数据采集第四次实验
作业1
要求: 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、 “上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站: 东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
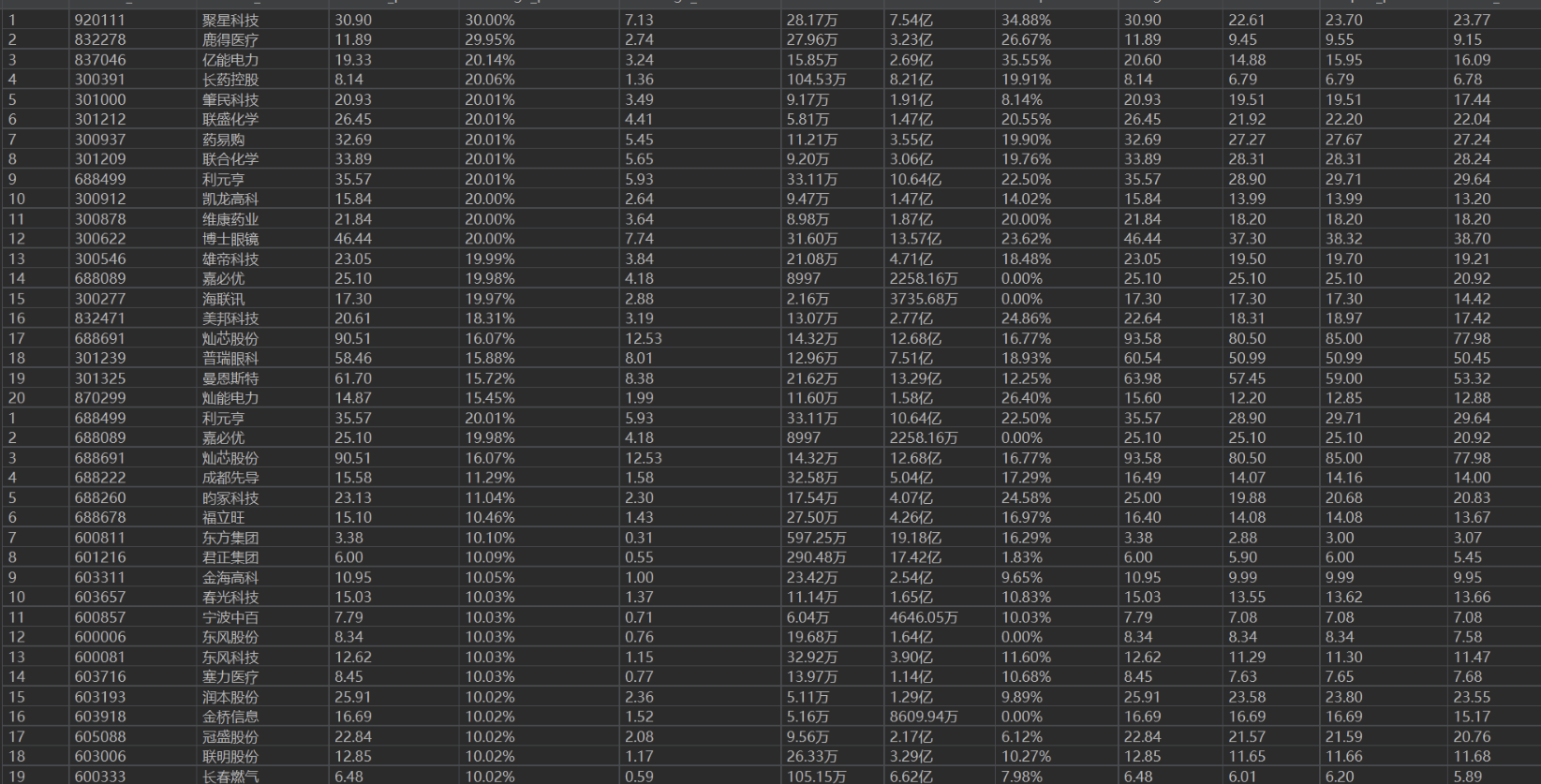
输出信息: MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号
id,股票代码: bStockNo……,由同学们自行定义设计表头:
–务必控制总下载的图片数量(学号尾数后2位)限制爬取的措施。
Gitee链接:https://gitee.com/wang-zicong-OVO/s1ened/tree/master/数据采集作业四/1
点击查看代码
import sqlite3
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建数据库连接
conn = sqlite3.connect('stock_data.db') # 'stock_data.db' 是数据库文件名
cursor = conn.cursor()
# 创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id TEXT,
stock_code TEXT,
stock_name TEXT,
latest_price TEXT,
change_percent TEXT,
change_amount TEXT,
volume TEXT,
turnover TEXT,
amplitude TEXT,
highest TEXT,
lowest TEXT,
open_price TEXT,
last_close TEXT
)
''')
# 初始化Selenium WebDriver
driver = webdriver.Edge()
driver.get("https://quote.eastmoney.com/center/gridlist.html#hs_a_board")
time.sleep(2)
# 获取数据
ts = driver.find_elements(By.XPATH, "//tbody//tr")
for t in ts:
id = t.find_element(By.XPATH, ".//td[1]").text
stock_code = t.find_element(By.XPATH, ".//td[2]").text
stock_name = t.find_element(By.XPATH, ".//td[3]").text
latest_price = t.find_element(By.XPATH, ".//td[5]").text
change_percent = t.find_element(By.XPATH, ".//td[6]").text
change_amount = t.find_element(By.XPATH, ".//td[7]").text
volume = t.find_element(By.XPATH, ".//td[8]").text
turnover = t.find_element(By.XPATH, ".//td[9]").text
amplitude = t.find_element(By.XPATH, ".//td[10]").text
highest = t.find_element(By.XPATH, ".//td[11]").text
lowest = t.find_element(By.XPATH, ".//td[12]").text
open_price = t.find_element(By.XPATH, ".//td[13]").text
last_close = t.find_element(By.XPATH, ".//td[14]").text
cursor.execute('''
INSERT INTO stocks (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close))
button1 = driver.find_element(By.XPATH,'//*[@id="nav_sh_a_board"]/a')
button1.click()
time.sleep(2)
ts = driver.find_elements(By.XPATH, "//tbody//tr")
for t in ts:
id = t.find_element(By.XPATH, ".//td[1]").text
stock_code = t.find_element(By.XPATH, ".//td[2]").text
