs4 import BeautifulSoup
import json
# 目标网站的URL
url = 'http://www.chongso.com/some-page'
# 发送HTTP请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 假设动物的图片和名字以及关键词都在特定的HTML元素中
# 你需要根据实际页面结构来调整选择器
animals = soup.find_all('div', class_='animal')
# 打开一个文件用于写入
with open('animals.jsonl', 'w', encoding='utf-8') as f:
for animal in animals:
# 获取图片
image = animal.find('img')['src']
# 获取名字
name = animal.find('h2').text.strip()
# 获取关键词
keywords = animal.find('p', class_='keywords').text.strip()
# 创建一个字典来存储信息
animal_data = {
'image': image,
'name': name,
'keywords': keywords
}
# 将字典序列化为JSON字符串,并写入文件
json_line = json.dumps(animal_data, ensure_ascii=False)
f.write(json_line + '\n')
else:
print('Failed to retrieve the webpage')
个人成效:
在项目开展过程中,我主要取得了以下成效:
1.高效的数据管理:成功建立了一个高效、可靠的数据管理系统,为项目的顺利进行提供了坚实的数据支持。
2.精准的数据预处理:通过精确的数据清洗和标注,大幅提高了数据的可用性和模型训练的准确性。
3.模型训练的有力支持:与模型训练团队的紧密合作,确保了模型训练的高效进行,为项目的成功打下了坚实的基础。
4.团队协作与贡献:积极参与团队讨论,分享数据管理的专业知识,为解决项目中的数据相关问题提供了有效的解决方案,增强了团队的协作效率。
总结
通过这次实践作业明白了在做项目时的分工合作的重要性,同时还学到了如何确保数据的多样性和质量,为模型训练提供了坚实的基础,为项目做出的贡献,也对大家合作的结果感到开心

