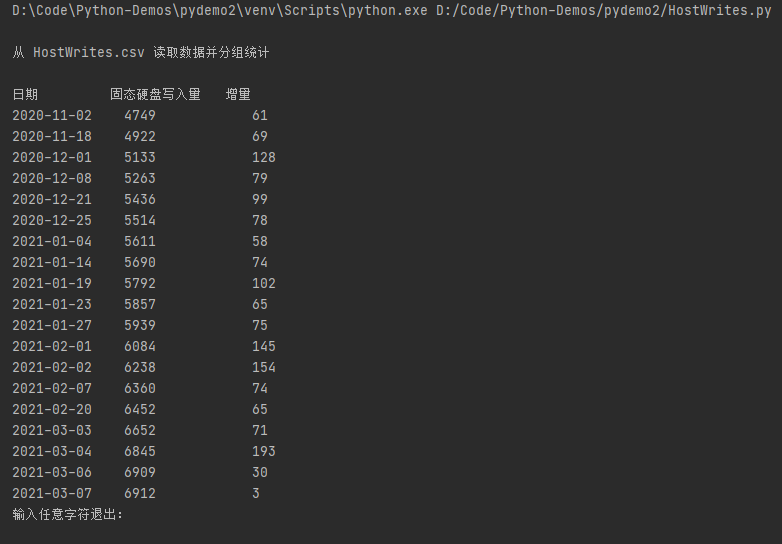
Python使用pandas库读取csv文件,并分组统计的一个例子
代码:


# coding=gbk # 从HostWrites.csv读取数据并分组统计 import pandas import datetime print "\r\n从 HostWrites.csv 读取数据并分组统计\r\n" excel = pandas.read_csv("D:\Program Files\CrystalDiskInfo8_2_0\Smart\KXG6AZNV512G TOSHIBA39HS1002TMFQ\HostWrites.csv", header=None) dates = [] kv = {} # for row in excel.iterrows(): for row in excel.tail(100).values: time = pandas.to_datetime(row[0]) value = row[1] date = datetime.datetime.strftime(time, "%Y-%m-%d") if date not in kv: dates.append(date) kv[date] = value last = None delta = 0 lst = [] for date in dates: if last is not None: delta = kv[date] - last last = kv[date] today = datetime.datetime.strftime(datetime.datetime.now(), "%Y-%m-%d") yesterday = datetime.datetime.strftime(datetime.datetime.now() + datetime.timedelta(-1), "%Y-%m-%d") if delta > 50 or date == today or date == yesterday: lst.append((date, kv[date], delta)) print "日期".ljust(12, " "), "固态硬盘写入量".ljust(16, " "), "增量" index = 0 for item in lst: index += 1 if len(lst) - index < 20: print str(item[0]).ljust(13, " "), str(item[1]).ljust(15, " "), item[2] raw_input("输入任意字符退出:")
输出: