
转Jmeter关联——正则表达式提取器
在日常工作中,jmeter的正则表达式提取器应该是我们最常用的组件之一了。通过它,我们能从请求的响应中提取需要的内容。
一 常用操作及用法
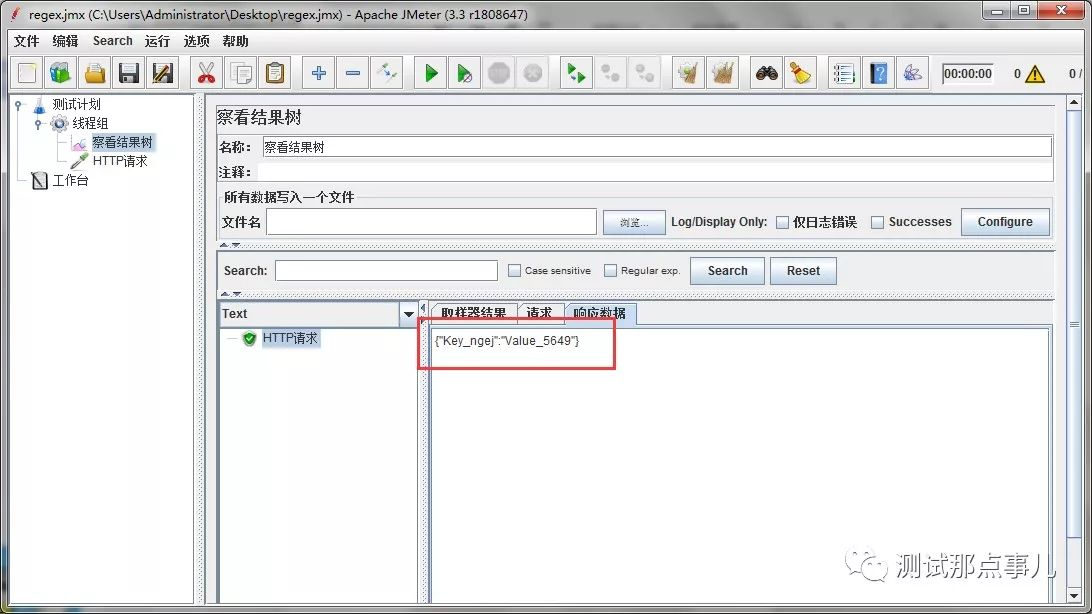
首先我们来看一下常用的用法(国际套路,不是重点)。用一个简单接口的响应结果为例,其中Key和Value都是变量,然后,我们来使用正则表达式提取一下例子中Vaule值。
正则表达式
1、添加正则表达提取器
http请求→添加→后置处理器→正则表达式提取器
2、添加Debug PostProcessor用于验证
3、书写正则表达式


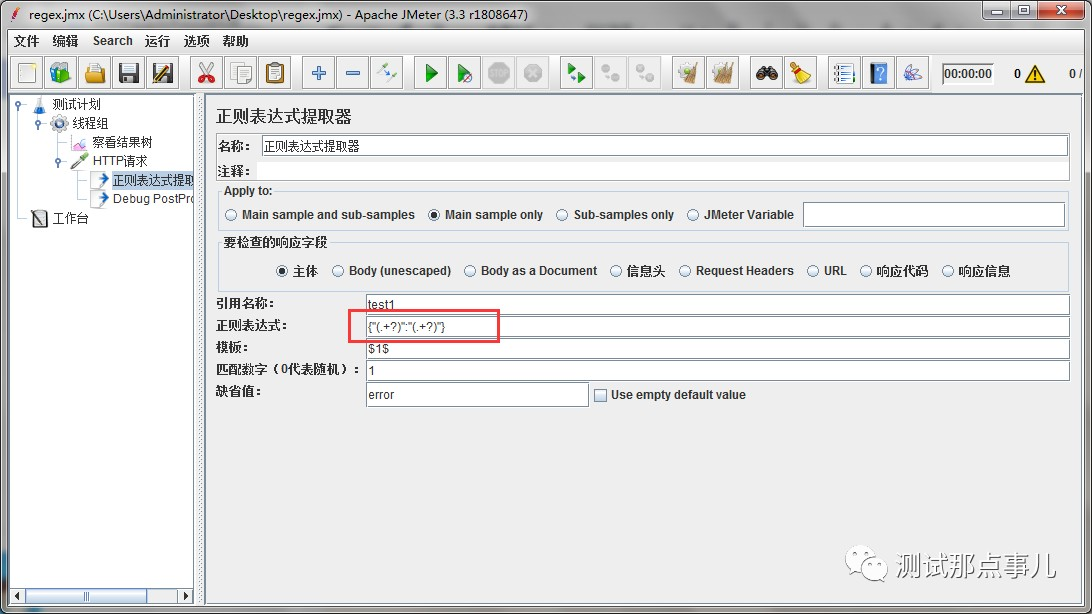
提取器页面相关参数解释
名称:正则表达式提取器的名称,自定义,一般用不到
引用名称:匹配结果的参数名称,自定义,需要后续引用
正则表达式:填写对应的正则表达式就ok
模板:正则表达式的组(不好理解的话,下面有具体的示例)
匹配数字:当匹配到多个值,取第几个(0代表随机,-1代表全部,正整数代表顺序取第几个值)
缺省值:如果没有匹配到结果,则获取缺省值
所使用的正则表达式介绍