stock_name = t.find_element(By.XPATH, ".//td[3]").text
latest_price = t.find_element(By.XPATH, ".//td[5]").text
change_percent = t.find_element(By.XPATH, ".//td[6]").text
change_amount = t.find_element(By.XPATH, ".//td[7]").text
volume = t.find_element(By.XPATH, ".//td[8]").text
turnover = t.find_element(By.XPATH, ".//td[9]").text
amplitude = t.find_element(By.XPATH, ".//td[10]").text
highest = t.find_element(By.XPATH, ".//td[11]").text
lowest = t.find_element(By.XPATH, ".//td[12]").text
open_price = t.find_element(By.XPATH, ".//td[13]").text
last_close = t.find_element(By.XPATH, ".//td[14]").text
cursor.execute('''
INSERT INTO stocks (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close))
button1 = driver.find_element(By.XPATH,'//*[@id="nav_sz_a_board"]/a')
button1.click()
time.sleep(2)
ts = driver.find_elements(By.XPATH, "//tbody//tr")
for t in ts:
id = t.find_element(By.XPATH, ".//td[1]").text
stock_code = t.find_element(By.XPATH, ".//td[2]").text
stock_name = t.find_element(By.XPATH, ".//td[3]").text
latest_price = t.find_element(By.XPATH, ".//td[5]").text
change_percent = t.find_element(By.XPATH, ".//td[6]").text
change_amount = t.find_element(By.XPATH, ".//td[7]").text
volume = t.find_element(By.XPATH, ".//td[8]").text
turnover = t.find_element(By.XPATH, ".//td[9]").text
amplitude = t.find_element(By.XPATH, ".//td[10]").text
highest = t.find_element(By.XPATH, ".//td[11]").text
lowest = t.find_element(By.XPATH, ".//td[12]").text
open_price = t.find_element(By.XPATH, ".//td[13]").text
last_close = t.find_element(By.XPATH, ".//td[14]").text
cursor.execute('''
INSERT INTO stocks (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (id, stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, last_close))
# 提交事务
conn.commit()
# 关闭数据库连接
cursor.close()
conn.close()
# 关闭WebDriver
driver.quit()
结果:
实验心得:
通过本次作业,我深入掌握了 Selenium 相关操作,包括查找元素、处理 Ajax 数据和等待元素。设计 MySQL 表头让我明白数据存储结构的重要性。过程有挑战,如东方财富网页结构变化和数据存储问题,但提升了编程和处理数据能力,对类似任务有很大帮助。
作业2:
要求:
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国 mooc 网:https://www.icourse163.org
输出信息:MYSQL 数据库存储和输出格式
Gitee 文件夹链接:https://gitee.com/wang-zicong-OVO/s1ened/tree/master/数据采集作业四/2
