
数据采集与融合技术作业三
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Gitee文件夹链接https://gitee.com/wang-zicong-OVO/s1ened/tree/master/数据采集作业三/1
单线程
代码及图片
点击查看代码
# Scrapy settings for weather_images project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "weather_images"
SPIDER_MODULES = ["weather_images.spiders"]
NEWSPIDER_MODULE = "weather_images.spiders"
# 图片存储配置
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
}
IMAGES_STORE = 'images'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "weather_images (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "weather_images.middlewares.WeatherImagesSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "weather_images.middlewares.WeatherImagesDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# "weather_images.pipelines.WeatherImagesPipeline": 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
多线程
代码及图片
点击查看代码
import scrapy
from scrapy.http import Request
from urllib.parse import urljoin
from weather_images.items import WeatherImagesItem
class WeatherSpider(scrapy.Spider):
name = 'weather_spider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
# 爬取控制变量
max_pages = 12
max_images = 102 # 学号尾数3位,012 张图片
image_count = 0
page_count = 0
def parse(self, response):
if self.page_count >= self.max_pages:
return
self.page_count += 1
# 寻找页面中的图片链接
image_urls = response.css('img::attr(src)').getall()
# 下载每个图片
for url in image_urls:
if self.image_count >= self.max_images:
break
# 构造完整的URL
image_url = urljoin(response.url, url)
yield WeatherImagesItem(image_urls=[image_url])
self.image_count += 1
self.logger.info(f"Downloaded image URL: {image_url}")
# 获取下一页的链接
next_page = response.css('a.next::attr(href)').get()
if next_page and self.page_count < self.max_pages:
yield response.follow(next_page, self.parse)
作业心得
1.理解Scrapy框架:
通过这次实验,我更深入地理解了Scrapy框架的工作原理和组件,包括Item Pipeline、Downloader Middlewares、Spiders等。Scrapy是一个强大的爬虫框架,它提供了异步处理的支持,可以显著提高爬取效率。
2.单线程与多线程爬取的比较:
在实验中,我分别实现了单线程和多线程的爬取方式。多线程爬取可以显著提高爬取速度,因为它可以同时从多个页面下载数据。然而,这也意味着对目标网站的请求压力增大,可能会触发网站的反爬机制。
3.处理反爬机制:
在实验过程中,我遇到了一些反爬机制,比如IP被封禁、请求被限制等。这让我意识到在爬虫开发中,需要考虑如何应对这些反爬措施,比如使用代理、设置下载延迟等。
4.数据存储与管理:
实验中,我学会了如何将爬取的图片存储到本地,并在控制台输出下载的URL信息。这让我对数据的存储和管理有了更深的认识,也学会了如何使用Scrapy的Item Pipeline来处理数据。
5.代码优化与调试:
在编写爬虫代码的过程中,我不断优化和调试代码,以确保爬虫的稳定性和效率。这个过程提高了我的编程能力和问题解决能力。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
Gitee文件夹链接https://gitee.com/wang-zicong-OVO/s1ened/tree/master/数据采集作业三/2
代码及图片
点击查看代码
#item.py
import scrapy
class StockItem(scrapy.Item):
id = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
newPrice = scrapy.Field()
price_change_amplitude = scrapy.Field()
price_change_Lines = scrapy.Field()
volume = scrapy.Field()
turnover = scrapy.Field()
amplitude = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()
点击查看代码
spider.py
import scrapy
from stock_scraper.items import StockItem
class StockSpider(scrapy.Spider):
name = 'stock_spider'
allowed_domains = ['www.eastmoney.com']
start_urls = ['https://quote.eastmoney.com/center/gridlist.html#hs_a_board']
def parse(self, response):
stocks = response.xpath("//tbody//tr")
for stock in stocks:
item = StockItem()
item['id'] = stock.xpath('.//td[1]//text()').get()
item['code'] = stock.xpath('.//td[2]//text()').get()
item['name'] = stock.xpath('.//td[3]//text()').get()
item['newPrice'] = stock.xpath('.//td[5]//text()').get()
item['price_change_amplitude'] = stock.xpath('.//td[6]//text()').get()
item['price_change_Lines'] = stock.xpath('.//td[7]//text()').get()
item['volume'] = stock.xpath('.//td[8]//text()').get()
item['turnover'] = stock.xpath('.//td[9]//text()').get()
item['amplitude'] = stock.xpath('.//td[10]//text()').get()
item['highest'] = stock.xpath('.//td[11]//text()').get()
item['lowest'] = stock.xpath('.//td[12]//text()').get()
item['today'] = stock.xpath('.//td[13]//text()').get()
item['yesterday'] = stock.xpath('.//td[14]//text()').get()
yield item
点击查看代码
#pipelines.py
import mysql.connector
from mysql.connector import Error
class MySQLPipeline:
def open_spider(self, spider):
try:
self.connection = mysql.connector.connect(
host='127.0.0.1',
database='wwh', # 使用您的数据库名称
user='root',
password='123456' # 使用您的密码
)
self.cursor = self.connection.cursor()
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stockData (
id INTEGER PRIMARY KEY AUTO_INCREMENT,
code VARCHAR(255),
name VARCHAR(255),
newPrice VARCHAR(255),
price_change_amplitude VARCHAR(255),
price_change_Lines VARCHAR(255),
volume VARCHAR(255),
turnover VARCHAR(255),
amplitude VARCHAR(255),
highest VARCHAR(255),
lowest VARCHAR(255),
today VARCHAR(255),
yesterday VARCHAR(255)
)
''')
except Error as e:
spider.logger.error(f"Error connecting to MySQL: {e}")
def close_spider(self, spider):
try:
self.connection.commit()
except Error as e:
spider.logger.error(f"Error committing to MySQL: {e}")
finally:
self.cursor.close()
self.connection.close()
def process_item(self, item, spider):
try:
with self.connection.cursor() as cursor:
cursor.execute('''
INSERT INTO stockData (code, name, newPrice, price_change_amplitude, price_change_Lines, volume, turnover, amplitude, highest, lowest, today, yesterday)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
newPrice=VALUES(newPrice),
price_change_amplitude=VALUES(price_change_amplitude),
price_change_Lines=VALUES(price_change_Lines),
volume=VALUES(volume),
turnover=VALUES(turnover),
amplitude=VALUES(amplitude),
highest=VALUES(highest),
lowest=VALUES(lowest),
today=VALUES(today),
yesterday=VALUES(yesterday)
''', (
item['code'],
item['name'],
item['newPrice'],
item['price_change_amplitude'],
item['price_change_Lines'],
item['volume'],
item['turnover'],
item['amplitude'],
item['highest'],
item['lowest'],
item['today'],
item['yesterday']
))
self.connection.commit()
except Error as e:
spider.logger.error(f"Error inserting data into MySQL: {e}")
return item
点击查看代码
#middlewares.py
import time
from selenium import webdriver
from scrapy.http import HtmlResponse
class SeleniumMiddleware:
def process_request(self, request, spider):
# 设置Selenium WebDriver
driver = webdriver.Edge()
try:
# 访问URL
driver.get(request.url)
# 等待页面加载
time.sleep(3)
# 获取页面源代码
data = driver.page_source
finally:
# 关闭WebDriver
driver.quit()
# 返回构造的HtmlResponse对象
return HtmlResponse(url=request.url, body=data.encode('utf-8'), encoding='utf-8', request=request)
点击查看代码
#settings.py
ITEM_PIPELINES = {
