

服务器的两种并发原理
众所周知,现在的服务器可以处理多个socket连接,背后并发的实现主要有两种途径。
- 多线程同步阻塞
- I/O多路复用
socket的建立
聊到socket,就不得不提到socket的建立的流程。祭出经典的老图:
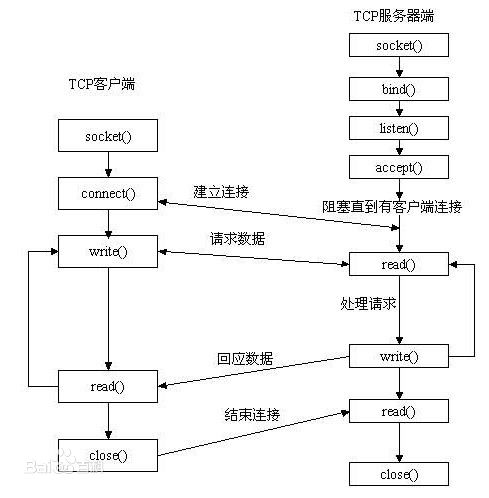
服务器依次使用socket,bind,listen之后就会监听对应的地址,此时accept会一直阻塞直到有连接建立,如果客户端和服务器建立了连接,那么accept就会返回一个连接句柄,可以对连接进行读数据或者写数据。
同步阻塞
那么问题来了,服务器如果不做特殊处理的话,一次只能处理一个连接,新的连接来是需要等待上一个连接结束才能连接成功,这就是最开始的服务器同步阻塞方法。
同步阻塞:进程发起IO系统调用后,进程被阻塞,转到内核空间处理,整个IO处理完毕后返回进程。操作成功则进程获取到数据。
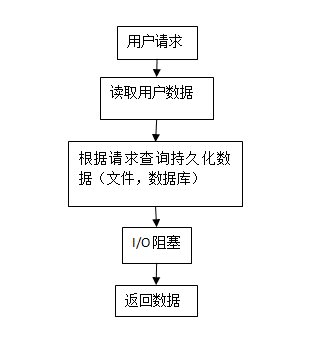
多线程并发
可能以前的拥有的电脑人不多,这种方式一次只能连接一个倒也没有问题,之后访问的人开始多起来,设计者觉得这样下去不行,就设计了多线程同步阻塞的方法。每次accept获得一个句柄,就创建一个线程去处理连接,这下子就能同时处理多个连接呢。这就是经典的多线程同步阻塞的方法。
典型的多线程(进程)并发模型就是cgi。
特点
服务器和客户端之间的并发,有以下特点:
- 外部连接很多,但很多连接是不活跃的连接,典型的如聊天的im系统。
- 少量的CPU消耗。
- 大部分的时间耗费在I/O阻塞和其他网络服务。
- 外部网络不稳定,客户端收发数据慢很多。
- 对业务的请求处理很快,大部分时候毫秒级就可以完成。
问题
根据以上特点,我们可以得知服务器有以下问题:
如果采用多线程同步阻塞,1个tcp连接需要建立1个线程,10k个连接需要建立10k个连接,然而大部分连接是不活跃,即便是需要处理业务逻辑,也可以快速返回结果,大部分时间也是处于I/O阻塞或网络等待。这就使得多个线程的创建很耗费资源,且线程的切换也是极其耗费CPU,这就很可能导致了CPU处理业务的消耗的资源不多,但是却花了很多资源在进程切换上面。
I/O多路复用
多线程并发的问题是大部分socket都是闲置的状态或者是处于IO阻塞的状态,那能不能把阻塞的socket先扔到一边去处理其他事情,来避免等待所带来的资源耗费,也就是非阻塞IO的概念。
非阻塞IO
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
因此:使用非阻塞IO是需要不断轮询IO数据是否好了。
IO多路复用原理就是不断轮询多个socket,当其中的某个socket准备好了数据就返回,否则整个进程继续阻塞,就可以让一个进程在不太耗费资源的情况下处理多个连接,但是这个轮询的操作是交给内核态去完成,也就避免了内核态和用户态的切换的问题。
而目前的实现方法有select, poll, epoll,其中epoll的性能最好,用的也是最广泛。
优点
- 避免了创建多个线程所耗费的资源以及时间。
- 对socket的轮询是内核态的完成,不需要像多线程那样切换需要耗费资源。
而epoll的实现可以做到性能几乎不受连接数(单单是连接而没有其他的操作)的影响。
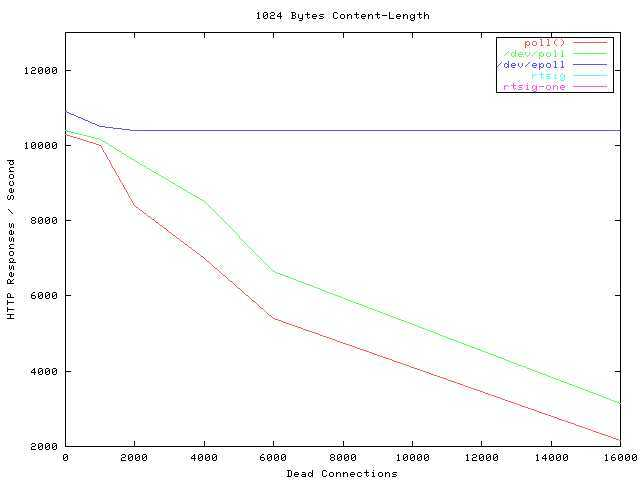
当然多路复用IO也有自己的问题,也就是本身不支持多核的使用,需要另外解决多核的利用。
其中使用enroll的成熟程序有nginx,redis,nodej等。
服务器的发展
根据知乎大佬的介绍,服务器经过发展可以分为两阶段:
第一代服务器模型
把传输层的tcp并发的连接放到IO多路复用去处理,应用层继续使用多线程并发模型去做。这样就可以大幅度减少线程的创建切换的资源耗费。
如:nginx + php-fpm(其实是php-fpm是多进程)
第二代服务器模型
第二代服务器模型是把应用层也使用IO多路复用去处理,减少应用层的等待外部接口调用阻塞等待,一般是大厂大流量并发需要用到。
如:
- nodejs的异步回调
- Go的goroutine
参考资料:
[1]:许怀远的知乎回答
[2]:Linux IO模式及 select、poll、epoll详解

