
数据采集与融合技术作业二
| 学号 | 姓名 |
|---|---|
| 102202102 | 王子聪 |
| 作业要求 | 点击这里 |
|---|---|
| 目标 | 爬取天气网、股票相关信息、中国大学2021主榜所有院校信息,并存储在数据库中 |
| 实验二仓库地址 | 点击这里 |
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的 7日天气预报,并保存在数据库。
点击查看代码
import requests
from bs4 import BeautifulSoup
import csv
def get_weather(city_name, city_code):
weather_url = f'https://www.weather.com.cn/weather/{city_code}.shtml'
try:
# 请求天气页面
weather_response = requests.get(weather_url)
weather_response.encoding = 'utf-8'
weather_soup = BeautifulSoup(weather_response.text, 'html.parser')
# 找到天气数据的父元素并提取每一天的天气信息
weather_elements = weather_soup.find('ul', class_='t clearfix').find_all('li')
weather_data = [] # 保存天气数据
for element in weather_elements:
date_str = element.find('h1').text.strip() if element.find('h1') else None
weather = element.find('p', class_='wea').text.strip() if element.find('p', class_='wea') else None
# 获取温度信息
temperature_info = element.find('p', class_='tem').text.strip() if element.find('p', class_='tem') else None
if temperature_info:
if '/' in temperature_info and '℃' in temperature_info:
temperature_high, temperature_low = temperature_info.split('/')
temperature_high = temperature_high.replace('℃', '').strip()
temperature_low = temperature_low.replace('℃', '').strip()
else:
temperature_high = temperature_low = temperature_info.replace('℃', '').strip()
else:
temperature_high = temperature_low = None
if date_str:
if '(' in date_str:
date_str = date_str.split('(')[0]
weather_data.append([city_name, date_str, weather, temperature_high, temperature_low])
输出结果
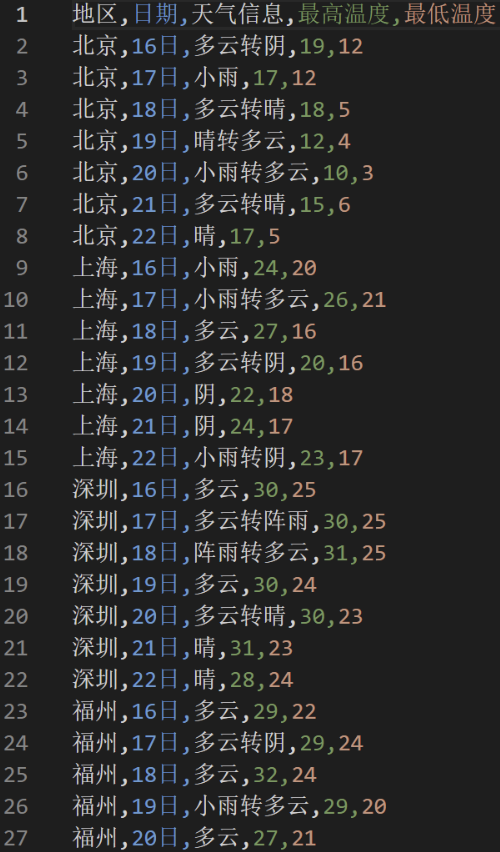
心得体会
在本次实验中,我通过使用Python的BeautifulSoup库来解析网页,成功地从复杂的HTML结构中提取了所需的信息。这个过程中,我学习到了如何识别和定位网页中的特定标签和属性,这对于精确抓取数据至关重要。我意识到,数据抓取不仅仅是下载网页内容,更重要的是理解网页的结构和逻辑,这样才能有效地提取出有用的数据。
在处理数据时,我遇到了数据格式不一致的问题,比如日期和时间的表示方式多种多样。这让我认识到,在数据科学中,数据预处理是一个不可或缺的步骤。我学会了如何使用正则表达式来清洗和统一数据格式,确保数据的一致性和准确性。
此外,我还学习了如何使用Pandas库来处理和分析数据。通过创建DataFrame,我可以轻松地对数据进行排序、筛选和统计分析。这个过程不仅提高了我的数据处理能力,也加深了我对数据科学流程的理解。
作业②
用 requests 和 BeautifulSoup 库方法定向爬取东方财富网(http://quote.eastmoney.com/center/gridlist.html#hk_sh_stocks) 的股票相关信息,并存储在数据库中。
– 技巧:在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改api 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数值,根据情况可删减请求的参数
点击查看代码
import requests
import pandas as pd
import sqlite3
import json
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
# 用get方法访问服务器并提取页面数据
def getHtml(page):
url = f"https://78.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408723133727080641_1728978540544&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728978540545""
try:
r = requests.get(url)
r.raise_for_status()
json_data = r.text[r.text.find("{"):r.text.rfind("}")+1] # 提取 JSON 数据部分
data = json.loads(json_data)
return data
except requests.RequestException as e:
print(f"Error fetching data from page {page}: {e}")
return None
# 获取单个页面股票数据
def getOnePageStock(page):
data = getHtml(page)
if not data or 'data' not in data or 'diff' not in data['data']:
return []
return data['data']['diff']
# 将股票信息存储到SQLite数据库
def saveToDatabase(stock_list):
conn = sqlite3.connect('stocks.db')
c = conn.cursor()
try:
c.execute('''CREATE TABLE IF NOT EXISTS stocks
(code TEXT PRIMARY KEY, name TEXT, price REAL, change REAL, percent_change REAL, volume INTEGER, amount REAL)''')
for stock in stock_list:
c.execute("INSERT OR IGNORE INTO stocks VALUES (?, ?, ?, ?, ?, ?, ?)",
(stock.get('f12'), stock.get('f14'), stock.get('f2'), stock.get('f3'), stock.get('f4'), stock.get('f5'), stock.get('f6')))
conn.commit()
except sqlite3.Error as e:
print(f"Database error: {e}")
finally:
c.execute("SELECT * FROM stocks")
rows = c.fetchall()
df = pd.DataFrame(rows, columns=['Code', 'Name', 'Price', 'Change', 'Percent Change', 'Volume', 'Amount'])
print(df)
conn.close()
def main():
all_stocks = []
max_pages = 100 # 设置要爬取的最大页数
with ThreadPoolExecutor(max_workers=10) as executor:
future_to_page = {executor.submit(getOnePageStock, page): page for page in range(1, max_pages + 1)}
for future in as_completed(future_to_page):
page = future_to_page[future]
try:
stock_list = future.result()
if stock_list:
all_stocks.extend(stock_list)
else:
print(f"未能获取到第{page}页的股票数据")
except Exception as e:
print(f"Error processing page {page}: {e}")
if all_stocks:
print("爬取到的股票数据:")
for stock in all_stocks:
print(stock)
saveToDatabase(all_stocks)
print("股票信息已成功存储到数据库。")
else:
print("未能获取到任何股票数据")
if __name__ == "__main__":
main()
运行结果
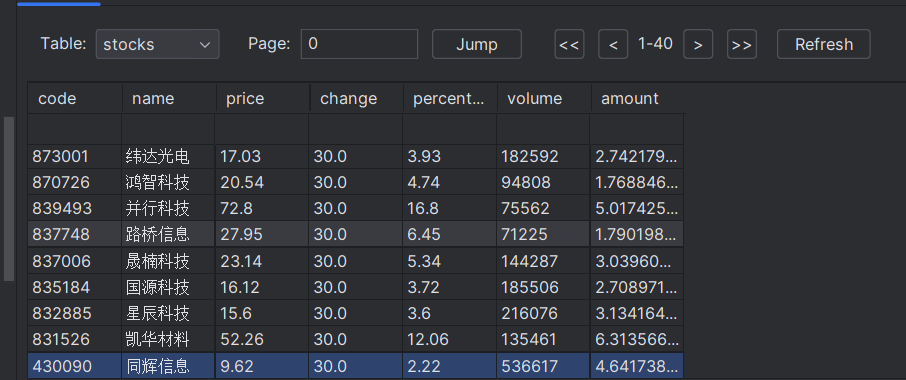
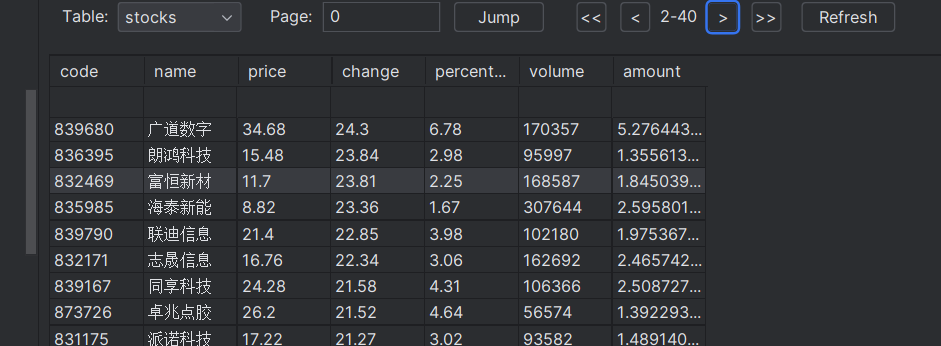
心得体会
在本次实验中,我深刻体会到了API抓包在现代数据采集中的重要性。与传统的网页解析方法相比,API抓包能够直接访问数据源,以一种更加高效和系统化的方式获取所需信息。在尝试获取东财网的股票数据时,我发现API提供了一种标准化的数据格式,这大大简化了数据处理和分析的流程。
我认识到,虽然API抓包为我们提供了一种快速获取数据的途径,但数据采集的复杂性仍然存在。例如,东财网的数据并不是以简单的JSON格式直接返回,而是被封装在JavaScript回调函数中。这就需要我不仅要理解API的响应结构,还要掌握字符串处理的技巧,以便从响应中提取出有用的数据。
在这个过程中,我学会了如何使用正则表达式和字符串分割方法来解析复杂的数据格式。这种技能对于处理各种非标准数据格式非常有用,因为它可以帮助我从混乱的数据中提取出有价值的信息。
此外,我还学习了如何使用网络抓包工具,如Wireshark或Fiddler,来监控和分析API请求和响应。这些工具对于理解API的工作原理和调试数据采集过程中的问题非常有帮助。
作业③:
要求:爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021 )所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
点击查看代码
import requests
import re
import sqlite3
class Database:
def __init__(self, db_name):