上图的正则表达式::"(.+?)"}
其中:
()中的内容是实际的正则表达式
. 表示任意字符
+ 表示匹配一次或者多次
? 表示匹配到一次就结束
整个表达式的意思就是:
匹配开始字符是 :",结束字符是"}之间的任意字符,匹配一次或者多次,当匹配到一次时,停止匹配。
获取Value值
OK,如上操作,那我们就练习下怎么获取Value值,以上面的请求为主,实际上就是匹配到Value_5649这一段。我们看一下结果:
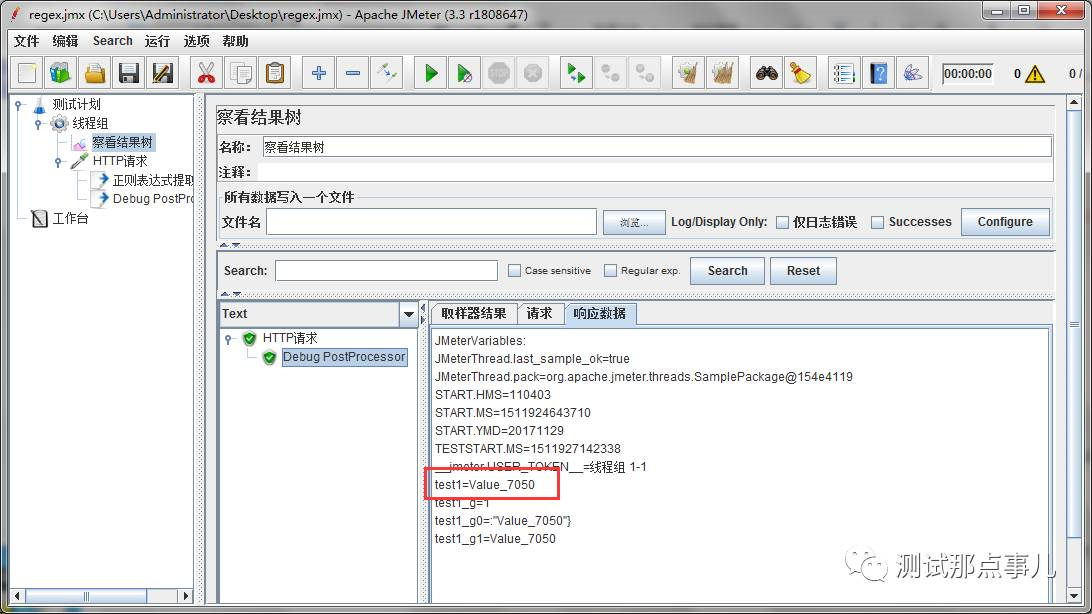
值已经匹配到了,而且是正确的,数字不对是因为它是变量,为了方便下面的演示。
二正则表达式介绍
一、常用表达式
不太理解?没有关系,一般(.+?)和(.*?)能够满足我们80%的使用场景。所以,一般的
正则表达式都可以写成下面这2种
left(.+?)right
left(.*?)right
left对应匹配目标的起始字符(参考lr关联函数的左边界)
right对应匹配目标的结束字符(参考lr关联函数的右边界)
二、适用性表达式
当然,按照套路,剩余的20%的场景才是我们今天的重点。
首先,我们思考一下,上述的通用正则表达式在什么情况下不适用,也就是说剩余20%是什么场景?
