Datawhale|Linux组队学习 任务8-10
Datawhale|Linux组队学习 任务8-10
任务8:使用grep和awk从文件中筛选字符串
任务要点:字符筛选
-
步骤1:下载周杰伦歌词文本,并进行解压。https://mirror.coggle.club/dataset/jaychou_lyrics.txt.zip
使用wget -O zhou.txt.zip https://mirror.coggle.club/dataset/jaychou_lyrics.txt.zip 进行下载并重命名为 zhou.txt.zip
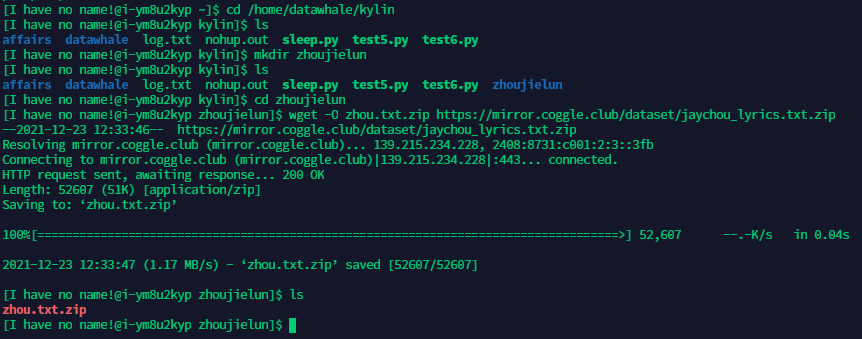
解压:

-
步骤2:利用grep命令完成以下操作,并输出到屏幕https://blog.csdn.net/baidu_41388533/article/details/107610827https://www.runoob.com/linux/linux-comm-grep.html
-
统计歌词中 包含【超人】的歌词

-
统计歌词中 包含【外婆】但不包含【期待】的歌词
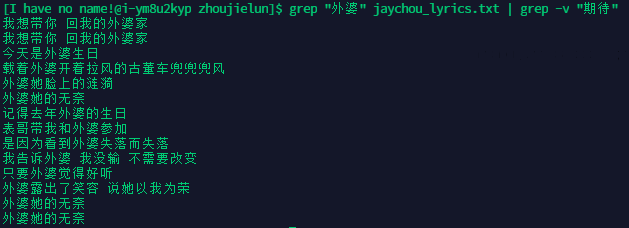
-
统计歌词中 以【我】开头的歌词