点击查看代码
def login(driver, username, password):
try:
driver.get("https://www.icourse163.org")
time.sleep(2)
# 点击登录按钮
login_register_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "div._3uWA6[role='button']"))
)
login_register_button.click()
# 切换到登录 iframe
iframe = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "iframe[src*='index_dl2_new.html']"))
)
driver.switch_to.frame(iframe)
# 输入账号和密码
phone_input = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "phoneipt"))
)
phone_input.send_keys(username)
password_input = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "j-inputtext"))
)
password_input.send_keys(password)
# 点击登录按钮
login_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "submitBtn"))
)
login_button.click()
driver.switch_to.default_content()
time.sleep(3)
except Exception as e:
print(f"Login failed: {e}")
driver.quit()
raise
while total_scraped < course_limit:
course_items = driver.find_elements(By.XPATH, '//div[contains(@class, "_2mbYw") and contains(@class, "commonCourseCardItem")]')
for course_item in course_items:
if total_scraped >= course_limit:
break
try:
# 滚动页面确保课程可见
driver.execute_script("arguments[0].scrollIntoView();", course_item)
time.sleep(1)
course_item.click()
time.sleep(2)
driver.switch_to.window(driver.window_handles[-1])
# 获取课程详情
cCourse = driver.find_element(By.XPATH, '//span[@class="course-title f-ib f-vam"]').text
cCollege = driver.find_element(By.XPATH, "//img[@class='u-img']").get_attribute("alt")
cTeacher = driver.find_element(By.XPATH, '//div[@class="cnt f-fl"]//h3[@class="f-fc3"]').text
cTeam = cTeacher
cCount = driver.find_element(By.XPATH, '//span[@class="count"]').text
cProcess = driver.find_element(By.XPATH, "//div[@class='course-enroll-info_course-info_term-info_term-time']").text
cBrief = driver.find_element(By.XPATH, "//div[@class='course-heading-intro_intro']").text
# 翻页处理
if total_scraped < course_limit:
try:
next_page_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//a[@class="_3YiUU " and text()="下一页"]'))
)
next_page_button.click()
time.sleep(3)
except Exception as e:
print("No more pages to scrape.")
