
数据采集实验一
题目一
(1)要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
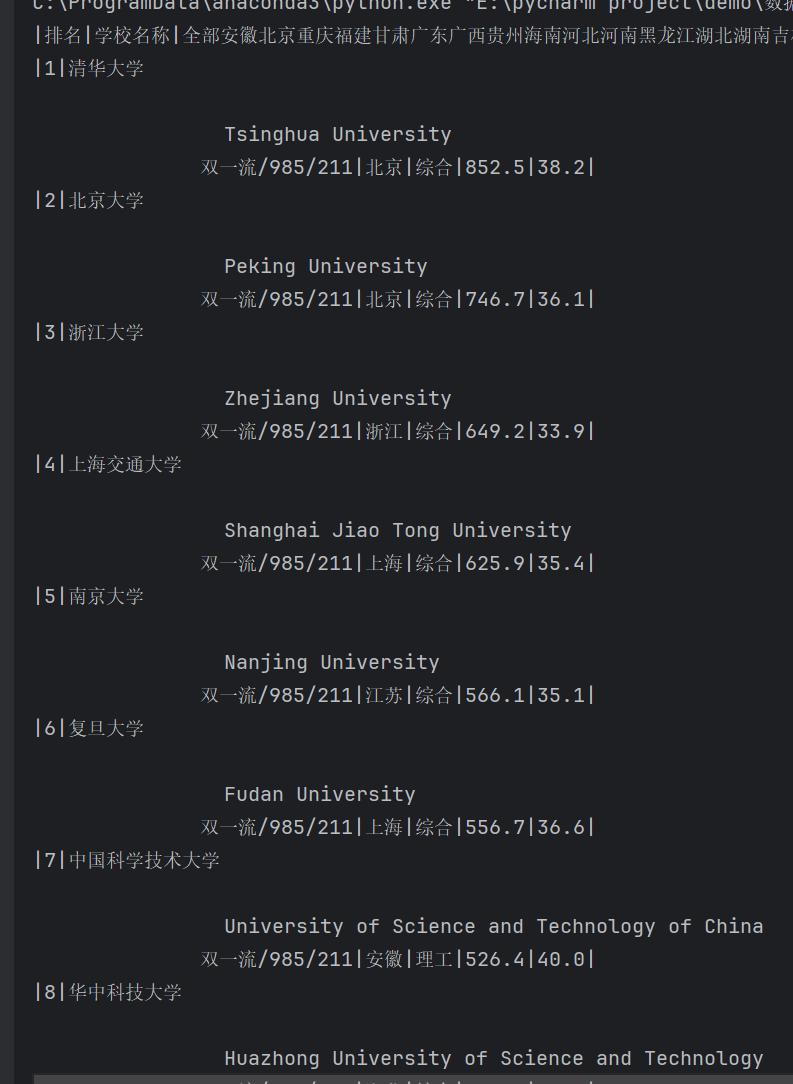
python
import requests
from bs4 import BeautifulSoup
# 目标网址
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
# 发送HTTP请求
response = requests.get(url)
response.encoding = 'utf-8' # 根据网页的编码格式设置编码
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到包含排名信息的表格
table = soup.find('table')
# 打印表头
headers = [th.text.strip() for th in table.find('tr').find_all('th')]
print('|' + '|'.join(headers) + '|')
# 遍历表格的每一行
for row in table.find_all('tr')[1:]: # 跳过表头
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
print('|' + '|'.join(cols) + '|')
题目一心得体会
1. 理解HTTP请求
通过使用requests库,你学习了如何发送HTTP请求来获取网页数据。这是网络爬虫的基础,也是与Web交互的重要技能。
2. 解析HTML内容
使用BeautifulSoup库,你学会了如何解析HTML文档,提取所需的信息。这不仅对爬虫开发有用,也有助于理解Web页面的结构和内容。
3. 数据提取技巧
在提取特定数据(如大学排名、名称、省市等)时,你学会了如何使用选择器(selectors)来定位和提取HTML中的特定部分。这是Web数据提取的关键技能。
4. 处理异常和错误
你可能会在请求或解析过程中遇到各种问题,如网络错误、数据格式变化等。通过解决这些问题,你学会了如何调试和处理异常情况。
5. 数据格式化输出
你学习了如何将提取的数据格式化并优雅地输出到屏幕上,这对于结果的展示和后续处理非常重要。
6. 代码组织和模块化
通过编写清晰、结构良好的代码,你提高了代码的可读性和可维护性。模块化的设计使得代码更容易理解和复用。
7. 实践和应用
通过实际编写和运行爬虫代码,你将理论知识应用于实践,加深了对Web爬虫和数据提取技术的理解。这些经验对于未来在数据科学、Web开发和信息检索等领域的工作都是非常宝贵的。
题目二
(1)要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
