实验五:全连接神经网络手写数字
【实验目的】
理解神经网络原理,掌握神经网络前向推理和后向传播方法;
掌握使用pytorch框架训练和推理全连接神经网络模型的编程实现方法。
【实验内容】
1.使用pytorch框架,设计一个全连接神经网络,实现Mnist手写数字字符集的训练与识别。
【实验报告要求】
修改神经网络结构,改变层数观察层数对训练和检测时间,准确度等参数的影响;
修改神经网络的学习率,观察对训练和检测效果的影响;
修改神经网络结构,增强或减少神经元的数量,观察对训练的检测效果的影响。
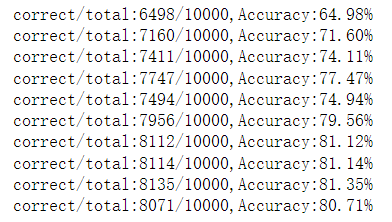
#构建一个类线性模型类,继承自nn.Module,nn.m中封装了许多方法 #本模型所用的包含库 import torch import torch import torch.nn from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader import torch.nn.functional as F #检测是否有cuda device = torch.device( 'cuda:0' if torch.cuda.is_available() else 'cpu') # 准备数据集 batch_size = 32 transform = transforms.Compose([ transforms.ToTensor() ]) # 下载训练集 MNIST 手写数字训练集 # 数据是datasets类型的 train_dataset = datasets.FashionMNIST( root='D:/nosql数据库/image_data', train=True, transform=transforms.ToTensor(), download=True) test_dataset = datasets.FashionMNIST( root='D:/nosql数据库/image_data', train=False, transform=transforms.ToTensor(),download=True) train_loader = DataLoader(dataset=train_dataset,batch_size=train_batch_size,shuffle=True,pin_memory=True) test_loader = DataLoader(dataset=test_dataset,batch_size=test_batch_size,shuffle=False,pin_memory=True) # 定义三层全连接神经网络 class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Conv2d( in_channels=1, out_channels=10, kernel_size=5) self.conv2 = torch.nn.Conv2d( in_channels=10, out_channels=20, kernel_size=5) self.pooling = torch.nn.MaxPool2d(kernel_size=2) self.fc = torch.nn.Linear(320, 10) def forward(self, x): # Flatten data from (n,1,28,28) to (n,784) batch_size = x.size(0) x = F.relu(self.pooling(self.conv1(x))) x = F.relu(self.pooling(self.conv2(x))) x = x.view(batch_size, -1) # Flatten x = self.fc(x) return x # 定义模型训练中用到的损失函数和优化器 # parameters()将model中可优化的参数传入到SGD中 model = Net().to(device) # 构建损失函数和优化器 criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD( params=model.parameters(), lr=0.01, momentum=0.5) # 定义训练函数 def train(epoch): running_loss = 0 for batch_idx, data in enumerate(train_loader): images, labels = data images = images.to(device) labels = labels.to(device) optimizer.zero_grad() # 前馈+反馈+更新 outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() # 每300次迭代输出一次 if (batch_idx + 1) % 300 == 0: print('[%d,%d],loss is %.2f' % (epoch, batch_idx, running_loss / 300)) running_loss = 0 # 定义测试函数 def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data images = images.to(device) labels = labels.to(device) outputs = model(images) # 沿着第一维度找最大值的下标 _, predict = torch.max(outputs, dim=1) correct += (labels == predict).sum().item() total += labels.size(0) print('correct/total:%d/%d,Accuracy:%.2f%%' % (correct, total, 100 * (correct / total))) # 实例化训练和测试 if __name__ == '__main__': for epoch in range(10): train(epoch) test()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号