Python基础—网络编程
一、前引
你现在已经学会了写python代码,假如你写了两个python文件a.py和b.py,分别去运行,你就会发现,这两个python的文件分别运行的很好。但是如果这两个程序之间想要传递一个数据,你要怎么做呢?
这个问题以你现在的知识就可以解决了,我们可以创建一个文件,把a.py想要传递的内容写到文件中,然后b.py从这个文件中读取内容就可以了。
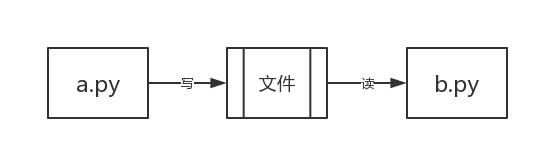
但是当你的a.py和b.py分别在不同电脑上的时候,你要怎么办呢?
类似的机制有计算机网盘,qq等等。我们可以在我们的电脑上和别人聊天,可以在自己的电脑上向网盘中上传、下载内容。这些都是两个程序在通信。
二、软件开发的架构
我们了解的涉及到两个程序之间通讯的应用大致可以分为两种:
第一种是应用类:qq、微信、网盘、优酷这一类是属于需要安装的桌面应用
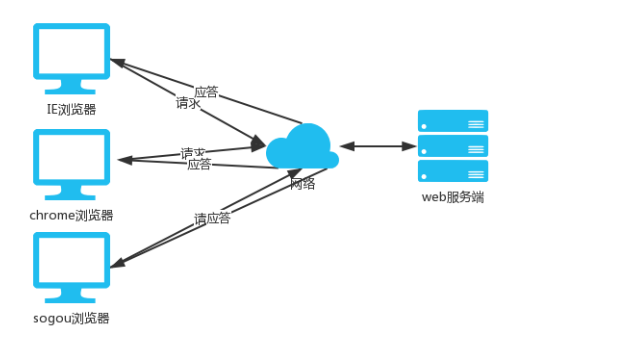
第二种是web类:比如百度、知乎、博客园等使用浏览器访问就可以直接使用的应用
这些应用的本质其实都是两个程序之间的通讯。而这两个分类又对应了两个软件开发的架构~
1.C/S架构
C/S:即Client与Server ,中文意思:客户端与服务器端架构,这种架构也是从用户层面(也可以是物理层面)来划分的。
这里的客户端一般泛指客户端应用程序EXE,程序需要先安装后,才能运行在用户的电脑上,对用户的电脑操作系统环境依赖较大。

2.B/S架构
B/S:即Browser与Server,中文意思:浏览器端与服务器端架构,这种架构是从用户层面来划分的。
Browser浏览器,其实也是一种Client客户端,只是这个客户端不需要大家去安装什么应用程序,只需在浏览器上通过HTTP请求服务器端相关的资源(网页资源),客户端Browser浏览器就能进行增删改查。
三、网络通信原理
1.前引
我们知道一个完整的计算机系统是由硬件、操作系统、应用软件三者组成,具备了这三个条件,一台计算机系统就可以自己跟自己玩了
如果你要跟别人一起玩,那你就需要上网了,什么是互联网?
互联网的核心就是由一堆协议组成,协议就是标准,比如全世界人通信的标准是英语,如果把计算机比作人,互联网协议就是计算机界的英语。所有的计算机都学会了互联网协议,那所有的计算机都就可以按照统一的标准去收发信息从而完成通信了。
2.互联网的本质:一系列的网络协议
一台硬设有了操作系统,然后装上软件你就可以正常使用了,然而你也只能自己使用
像这样,每个人都拥有一台自己的机器,然而彼此孤立

如何能一起玩耍

其实两台计算机之间通信与两个人打电话之间通信的原理是一样的(中国有很多地区,不同的地区有不同的方言,为了全中国人都可以听懂,大家统一讲普通话)
普通话属于中国国内人与人之间通信的标准,那如果是两个国家的人交流呢?当然,你不可能要求一个人/计算机掌握全世界的语言/标准,于是有了世界统一的通信标准:英语
结论
英语成为世界上所有人通信的统一标准,如果把计算机看成分布于世界各地的人,那么连接两台计算机之间的internet实际上就是
一系列统一的标准,这些标准称之为互联网协议。
互联网的本质就是一系列的协议,总称为‘互联网协议’(Internet Protocol Suite).
互联网协议的功能:定义计算机如何接入internet,以及接入internet的计算机通信的标准。
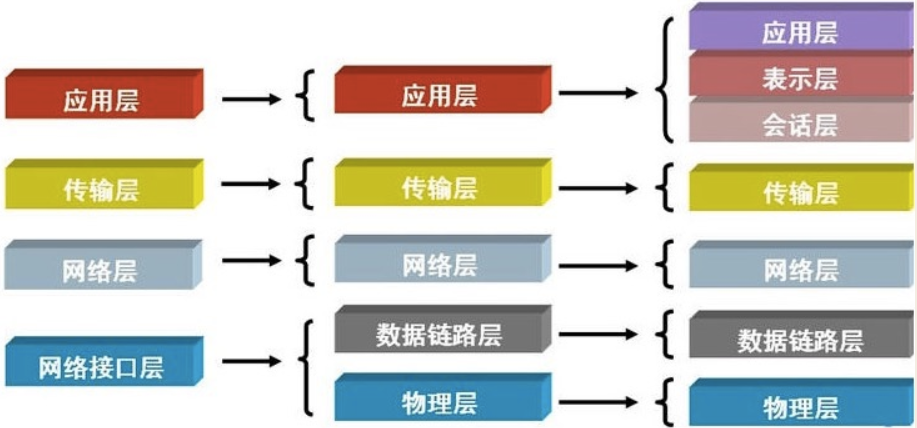
3.osi七层协议
互联网协议按照功能不同分为osi七层或tcp/ip五层或tcp/ip四层
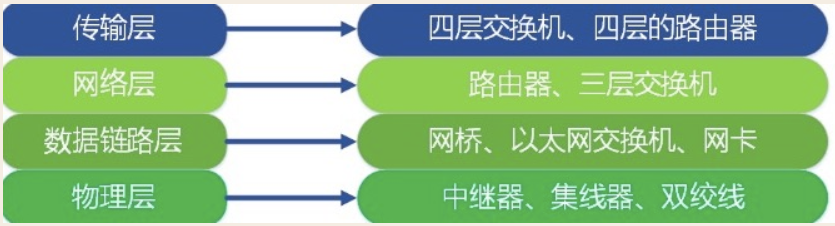
每层运行对应的物理设备:
4.tcp/ip五层模型解析
我们将应用层,表示层,会话层并作应用层,从tcp/ip五层协议的角度来阐述每层的由来与功能,搞清楚了每层的主要协议
就理解了整个互联网通信的原理。
首先,用户感知到的只是最上面一层应用层,自上而下每层都依赖于下一层,所以我们从最下一层开始切入,比较好理解
每层都运行特定的协议,越往上越靠近用户,越往下越靠近硬件。
物理层
物理层由来:上面提到,孤立的计算机之间要想一起玩,就必须接入internet,言外之意就是计算机之间必须完成组网