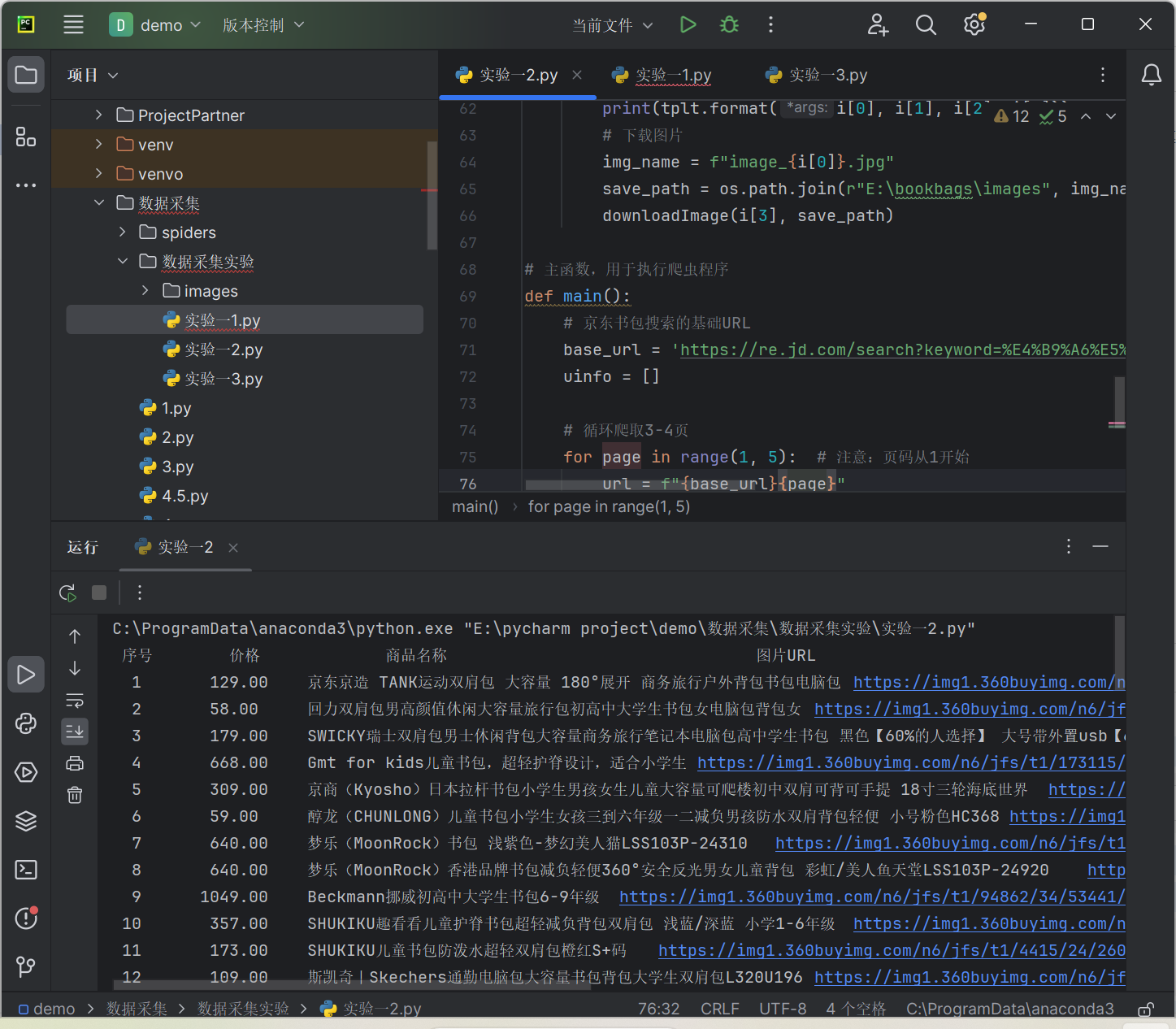
python
import re
import urllib.request
import os
# 定义一个函数,用于获取网页的HTML内容
def getHTMLText(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
try:
# 发送HTTP请求并获取响应内容
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req).read().decode()
return data
except Exception as err:
# 打印错误信息
print(f"Error fetching data from {url}: {err}")
return ""
# 定义一个函数,用于解析网页内容并提取商品信息
def parsePage(uinfo, data):
# 使用正则表达式提取商品价格、名称和图片URL
plt = re.findall(r'"sku_price":"([\d.]+)"', data)
tlt = re.findall(r'"ad_title_text":"(.*?)"', data)
img_urls = re.findall(r'"image_url":"(.*?)"', data)
# 图片基础URL
base_url = "https://img1.360buyimg.com/n6/"
# 获取列表长度的最小值
min_length = min(len(plt), len(tlt), len(img_urls))
# 遍历并提取商品信息
for i in range(min_length):
price = plt[i].replace('"', '') # 去掉引号
name = tlt[i].strip('"') # 去掉引号
# 检查和修正图片 URL
img_url = img_urls[i].replace('"', '') if i < len(img_urls) else '无图片'
if img_url and not img_url.startswith('http'):
img_url = base_url + img_url # 添加基础 URL
# 添加信息到uinfo列表
uinfo.append([len(uinfo) + 1, price, name, img_url])
return uinfo
# 定义一个函数,用于下载图片
def downloadImage(img_url, save_path):
try:
if img_url != '无图片':
urllib.request.urlretrieve(img_url, save_path)
except Exception as e:
print(f"Error downloading {img_url}: {e}")