self.conn = sqlite3.connect(db_name)
self.cursor = self.conn.cursor()
self.create_table()
def create_table(self):
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS university_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
rank INTEGER,
name TEXT,
province TEXT,
category TEXT,
score REAL
)
""")
self.conn.commit()
def close(self):
self.conn.commit()
self.conn.close()
def insert_many(self, data):
self.cursor.executemany("""
INSERT INTO university_data (rank, name, province, category, score)
VALUES (?, ?, ?, ?, ?)
""", data)
self.conn.commit()
def fetch_all(self):
self.cursor.execute("SELECT * FROM university_data")
return self.cursor.fetchall()
class UniversityScraper:
def __init__(self, db):
self.db = db
def fetch_content(self, url):
response = requests.get(url)
response.raise_for_status()
return response.text
def extract_data(self, content):
patterns = {
'name': r',univNameCn:"(.*?)",',
'score': r',score:(.*?),',
'category': r',univCategory:(.*?),',
'province': r',province:(.*?),'
}
data = {key: re.findall(pattern, content) for key, pattern in patterns.items()}
code_block = re.search(r'function(.*?){', content).group(1)
code_items = re.split(',', code_block[code_block.find('a'):code_block.find('pE')])
mutation_block = re.search(r'mutations:(.*?);', content).group(1)
mutation_values = re.split(',', mutation_block[mutation_block.find('(')+1:mutation_block.find(')')])
return [
(i + 1, data['name'][i], mutation_values[code_items.index(data['province'][i])][1:-1],
mutation_values[code_items.index(data['category'][i])][1:-1], data['score'][i])
for i in range(len(data['name']))
]
def process_data(self, url):
try:
content = self.fetch_content(url)
data = self.extract_data(content)
self.db.insert_many(data)
except Exception as e:
print(f"Error processing data: {e}")
def display_data(self):
results = self.db.fetch_all()
print("{:<10} {:<20} {:<15} {:<15} {:<10}".format("Rank", "University", "Province", "Category", "Score"))
for record in results:
print("{:<10} {:<20} {:<15} {:<15} {:<10}".format(record[1], record[2], record[3], record[4], record[5]))
# Example usage
if __name__ == "__main__":
db = Database("universities.db")
scraper = UniversityScraper(db)
target_url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
scraper.process_data(target_url)
scraper.display_data()
db.close()
print("Process completed")
心得体会
实验心得体会
网站分析
- 使用浏览器的F12开发者工具分析网站结构,找出数据加载的API。
API请求 - 通过分析网络请求,构造出获取数据的API请求。
数据爬取 - 使用Python和相关库编写爬虫,抓取并解析数据。
数据存储 - 将清洗后的数据存储到数据库中。
异常处理 - 在代码中加入异常处理,确保爬虫的稳定性。
可视化 - 录制F12调试分析过程的Gif,并将其加入博客中。
技术提升 - 通过实践提升网络爬虫和数据处理技能。