物理层功能:主要是基于电器特性发送高低电压(电信号),高电压对应数字1,低电压对应数字0。
数据链路层
数据链路层由来:单纯的电信号0和1没有任何意义,必须规定电信号多少位一组,每组什么意思
数据链路层的功能:定义了电信号的分组方式。
以太网协议
早期的时候各个公司都有自己的分组方式,后来形成了统一的标准,即以太网协议ethernet
以太网协议ethernet规定:
- 一组电信号构成一个数据包,叫做‘帧’
- 每一数据帧分成:报头head和数据data两部分
| head | data |
head包含:(固定18个字节)
- 发送者/源地址,6个字节
- 接收者/目标地址,6个字节
- 数据类型,6个字节
data包含:(最短46字节,最长1500字节)
- 数据包的具体内容
head长度+data长度=最短64字节,最长1518字节,超过最大限制就分片发送
head中包含的源和目标地址由来:ethernet规定接入internet的设备都必须具备网卡,发送端和接收端的地址便是指网卡的地址,即mac地址
mac地址
每块网卡出厂时都被烧制上一个世界唯一的mac地址,长度为48位2进制,通常由12位16进制数表示(前六位是厂商编号,后六位是流水线号)
广播
有了mac地址,同一网络内的两台主机就可以通信了(一台主机通过arp协议获取另外一台主机的mac地址)
ethernet采用最原始的方式,广播的方式进行通信,即计算机通信基本靠吼
在物理设备中,完成广播功能的设备就是交换机。
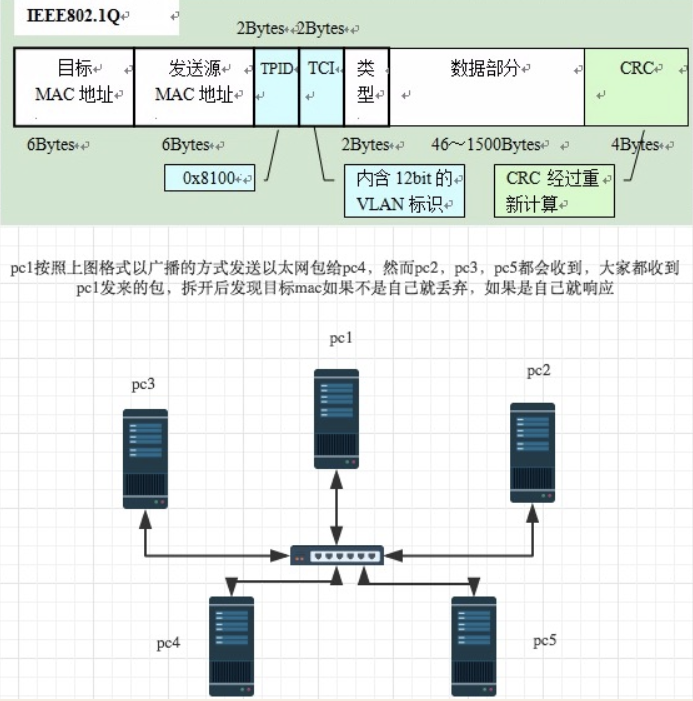
网络层
网络层由来
有了ethernet、mac地址、广播的发送方式,世界上的计算机就可以彼此通信了
问题是世界范围的互联网是由一个个彼此隔离的小的局域网组成的
那么如果所有的通信都采用以太网的广播方式,那么一台机器发送的包全世界都会收到,这就不仅仅是效率低的问题了,这会是一种灾难。

上图结论:必须找出一种方法来区分哪些计算机属于同一广播域,哪些不是,如果是就采用广播的方式发送,如果不是,就采用路由的方式(向不同广播域/子网分发数据包),mac地址是无法区分的,它只跟厂商有关
网络层功能:引入一套新的地址用来区分不同的广播域/子网,这套地址即网络地址。
ip协议
- 规定网络地址的协议叫ip协议,它定义的地址称之为ip地址,广泛采用的v4版本即ipv4,它规定网络地址由32位2进制表示
- 范围0.0.0.0-255.255.255.255
- 一个ip地址通常写成四段十进制数,例:172.16.10.1
ip地址组成
- 网络部分:标识子网
- 主机部分:标识主机
注意:单纯的ip地址段只是标识了ip地址的种类,从网络部分或主机部分都无法辨识一个ip所处的子网
例:172.16.10.1与172.16.10.2并不能确定二者处于同一子网
子网掩码
所谓”子网掩码”,就是表示子网络特征的一个参数。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。
比如,IP地址172.16.10.1,如果已知网络部分是前24位,主机部分是后8位,那么子网络掩码就是11111111.11111111.11111111.00000000,写成十进制就是255.255.255.0。
知道”子网掩码”,我们就能判断,任意两个IP地址是否处在同一个子网络。
判断是否同一子网
将两个IP地址与子网掩码分别进行AND运算(两个数位都为1,运算结果为1,否则为0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
''' 比如,已知IP地址172.16.10.1和172.16.10.2的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码 ''' 分别进行AND运算, 172.16.10.1:10101100.00010000.00001010.000000001 255255.255.255.0:11111111.11111111.11111111.00000000 AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0 172.16.10.2:10101100.00010000.00001010.000000010 255255.255.255.0:11111111.11111111.11111111.00000000 AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0
结果都是172.16.10.0,因此它们在同一个子网络。
总结一下,IP协议的作用主要有两个,一个是为每一台计算机分配IP地址,另一个是确定哪些地址在同一个子网络。
ip数据包
ip数据包也分为head和data部分,无须为ip包定义单独的栏位,直接放入以太网包的data部分
- head:长度为20到60字节
- data:最长为65,515字节。
| 以太网头 | ip 头 | ip数据 |
以太网数据包的”数据”部分,最长只有1500字节。因此,如果IP数据包超过了1500字节,它就需要分割成几个以太网数据包,分开发送了。
arp协议
arp协议由来:计算机通信基本靠吼,即广播的方式,所有上层的包到最后都要封装上以太网头,然后通过以太网协议发送,
在谈及以太网协议时候,我门了解到通信是基于mac的广播方式实现,计算机在发包时,获取自身的mac是容易的,如何获取目标主机的mac,就需要通过arp协议
arp协议功能:广播的方式发送数据包,获取目标主机的mac地址。
协议工作的前提:每台主机ip都是已知的
例如:主机172.16.10.10/24 访问172.16.10.11/24
1、首先通过ip地址和子网掩码区分出自己所处的子网
| 场景 | 数据包地址 |
| 同一子网 | 目标主机mac,目标主机ip |
| 不同子网 | 网关mac,目标主机ip |
2、分析172.16.10.10/24与172.16.10.11/24处于同一网络(如果不是同一网络,那么下表中目标ip为172.16.10.1,通过arp获取的是网关的mac)
其中:FF:FF:FF:FF:FF:FF,代表网关地址,在下面的意思是需要找一个mac地址
| 源mac | 目标mac | 源ip | 目标ip | 数据部分 | |
| 发送端主机 | 发送端mac | FF:FF:FF:FF:FF:FF | 172.16.10.10/24 | 172.16.10.11/24 | 数据 |
3、这个包会以广播的方式在发送端所处的自网内传输,所有主机接收后拆开包,发现目标ip为自己的,就响应,返回自己的mac
跨网络通信如何获取mac地址
本质上在网络通信之前,计算机会有一个步骤,计算源ip和目标ip是否同属于一个局域网内,通过上面讲过的子网掩码。
如果发现在同一区域内,采取上面方法获取目标mac地址。
如果发现不在同一局域网内,这时,我们发送数据包的时候会直接发送给网关,目标ip地址会变成网关的ip地址。
| 源mac | 目标mac | 源ip | 目标ip | 数据部分 | |
| 发送端主机 | 发送端mac | FF:FF:FF:FF:FF:FF | 172.16.10.10/24 | 网关ip:255.255.255.255 | 数据 |
网关获取到这条数据包时,知道我们是要跨网络通信,网关会将自己的mac地址返回给我们,我们接受到后,会给网关发送另外一个数据包,目标mac直接填网关的,而目标ip是我们想要发送的目标对象,比如老王。
| 源mac | 目标mac | 源ip | 目标ip | 数据部分 | |
| 发送端主机 | 发送端mac | 网关mac地址 | 172.16.10.10/24 | 172.16.13.151/24 | 数据 |
网关接受到后,会通过路由跟其他局域网中的网关通信。从而找到目标对象的mac地址,并返回。这个过程中本质上是网关在对外发送这个数据包,但是用户感觉不到。
传输层
传输层的由来
网络层的ip帮我们区分子网,以太网层的mac帮我们找到主机,然后大家使用的都是应用程序,你的电脑上可能同时开启qq,暴风影音,等多个应用程序,
那么我们通过ip和mac找到了一台特定的主机,如何标识这台主机上的应用程序,答案就是端口,端口即应用程序与网卡关联的编号。
传输层功能:建立端口到端口的通信
补充:端口范围0-65535,0-1023为系统占用端口
基于端口的两种协议:tcp和udp协议。
tcp协议(Transmission Control Protocol)
特点:可靠的、面向连接的协议(eg:打电话)、传输效率低全双工通信(发送缓存&接收缓存)、面向字节流。
- 面向连接:两台机器要想传递,必须先建立连接,在连接的基础上进行信息的传递。
- 可靠传输:数据不丢失,不会重复被接收
- 慢:每一次发送的数据还要等待结果
TCP数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常TCP数据包的长度不会超过IP数据包的长度,以确保单个TCP数据包不必再分割。
场景:发送邮件/文件
| 以太网头 | ip 头 | tcp头 | 数据 |
udp协议(User Datagram Protocol)
特点:不可靠的、无连接的服务,传输效率高(发送前时延小),一对一、一对多、多对一、多对多、面向报文,尽最大努力服务,无拥塞控制
- 无连接:机器之间传递信息不需要建立连接,直接发送就行。
- 不可靠传输:数据有可能丢失
- ”报头”部分一共只有8个字节,总长度不超过65,535字节,正好放进一个IP数据包。
场景:即时通讯类的软件:QQ、微信、yy、域名系统 (DNS)
| 以太网头 | ip头 | udp头 | 数据 |
tcp报文