break
# 数据清洗
participants = int(re.sub(r'\D', '', cCount)) # 提取数字参与人数
course_time = re.sub(r'开课时间:', '', cProcess) # 清理课程时间的无关文字
# 插入数据库
if insert_values:
insert_query = """
INSERT INTO course_data (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
cursor.executemany(insert_query, insert_values)
db_connection.commit()
运行结果: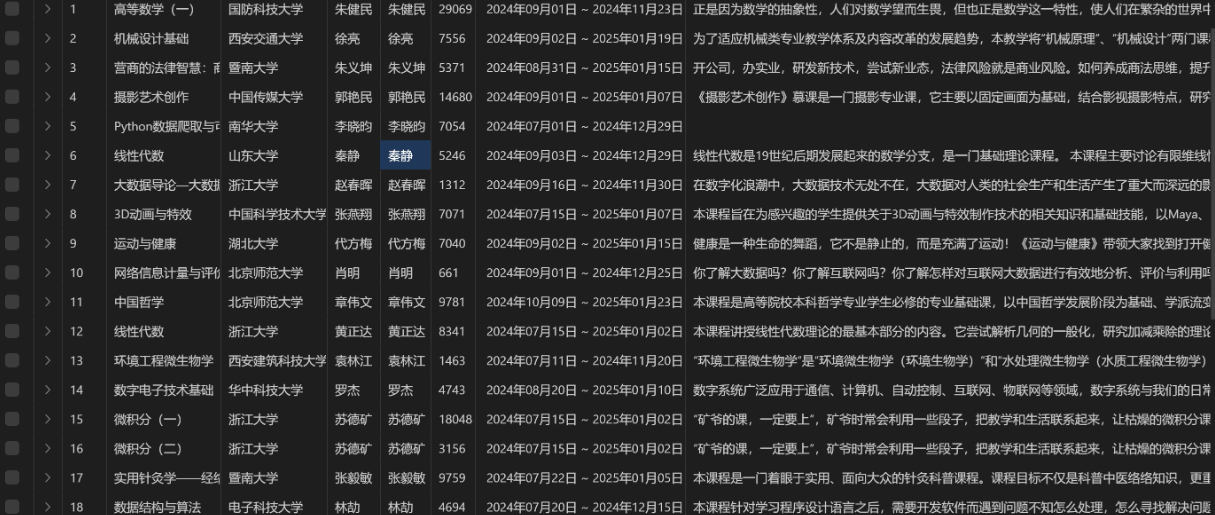
实验心得:
此次作业让我对 Selenium 有了新认识,模拟登录很关键。爬取 mooc 网课程信息使我在数据提取和存储上有了更多实践经验,也提高了应对复杂网页结构的能力,有助于今后的爬虫工作。
作业3:
要求:
掌握大数据相关服务,熟悉 Xshell 的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx中的任务,即为下面5个任务,具体操作见文档。
任务一:任务一:开通 MapReduce 服务

实时分析开发实战
任务一:
Python 脚本生成测试数据
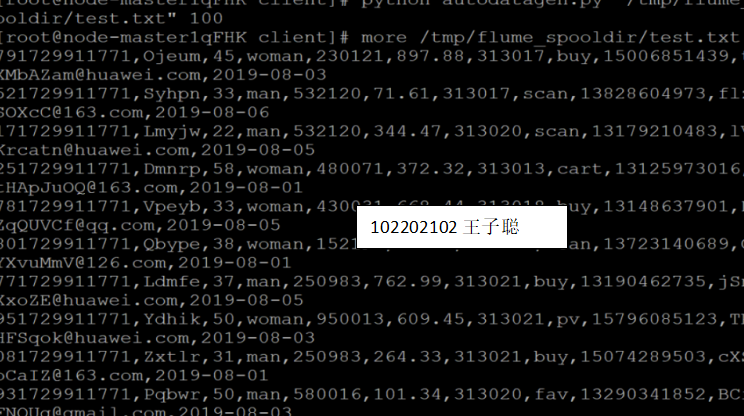
任务二:
配置 Kafka

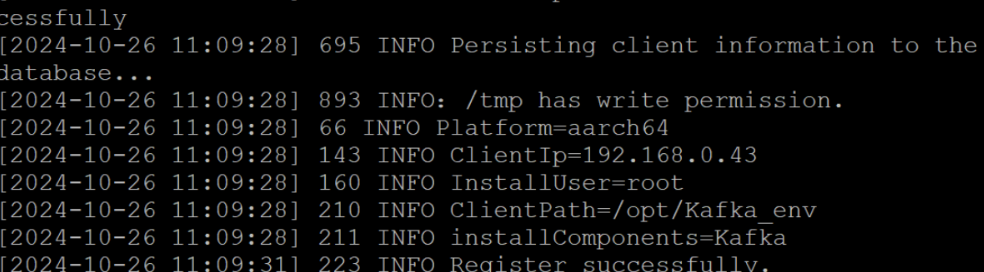
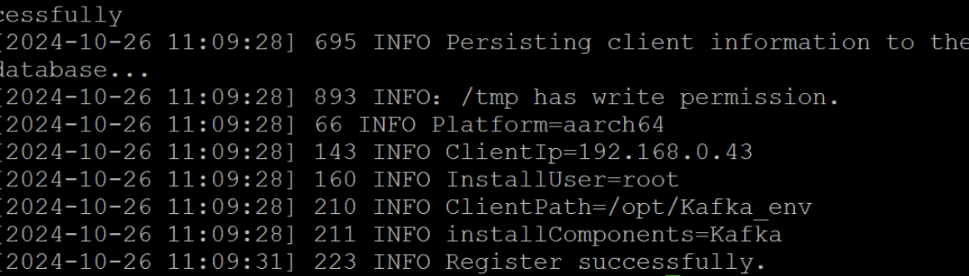
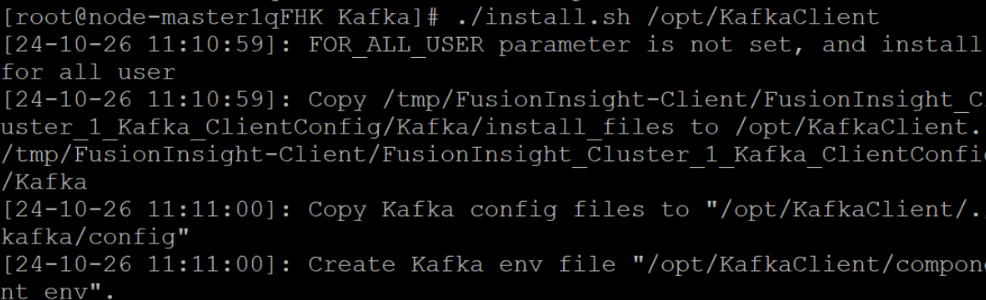
任务三:
安装 Flume 客户端


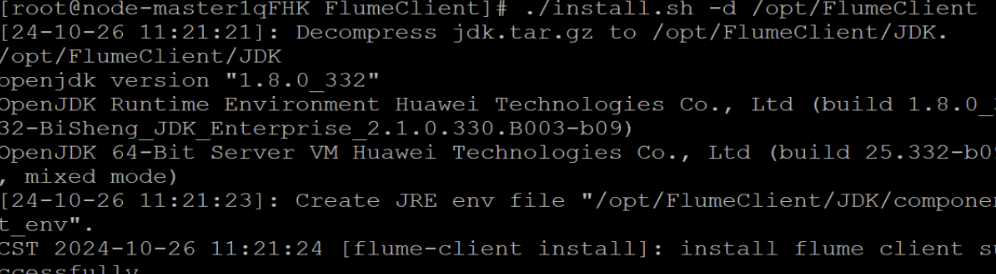

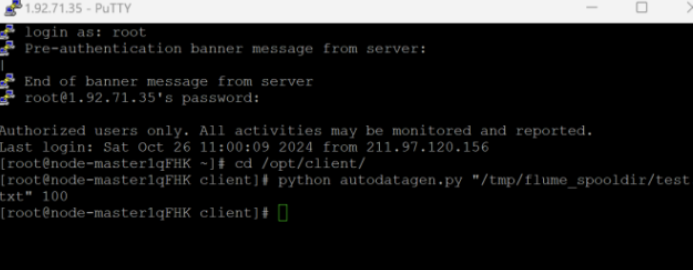
心得体会:
经过对Flume日志采集实验手册的深入学习,我对Flume的核心理念和日志采集服务的操作流程有了更加深刻的理解。这不仅包括了数据流的配置和传输优化,还涉及到了华为云实验中大数据服务和实时数据处理的实际应用。通过这些实验,我不仅熟悉了Xshell工具的使用,还掌握了远程环境管理的技巧。
在实践过程中,我按照文档的指导,逐步完成了从环境搭建到数据采集和实时处理的各项任务。这让我全面掌握了大数据服务与工具的操作流程,并在技术技能和操作能力上得到了显著提升。同时,我对大数据生态系统有了更为清晰的认识,特别是从数据采集到实时处理的整个流程。
通过本次学习,我不仅增强了对Flume的使用能力,而且在实时数据处理和工具应用方面也有所精进。这不仅拓宽了我在大数据技术领域的知识视野,也为我未来的实践工作打下了坚实的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号