如: left、right不唯一 和 left、right唯一,但是为变量,也需要提取这两种情况
(1)第一种情况
我们可以通过提取器中的匹配数字获取特定的值,也可以通过自定义left、right使它变成唯一,从而解决。
(2)第二种情况
它可以再细分为2种现象,如下
<1> 现象一
一个json串,多对键值,比如{"key_1":"value_1","a":"b","c":"d","key_2":"value_2"}
其中a,b,c,d是变量,此时我想要用正则表达式提取b和c时,就会遇到问题。因为b,c的左右都是变量,无法确定确定边界,所以无法通过之前的正则表达式进行匹配
解决方案:
当然,办法总是有的。需要一次匹配多个变量的时候,我们使用这种方式:
正则表达式如下:
{"(.+?)":"(.+?)"}
每个()代表一个正则表达式组,每个变量我们可以通过一个组去匹配模板用来表示该提取哪一组,我们来看一下结果
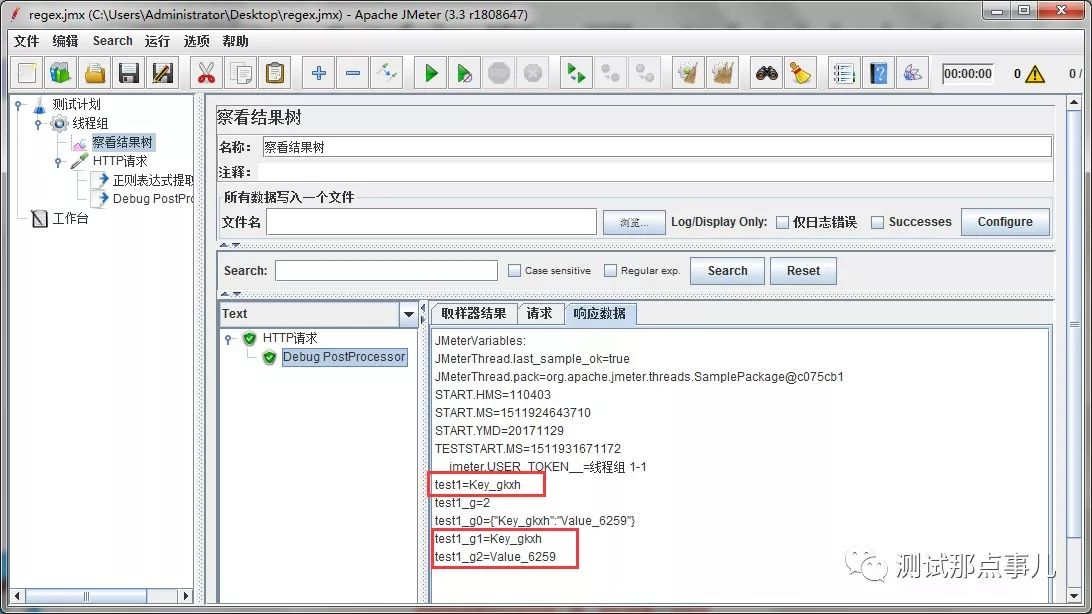

可以看到,test1能匹配到Key的值,并且它匹配到了2个(test1_g),第二组是Value的值。现在我们将模板改成$2$,看看是否能匹配到第二组Value的值。
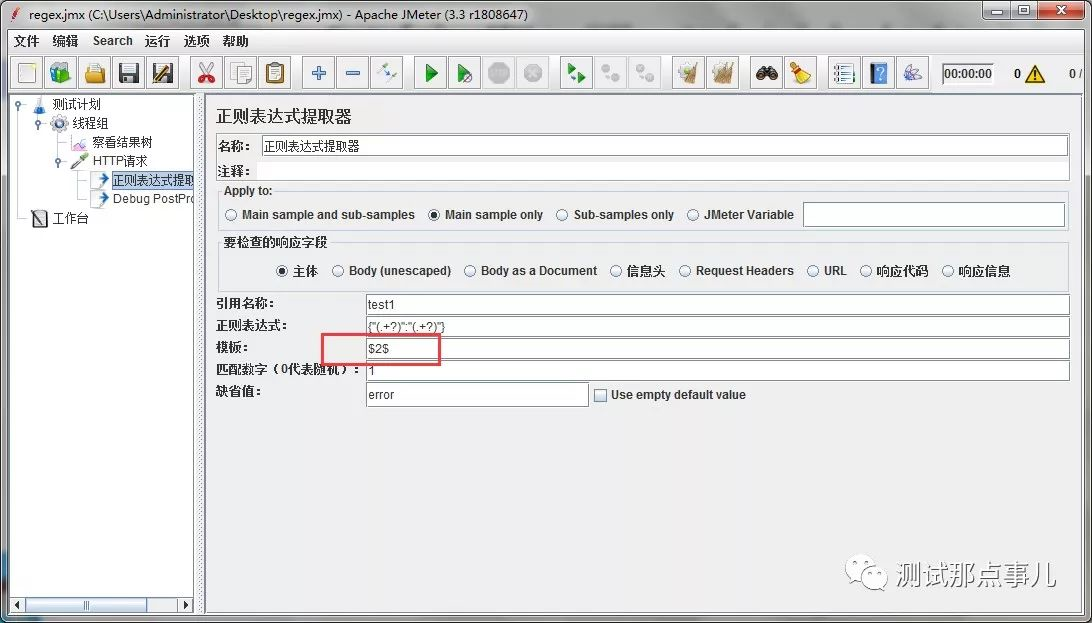
结果如下:
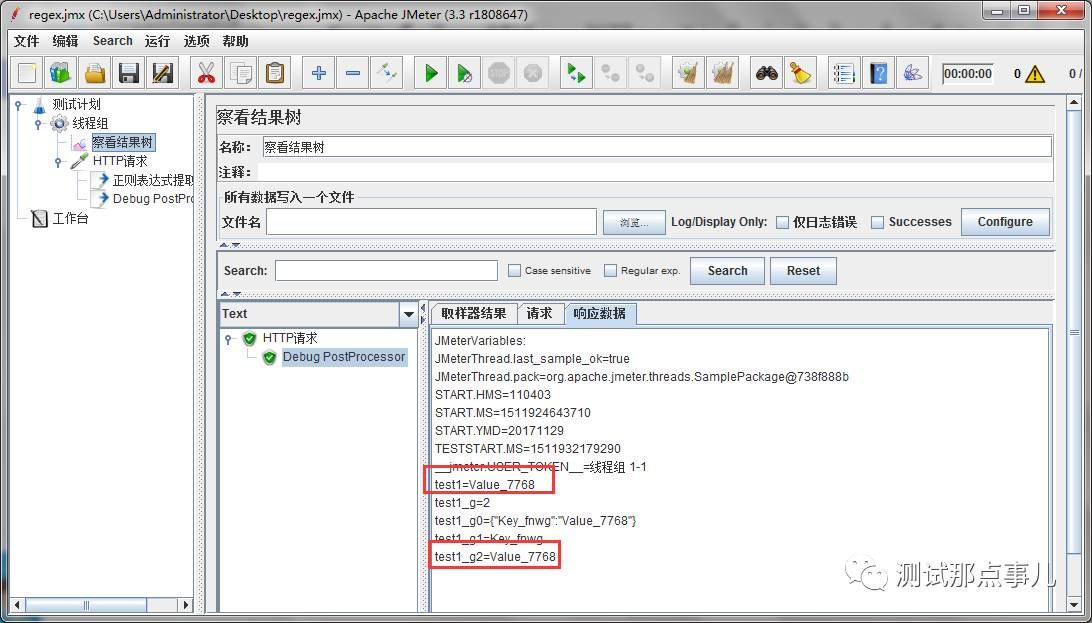
test1获取到了Value的值,成功!