tcp三次握手和四次挥手
建立链接三次握手:SYN(synchronous建立联机):建立连接请求,ACK(acknowledgement确认):回复消息
断开链接四次挥手:FIN(finish结束):断开链接请求,ACK(acknowledgement确认):回复消息

应用层
应用层由来
用户使用的都是应用程序,均工作于应用层,互联网是开发的,大家都可以开发自己的应用程序,数据多种多样,必须规定好数据的组织形式
应用层功能:规定应用程序的数据格式。
例:TCP协议可以为各种各样的程序传递数据,比如Email、WWW、FTP等等。那么,必须有不同协议规定电子邮件、网页、FTP数据的格式,这些应用程序协议就构成了”应用层”。

三、socket理论知识
5.初识socket
网络通信如何实现
我们知道两个进程如果需要进行通讯最基本的一个前提能能够唯一的标示一个进程,在本地进程通讯中我们可以使用PID来唯一标示一个进程,但PID只在本地唯一,网络中的两个进程PID冲突几率很大,这时候我们需要另辟它径了,我们知道IP层的ip地址可以唯一标示主机,而TCP层协议和端口号可以唯一标示主机的一个进程,这样我们可以利用ip地址+协议+端口号唯一标示网络中的一个进程。
能够唯一标示网络中的进程后,它们就可以利用socket进行通信了,什么是socket呢?我们经常把socket翻译为套接字,socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信。
socket层的意义
通俗的说:socket就是位于应用层和网络层,帮我将发送的数据封装好TCP/UDP头(区分端口)、IP头(区分局域网)、以太网头(区分MAC地址)的一个抽象层。有了socket我们开发应用程序进行网络传输时无需自己封装数据的各种协议头,只需要调用socket为我们封装好的接口,从而极大简化了开发的效率。
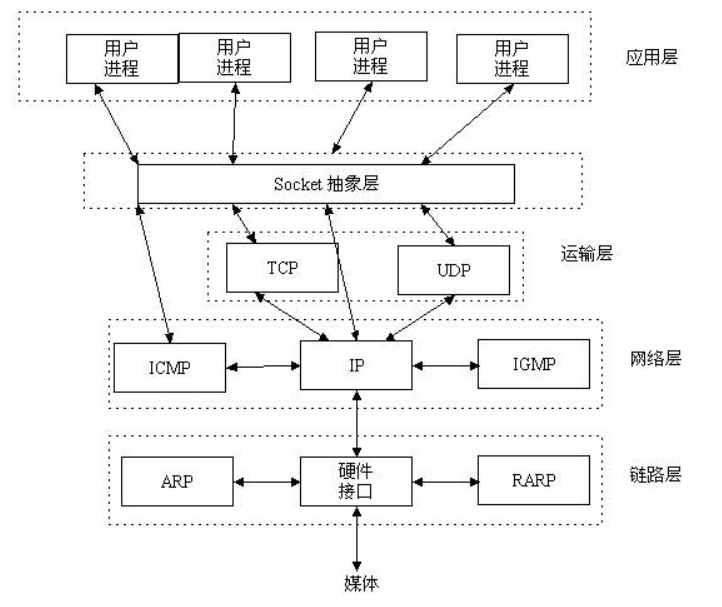
socket起源于UNIX,在Unix一切皆文件哲学的思想下,socket是一种"打开—读/写—关闭"模式的实现,服务器和客户端各自维护一个"文件",在建立连接打开后,可以向自己文件写入内容供对方读取或者读取对方内容,通讯结束时关闭文件。
2.理解socket
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。


其实站在你的角度上看,socket就是一个模块。我们通过调用模块中已经实现的方法建立两个进程之间的连接和通信。 也有人将socket说成ip+port,因为ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序。 所以我们只要确立了ip和port就能找到一个应用程序,并且使用socket模块来与之通信。
3.套接字socket的发展
套接字起源于 20 世纪 70 年代加利福尼亚大学伯克利分校版本的 Unix,即人们所说的 BSD Unix。 因此,有时人们也把套接字称为“伯克利套接字”或“BSD 套接字”。一开始,套接字被设计用在同 一台主机上多个应用程序之间的通讯。这也被称进程间通讯,或 IPC。套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的。
基于文件类型的套接字家族
套接字家族的名字:AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
基于网络类型的套接字家族
套接字家族的名字:AF_INET
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我们只使用AF_INET)
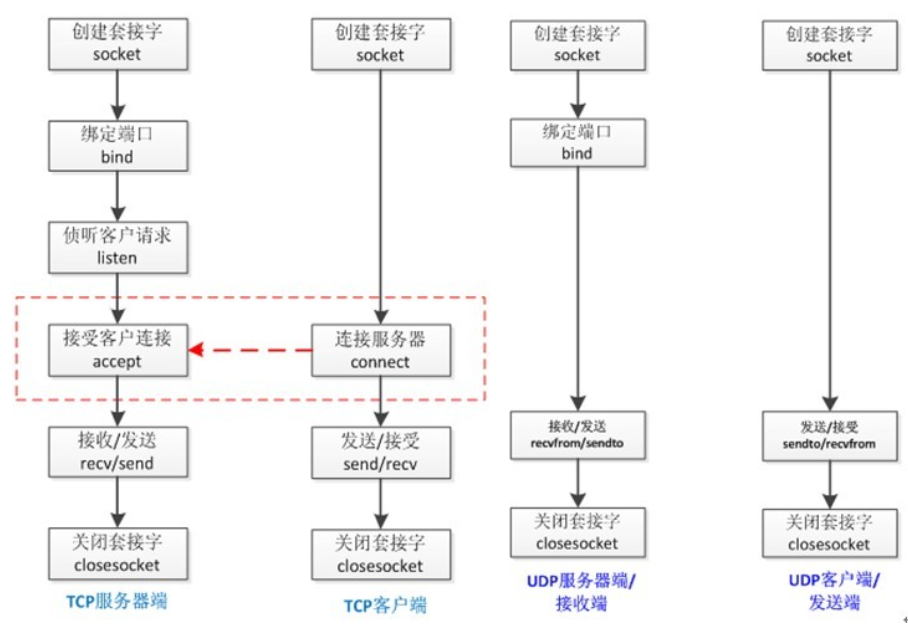
套接字socket和tcp、udp协议工作图
4.套接字常用操作
socket模块函数用法
import socket socket.socket(socket_family,socket_type,protocal=0) socket_family 可以是 AF_UNIX 或 AF_INET。socket_type 可以是 SOCK_STREAM 或 SOCK_DGRAM。protocol 一般不填,默认值为 0。 获取tcp/ip套接字 tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 获取udp/ip套接字 udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) 由于 socket 模块中有太多的属性。我们在这里破例使用了'from module import *'语句。使用 'from socket import *',我们就把 socket 模块里的所有属性都带到我们的命名空间里了,这样能 大幅减短我们的代码。 例如tcpSock = socket(AF_INET, SOCK_STREAM)
服务端套接字函数
- s.bind() 绑定(主机,端口号)到套接字
- s.listen() 开始TCP监听
- s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
客户端套接字函数
- s.connect() 主动初始化TCP服务器连接
- s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
- s.recv() 接收TCP数据
- s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
- s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
- s.recvfrom() 接收UDP数据
- s.sendto() 发送UDP数据
- s.getpeername() 连接到当前套接字的远端的地址
- s.getsockname() 当前套接字的地址
- s.getsockopt() 返回指定套接字的参数
- s.setsockopt() 设置指定套接字的参数
- s.close() 关闭套接字
面向锁的套接字方法
- s.setblocking() 设置套接字的阻塞与非阻塞模式
- s.settimeout() 设置阻塞套接字操作的超时时间
- s.gettimeout() 得到阻塞套接字操作的超时时间
面向文件的套接字的函数
- s.fileno() 套接字的文件描述符
- s.makefile() 创建一个与该套接字相关的文件
五、套接字(socket)使用
1.基于TCP协议的socket
TCP是基于连接的,必须先启动服务端,然后在启动客户端去连接服务端
server端
import socket sk = socket.socket() sk.bind(('127.0.0.1',8898)) #把地址绑定到套接字 sk.listen() #监听链接 conn,addr = sk.accept() #接受客户端链接 ret = conn.recv(1024) #接收客户端信息 print(ret) #打印客户端信息 conn.send(b'hi') #向客户端发送信息 conn.close() #关闭客户端套接字 sk.close() #关闭服务器套接字(可选)
client端
import socket sk = socket.socket() # 创建客户套接字 sk.connect(('127.0.0.1',8898)) # 尝试连接服务器 sk.send(b'hello!') ret = sk.recv(1024) # 对话(发送/接收) print(ret) sk.close() # 关闭客户套接字
重启服务可能遇到的问题