'stock_scraper.pipelines.MySQLPipeline': 300,
}
DOWNLOADER_MIDDLEWARES = {
'stock_scraper.middlewares.SeleniumMiddleware': 543,
}
MYSQL_HOST = '127.0.0.1'
MYSQL_DATABASE = 'wwh'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
ROBOTSTXT_OBEY = False
图片
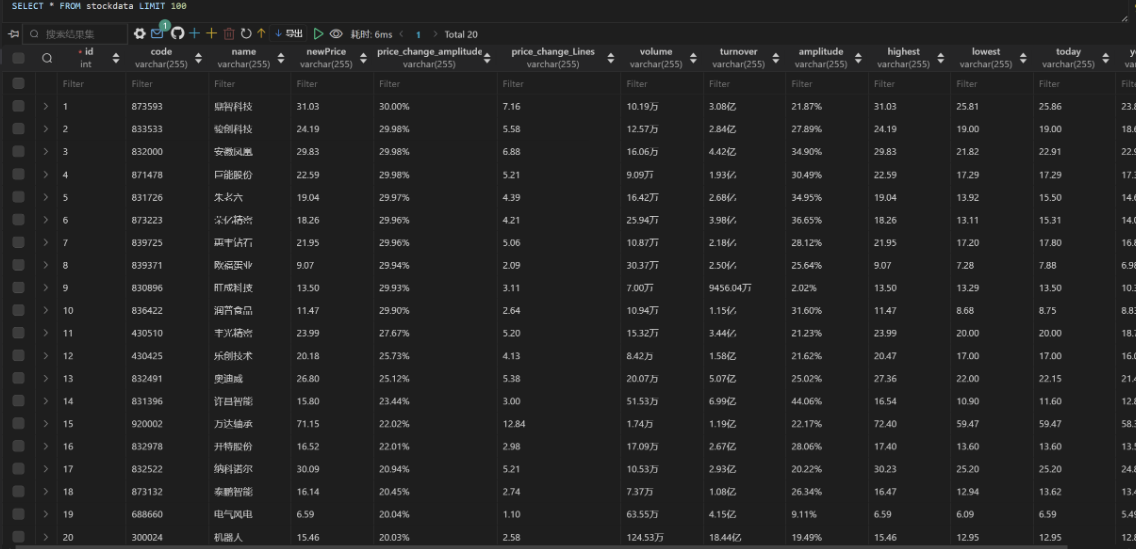
实验心得
1.深入理解 Scrapy 框架:通过实际操作,我对 Scrapy 框架的工作流程有了更加深入的理解。我学会了如何创建 Spider 来抓取网页数据,如何使用 Item 来定义数据结构,以及如何通过 Pipeline 来处理和存储数据。
2.掌握数据序列化与存储:我学会了如何将爬取的数据序列化,并通过 Pipeline 将数据存储到 MySQL 数据库中。这个过程让我对数据的处理流程有了清晰的认识,并且提高了我对数据库操作的熟练度。
3.XPath 的应用:在实验中,我学会了如何使用 XPath 来定位和提取网页中的数据。我意识到编写精确的 XPath 表达式对于爬虫的准确性和效率至关重要。
4.数据库设计的实践:我学会了如何设计数据库表结构,这对于数据的存储和查询效率非常关键。我也学会了如何优化 SQL 查询,以提高数据操作的性能。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
Gitee文件夹链接:https://gitee.com/wang-zicong-OVO/s1ened/tree/master/数据采集作业三/3
代码及图片
点击查看代码
#items.py
import scrapy
class ForexItem(scrapy.Item):
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
time = scrapy.Field()
点击查看代码
#spider.py
import scrapy
from forex_scraper.items import ForexItem
class BankSpider(scrapy.Spider):
name = "forex_spider"
allowed_domains = ["www.boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
# 选择第一个 tbody 中的所有行
rows = response.xpath('//tbody[1]/tr')
# 调整循环范围,以遍历相关的行
for row in rows[2:-2]: # 从索引 2 开始,到倒数第二行结束
item = ForexItem()
item['currency'] = row.xpath(".//td[1]//text()").get() # 使用 .get() 简化语法
item['tbp'] = row.xpath(".//td[2]//text()").get()
item['cbp'] = row.xpath(".//td[3]//text()").get()
item['tsp'] = row.xpath(".//td[4]//text()").get()
item['csp'] = row.xpath(".//td[5]//text()").get()
item['time'] = row.xpath(".//td[8]//text()").get()
yield item
点击查看代码
#pipelines.py
import mysql.connector
from mysql.connector import Error
class MySQLPipeline:
def open_spider(self, spider):
try:
self.connection = mysql.connector.connect(
host='127.0.0.1',
user='root', # 替换为你的MySQL用户名
password='123456', # 替换为你的MySQL密码
database='wwh', # 替换为你的数据库名
charset='utf8mb4',
use_unicode=True
)
self.cursor = self.connection.cursor()
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS exchange_rates (
id Integer,
currency VARCHAR(255),
tbp VARCHAR(255),
cbp VARCHAR(255),
tsp VARCHAR(255),
csp VARCHAR(255),
time VARCHAR(255)
)
''')
self.connection.commit()
except Error as e:
print(f"Error connecting to MySQL: {e}")
def close_spider(self, spider):
if self.connection.is_connected():
self.cursor.close()
self.connection.close()
def process_item(self, item, spider):
try:
self.cursor.execute('''
INSERT INTO exchange_rates (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
''', (item['currency'], item['tbp'], item['cbp'], item['tsp'], item['csp'], item['time']))
self.connection.commit()
except Error as e:
print(f"Error inserting item into MySQL: {e}")
return item
作业心得
1.理解 Scrapy 框架的重要性:通过本次实验,我更加深刻地理解了 Scrapy 框架的工作流程,包括 Spiders、Items、Pipelines 等组件的作用和相互之间的协作方式。这让我对 Scrapy 有了更深层次的认识。
2.掌握 Item 和 Pipeline 的使用:在实验中,我学会了如何定义 Item 类来存储爬取的数据,并通过 Pipeline 对数据进行序列化和存储。这个过程让我理解了数据处理的流程,以及如何在 Pipeline 中操作 MySQL 数据库来保存数据。
3.XPath 的选择和运用:使用 XPath 来定位和提取网页中的数据是一种非常强大和灵活的方法。我学会了如何编写有效的 XPath 表达式来精确地抓取我需要的数据,这对于提高爬虫的准确性和效率至关重要。
4.数据库操作的实践:通过将数据存储到 MySQL 数据库中,我加深了对 SQL 语言和数据库操作的理解。我学会了如何设计数据库表结构,以及如何将数据有效地插入到数据库中。