那么,对应到{"key_1":"value_1","a":"b","c":"d","key_2":"value_2"}这一类的返回,我们想要获取某个变量时,只需要将变量全部替换为正则表达式,并且获取对应的组(模板)即可。
{"key_1":"value_1","(.+?)":"(.+?)","(.+?)":"(.+?)","key_2":"value_2"}
a→$1$
b→$2$
c→$3$
d→$4$
json中的多变量匹配算比较常见,相对来说也比较好解决。但是,下面这种情况,利用
上述的方法都无法解决。
<2> 现象二
返回了一个长字符串,前n为代表aaa,后m位代表bbb,各段均为变量,且意义不同。
比如,一个身份证号18位,第7-14位是生日,如果返回一个身份证号,如何将生日提取出来。
从上述条件来看:
1)身份证号码本身就是变量,18位数均有可能变化,所以,不可能抽取出常量来给我们当起始/结束字符,所以方法上述的方法不能满足条件。
2)身份证号码是分段的,前1-6位是地区,7-14位是生日,15-17位是顺序码,最后1位是校验码。可以利用这个规则来给正则表达式分组。
解决方案:
好,思路是这样,那么我们还是以刚才的接口做演示。从上面的几张图,也可以发现这个接口返回的规则,Key_(4位随机字母),Value_(4位随机数字)。去除开始的{“和末尾的”},我们将剩余的部分进行如下分组:
前8位:key值
9-11位: ","
后10位:value值
正则表达式实现如下:
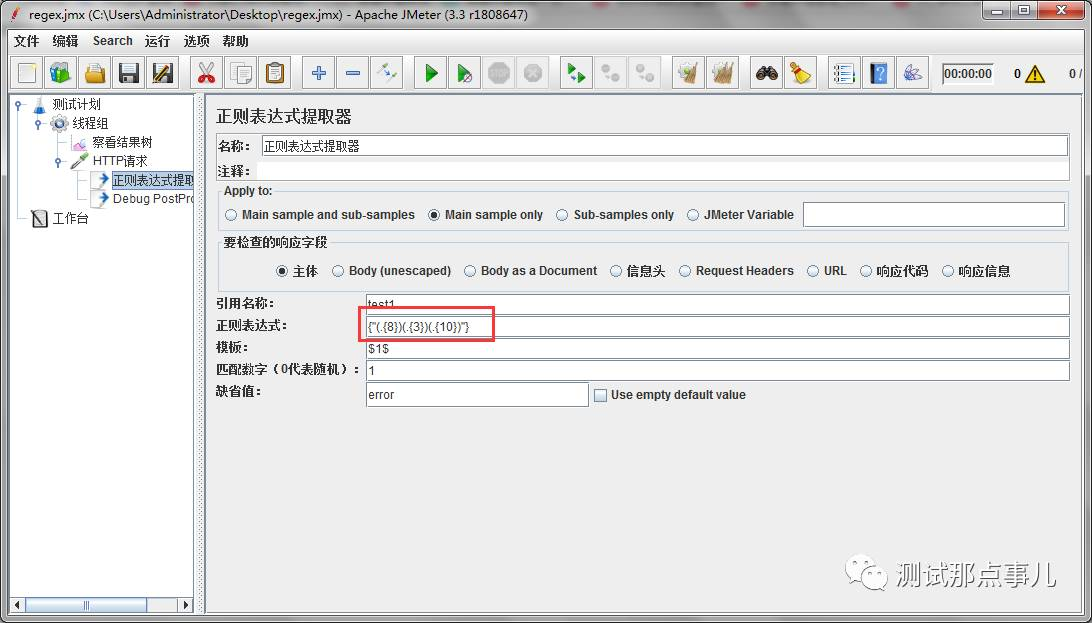
匹配结果如下:
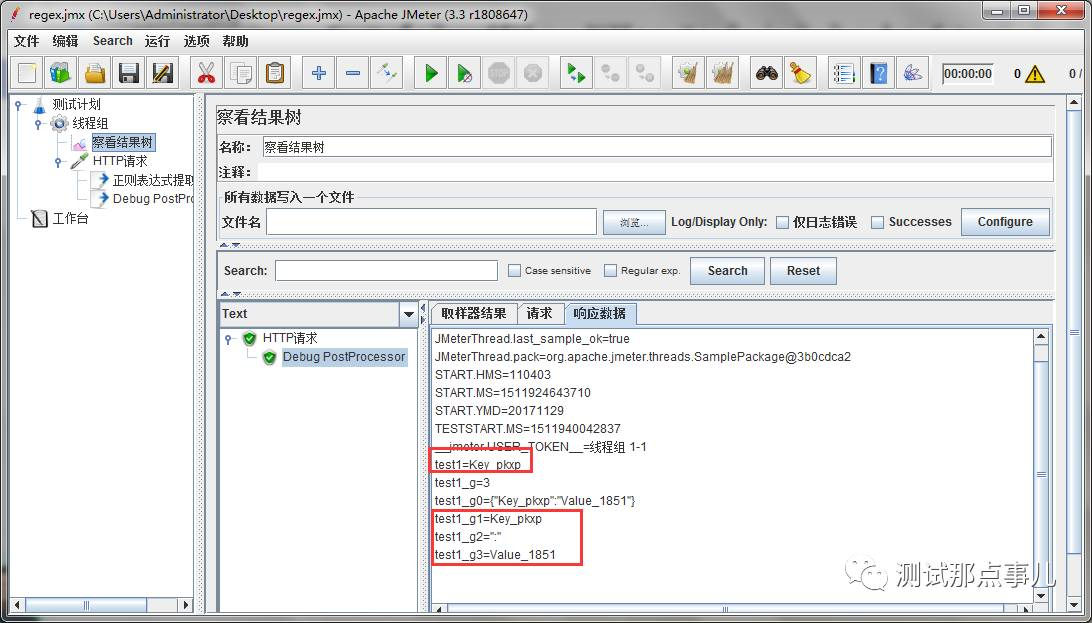
test1匹配到了3组结果,而每组对应的值符合我们的分组预期。成功!
正则表达式:
{"(.{8})(.{3})(.{10})"}
(.{8}):任意字符匹配8次,对应匹配结果中的前8位字符(key值)
(.{3}):任意字符匹配3次,对应匹配结果中的第9-11位字符(":")
(.{10}):任意字符匹配10次,对应匹配结果中的12-21位字符(value值)
那么,回到刚才的例子,从身份证号码中取出生日,对应的正则表达式为:
(.{6})(.{8})(.{3})(.)
匹配第二组→$2$
结果请大家自己实验。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号