解决方法
#加入一条socket配置,重用ip和端口 import socket from socket import SOL_SOCKET,SO_REUSEADDR sk = socket.socket() sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加 sk.bind(('127.0.0.1',8898)) #把地址绑定到套接字 sk.listen() #监听链接 conn,addr = sk.accept() #接受客户端链接 ret = conn.recv(1024) #接收客户端信息 print(ret) #打印客户端信息 conn.send(b'hi') #向客户端发送信息 conn.close() #关闭客户端套接字 sk.close() #关闭服务器套接字(可选)
2.基于UDP协议的socket
udp是无连接的,启动服务器之后可以直接发送接收消息,不需要提前建立连接
server端
import socket udp_sk = socket.socket(type=socket.SOCK_DGRAM) #创建一个服务器的套接字 udp_sk.bind(('127.0.0.1',9000)) #绑定服务器套接字 msg,addr = udp_sk.recvfrom(1024) print(msg) udp_sk.sendto(b'hi',addr) # 对话(接收与发送) udp_sk.close() # 关闭服务器套接字
client端
import socket ip_port=('127.0.0.1',9000) udp_sk=socket.socket(type=socket.SOCK_DGRAM) udp_sk.sendto(b'hello',ip_port) back_msg,addr=udp_sk.recvfrom(1024) print(back_msg.decode('utf-8'),addr)
qq聊天实现
import socket ip_port=('127.0.0.1',8081) udp_server_sock=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) #买手机 udp_server_sock.bind(ip_port) while True: qq_msg,addr=udp_server_sock.recvfrom(1024) print('来自[%s:%s]的一条消息:\033[1;44m%s\033[0m' %(addr[0],addr[1],qq_msg.decode('utf-8'))) back_msg=input('回复消息: ').strip() udp_server_sock.sendto(back_msg.encode('utf-8'),addr)
import socket BUFSIZE=1024 udp_client_socket=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) qq_name_dic={ '狗哥alex':('127.0.0.1',8081), '瞎驴':('127.0.0.1',8081), '一棵树':('127.0.0.1',8081), '武大郎':('127.0.0.1',8081), } while True: qq_name=input('请选择聊天对象: ').strip() while True: msg=input('请输入消息,回车发送: ').strip() if msg == 'quit':break if not msg or not qq_name or qq_name not in qq_name_dic:continue udp_client_socket.sendto(msg.encode('utf-8'),qq_name_dic[qq_name]) back_msg,addr=udp_client_socket.recvfrom(BUFSIZE) print('来自[%s:%s]的一条消息:\033[1;44m%s\033[0m' %(addr[0],addr[1],back_msg.decode('utf-8'))) udp_client_socket.close()
import socket BUFSIZE=1024 udp_client_socket=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) qq_name_dic={ '狗哥alex':('127.0.0.1',8081), '瞎驴':('127.0.0.1',8081), '一棵树':('127.0.0.1',8081), '武大郎':('127.0.0.1',8081), } while True: qq_name=input('请选择聊天对象: ').strip() while True: msg=input('请输入消息,回车发送: ').strip() if msg == 'quit':break if not msg or not qq_name or qq_name not in qq_name_dic:continue udp_client_socket.sendto(msg.encode('utf-8'),qq_name_dic[qq_name]) back_msg,addr=udp_client_socket.recvfrom(BUFSIZE) print('来自[%s:%s]的一条消息:\033[1;44m%s\033[0m' %(addr[0],addr[1],back_msg.decode('utf-8'))) udp_client_socket.close()
3.socket参数详解
socket.socket(family=AF_INET,type=SOCK_STREAM,proto=0,fileno=None)
创建socket对象的参数说明
| 说明 | |
|---|---|
| family | 地址系列应为AF_INET(默认值),AF_INET6,AF_UNIX,AF_CAN或AF_RDS。 |
| type | 套接字类型应为SOCK_STREAM(默认值) SOCK_STREAM 是基于TCP的,有保障的,面向连接的SOCKET,多用于资料传送。 SOCK_DGRAM 是基于UDP的,无保障的面向消息的socket,多用于在网络上发广播信息。 |
| proto | 协议号通常为零,可以省略,或者在地址族为AF_CAN的情况下,协议应为CAN_RAW或CAN_BCM之一。 |
| fileno | 如果指定了fileno,则其他参数将被忽略,导致带有指定文件描述符的套接字返回。 与socket.fromfd()不同,fileno将返回相同的套接字,而不是重复的。 |
六、黏包
1.黏包现象
什么是黏包
让我们基于tcp先制作一个远程执行命令的程序(1:执行错误命令 2:执行ls 3:执行ifconfig)
注意:命令ls -l ; lllllll ; pwd 的结果是既有正确stdout结果,又有错误stderr结果
'''注意 注意''' res=subprocess.Popen(cmd.decode('utf-8'), shell=True, stderr=subprocess.PIPE, stdout=subprocess.PIPE)
上述结果的编码是以当前所在的系统为准的,如果是windows,那么res.stdout.read()读出的就是GBK编码的,在接收端需要用GBK解码,且只能从管道里读一次结果。
#_*_coding:utf-8_*_ from socket import * import subprocess ip_port=('127.0.0.1',8080) BUFSIZE=1024 tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) while True: conn,addr=tcp_socket_server.accept() print('客户端',addr) while True: cmd=conn.recv(BUFSIZE) if len(cmd) == 0:break res=subprocess.Popen(cmd.decode('utf-8'),shell=True, stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE) stderr=act_res.stderr.read() stdout=act_res.stdout.read() conn.send(stderr) conn.send(stdout)
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) while True: msg=input('>>: ').strip() if len(msg) == 0:continue if msg == 'quit':break s.send(msg.encode('utf-8')) act_res=s.recv(BUFSIZE) print(act_res.decode('utf-8'),end='')
上述程序是基于tcp的socket,在运行时会发生粘包
让我们再基于udp制作一个远程执行命令的程序
#_*_coding:utf-8_*_ from socket import * import subprocess ip_port=('127.0.0.1',9003) bufsize=1024 udp_server=socket(AF_INET,SOCK_DGRAM) udp_server.bind(ip_port) while True: #收消息 cmd,addr=udp_server.recvfrom(bufsize) print('用户命令----->',cmd) #逻辑处理 res=subprocess.Popen(cmd.decode('utf-8'),shell=True,stderr=subprocess.PIPE,stdin=subprocess.PIPE,stdout=subprocess.PIPE) stderr=res.stderr.read() stdout=res.stdout.read() #发消息 udp_server.sendto(stderr,addr) udp_server.sendto(stdout,addr) udp_server.close()
from socket import * ip_port=('127.0.0.1',9003) bufsize=1024 udp_client=socket(AF_INET,SOCK_DGRAM) while True: msg=input('>>: ').strip() udp_client.sendto(msg.encode('utf-8'),ip_port) data,addr=udp_client.recvfrom(bufsize) print(data.decode('utf-8'),end='')
上述程序是基于udp的socket,在运行时永远不会发生粘包
概念
同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令的时候又接收到之前执行的另外一部分结果,这种现象就是黏包。
只有TCP有粘包现象,UDP永远不会粘包
2.黏包问题的本质
socket收发消息原理