# 定义一个函数,用于打印商品列表
def printGoodslist(uinfo):
# 定义表格格式
tplt = "{0:^5}\t{1:^10}\t{2:^20}\t{3:^50}"
print(tplt.format("序号", "价格", "商品名称", "图片URL"))
for i in uinfo:
print(tplt.format(i[0], i[1], i[2], i[3]))
# 下载图片
img_name = f"image_{i[0]}.jpg"
save_path = os.path.join(r"E:\bookbags\images", img_name)
downloadImage(i[3], save_path)
# 主函数,用于执行爬虫程序
def main():
# 京东书包搜索的基础URL
base_url = 'https://re.jd.com/search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&page='
uinfo = []
# 循环爬取3-4页
for page in range(1, 5): # 注意:页码从1开始
url = f"{base_url}{page}"
data = getHTMLText(url)
if data:
parsePage(uinfo, data)
printGoodslist(uinfo)
# 程序入口点
if __name__ == '__main__':
# 确保图片保存目录存在
os.makedirs(r"E:\bookbags\images", exist_ok=True)
main()
题目二:商品比价定向爬虫开发心得体会
1. 选择合适的商城
选择一个合适的商城进行爬虫设计是一个重要的决策。我选择了一个商品种类丰富、搜索功能完善的商城,以确保能够获取到足够的数据进行比价分析。
2. 分析网页结构
在开始编写爬虫代码之前,我使用浏览器的开发者工具分析了目标商城的网页结构。这一步是必要的,因为它帮助我理解了网页的HTML结构,以及如何定位商品名称和价格信息。
3. 使用requests库发送请求
通过requests库,我学会了如何发送HTTP请求来获取网页数据。这个过程包括设置合适的请求头,以模拟真实用户的浏览器行为,避免被网站的反爬虫机制拦截。
4. 利用正则表达式提取数据
使用re库中的正则表达式,我提取了商品名称和价格信息。这个过程需要仔细设计正则表达式,以确保能够准确匹配并提取所需的数据。
5. 处理动态加载的内容
我意识到许多商城网站使用JavaScript动态加载内容,这可能需要使用更高级的工具如Selenium来模拟浏览器行为,以获取完整的页面数据。
6. 数据解析与清洗
提取的数据往往包含一些不需要的字符或格式问题,我学会了如何使用字符串操作和正则表达式进行数据清洗,以确保数据的准确性和可用性。
7. 遵守爬虫礼仪