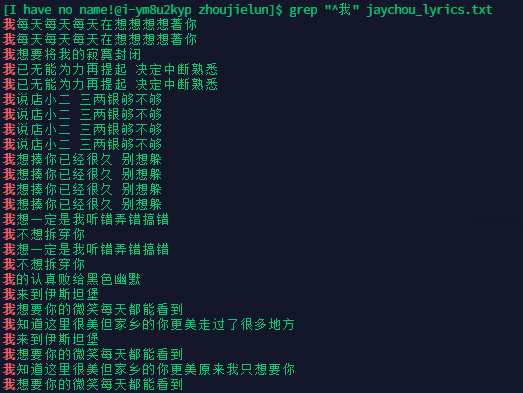
-
统计歌词中 以【我】结尾的歌词
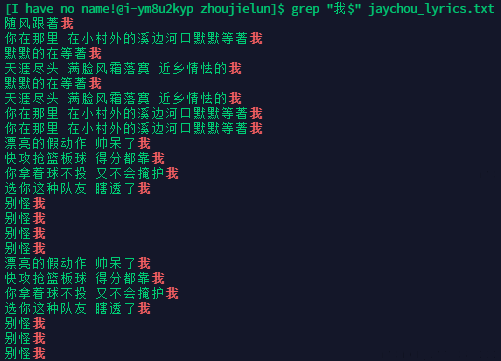
-
-
步骤3:利用sed命令完成以下操作,并输出到屏幕https://www.cnblogs.com/JohnLiang/p/6202962.html
-
将歌词中 第2行 至 第40行 删除
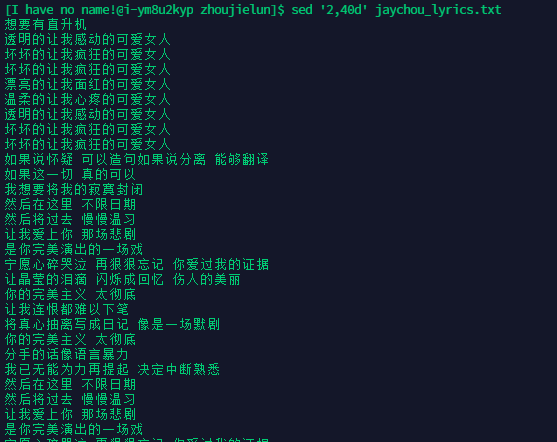
-
将歌词中 所有【我】替换成【你】
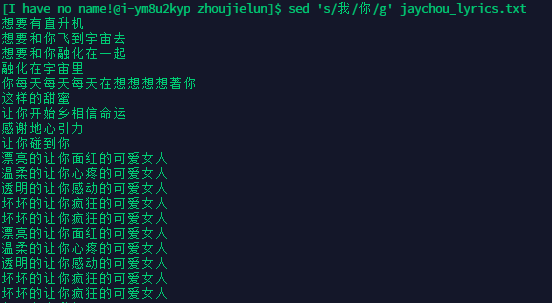
-
任务9:在目录下创建zip和tar压缩文件,并进行解压
任务要点:文件压缩
https://www.cnblogs.com/wxlf/p/8117602.html
-
步骤1:在/home/datawhale目录下在你英文昵称(中间不要有空格哦)的文件夹中,下载https://mirror.coggle.club/dataset/jaychou_lyrics.txt.zip
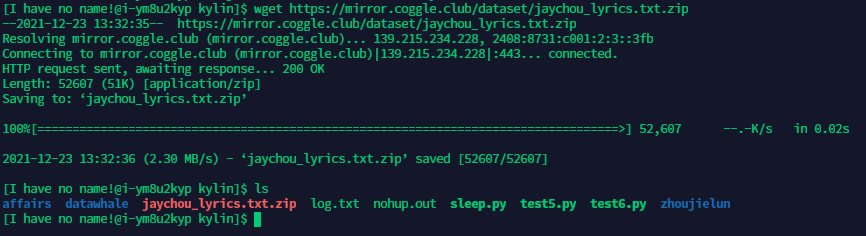
-
步骤2:使用zip 压缩/home/datawhale目录下在你英文昵称(中间不要有空格哦)的文件夹
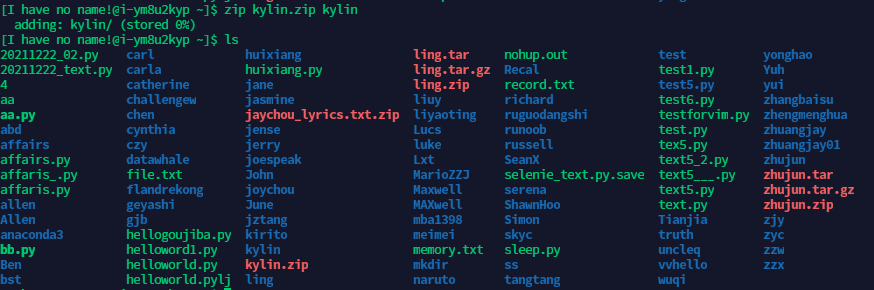
-
将步骤3:步骤3:将 /home/datawhale目录下在你英文昵称(中间不要有空格哦)的文件夹,打包为tar格式。
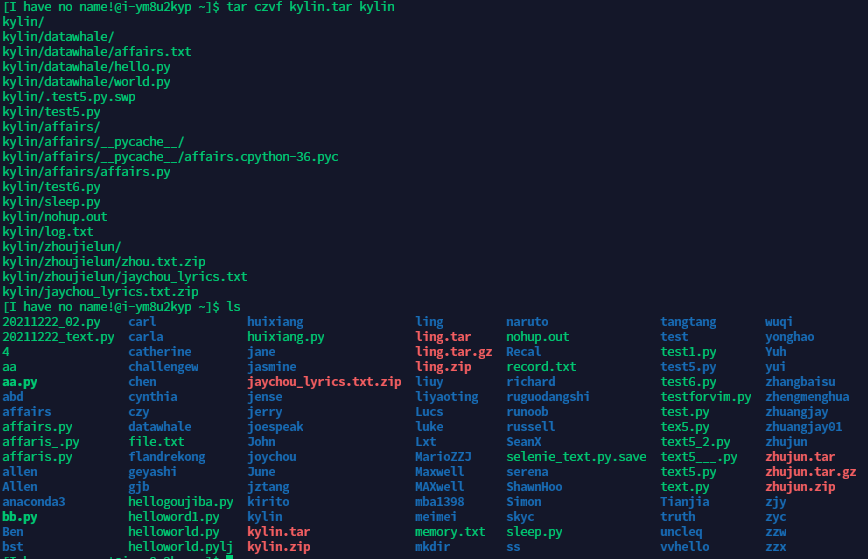
-
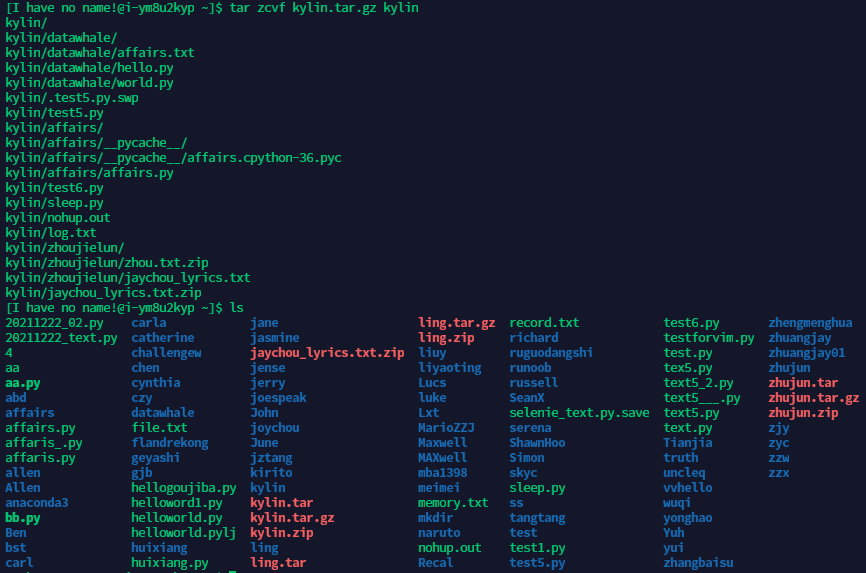
步骤4:将 /home/datawhale目录下在你英文昵称(中间不要有空格哦)的文件夹,打包为tar.gz格式。
任务10:使用find和locate定位文件
任务要点:文件搜索
https://www.runoob.com/linux/linux-comm-find.html
https://www.cnblogs.com/linjiqin/p/11678012.html
-
步骤1:使用find统计文件系统中以py为后缀名的文件个数
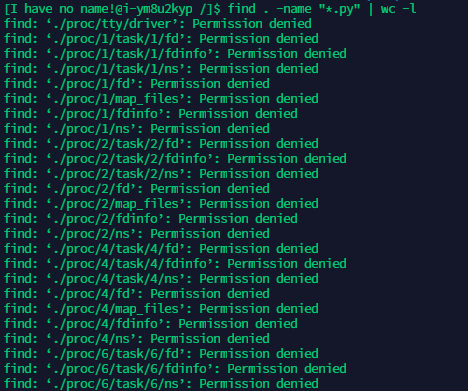

-
步骤2:使用find寻找/home/文件夹下文件内容包含datawhale的文件
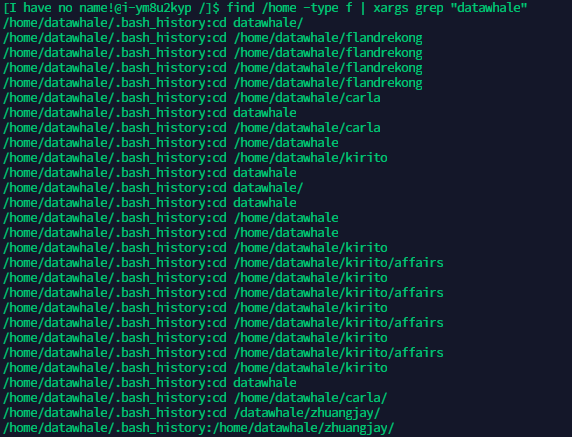
-
步骤3:时候用locate寻找到python3.6.1.gz文件