发送端发送的消息可以是字节流(stream)的形式,也可以是数据整体的形式:
- TCP协议是面向流的协议,这也是容易出现粘包问题的原因。
- UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。
当基于tcp发送消息时,文件内容是按照一段一段的字节流发送的,在接收方看来,根本不知道该文件的字节流从何处开始,在何处结束,导致数据的黏包现象。
此外,发送方引起的粘包是由TCP协议本身造成的,TCP协议中存在两个机制:合包机制和拆包机制
合包机制
TCP协议为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。这种合并数据就是合包机制。
拆包机制
TCP协议在从获取数据的时候,如果数据过大,socket并不会一次取走全部数据,而是拿走一部分数据,剩余数据会在下一次提取数据时候再取走,从而导致剩余数据和后面数据的黏包。
所谓粘包问题本质还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
tcp协议中的数据传递
TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。
收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。
这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
udp协议中的数据传递
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。
不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),
这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
对于空消息而言
tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住。
而udp是基于数据报的,即便是你输入的是空内容(直接回车),也可以被发送,udp协议会帮你封装上消息头发送过去。
可靠黏包的tcp协议:tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。
补充说明(了解)
1.tcp和udp一次发送数据长度
用UDP协议发送时,用sendto函数最大能发送数据的长度为:65535- IP头(20) – UDP头(8)=65507字节。用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。(丢弃这个包,不进行发送)
用TCP协议发送时,由于TCP是数据流协议,因此不存在包大小的限制(暂不考虑缓冲区的大小),这是指在用send函数时,数据长度参数不受限制。而实际上,所指定的这段数据并不一定会一次性发送出去,如果这段数据比较长,会被分段发送,如果比较短,可能会等待和下一次数据一起发送。
2.为何tcp可靠,udp不可靠
tcp在数据传输时,发送端先把数据发送到自己的缓存中,然后协议控制将缓存中的数据发往对端,对端返回一个ack=1,发送端则清理缓存中的数据,对端返回ack=0,则重新发送数据,所以tcp是可靠的
而udp发送数据,对端是不会返回确认信息的,因此不可靠
详细知识参考林海峰老师博客:http://www.cnblogs.com/linhaifeng/articles/5937962.html
3.send(字节流)和recv(1024)及sendall
recv里指定的1024意思是从缓存里一次拿出1024个字节的数据
send的字节流是先放入己端缓存,然后由协议控制将缓存内容发往对端,如果待发送的字节流大小大于缓存剩余空间,那么数据丢失
使用sendall就会循环调用send,数据不会丢失。
3.发生黏包的两种情况
1.发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(10) data2=conn.recv(10) print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello'.encode('utf-8')) s.send('feng'.encode('utf-8'))
2.接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(2) #一次没有收完整 data2=conn.recv(10)#下次收的时候,会先取旧的数据,然后取新的 print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello feng'.encode('utf-8'))
4.黏包解决方法
普通解决方法
问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据。
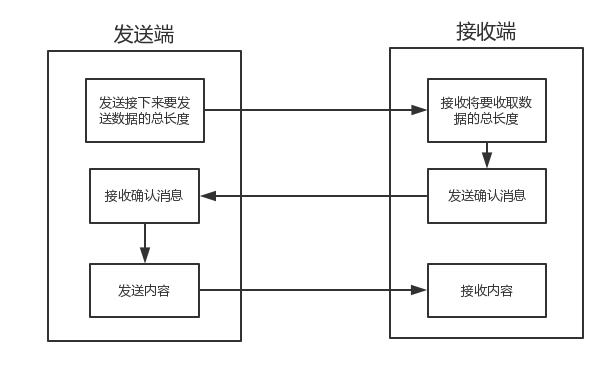
存在的问题: 程序的运行速度远快于网络传输速度,所以在发送一段字节前,先用send去发送该字节流长度,这种方式会放大网络延迟带来的性能损耗
进阶解决方案
利用struct模块,这个模块可以把要发送的数据长度转换成固定长度的字节。这样客户端每次接收消息之前只要先接受这个固定长度字节的内容看一看接下来要接收的信息大小,那么最终接受的数据只要达到这个值就停止,就能刚好不多不少的接收完整的数据了。
struct模块
struct模块可以将一个整数数字变成固定4个字节长度的bytes数据。也可以将4个字节长度的bytes数据解包成整数数字。
常用语法
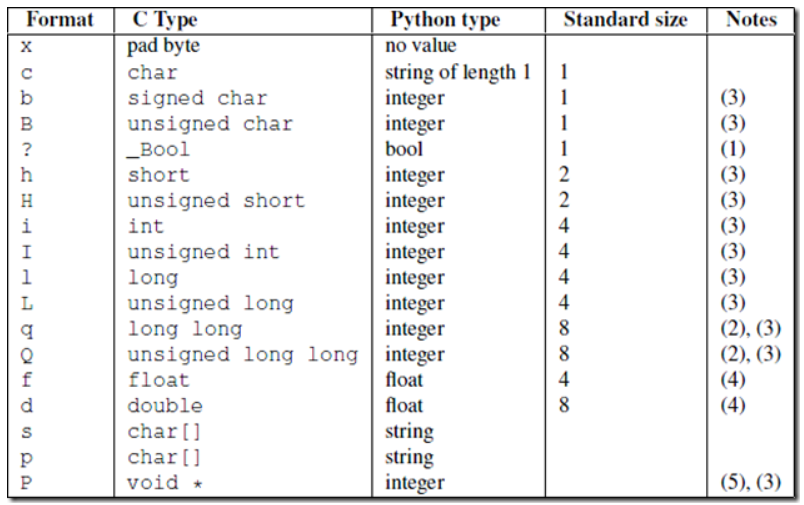
import struct # 将一个整数转化为固定4个字节长度的bytes bytes_len = struct.pack('i', number) # 将一个4字节长度的bytes反解成一个整数 number = struct.unpack('i', bytes_len)[0]
使用实例!
struct.pack('i',1111111111111) struct.error: 'i' format requires -2147483648 <= number <= 2147483647 #这个是范围
通过客户端上传文件示例
import json,struct #假设通过客户端上传1T:1073741824000的文件a.txt #为避免粘包,必须自定制报头 header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值 #为了该报头能传送,需要序列化并且转为bytes head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输 #为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节 head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度 #客户端开始发送 conn.send(head_len_bytes) #先发报头的长度,4个bytes conn.send(head_bytes) #再发报头的字节格式 conn.sendall(文件内容) #然后发真实内容的字节格式 #服务端开始接收 head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式 x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度 head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式 header=json.loads(json.dumps(header)) #提取报头 #最后根据报头的内容提取真实的数据,比如 real_data_len=s.recv(header['file_size']) s.recv(real_data_len)
#_*_coding:utf-8_*_ #http://www.cnblogs.com/coser/archive/2011/12/17/2291160.html __author__ = 'Linhaifeng' import struct import binascii import ctypes values1 = (1, 'abc'.encode('utf-8'), 2.7) values2 = ('defg'.encode('utf-8'),101) s1 = struct.Struct('I3sf') s2 = struct.Struct('4sI') print(s1.size,s2.size) prebuffer=ctypes.create_string_buffer(s1.size+s2.size) print('Before : ',binascii.hexlify(prebuffer)) # t=binascii.hexlify('asdfaf'.encode('utf-8')) # print(t) s1.pack_into(prebuffer,0,*values1) s2.pack_into(prebuffer,s1.size,*values2) print('After pack',binascii.hexlify(prebuffer)) print(s1.unpack_from(prebuffer,0)) print(s2.unpack_from(prebuffer,s1.size)) s3=struct.Struct('ii') s3.pack_into(prebuffer,0,123,123) print('After pack',binascii.hexlify(prebuffer)) print(s3.unpack_from(prebuffer,0))
使用struct模块解决黏包
借助struct模块,我们知道长度数字可以被转换成一个标准大小的4字节数字。因此可以利用这个特点来预先发送数据长度。
| 发送时 | 接收时 |
| 先发送struct转换好的数据长度4字节 | 先接受4个字节使用struct转换成数字来获取要接收的数据长度 |
| 再发送数据 | 再按照长度接收数据 |
自定义协议客户端
import os import json import struct import socket sk = socket.socket() sk.connect(('127.0.0.1',9001)) filepath = r'D:\PyCharmProject\python全栈S20\day029 网络编程—黏包\04 总结.py' filename = os.path.basename(filepath) filesize = os.path.getsize(filepath) # 将文件的信息存储在字典中 dic = {'filename':filename,'filesize':filesize} # 获取字典json字符串的字节类型 bytes_dic = json.dumps(dic).encode('utf-8') # 获取字典json格式下的字节长度 len_dic = len(bytes_dic) # 通过struct将字典json字符串的bytes长度打包成固定4字节长度 bytes_len = struct.pack('i',len_dic) # 分别发送字节长度和json字典 sk.send(bytes_len) sk.send(bytes_dic) # 打开文件发送读取文件内容并发送 with open(filepath,'rb') as f: content = f.read() sk.send(content) sk.close()
自定义协议服务端
import json import struct import socket sk = socket.socket() sk.bind(('127.0.0.1',9001)) sk.listen() conn,addr = sk.accept() # 接受固定4字节长度的bytes dic_num = conn.recv(4) # 通过struct模块反解4字节bytes获取字典的长度 dic_num = struct.unpack('i',dic_num)[0] # 接受字典数据 str_dic = conn.recv(dic_num).decode('utf-8') dic = json.loads(str_dic) # 通过字典数据获取文件信息 filename = dic['filename'] filesize = dic['filesize'] with open(filename,'wb') as f: content = conn.recv(filesize) f.write(content) conn.close() sk.close()
我们还可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节(4个自己足够用了)
| 发送时 | 接收时 |
|
先发报头长度 |
先收报头长度,用struct取出来 |
| 再编码报头内容然后发送 | 根据取出的长度收取报头内容,然后解码,反序列化 |
| 最后发真实内容 | 从反序列化的结果中取出待取数据的详细信息,然后去取真实的数据内容 |
九、认证客户端的链接合法性
hmac模块
接受两个字节类型的数据,通过特殊算法获得字节类型密文,用于服务器合法性验证
import os import hmac # os.urandom(32)随机生成一个32位的byte类型数据 hmac = hmac.new(b'alexsb',os.urandom(32)) # 通过hmac接受两个byte类型数据,加盐摘要生成密文。 print(hmac.digest()) # 打印密文
验证客户端合法性
import os import hmac import socket # 设置共同的密匙,客户端和服务端一致 secret_key = 'alexsb' # 开启服务器 sk = socket.socket() sk.bind(('127.0.0.1',9001)) sk.listen() # 链接服务器 conn,addr = sk.accept() # 给客户端发送随机的32位byte类型数字 rand = os.urandom(32) conn.send(rand) # 通过hmac摘要算法生成密文 res = hmac.new(secret_key.encode('utf-8'),rand).digest() # 跟客户端发送过来的密文进行比对,正确连接,错误忽略 if res == conn.recv(2014): print('合法客户端') else: print('非法客户端') conn.close() sk.close()
import hmac import socket # 设置共同的密匙,客户端和服务端一致 secret_key = 'alexsb' # 开启客户端 sk = socket.socket() sk.connect(('127.0.0.1',9001)) # 获取服务器发送的随机码byte类型 rand = sk.recv(2014) # 通过hmac根据密匙和随机码摘要生成密文,发送给服务器 res = hmac.new(secret_key.encode('utf-8'),rand).digest() sk.send(res) sk.close()
十、socketserver实现并发
socketserver简单使用
socketserver是基于源生socket进行封装出来一个模块,可以实现并发效果。
注意:使用socketserver方法必须要重写自定类中的handle方法。
客户端代码
与源生socket的客户端写法一致
import socket sk = socket.socket() sk.connect(('127.0.0.1',9001)) while True: sk.send('hello'.encode('utf-8')) msg = sk.recv(1024).decode('utf-8') print(msg) sk.close()
服务端代码
import time import socketserver class Myserver(socketserver.BaseRequestHandler): def handle(self): conn = self.request # self代表每一个链接服务端的对象,conn是代表每一个客户端和服务端直接的链接 for i in range(20): msg = conn.recv(1024).decode('utf-8') print(msg) conn.send('byebye'.encode('utf-8')) time.sleep(0.8) # 使用自定义server类绑定一个ip和端口,并开启监听 类似于socket中的bind和listen sk = socketserver.ThreadingTCPServer(('127.0.0.1',9001),Myserver) # 循环一直等待客户端的链接,类似socket中的accept sk.serve_forever()
socketserver扩展(了解)
基于tcp的套接字,关键就是两个循环,一个链接循环,一个通信循环
socketserver模块中分两大类:server类(解决链接问题)和request类(解决通信问题)
server类:

request类:

继承关系:



以下述代码为例,分析socketserver源码:
ftpserver=socketserver.ThreadingTCPServer(('127.0.0.1',8080),FtpServer) ftpserver.serve_forever()
查找属性的顺序:ThreadingTCPServer->ThreadingMixIn->TCPServer->BaseServer
- 实例化得到ftpserver,先找类ThreadingTCPServer的__init__,在TCPServer中找到,进而执行server_bind,server_active
- 找ftpserver下的serve_forever,在BaseServer中找到,进而执行self._handle_request_noblock(),该方法同样是在BaseServer中
- 执行self._handle_request_noblock()进而执行request, client_address = self.get_request()(就是TCPServer中的self.socket.accept()),然后执行self.process_request(request, client_address)
- 在ThreadingMixIn中找到process_request,开启多线程应对并发,进而执行process_request_thread,执行self.finish_request(request, client_address)
- 上述四部分完成了链接循环,本部分开始进入处理通讯部分,在BaseServer中找到finish_request,触发我们自己定义的类的实例化,去找__init__方法,而我们自己定义的类没有该方法,则去它的父类也就是BaseRequestHandler中找....
源码分析总结
基于tcp的socketserver我们自己定义的类中的
- self.server即套接字对象
- self.request即一个链接
- self.client_address即客户端地址
基于udp的socketserver我们自己定义的类中的
- self.request是一个元组(第一个元素是客户端发来的数据,第二部分是服务端的udp套接字对象),如(b'adsf', <socket.socket fd=200, family=AddressFamily.AF_INET, type=SocketKind.SOCK_DGRAM, proto=0, laddr=('127.0.0.1', 8080)>)
- self.client_address即客户端地址
import socketserver import struct import json import os class FtpServer(socketserver.BaseRequestHandler): coding='utf-8' server_dir='file_upload' max_packet_size=1024 BASE_DIR=os.path.dirname(os.path.abspath(__file__)) def handle(self): print(self.request) while True: data=self.request.recv(4) data_len=struct.unpack('i',data)[0] head_json=self.request.recv(data_len).decode(self.coding) head_dic=json.loads(head_json) # print(head_dic) cmd=head_dic['cmd'] if hasattr(self,cmd): func=getattr(self,cmd) func(head_dic) def put(self,args): file_path = os.path.normpath(os.path.join( self.BASE_DIR, self.server_dir, args['filename'] )) filesize = args['filesize'] recv_size = 0 print('----->', file_path) with open(file_path, 'wb') as f: while recv_size < filesize: recv_data = self.request.recv(self.max_packet_size) f.write(recv_data) recv_size += len(recv_data) print('recvsize:%s filesize:%s' % (recv_size, filesize)) ftpserver=socketserver.ThreadingTCPServer(('127.0.0.1',8080),FtpServer) ftpserver.serve_forever()
import socket import struct import json import os class MYTCPClient: address_family = socket.AF_INET socket_type = socket.SOCK_STREAM allow_reuse_address = False max_packet_size = 8192 coding='utf-8' request_queue_size = 5 def __init__(self, server_address, connect=True): self.server_address=server_address self.socket = socket.socket(self.address_family, self.socket_type) if connect: try: self.client_connect() except: self.client_close() raise def client_connect(self): self.socket.connect(self.server_address) def client_close(self): self.socket.close() def run(self): while True: inp=input(">>: ").strip() if not inp:continue l=inp.split() cmd=l[0] if hasattr(self,cmd): func=getattr(self,cmd) func(l) def put(self,args): cmd=args[0] filename=args[1] if not os.path.isfile(filename): print('file:%s is not exists' %filename) return else: filesize=os.path.getsize(filename) head_dic={'cmd':cmd,'filename':os.path.basename(filename),'filesize':filesize} print(head_dic) head_json=json.dumps(head_dic) head_json_bytes=bytes(head_json,encoding=self.coding) head_struct=struct.pack('i',len(head_json_bytes)) self.socket.send(head_struct) self.socket.send(head_json_bytes) send_size=0 with open(filename,'rb') as f: for line in f: self.socket.send(line) send_size+=len(line) print(send_size) else: print('upload successful') client=MYTCPClient(('127.0.0.1',8080)) client.run()
四、网络通信实现(了解)
想实现网络通信,每台主机需具备四要素
- 本机的IP地址
- 子网掩码
- 网关的IP地址
- DNS的IP地址
获取这四要素分两种方式
- 静态获取:即手动配置
- 动态获取:通过dhcp获取
| 以太网头 | ip头 | udp头 | dhcp数据包 |
- 最前面的”以太网标头”,设置发出方(本机)的MAC地址和接收方(DHCP服务器)的MAC地址。前者就是本机网卡的MAC地址,后者这时不知道,就填入一个广播地址:FF-FF-FF-FF-FF-FF。
- 后面的”IP标头”,设置发出方的IP地址和接收方的IP地址。这时,对于这两者,本机都不知道。于是,发出方的IP地址就设为0.0.0.0,接收方的IP地址设为255.255.255.255。
- 最后的”UDP标头”,设置发出方的端口和接收方的端口。这一部分是DHCP协议规定好的,发出方是68端口,接收方是67端口。
这个数据包构造完成后,就可以发出了。以太网是广播发送,同一个子网络的每台计算机都收到了这个包。因为接收方的MAC地址是FF-FF-FF-FF-FF-FF,看不出是发给谁的,所以每台收到这个包的计算机,还必须分析这个包的IP地址,才能确定是不是发给自己的。当看到发出方IP地址是0.0.0.0,接收方是255.255.255.255,于是DHCP服务器知道”这个包是发给我的”,而其他计算机就可以丢弃这个包。
接下来,DHCP服务器读出这个包的数据内容,分配好IP地址,发送回去一个”DHCP响应”数据包。这个响应包的结构也是类似的,以太网标头的MAC地址是双方的网卡地址,IP标头的IP地址是DHCP服务器的IP地址(发出方)和255.255.255.255(接收方),UDP标头的端口是67(发出方)和68(接收方),分配给请求端的IP地址和本网络的具体参数则包含在Data部分。
新加入的计算机收到这个响应包,于是就知道了自己的IP地址、子网掩码、网关地址、DNS服务器等等参数
五、网络通信流程(了解)
1.本机获取
- 本机的IP地址:192.168.1.100
- 子网掩码:255.255.255.0
- 网关的IP地址:192.168.1.1
- DNS的IP地址:8.8.8.8
2.打开浏览器
想要访问Google,在地址栏输入了网址:www.google.com。
3.dns协议(基于udp协议)