在爬取数据的过程中,我特别注意遵守网站的robots.txt规则,合理设置访问频率,以尊重网站的爬虫政策并减少对网站服务器的负担。
8. 错误处理与调试
在开发过程中,我遇到了各种预料之外的问题,如网络请求失败、数据格式变化等。通过添加异常处理和调试信息,我学会了如何稳定地运行爬虫并处理潜在的错误。
9. 代码优化与重构
为了提高代码的可读性和可维护性,我对代码进行了优化和重构,使其更加模块化和易于管理。
10. 法律和伦理考量
我认识到了在爬虫活动中遵守相关法律法规的必要性,以及在获取和使用数据时考虑伦理问题。
11. 实践与应用
通过实际编写和运行爬虫代码,我将理论知识应用于实践,加深了对Web爬虫和数据提取技术的理解。这些经验对于未来在数据分析、Web开发和信息检索等领域的工作都是非常宝贵的。
通过这次作业,我不仅提升了编程技能,还增强了解决问题的能力,同时也对Web数据的获取和处理有了更深入的认识。这些经验对于未来在数据科学、Web开发和信息检索等领域的工作都是非常宝贵的。
题目三
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
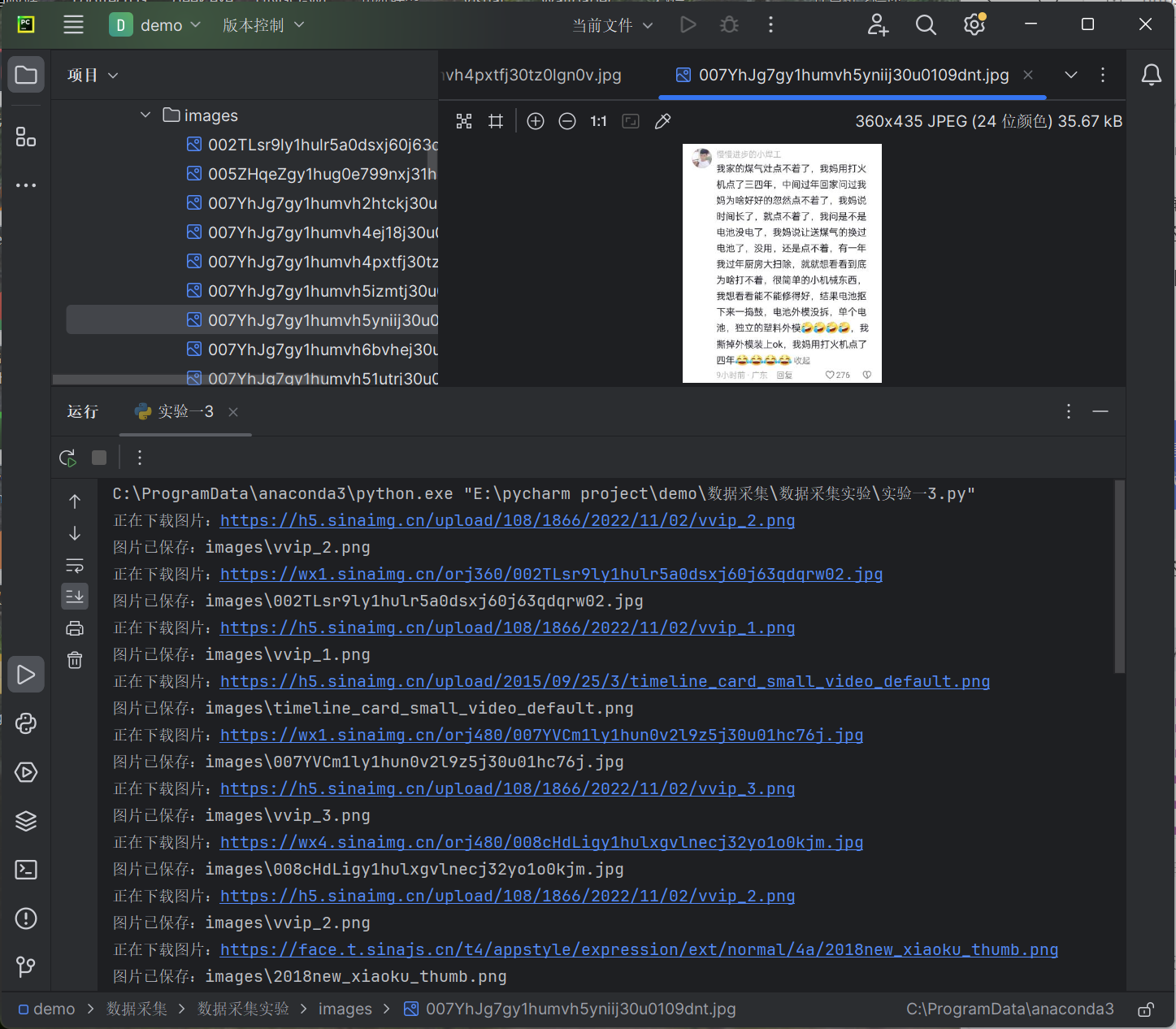
python
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
import time
import os
import requests # 确保 requests 库已被导入
# 设置Selenium浏览器选项
options = webdriver.EdgeOptions()
options.use_chromium = True # 指定使用基于 Chromium 的 Edge 浏览器
options.add_argument('headless') # 无头模式,不显示浏览器窗口
# 指定EdgeDriver的路径
s = Service(executable_path=r'D:\Desktop\edgedriver_win64\msedgedriver.exe')
# 创建WebDriver实例
driver = webdriver.Edge(service=s, options=options)
# 目标网址
url = 'https://weibo.com/newlogin?tabtype=weibo&gid=102803&openLoginLayer=0&url='
# 访问网页
driver.get(url)
# 等待页面加载
time.sleep(5) # 根据网络情况和页面复杂度调整等待时间
# 获取页面源代码
html = driver.page_source
# 使用BeautifulSoup解析HTML内容
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
# 创建一个文件夹来保存图片
folder_name = 'images'
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# 找到所有图片标签
img_tags = soup.find_all('img')
# 遍历图片标签
for img in img_tags:
# 获取图片的URL
img_url = img.get('src')
if img_url:
# 确保图片URL是完整的
if not img_url.startswith(('http:', 'https:')):
img_url = url + img_url
# 检查图片格式是否为JPEG或JPG或PNG
if img_url.lower().endswith(('.jpg', '.jpeg', '.png')):
print(f'正在下载图片:{img_url}') # 打印图片URL
try:
# 获取图片内容
img_data = requests.get(img_url).content
# 获取图片名称
img_name = os.path.join(folder_name, img_url.split('/')[-1])
# 保存图片
with open(img_name, 'wb') as file:
file.write(img_data)
print(f'图片已保存:{img_name}')
except Exception as e:
print(f'下载图片失败:{img_url}, 错误:{e}')
# 关闭浏览器
driver.quit()
题目三:JPEG和JPG格式文件爬取心得体会
1. 确定目标网页
在进行爬虫之前,我选择了一个特定的网页(例如:https://xcb.fzu.edu.cn/info/1071/4481.htm)作为目标,计划爬取该网页上的所有JPEG和JPG格式的图片文件。
2. 使用合适的工具
为了实现这一目标,我决定使用requests库来发送HTTP请求,并使用BeautifulSoup库来解析HTML内容。这两者结合可以有效地获取网页数据并提取所需的信息。
3. 解析网页内容
在编写爬虫代码时,我首先发送请求获取网页的HTML内容,然后使用BeautifulSoup解析HTML文档,查找所有的<img>标签,以提取图片的URL。
4. 处理图片链接
我特别注意了图片链接的格式,确保提取的URL是完整的,并且符合JPEG和JPG格式的要求。对于相对路径的链接,我使用urljoin来构建完整的URL。
5. 遇到的问题
在实际操作中,由于网络原因,我未能成功解析目标网页。这可能是由于网页链接的合法性问题,或者是网络连接不稳定导致的。遇到这种情况,我意识到需要引导用户检查网页链接的有效性,并建议适当重试。
6. 错误处理与调试
在开发过程中,我学会了如何处理潜在的错误和异常情况,例如网络请求失败、解析错误等。这使得我的代码更加健壮,能够应对各种意外情况。