13台根dns
A.root-servers.net198.41.0.4美国
B.root-servers.net192.228.79.201美国(另支持IPv6)
C.root-servers.net192.33.4.12法国
D.root-servers.net128.8.10.90美国
E.root-servers.net192.203.230.10美国
F.root-servers.net192.5.5.241美国(另支持IPv6)
G.root-servers.net192.112.36.4美国
H.root-servers.net128.63.2.53美国(另支持IPv6)
I.root-servers.net192.36.148.17瑞典
J.root-servers.net192.58.128.30美国
K.root-servers.net193.0.14.129英国(另支持IPv6)
L.root-servers.net198.32.64.12美国
M.root-servers.net202.12.27.33日本(另支持IPv6)
域名定义:http://jingyan.baidu.com/article/1974b289a649daf4b1f774cb.html
顶级域名
以.com,.net,.org,.cn等等属于国际顶级域名,根据目前的国际互联网域名体系,国际顶级域名分为两类:类别顶级域名(gTLD)和地理顶级域名(ccTLD)两种。类别顶级域名是以"COM"、"NET"、"ORG"、"BIZ"、"INFO"等结尾的域名,均由国外公司负责管理。地理顶级域名是以国家或地区代码为结尾的域名,如"CN"代表中国,"UK"代表英国。地理顶级域名一般由各个国家或地区负责管理。
二级域名
二级域名是以顶级域名为基础的地理域名,比喻中国的二级域有,.com.cn,.net.cn,.org.cn,.gd.cn等.子域名是其父域名的子域名,比喻父域名是abc.com,子域名就是www.abc.com或者*.abc.com.
一般来说,二级域名是域名的一条记录,比如alidiedie.com是一个域名,www.alidiedie.com是其中比较常用的记录,一般默认是用这个,但是类似*.alidiedie.com的域名全部称作是alidiedie.com的二级
4.HTTP部分的内容
类似于下面这样:
GET / HTTP/1.1
Host: www.google.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1) ……
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3
Cookie: … …
我们假定这个部分的长度为4960字节,它会被嵌在TCP数据包之中。
5 TCP协议
TCP数据包需要设置端口,接收方(Google)的HTTP端口默认是80,发送方(本机)的端口是一个随机生成的1024-65535之间的整数,假定为51775。
TCP数据包的标头长度为20字节,加上嵌入HTTP的数据包,总长度变为4980字节。
6 IP协议
然后,TCP数据包再嵌入IP数据包。IP数据包需要设置双方的IP地址,这是已知的,发送方是192.168.1.100(本机),接收方是172.194.72.105(Google)。
IP数据包的标头长度为20字节,加上嵌入的TCP数据包,总长度变为5000字节。
7 以太网协议
最后,IP数据包嵌入以太网数据包。以太网数据包需要设置双方的MAC地址,发送方为本机的网卡MAC地址,接收方为网关192.168.1.1的MAC地址(通过ARP协议得到)。
以太网数据包的数据部分,最大长度为1500字节,而现在的IP数据包长度为5000字节。因此,IP数据包必须分割成四个包。因为每个包都有自己的IP标头(20字节),所以四个包的IP数据包的长度分别为1500、1500、1500、560。
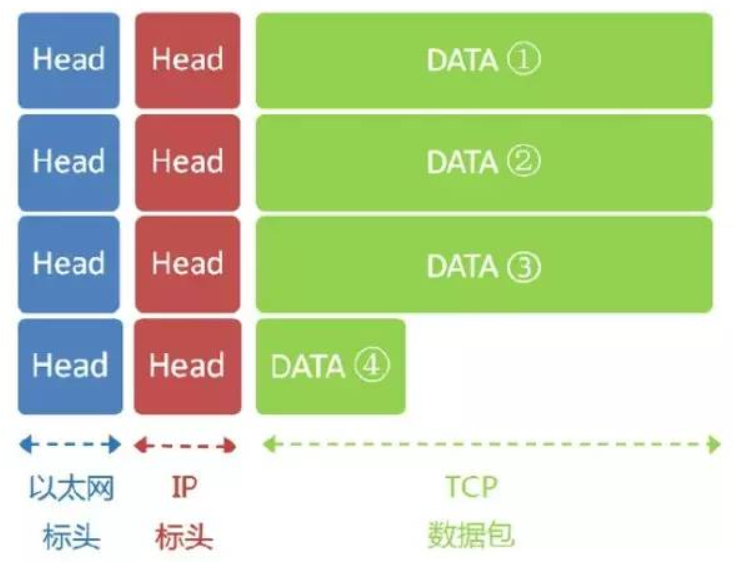
8 服务器端响应
经过多个网关的转发,Google的服务器172.194.72.105,收到了这四个以太网数据包。
根据IP标头的序号,Google将四个包拼起来,取出完整的TCP数据包,然后读出里面的”HTTP请求”,接着做出”HTTP响应”,再用TCP协议发回来。
本机收到HTTP响应以后,就可以将网页显示出来,完成一次网络通信。
